 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Contact-Rich Manipulation of a Flexible Object based on Deep Predictive Learning using Vision and Tactility
Dec 13, 2021
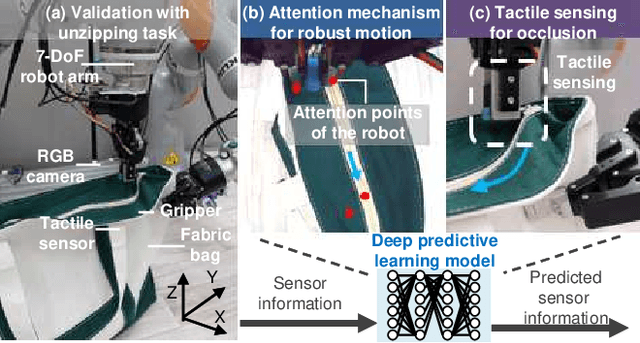
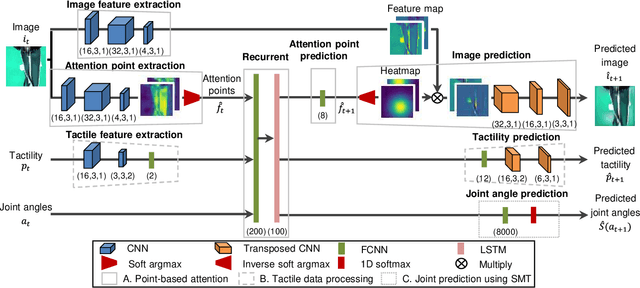

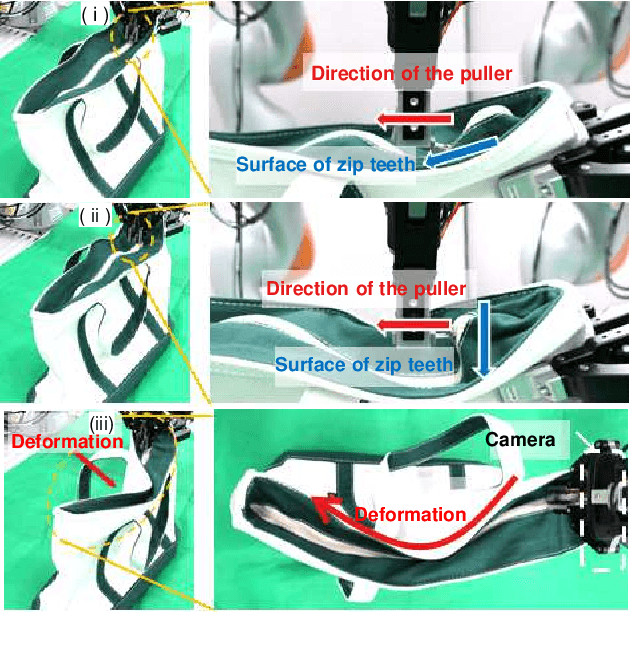
We achieved contact-rich flexible object manipulation, which was difficult to control with vision alone. In the unzipping task we chose as a validation task, the gripper grasps the puller, which hides the bag state such as the direction and amount of deformation behind it, making it difficult to obtain information to perform the task by vision alone. Additionally, the flexible fabric bag state constantly changes during operation, so the robot needs to dynamically respond to the change. However, the appropriate robot behavior for all bag states is difficult to prepare in advance. To solve this problem, we developed a model that can perform contact-rich flexible object manipulation by real-time prediction of vision with tactility. We introduced a point-based attention mechanism for extracting image features, softmax transformation for predicting motions, and convolutional neural network for extracting tactile features. The results of experiments using a real robot arm revealed that our method can realize motions responding to the deformation of the bag while reducing the load on the zipper. Furthermore, using tactility improved the success rate from 56.7% to 93.3% compared with vision alone, demonstrating the effectiveness and high performance of our method.
Nuclei Segmentation in Histopathology Images using Deep Learning with Local and Global Views
Dec 07, 2021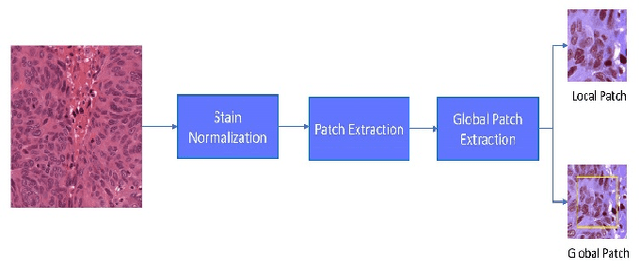
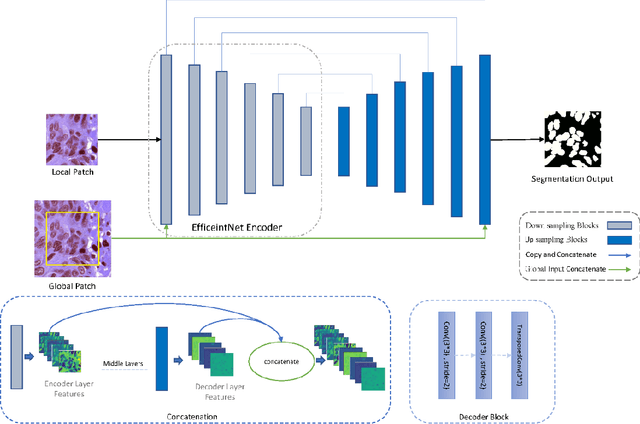
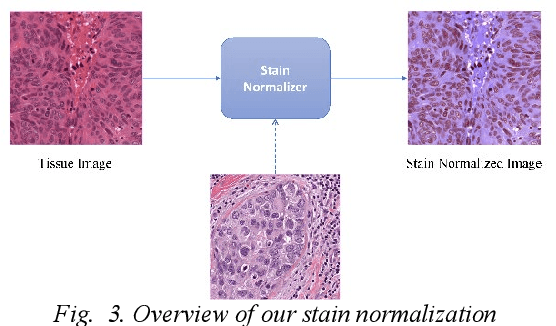
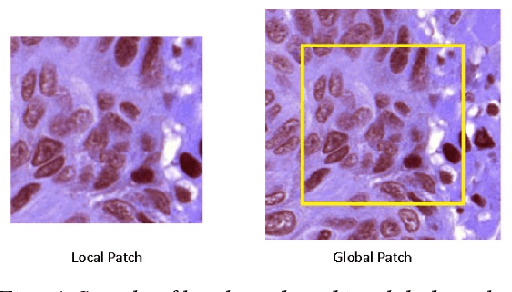
Digital pathology is one of the most significant developments in modern medicine. Pathological examinations are the gold standard of medical protocols and play a fundamental role in diagnosis. Recently, with the advent of digital scanners, tissue histopathology slides can now be digitized and stored as digital images. As a result, digitized histopathological tissues can be used in computer-aided image analysis programs and machine learning techniques. Detection and segmentation of nuclei are some of the essential steps in the diagnosis of cancers. Recently, deep learning has been used for nuclei segmentation. However, one of the problems in deep learning methods for nuclei segmentation is the lack of information from out of the patches. This paper proposes a deep learning-based approach for nuclei segmentation, which addresses the problem of misprediction in patch border areas. We use both local and global patches to predict the final segmentation map. Experimental results on the Multi-organ histopathology dataset demonstrate that our method outperforms the baseline nuclei segmentation and popular segmentation models.
Wav-BERT: Cooperative Acoustic and Linguistic Representation Learning for Low-Resource Speech Recognition
Sep 19, 2021
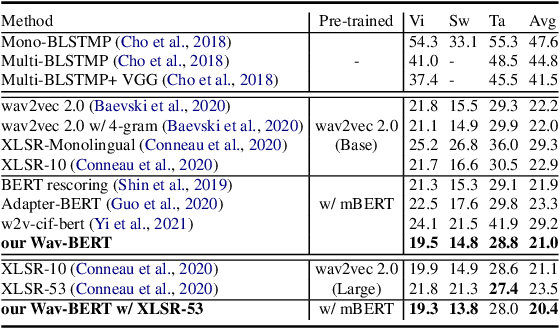
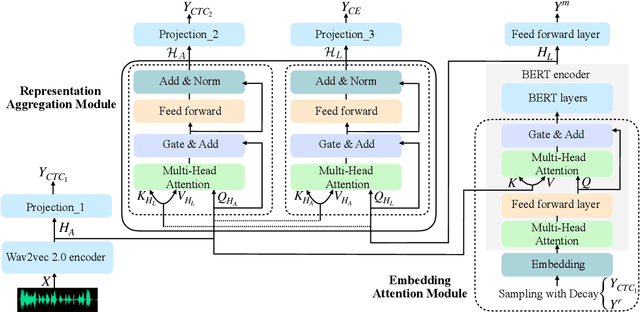
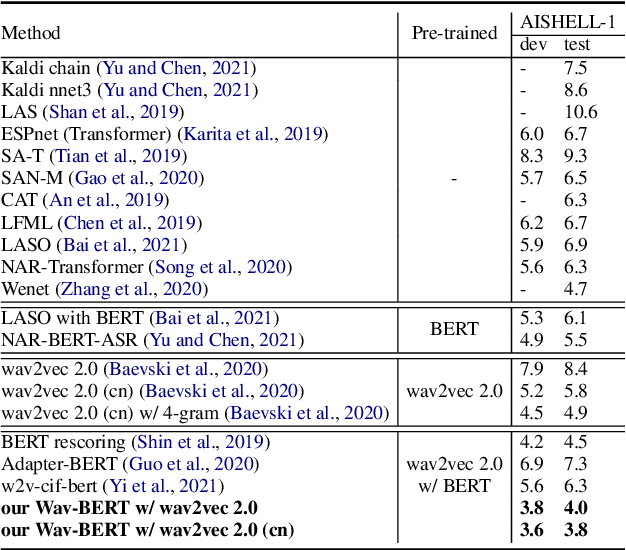
Unifying acoustic and linguistic representation learning has become increasingly crucial to transfer the knowledge learned on the abundance of high-resource language data for low-resource speech recognition. Existing approaches simply cascade pre-trained acoustic and language models to learn the transfer from speech to text. However, how to solve the representation discrepancy of speech and text is unexplored, which hinders the utilization of acoustic and linguistic information. Moreover, previous works simply replace the embedding layer of the pre-trained language model with the acoustic features, which may cause the catastrophic forgetting problem. In this work, we introduce Wav-BERT, a cooperative acoustic and linguistic representation learning method to fuse and utilize the contextual information of speech and text. Specifically, we unify a pre-trained acoustic model (wav2vec 2.0) and a language model (BERT) into an end-to-end trainable framework. A Representation Aggregation Module is designed to aggregate acoustic and linguistic representation, and an Embedding Attention Module is introduced to incorporate acoustic information into BERT, which can effectively facilitate the cooperation of two pre-trained models and thus boost the representation learning. Extensive experiments show that our Wav-BERT significantly outperforms the existing approaches and achieves state-of-the-art performance on low-resource speech recognition.
Incorporation of Deep Neural Network & Reinforcement Learning with Domain Knowledge
Jul 29, 2021
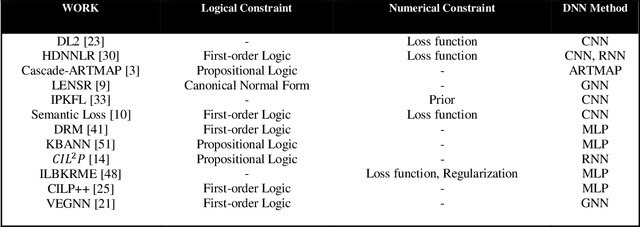
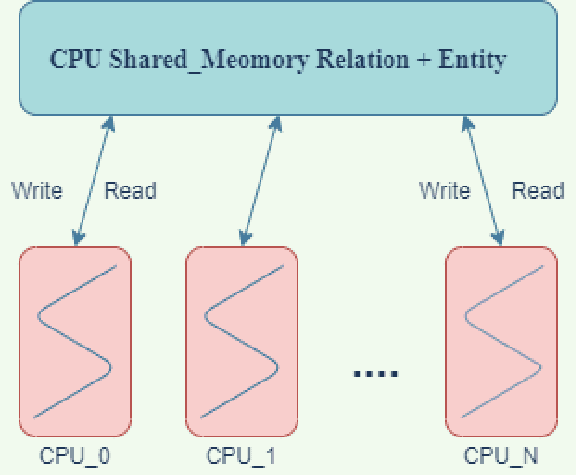
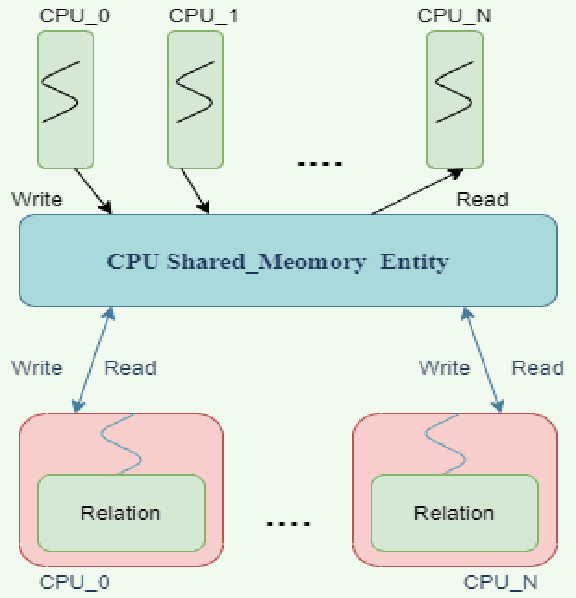
We present a study of the manners by which Domain information has been incorporated when building models with Neural Networks. Integrating space data is uniquely important to the development of Knowledge understanding model, as well as other fields that aid in understanding information by utilizing the human-machine interface and Reinforcement Learning. On numerous such occasions, machine-based model development may profit essentially from the human information on the world encoded in an adequately exact structure. This paper inspects expansive ways to affect encode such information as sensible and mathematical limitations and portrays methods and results that came to a couple of subcategories under all of those methodologies.
Trust in AutoML: Exploring Information Needs for Establishing Trust in Automated Machine Learning Systems
Jan 17, 2020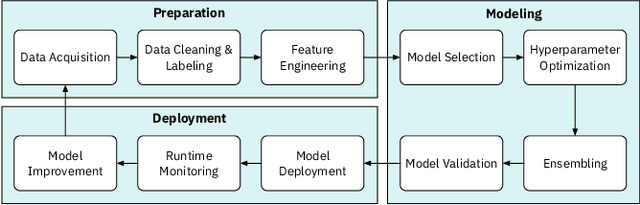

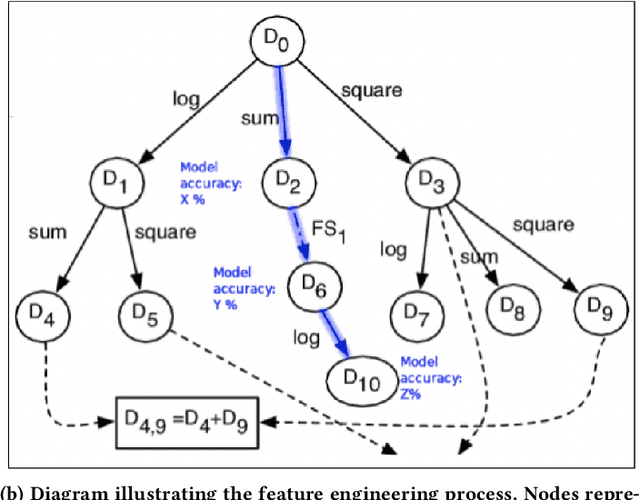
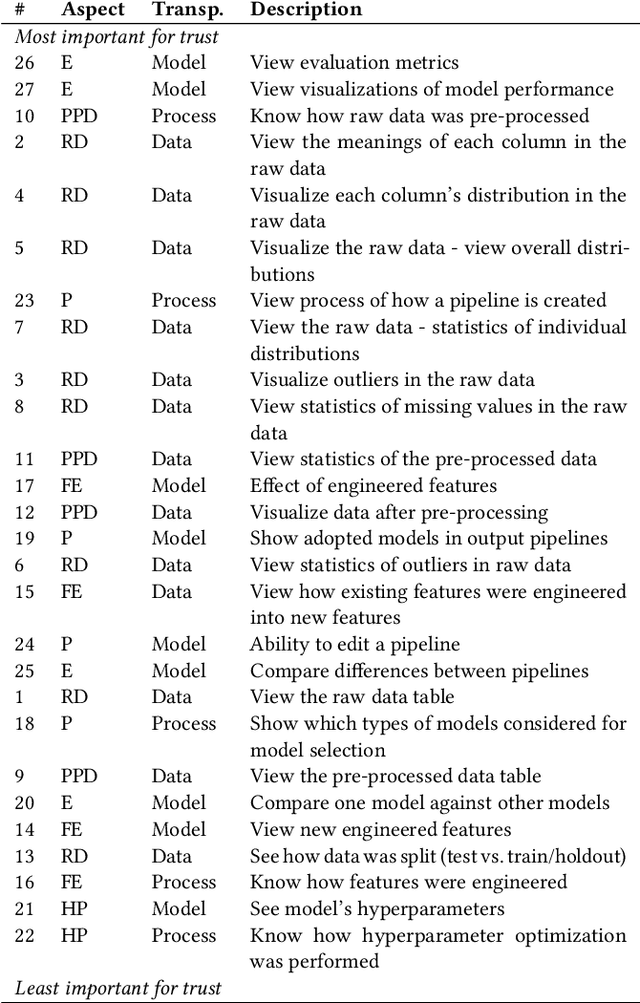
We explore trust in a relatively new area of data science: Automated Machine Learning (AutoML). In AutoML, AI methods are used to generate and optimize machine learning models by automatically engineering features, selecting models, and optimizing hyperparameters. In this paper, we seek to understand what kinds of information influence data scientists' trust in the models produced by AutoML? We operationalize trust as a willingness to deploy a model produced using automated methods. We report results from three studies -- qualitative interviews, a controlled experiment, and a card-sorting task -- to understand the information needs of data scientists for establishing trust in AutoML systems. We find that including transparency features in an AutoML tool increased user trust and understandability in the tool; and out of all proposed features, model performance metrics and visualizations are the most important information to data scientists when establishing their trust with an AutoML tool.
DA-FDFtNet: Dual Attention Fake Detection Fine-tuning Network to Detect Various AI-Generated Fake Images
Dec 22, 2021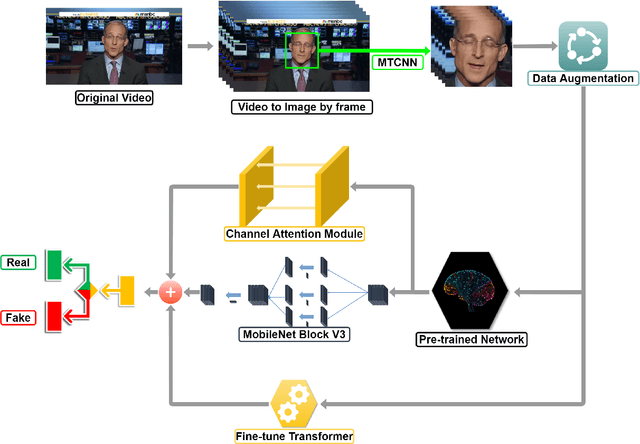

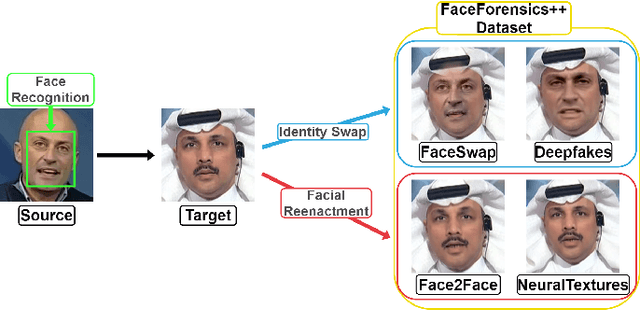

Due to the advancement of Generative Adversarial Networks (GAN), Autoencoders, and other AI technologies, it has been much easier to create fake images such as "Deepfakes". More recent research has introduced few-shot learning, which uses a small amount of training data to produce fake images and videos more effectively. Therefore, the ease of generating manipulated images and the difficulty of distinguishing those images can cause a serious threat to our society, such as propagating fake information. However, detecting realistic fake images generated by the latest AI technology is challenging due to the reasons mentioned above. In this work, we propose Dual Attention Fake Detection Fine-tuning Network (DA-FDFtNet) to detect the manipulated fake face images from the real face data. Our DA-FDFtNet integrates the pre-trained model with Fine-Tune Transformer, MBblockV3, and a channel attention module to improve the performance and robustness across different types of fake images. In particular, Fine-Tune Transformer consists of multiple numbers of an image-based self-attention module and a down-sampling layer. The channel attention module is also connected with the pre-trained model to capture the fake images feature space. We experiment with our DA-FDFtNet with the FaceForensics++ dataset and various GAN-generated datasets, and we show that our approach outperforms the previous baseline models.
Self-supervised Monocular Depth Estimation for All Day Images using Domain Separation
Aug 17, 2021
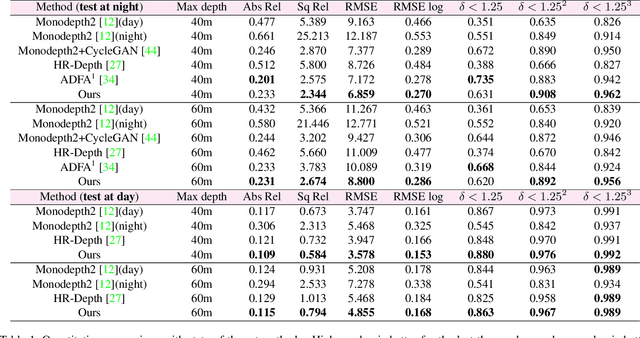
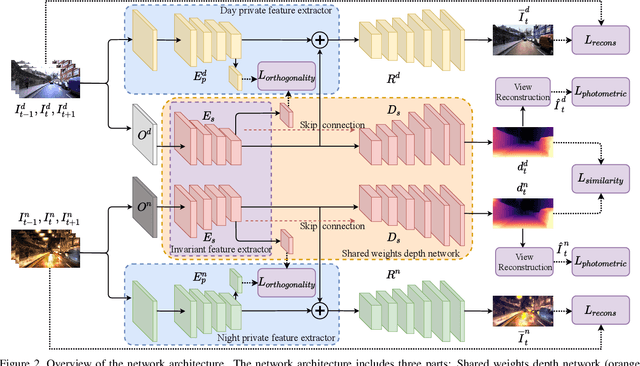
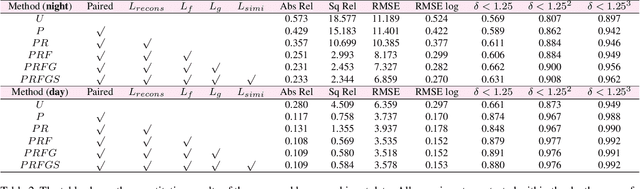
Remarkable results have been achieved by DCNN based self-supervised depth estimation approaches. However, most of these approaches can only handle either day-time or night-time images, while their performance degrades for all-day images due to large domain shift and the variation of illumination between day and night images. To relieve these limitations, we propose a domain-separated network for self-supervised depth estimation of all-day images. Specifically, to relieve the negative influence of disturbing terms (illumination, etc.), we partition the information of day and night image pairs into two complementary sub-spaces: private and invariant domains, where the former contains the unique information (illumination, etc.) of day and night images and the latter contains essential shared information (texture, etc.). Meanwhile, to guarantee that the day and night images contain the same information, the domain-separated network takes the day-time images and corresponding night-time images (generated by GAN) as input, and the private and invariant feature extractors are learned by orthogonality and similarity loss, where the domain gap can be alleviated, thus better depth maps can be expected. Meanwhile, the reconstruction and photometric losses are utilized to estimate complementary information and depth maps effectively. Experimental results demonstrate that our approach achieves state-of-the-art depth estimation results for all-day images on the challenging Oxford RobotCar dataset, proving the superiority of our proposed approach.
Covariance-Generalized Matching Component Analysis for Data Fusion and Transfer Learning
Oct 25, 2021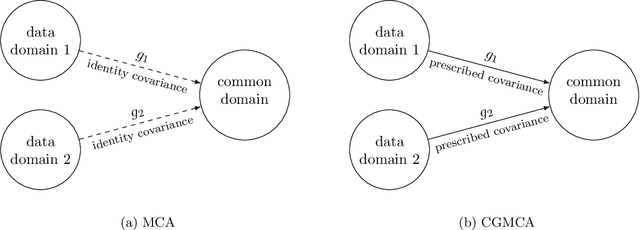


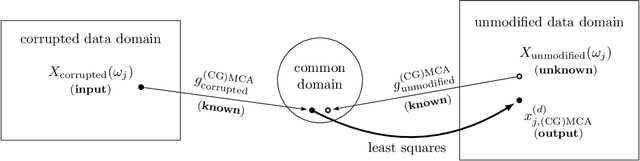
In order to allow for the encoding of additional statistical information in data fusion and transfer learning applications, we introduce a generalized covariance constraint for the matching component analysis (MCA) transfer learning technique. After proving a semi-orthogonally constrained trace maximization lemma, we develop a closed-form solution to the resulting covariance-generalized optimization problem and provide an algorithm for its computation. We call this technique -- applicable to both data fusion and transfer learning -- covariance-generalized MCA (CGMCA).
Vehicle Detection and Tracking From Surveillance Cameras in Urban Scenes
Sep 25, 2021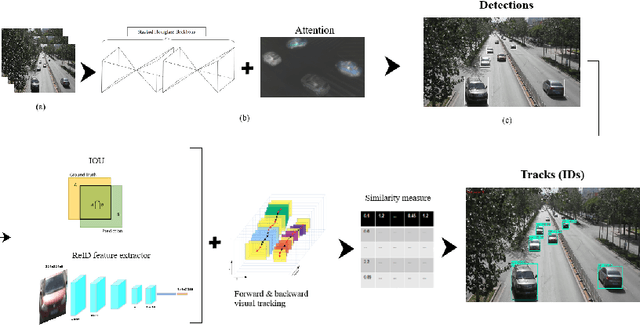
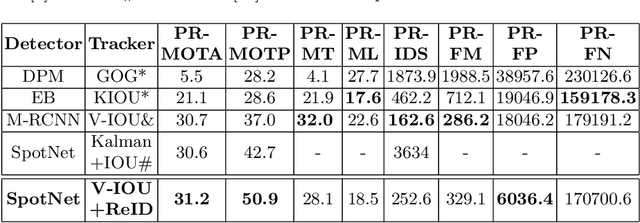
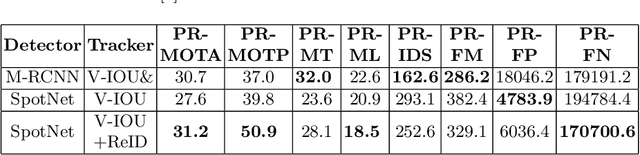
Detecting and tracking vehicles in urban scenes is a crucial step in many traffic-related applications as it helps to improve road user safety among other benefits. Various challenges remain unresolved in multi-object tracking (MOT) including target information description, long-term occlusions and fast motion. We propose a multi-vehicle detection and tracking system following the tracking-by-detection paradigm that tackles the previously mentioned challenges. Our MOT method extends an Intersection-over-Union (IOU)-based tracker with vehicle re-identification features. This allows us to utilize appearance information to better match objects after long occlusion phases and/or when object location is significantly shifted due to fast motion. We outperform our baseline MOT method on the UA-DETRAC benchmark while maintaining a total processing speed suitable for online use cases.
Complementary Patch for Weakly Supervised Semantic Segmentation
Aug 09, 2021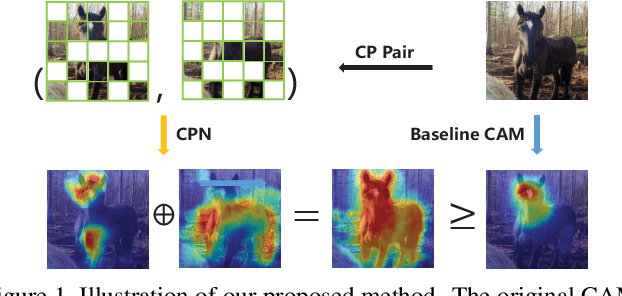
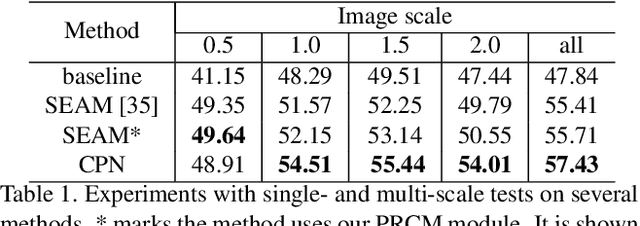
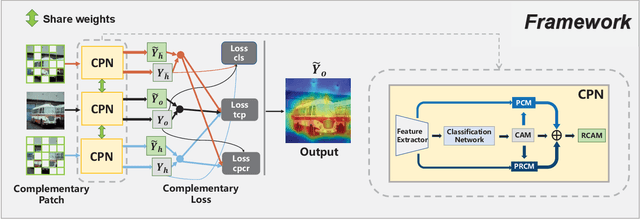

Weakly Supervised Semantic Segmentation (WSSS) based on image-level labels has been greatly advanced by exploiting the outputs of Class Activation Map (CAM) to generate the pseudo labels for semantic segmentation. However, CAM merely discovers seeds from a small number of regions, which may be insufficient to serve as pseudo masks for semantic segmentation. In this paper, we formulate the expansion of object regions in CAM as an increase in information. From the perspective of information theory, we propose a novel Complementary Patch (CP) Representation and prove that the information of the sum of the CAMs by a pair of input images with complementary hidden (patched) parts, namely CP Pair, is greater than or equal to the information of the baseline CAM. Therefore, a CAM with more information related to object seeds can be obtained by narrowing down the gap between the sum of CAMs generated by the CP Pair and the original CAM. We propose a CP Network (CPN) implemented by a triplet network and three regularization functions. To further improve the quality of the CAMs, we propose a Pixel-Region Correlation Module (PRCM) to augment the contextual information by using object-region relations between the feature maps and the CAMs. Experimental results on the PASCAL VOC 2012 datasets show that our proposed method achieves a new state-of-the-art in WSSS, validating the effectiveness of our CP Representation and CPN.