 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWav-BERT: Cooperative Acoustic and Linguistic Representation Learning for Low-Resource Speech Recognition
Paper and Code

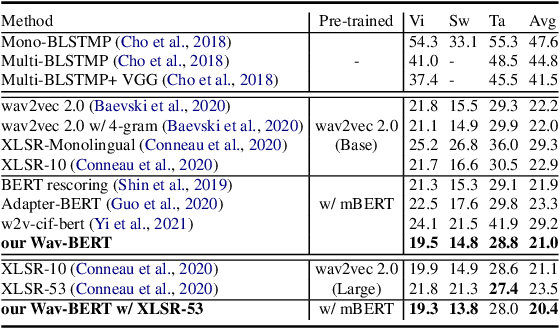
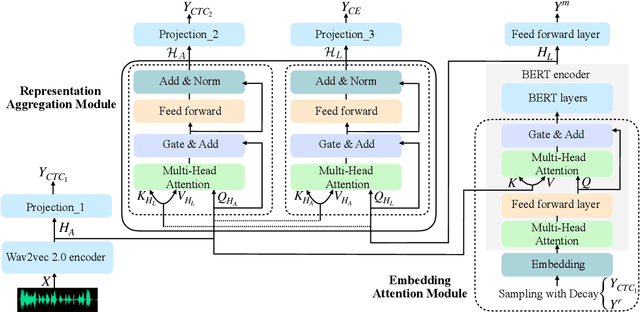
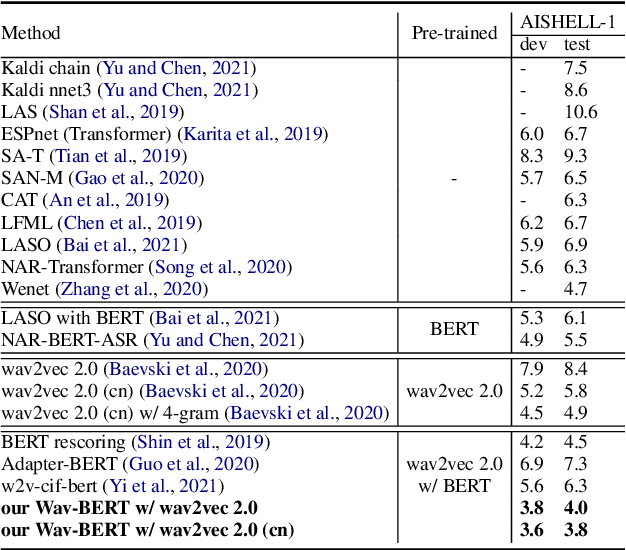
Unifying acoustic and linguistic representation learning has become increasingly crucial to transfer the knowledge learned on the abundance of high-resource language data for low-resource speech recognition. Existing approaches simply cascade pre-trained acoustic and language models to learn the transfer from speech to text. However, how to solve the representation discrepancy of speech and text is unexplored, which hinders the utilization of acoustic and linguistic information. Moreover, previous works simply replace the embedding layer of the pre-trained language model with the acoustic features, which may cause the catastrophic forgetting problem. In this work, we introduce Wav-BERT, a cooperative acoustic and linguistic representation learning method to fuse and utilize the contextual information of speech and text. Specifically, we unify a pre-trained acoustic model (wav2vec 2.0) and a language model (BERT) into an end-to-end trainable framework. A Representation Aggregation Module is designed to aggregate acoustic and linguistic representation, and an Embedding Attention Module is introduced to incorporate acoustic information into BERT, which can effectively facilitate the cooperation of two pre-trained models and thus boost the representation learning. Extensive experiments show that our Wav-BERT significantly outperforms the existing approaches and achieves state-of-the-art performance on low-resource speech recognition.