 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards generating citation sentences for multiple references with intent control
Dec 02, 2021

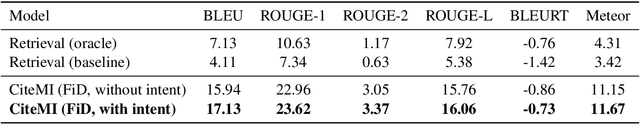
Machine-generated citation sentences can aid automated scientific literature review and assist article writing. Current methods in generating citation text were limited to single citation generation using the citing document and a cited document as input. However, in real-world situations, writers often summarize several studies in one sentence or discuss relevant information across the entire paragraph. In addition, multiple citation intents have been previously identified, implying that writers may need control over the intents of generated sentences to cover different scenarios. Therefore, this work focuses on generating multiple citations and releasing a newly collected dataset named CiteMI to drive the future research. We first build a novel generation model with the Fusion-in-Decoder approach to cope with multiple long inputs. Second, we incorporate the predicted citation intents into training for intent control. The experiments demonstrate that the proposed approaches provide much more comprehensive features for generating citation sentences.
CHIP: CHannel Independence-based Pruning for Compact Neural Networks
Oct 26, 2021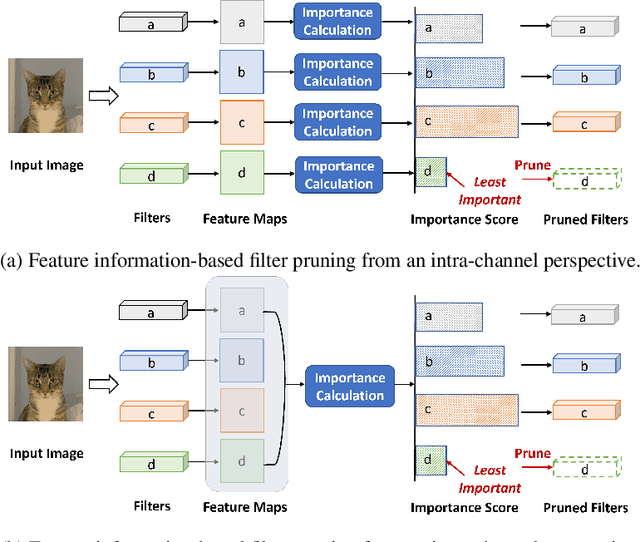
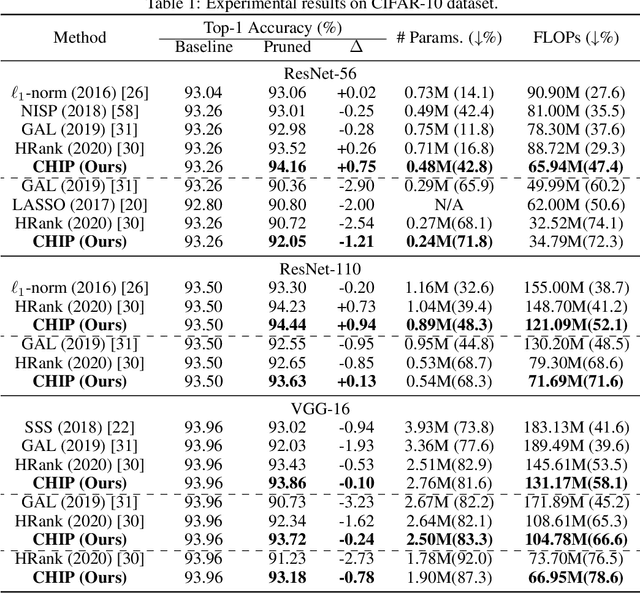
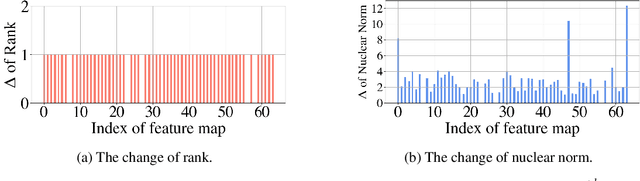
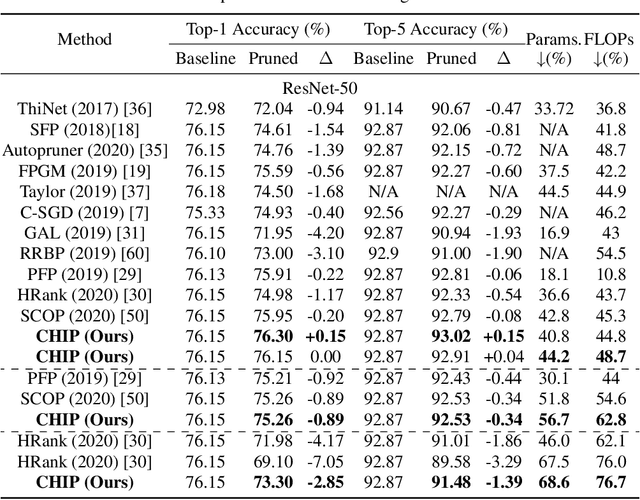
Filter pruning has been widely used for neural network compression because of its enabled practical acceleration. To date, most of the existing filter pruning works explore the importance of filters via using intra-channel information. In this paper, starting from an inter-channel perspective, we propose to perform efficient filter pruning using Channel Independence, a metric that measures the correlations among different feature maps. The less independent feature map is interpreted as containing less useful information$/$knowledge, and hence its corresponding filter can be pruned without affecting model capacity. We systematically investigate the quantification metric, measuring scheme and sensitiveness$/$reliability of channel independence in the context of filter pruning. Our evaluation results for different models on various datasets show the superior performance of our approach. Notably, on CIFAR-10 dataset our solution can bring $0.75\%$ and $0.94\%$ accuracy increase over baseline ResNet-56 and ResNet-110 models, respectively, and meanwhile the model size and FLOPs are reduced by $42.8\%$ and $47.4\%$ (for ResNet-56) and $48.3\%$ and $52.1\%$ (for ResNet-110), respectively. On ImageNet dataset, our approach can achieve $40.8\%$ and $44.8\%$ storage and computation reductions, respectively, with $0.15\%$ accuracy increase over the baseline ResNet-50 model. The code is available at https://github.com/Eclipsess/CHIP_NeurIPS2021.
CPRAL: Collaborative Panoptic-Regional Active Learning for Semantic Segmentation
Dec 11, 2021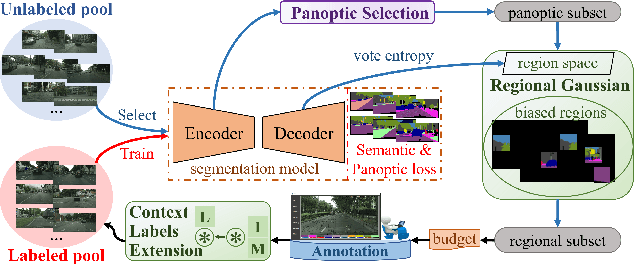
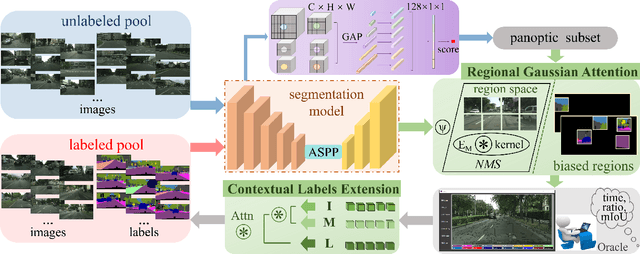
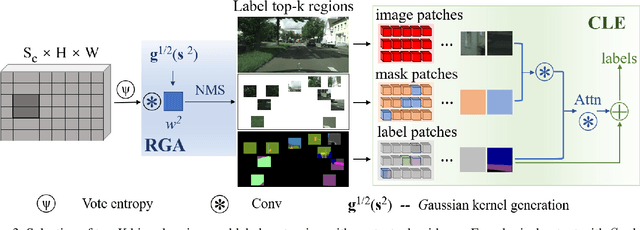

Acquiring the most representative examples via active learning (AL) can benefit many data-dependent computer vision tasks by minimizing efforts of image-level or pixel-wise annotations. In this paper, we propose a novel Collaborative Panoptic-Regional Active Learning framework (CPRAL) to address the semantic segmentation task. For a small batch of images initially sampled with pixel-wise annotations, we employ panoptic information to initially select unlabeled samples. Considering the class imbalance in the segmentation dataset, we import a Regional Gaussian Attention module (RGA) to achieve semantics-biased selection. The subset is highlighted by vote entropy and then attended by Gaussian kernels to maximize the biased regions. We also propose a Contextual Labels Extension (CLE) to boost regional annotations with contextual attention guidance. With the collaboration of semantics-agnostic panoptic matching and regionbiased selection and extension, our CPRAL can strike a balance between labeling efforts and performance and compromise the semantics distribution. We perform extensive experiments on Cityscapes and BDD10K datasets and show that CPRAL outperforms the cutting-edge methods with impressive results and less labeling proportion.
Complexity from Adaptive-Symmetries Breaking: Global Minima in the Statistical Mechanics of Deep Neural Networks
Jan 03, 2022
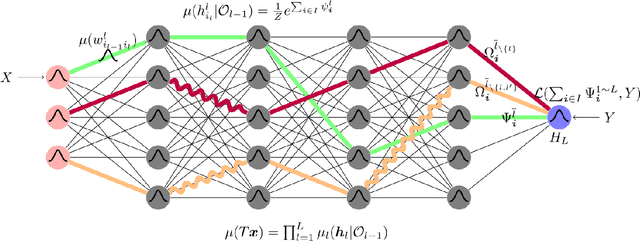

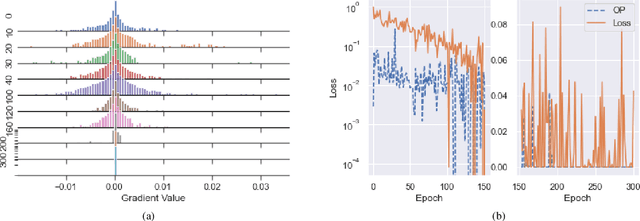
An antithetical concept, adaptive symmetry, to conservative symmetry in physics is proposed to understand the deep neural networks (DNNs). It characterizes the invariance of variance, where a biotic system explores different pathways of evolution with equal probability in absence of feedback signals, and complex functional structure emerges from quantitative accumulation of adaptive-symmetries breaking in response to feedback signals. Theoretically and experimentally, we characterize the optimization process of a DNN system as an extended adaptive-symmetry-breaking process. One particular finding is that a hierarchically large DNN would have a large reservoir of adaptive symmetries, and when the information capacity of the reservoir exceeds the complexity of the dataset, the system could absorb all perturbations of the examples and self-organize into a functional structure of zero training errors measured by a certain surrogate risk. More specifically, this process is characterized by a statistical-mechanical model that could be appreciated as a generalization of statistics physics to the DNN organized complex system, and characterizes regularities in higher dimensionality. The model consists of three constitutes that could be appreciated as the counterparts of Boltzmann distribution, Ising model, and conservative symmetry, respectively: (1) a stochastic definition/interpretation of DNNs that is a multilayer probabilistic graphical model, (2) a formalism of circuits that perform biological computation, (3) a circuit symmetry from which self-similarity between the microscopic and the macroscopic adaptability manifests. The model is analyzed with a method referred as the statistical assembly method that analyzes the coarse-grained behaviors (over a symmetry group) of the heterogeneous hierarchical many-body interaction in DNNs.
PWM2Vec: An Efficient Embedding Approach for Viral Host Specification from Coronavirus Spike Sequences
Jan 06, 2022
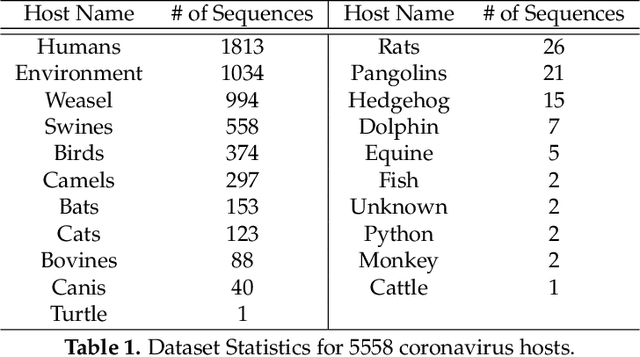
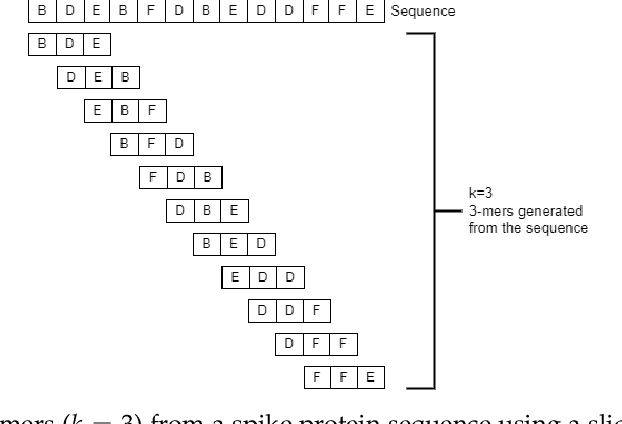
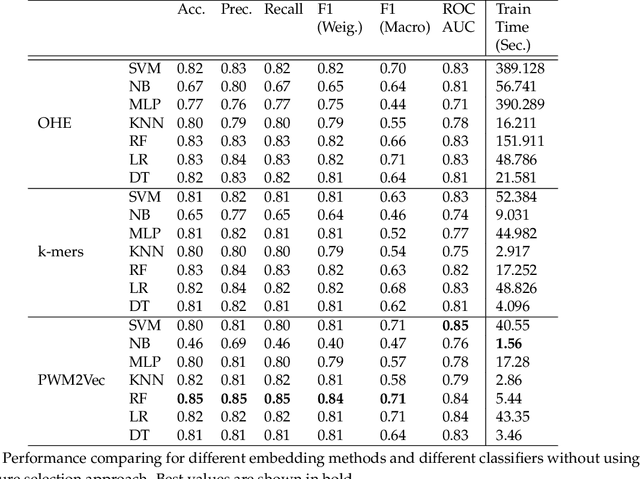
COVID-19 pandemic, is still unknown and is an important open question. There are speculations that bats are a possible origin. Likewise, there are many closely related (corona-) viruses, such as SARS, which was found to be transmitted through civets. The study of the different hosts which can be potential carriers and transmitters of deadly viruses to humans is crucial to understanding, mitigating and preventing current and future pandemics. In coronaviruses, the surface (S) protein, or spike protein, is an important part of determining host specificity since it is the point of contact between the virus and the host cell membrane. In this paper, we classify the hosts of over five thousand coronaviruses from their spike protein sequences, segregating them into clusters of distinct hosts among avians, bats, camels, swines, humans and weasels, to name a few. We propose a feature embedding based on the well-known position-weight matrix (PWM), which we call PWM2Vec, and use to generate feature vectors from the spike protein sequences of these coronaviruses. While our embedding is inspired by the success of PWMs in biological applications such as determining protein function, or identifying transcription factor binding sites, we are the first (to the best of our knowledge) to use PWMs in the context of host classification from viral sequences to generate a fixed-length feature vector representation. The results on the real world data show that in using PWM2Vec, we are able to perform comparably well as compared to baseline models. We also measure the importance of different amino acids using information gain to show the amino acids which are important for predicting the host of a given coronavirus.
Supervised Graph Contrastive Pretraining for Text Classification
Dec 21, 2021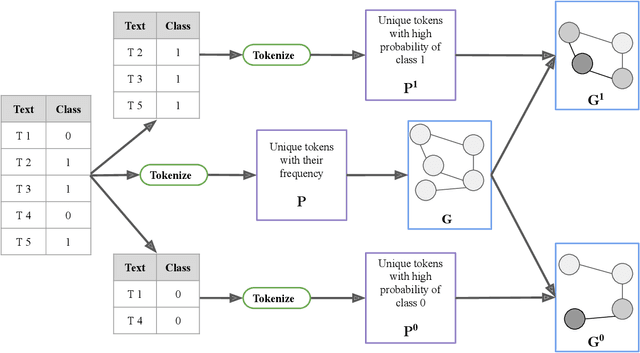
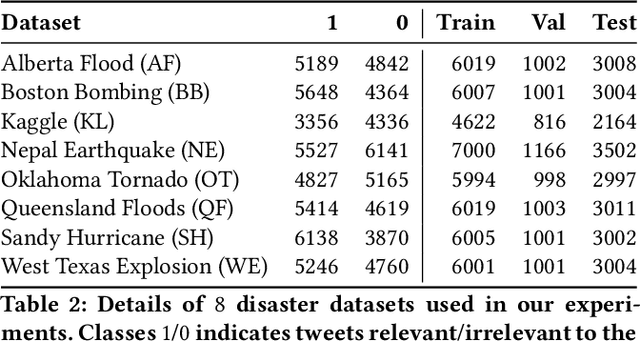
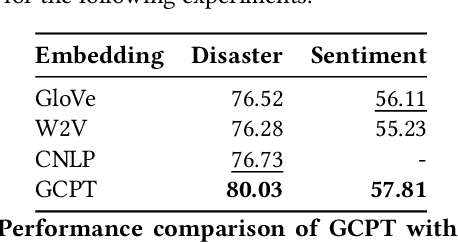
Contrastive pretraining techniques for text classification has been largely studied in an unsupervised setting. However, oftentimes labeled data from related tasks which share label semantics with current task is available. We hypothesize that using this labeled data effectively can lead to better generalization on current task. In this paper, we propose a novel way to effectively utilize labeled data from related tasks with a graph based supervised contrastive learning approach. We formulate a token-graph by extrapolating the supervised information from examples to tokens. Our formulation results in an embedding space where tokens with high/low probability of belonging to same class are near/further-away from one another. We also develop detailed theoretical insights which serve as a motivation for our method. In our experiments with $13$ datasets, we show our method outperforms pretraining schemes by $2.5\%$ and also example-level contrastive learning based formulation by $1.8\%$ on average. In addition, we show cross-domain effectiveness of our method in a zero-shot setting by $3.91\%$ on average. Lastly, we also demonstrate our method can be used as a noisy teacher in a knowledge distillation setting to significantly improve performance of transformer based models in low labeled data regime by $4.57\%$ on average.
ALEBk: Feasibility Study of Attention Level Estimation via Blink Detection applied to e-Learning
Dec 16, 2021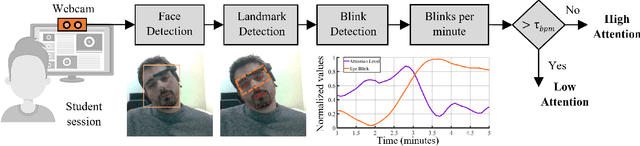
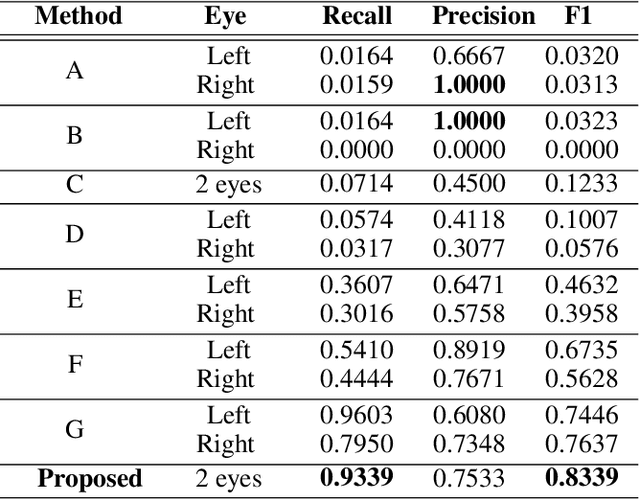
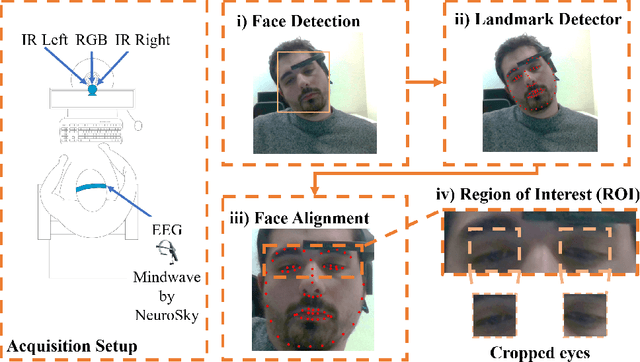
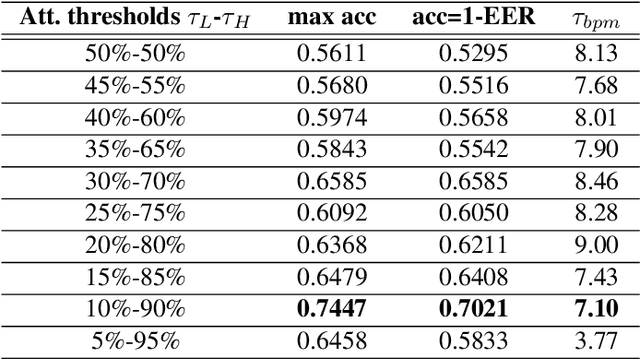
This work presents a feasibility study of remote attention level estimation based on eye blink frequency. We first propose an eye blink detection system based on Convolutional Neural Networks (CNNs), very competitive with respect to related works. Using this detector, we experimentally evaluate the relationship between the eye blink rate and the attention level of students captured during online sessions. The experimental framework is carried out using a public multimodal database for eye blink detection and attention level estimation called mEBAL, which comprises data from 38 students and multiples acquisition sensors, in particular, i) an electroencephalogram (EEG) band which provides the time signals coming from the student's cognitive information, and ii) RGB and NIR cameras to capture the students face gestures. The results achieved suggest an inverse correlation between the eye blink frequency and the attention level. This relation is used in our proposed method called ALEBk for estimating the attention level as the inverse of the eye blink frequency. Our results open a new research line to introduce this technology for attention level estimation on future e-learning platforms, among other applications of this kind of behavioral biometrics based on face analysis.
Modeling Scale-free Graphs for Knowledge-aware Recommendation
Aug 14, 2021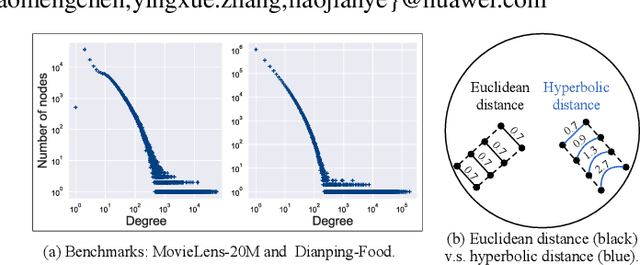
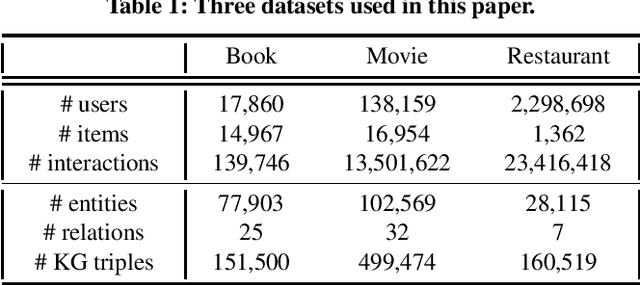
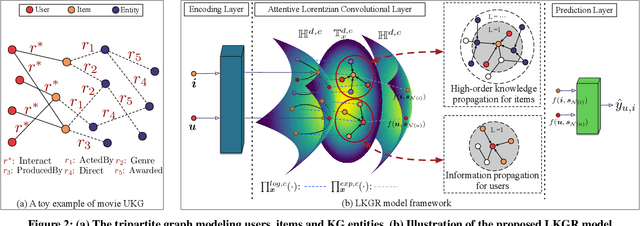
Aiming to alleviate data sparsity and cold-start problems of traditional recommender systems, incorporating knowledge graphs (KGs) to supplement auxiliary information has recently gained considerable attention. Via unifying the KG with user-item interactions into a tripartite graph, recent works explore the graph topologies to learn the low-dimensional representations of users and items with rich semantics. However, these real-world tripartite graphs are usually scale-free, the intrinsic hierarchical graph structures of which are underemphasized in existing works, consequently, leading to suboptimal recommendation performance. To address this issue and provide more accurate recommendation, we propose a knowledge-aware recommendation method with the hyperbolic geometry, namely Lorentzian Knowledge-enhanced Graph convolutional networks for Recommendation (LKGR). LKGR facilitates better modeling of scale-free tripartite graphs after the data unification. Specifically, we employ different information propagation strategies in the hyperbolic space to explicitly encode heterogeneous information from historical interactions and KGs. Our proposed knowledge-aware attention mechanism enables the model to automatically measure the information contribution, producing the coherent information aggregation in the hyperbolic space. Extensive experiments on three real-world benchmarks demonstrate that LKGR outperforms state-of-the-art methods by 2.2-29.9% of Recall@20 on Top-K recommendation.
Inspecting adversarial examples using the Fisher information
Sep 12, 2019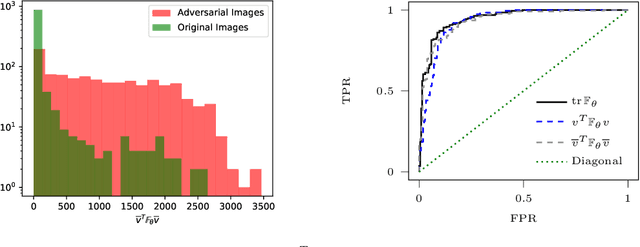

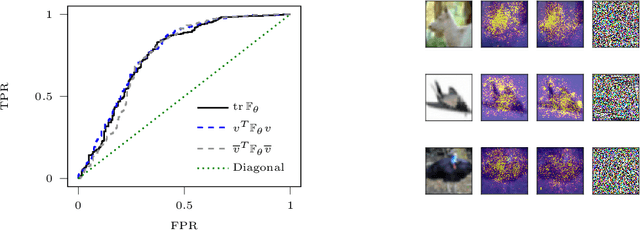
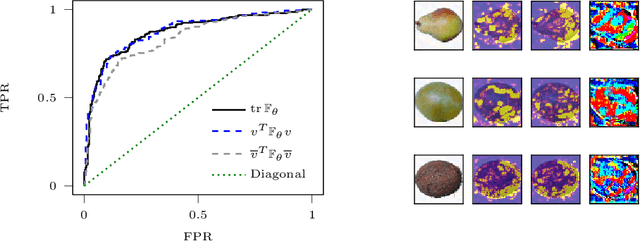
Adversarial examples are slight perturbations that are designed to fool artificial neural networks when fed as an input. In this work the usability of the Fisher information for the detection of such adversarial attacks is studied. We discuss various quantities whose computation scales well with the network size, study their behavior on adversarial examples and show how they can highlight the importance of single input neurons, thereby providing a visual tool for further analyzing (un-)reasonable behavior of a neural network. The potential of our methods is demonstrated by applications to the MNIST, CIFAR10 and Fruits-360 datasets.
Generalized Bayesian Cramér-Rao Inequality via Information Geometry of Relative $α$-Entropy
Feb 11, 2020The relative $\alpha$-entropy is the R\'enyi analog of relative entropy and arises prominently in information-theoretic problems. Recent information geometric investigations on this quantity have enabled the generalization of the Cram\'{e}r-Rao inequality, which provides a lower bound for the variance of an estimator of an escort of the underlying parametric probability distribution. However, this framework remains unexamined in the Bayesian framework. In this paper, we propose a general Riemannian metric based on relative $\alpha$-entropy to obtain a generalized Bayesian Cram\'{e}r-Rao inequality. This establishes a lower bound for the variance of an unbiased estimator for the $\alpha$-escort distribution starting from an unbiased estimator for the underlying distribution. We show that in the limiting case when the entropy order approaches unity, this framework reduces to the conventional Bayesian Cram\'{e}r-Rao inequality. Further, in the absence of priors, the same framework yields the deterministic Cram\'{e}r-Rao inequality.