 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgecc-Shapley: Measuring Multivariate Feature Importance Needs Causal Context
Feb 23, 2026Explainable artificial intelligence promises to yield insights into relevant features, thereby enabling humans to examine and scrutinize machine learning models or even facilitating scientific discovery. Considering the widespread technique of Shapley values, we find that purely data-driven operationalization of multivariate feature importance is unsuitable for such purposes. Even for simple problems with two features, spurious associations due to collider bias and suppression arise from considering one feature only in the observational context of the other, which can lead to misinterpretations. Causal knowledge about the data-generating process is required to identify and correct such misleading feature attributions. We propose cc-Shapley (causal context Shapley), an interventional modification of conventional observational Shapley values leveraging knowledge of the data's causal structure, thereby analyzing the relevance of a feature in the causal context of the remaining features. We show theoretically that this eradicates spurious association induced by collider bias. We compare the behavior of Shapley and cc-Shapley values on various, synthetic, and real-world datasets. We observe nullification or reversal of associations compared to univariate feature importance when moving from observational to cc-Shapley.
Optimal Subspace Inference for the Laplace Approximation of Bayesian Neural Networks
Feb 04, 2025Subspace inference for neural networks assumes that a subspace of their parameter space suffices to produce a reliable uncertainty quantification. In this work, we mathematically derive the optimal subspace model to a Bayesian inference scenario based on the Laplace approximation. We demonstrate empirically that, in the optimal case, often a fraction of parameters less than 1% is sufficient to obtain a reliable estimate of the full Laplace approximation. Since the optimal solution is derived, we can evaluate all other subspace models against a baseline. In addition, we give an approximation of our method that is applicable to larger problem settings, in which the optimal solution is not computable, and compare it to existing subspace models from the literature. In general, our approximation scheme outperforms previous work. Furthermore, we present a metric to qualitatively compare different subspace models even if the exact Laplace approximation is unknown.
A framework for benchmarking uncertainty in deep regression
Sep 10, 2021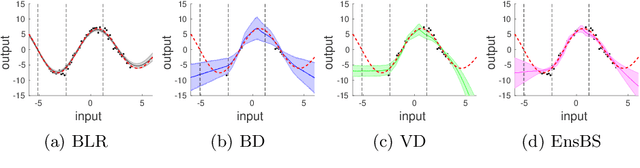
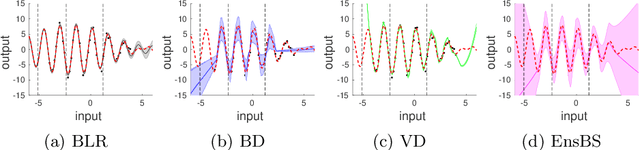
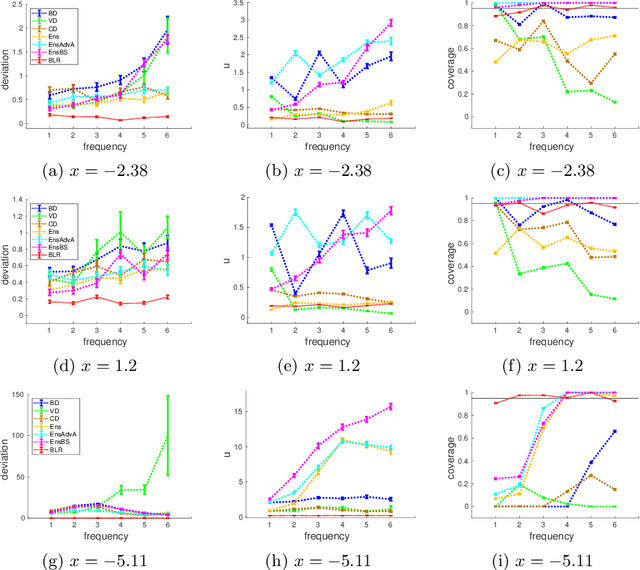
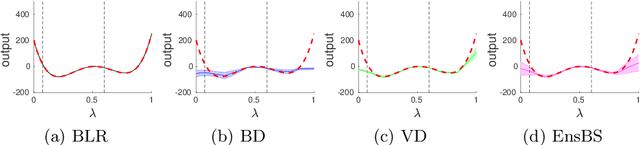
We propose a framework for the assessment of uncertainty quantification in deep regression. The framework is based on regression problems where the regression function is a linear combination of nonlinear functions. Basically, any level of complexity can be realized through the choice of the nonlinear functions and the dimensionality of their domain. Results of an uncertainty quantification for deep regression are compared against those obtained by a statistical reference method. The reference method utilizes knowledge of the underlying nonlinear functions and is based on a Bayesian linear regression using a reference prior. Reliability of uncertainty quantification is assessed in terms of coverage probabilities, and accuracy through the size of calculated uncertainties. We illustrate the proposed framework by applying it to current approaches for uncertainty quantification in deep regression. The flexibility, together with the availability of a reference solution, makes the framework suitable for defining benchmark sets for uncertainty quantification.
Errors-in-Variables for deep learning: rethinking aleatoric uncertainty
May 27, 2021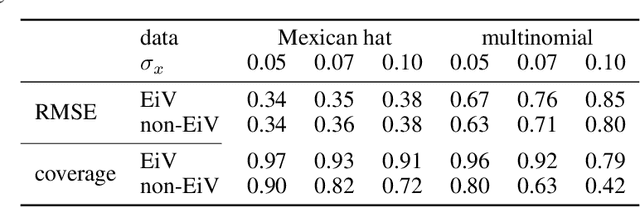
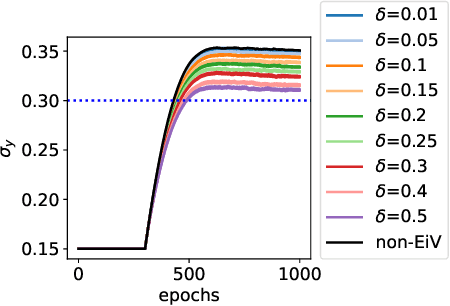
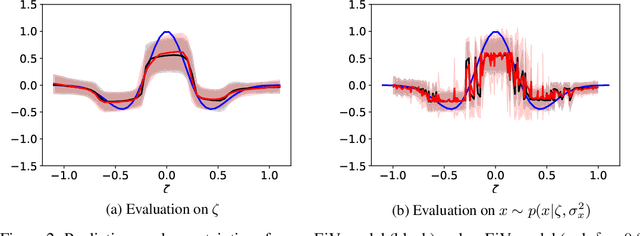
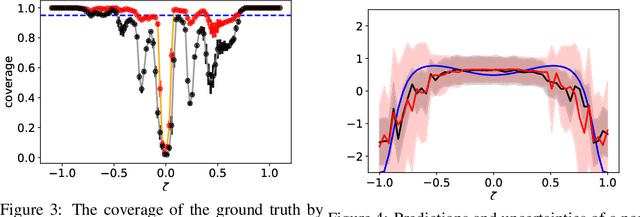
We present a Bayesian treatment for deep regression using an Errors-in-Variables model which accounts for the uncertainty associated with the input to the employed neural network. It is shown how the treatment can be combined with already existing approaches for uncertainty quantification that are based on variational inference. Our approach yields a decomposition of the predictive uncertainty into an aleatoric and epistemic part that is more complete and, in many cases, more consistent from a statistical perspective. We illustrate and discuss the approach along various toy and real world examples.
About the regularity of the discriminator in conditional WGANs
Mar 25, 2021Training of conditional WGANs is usually done by averaging the underlying loss over the condition. Depending on the way this is motivated different constraints on the Lipschitz continuity of the discriminator arise. For the weaker requirement on the regularity there is however so far no mathematically complete justification for the used loss function. This short mathematical note intends to fill this gap and provides the mathematical rationale for discriminators that are only partially Lipschitz-1 for cases where this approach is more appropriate or successful.
Detecting unusual input to neural networks
Jun 15, 2020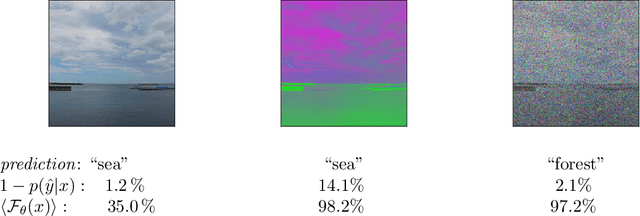
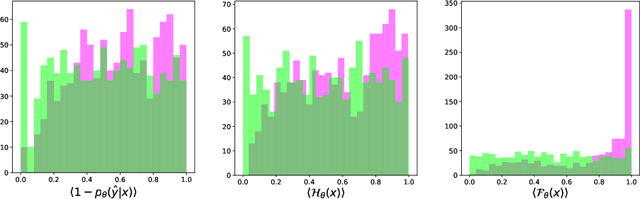
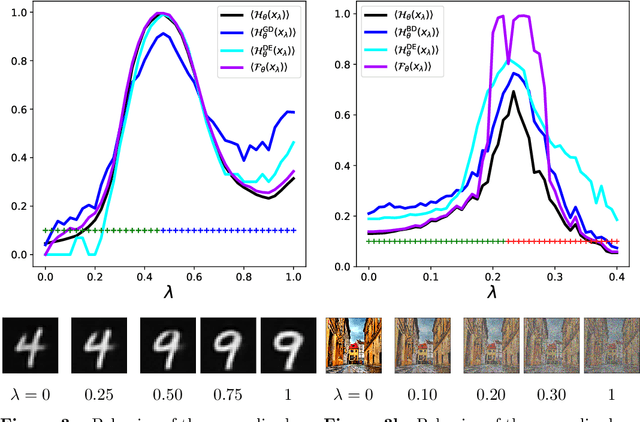
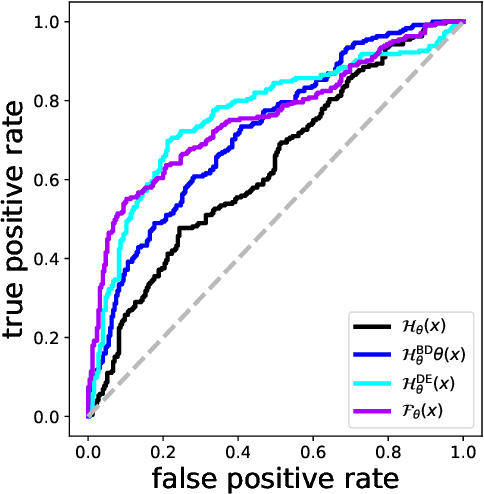
Evaluating a neural network on an input that differs markedly from the training data might cause erratic and flawed predictions. We study a method that judges the unusualness of an input by evaluating its informative content compared to the learned parameters. This technique can be used to judge whether a network is suitable for processing a certain input and to raise a red flag that unexpected behavior might lie ahead. We compare our approach to various methods for uncertainty evaluation from the literature for various datasets and scenarios. Specifically, we introduce a simple, effective method that allows to directly compare the output of such metrics for single input points even if these metrics live on different scales.
Inspecting adversarial examples using the Fisher information
Sep 12, 2019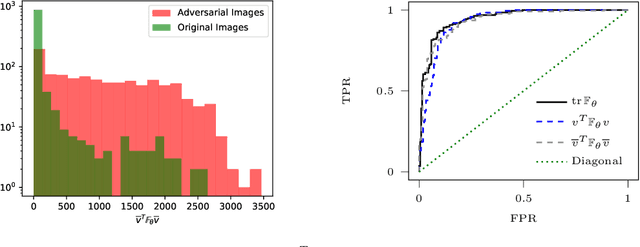

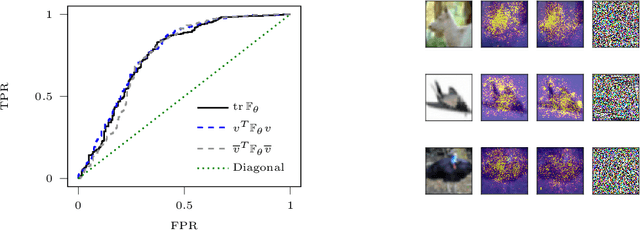
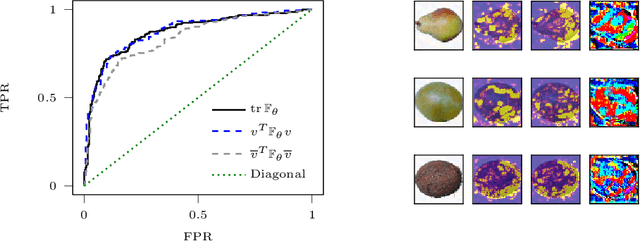
Adversarial examples are slight perturbations that are designed to fool artificial neural networks when fed as an input. In this work the usability of the Fisher information for the detection of such adversarial attacks is studied. We discuss various quantities whose computation scales well with the network size, study their behavior on adversarial examples and show how they can highlight the importance of single input neurons, thereby providing a visual tool for further analyzing (un-)reasonable behavior of a neural network. The potential of our methods is demonstrated by applications to the MNIST, CIFAR10 and Fruits-360 datasets.