 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative models and Bayesian inversion using Laplace approximation
Mar 15, 2022


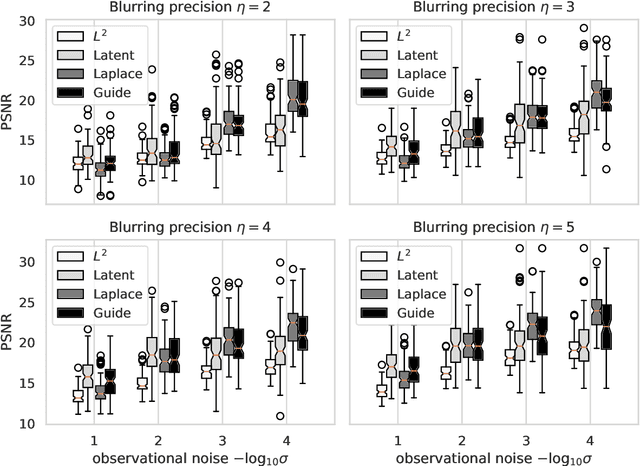
The Bayesian approach to solving inverse problems relies on the choice of a prior. This critical ingredient allows the formulation of expert knowledge or physical constraints in a probabilistic fashion and plays an important role for the success of the inference. Recently, Bayesian inverse problems were solved using generative models as highly informative priors. Generative models are a popular tool in machine learning to generate data whose properties closely resemble those of a given database. Typically, the generated distribution of data is embedded in a low-dimensional manifold. For the inverse problem, a generative model is trained on a database that reflects the properties of the sought solution, such as typical structures of the tissue in the human brain in magnetic resonance (MR) imaging. The inference is carried out in the low-dimensional manifold determined by the generative model which strongly reduces the dimensionality of the inverse problem. However, this proceeding produces a posterior that admits no Lebesgue density in the actual variables and the accuracy reached can strongly depend on the quality of the generative model. For linear Gaussian models we explore an alternative Bayesian inference based on probabilistic generative models which is carried out in the original high-dimensional space. A Laplace approximation is employed to analytically derive the required prior probability density function induced by the generative model. Properties of the resulting inference are investigated. Specifically, we show that derived Bayes estimates are consistent, in contrast to the approach employing the low-dimensional manifold of the generative model. The MNIST data set is used to construct numerical experiments which confirm our theoretical findings.
A framework for benchmarking uncertainty in deep regression
Sep 10, 2021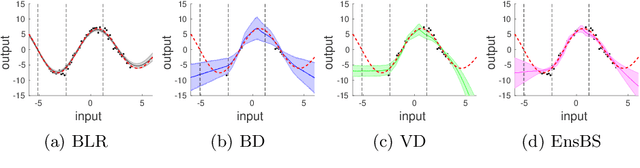
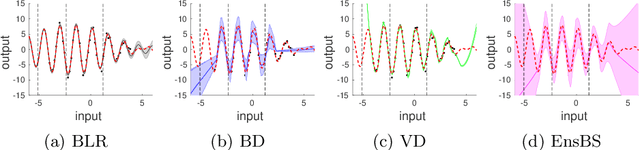
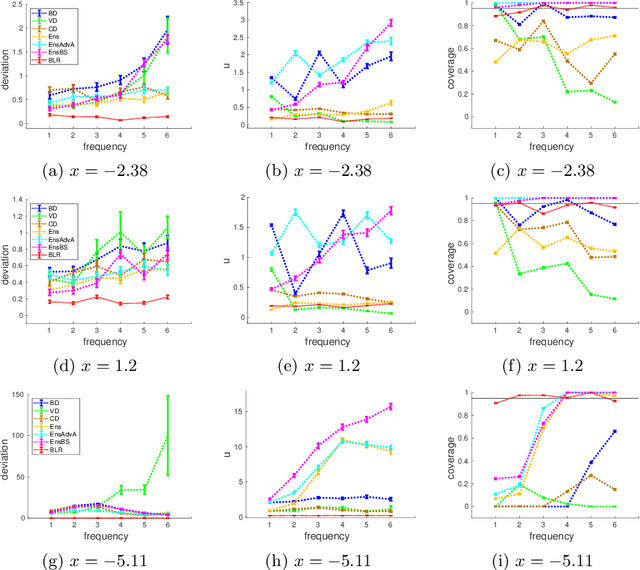
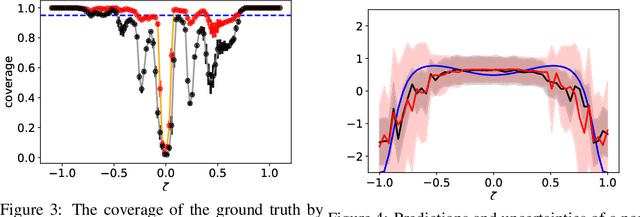
We propose a framework for the assessment of uncertainty quantification in deep regression. The framework is based on regression problems where the regression function is a linear combination of nonlinear functions. Basically, any level of complexity can be realized through the choice of the nonlinear functions and the dimensionality of their domain. Results of an uncertainty quantification for deep regression are compared against those obtained by a statistical reference method. The reference method utilizes knowledge of the underlying nonlinear functions and is based on a Bayesian linear regression using a reference prior. Reliability of uncertainty quantification is assessed in terms of coverage probabilities, and accuracy through the size of calculated uncertainties. We illustrate the proposed framework by applying it to current approaches for uncertainty quantification in deep regression. The flexibility, together with the availability of a reference solution, makes the framework suitable for defining benchmark sets for uncertainty quantification.
Deep Ensembles from a Bayesian Perspective
May 27, 2021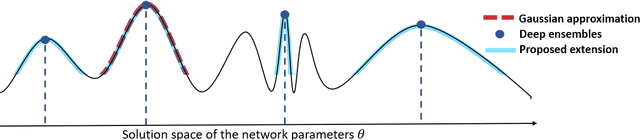
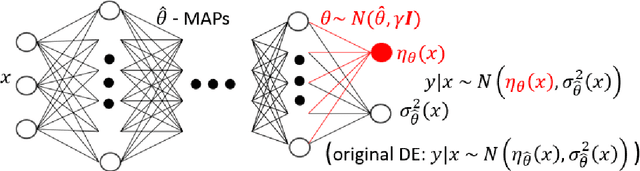
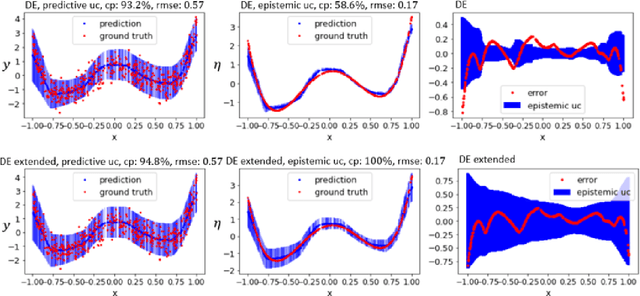
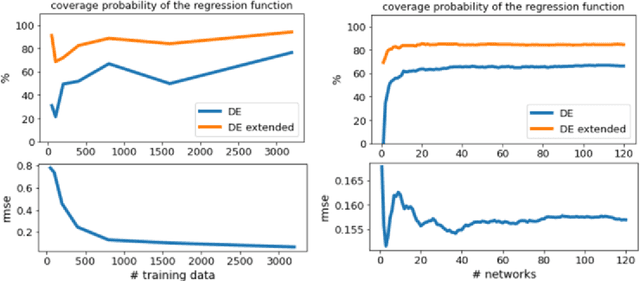
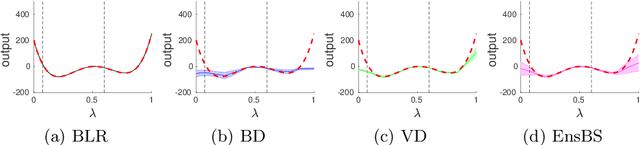
Deep ensembles can be seen as the current state-of-the-art for uncertainty quantification in deep learning. While the approach was originally proposed as an non-Bayesian technique, arguments towards its Bayesian footing have been put forward as well. We show that deep ensembles can be viewed as an approximate Bayesian method by specifying the corresponding assumptions. Our finding leads to an improved approximation which results in an increased epistemic part of the uncertainty. Numerical examples suggest that the improved approximation can lead to more reliable uncertainties. Analytical derivations ensure easy calculation of results.
Errors-in-Variables for deep learning: rethinking aleatoric uncertainty
May 27, 2021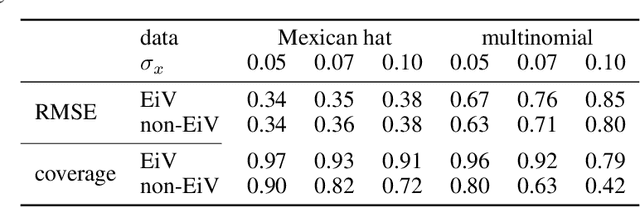
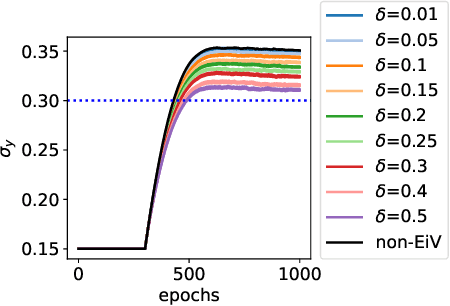
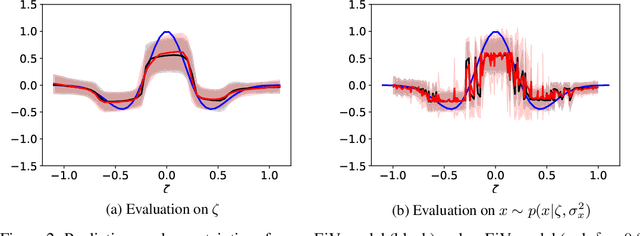
We present a Bayesian treatment for deep regression using an Errors-in-Variables model which accounts for the uncertainty associated with the input to the employed neural network. It is shown how the treatment can be combined with already existing approaches for uncertainty quantification that are based on variational inference. Our approach yields a decomposition of the predictive uncertainty into an aleatoric and epistemic part that is more complete and, in many cases, more consistent from a statistical perspective. We illustrate and discuss the approach along various toy and real world examples.
Uncertainty Quantification by Ensemble Learning for Computational Optical Form Measurements
Mar 01, 2021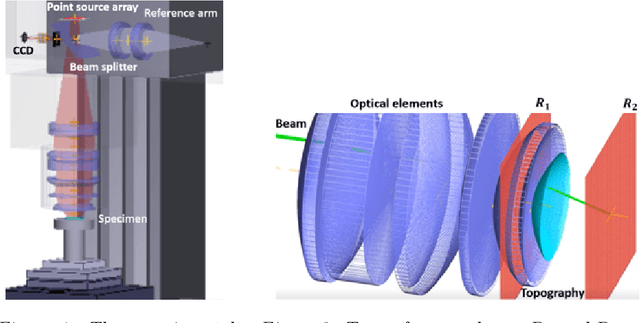
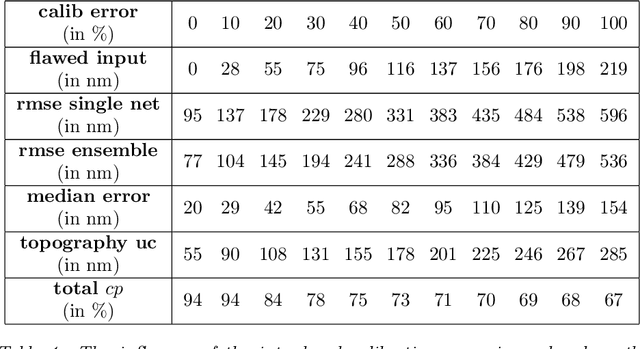
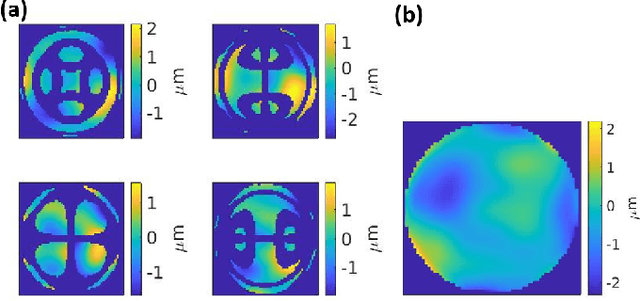
Uncertainty quantification by ensemble learning is explored in terms of an application from computational optical form measurements. The application requires to solve a large-scale, nonlinear inverse problem. Ensemble learning is used to extend a recently developed deep learning approach for this application in order to provide an uncertainty quantification of its predicted solution to the inverse problem. By systematically inserting out-of-distribution errors as well as noisy data the reliability of the developed uncertainty quantification is explored. Results are encouraging and the proposed application exemplifies the ability of ensemble methods to make trustworthy predictions on high dimensional data in a real-world application.
Deep Neural Networks for Computational Optical Form Measurements
Jul 01, 2020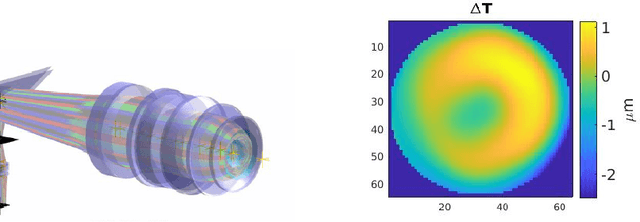
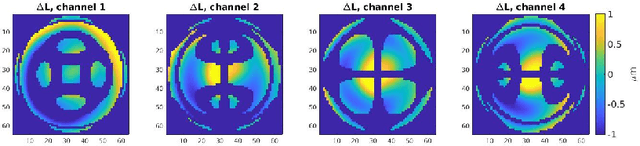
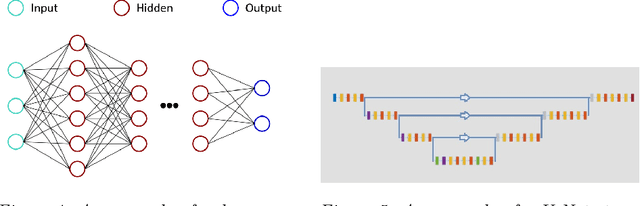
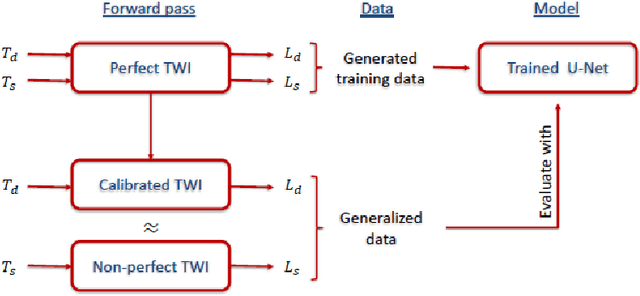
Deep neural networks have been successfully applied in many different fields like computational imaging, medical healthcare, signal processing, or autonomous driving. In a proof-of-principle study, we demonstrate that computational optical form measurement can also benefit from deep learning. A data-driven machine learning approach is explored to solve an inverse problem in the accurate measurement of optical surfaces. The approach is developed and tested using virtual measurements with known ground truth.
Detecting unusual input to neural networks
Jun 15, 2020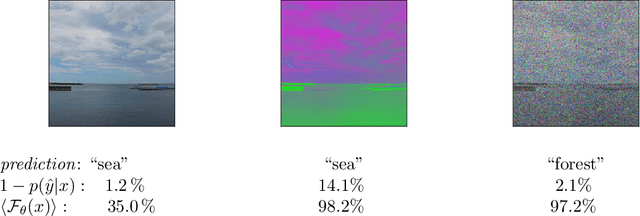
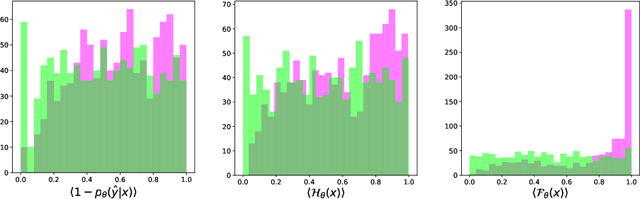
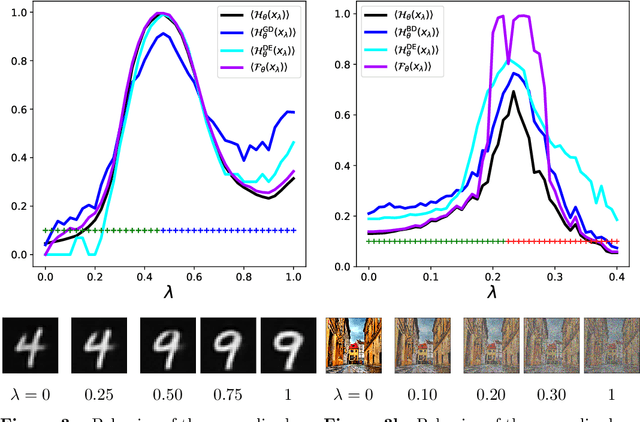
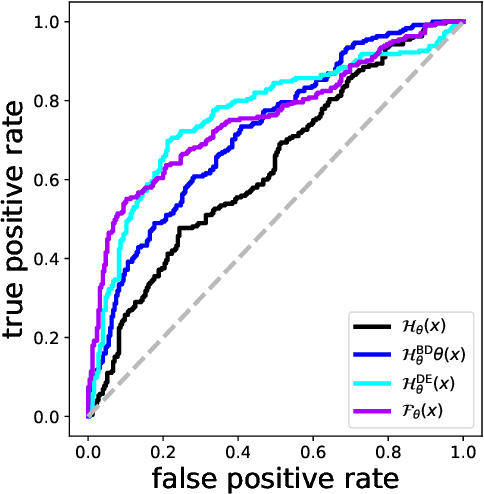
Evaluating a neural network on an input that differs markedly from the training data might cause erratic and flawed predictions. We study a method that judges the unusualness of an input by evaluating its informative content compared to the learned parameters. This technique can be used to judge whether a network is suitable for processing a certain input and to raise a red flag that unexpected behavior might lie ahead. We compare our approach to various methods for uncertainty evaluation from the literature for various datasets and scenarios. Specifically, we introduce a simple, effective method that allows to directly compare the output of such metrics for single input points even if these metrics live on different scales.
Inspecting adversarial examples using the Fisher information
Sep 12, 2019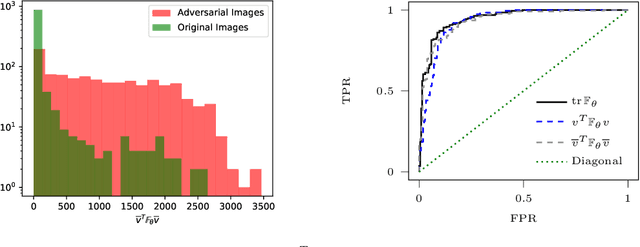

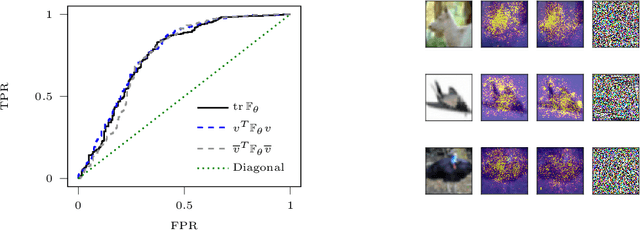
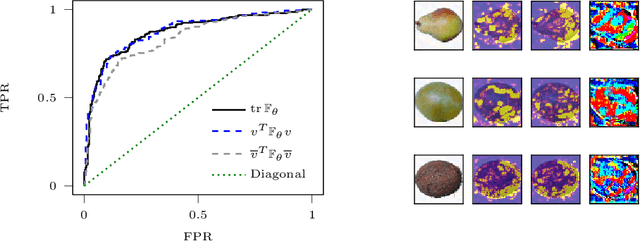
Adversarial examples are slight perturbations that are designed to fool artificial neural networks when fed as an input. In this work the usability of the Fisher information for the detection of such adversarial attacks is studied. We discuss various quantities whose computation scales well with the network size, study their behavior on adversarial examples and show how they can highlight the importance of single input neurons, thereby providing a visual tool for further analyzing (un-)reasonable behavior of a neural network. The potential of our methods is demonstrated by applications to the MNIST, CIFAR10 and Fruits-360 datasets.