 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Higher Order Kernel Mean Embeddings to Capture Filtrations of Stochastic Processes
Sep 29, 2021
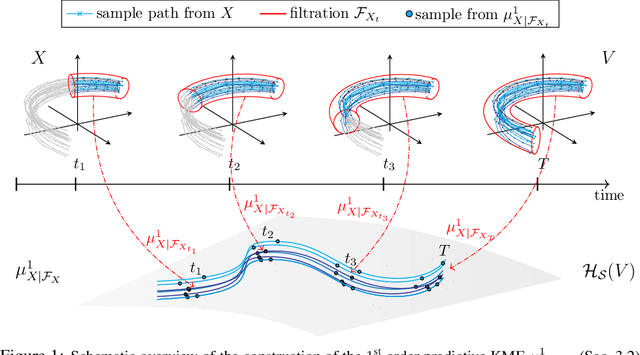


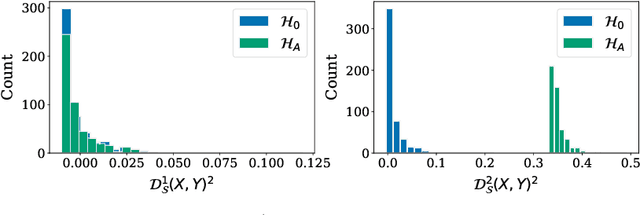
Stochastic processes are random variables with values in some space of paths. However, reducing a stochastic process to a path-valued random variable ignores its filtration, i.e. the flow of information carried by the process through time. By conditioning the process on its filtration, we introduce a family of higher order kernel mean embeddings (KMEs) that generalizes the notion of KME and captures additional information related to the filtration. We derive empirical estimators for the associated higher order maximum mean discrepancies (MMDs) and prove consistency. We then construct a filtration-sensitive kernel two-sample test able to pick up information that gets missed by the standard MMD test. In addition, leveraging our higher order MMDs we construct a family of universal kernels on stochastic processes that allows to solve real-world calibration and optimal stopping problems in quantitative finance (such as the pricing of American options) via classical kernel-based regression methods. Finally, adapting existing tests for conditional independence to the case of stochastic processes, we design a causal-discovery algorithm to recover the causal graph of structural dependencies among interacting bodies solely from observations of their multidimensional trajectories.
Learning to ignore: rethinking attention in CNNs
Nov 10, 2021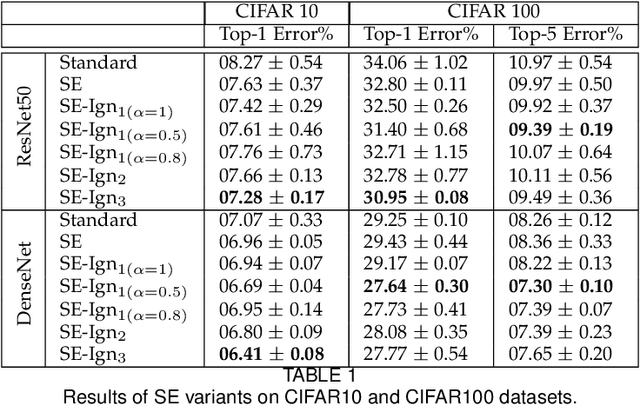
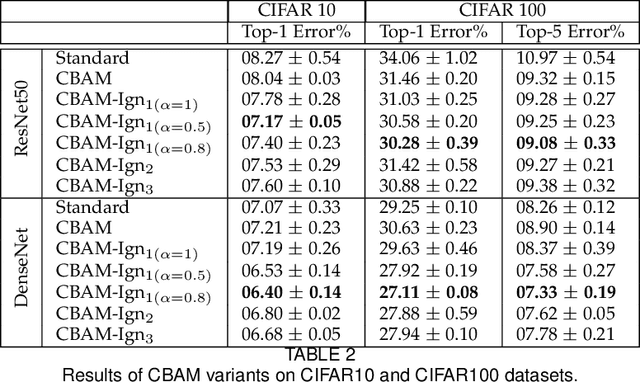
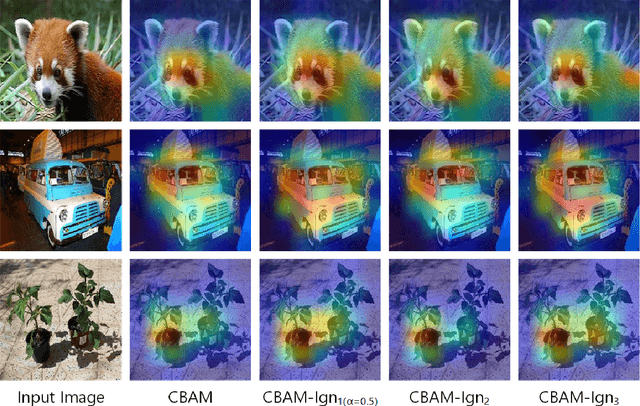
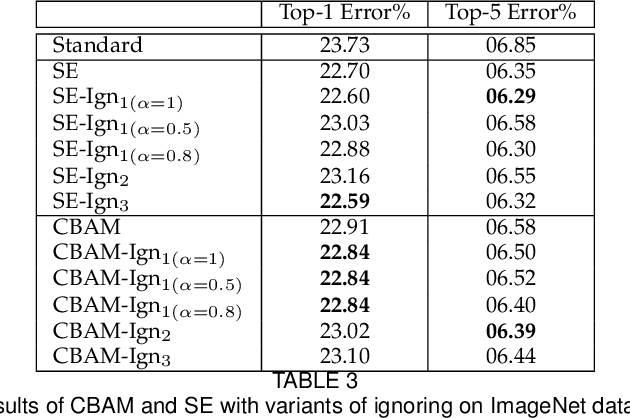
Recently, there has been an increasing interest in applying attention mechanisms in Convolutional Neural Networks (CNNs) to solve computer vision tasks. Most of these methods learn to explicitly identify and highlight relevant parts of the scene and pass the attended image to further layers of the network. In this paper, we argue that such an approach might not be optimal. Arguably, explicitly learning which parts of the image are relevant is typically harder than learning which parts of the image are less relevant and, thus, should be ignored. In fact, in vision domain, there are many easy-to-identify patterns of irrelevant features. For example, image regions close to the borders are less likely to contain useful information for a classification task. Based on this idea, we propose to reformulate the attention mechanism in CNNs to learn to ignore instead of learning to attend. Specifically, we propose to explicitly learn irrelevant information in the scene and suppress it in the produced representation, keeping only important attributes. This implicit attention scheme can be incorporated into any existing attention mechanism. In this work, we validate this idea using two recent attention methods Squeeze and Excitation (SE) block and Convolutional Block Attention Module (CBAM). Experimental results on different datasets and model architectures show that learning to ignore, i.e., implicit attention, yields superior performance compared to the standard approaches.
Human Parity on CommonsenseQA: Augmenting Self-Attention with External Attention
Dec 14, 2021
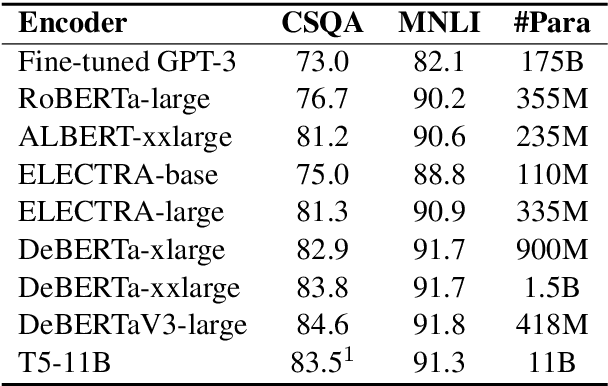
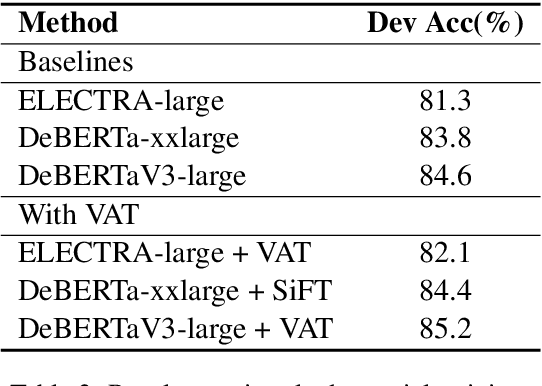

Most of today's AI systems focus on using self-attention mechanisms and transformer architectures on large amounts of diverse data to achieve impressive performance gains. In this paper, we propose to augment the transformer architecture with an external attention mechanism to bring external knowledge and context to bear. By integrating external information into the prediction process, we hope to reduce the need for ever-larger models and increase the democratization of AI systems. We find that the proposed external attention mechanism can significantly improve the performance of existing AI systems, allowing practitioners to easily customize foundation AI models to many diverse downstream applications. In particular, we focus on the task of Commonsense Reasoning, demonstrating that the proposed external attention mechanism can augment existing transformer models and significantly improve the model's reasoning capabilities. The proposed system, Knowledgeable External Attention for commonsense Reasoning (KEAR), reaches human parity on the open CommonsenseQA research benchmark with an accuracy of 89.4\% in comparison to the human accuracy of 88.9\%.
Understanding Autoencoders with Information Theoretic Concepts
Aug 23, 2018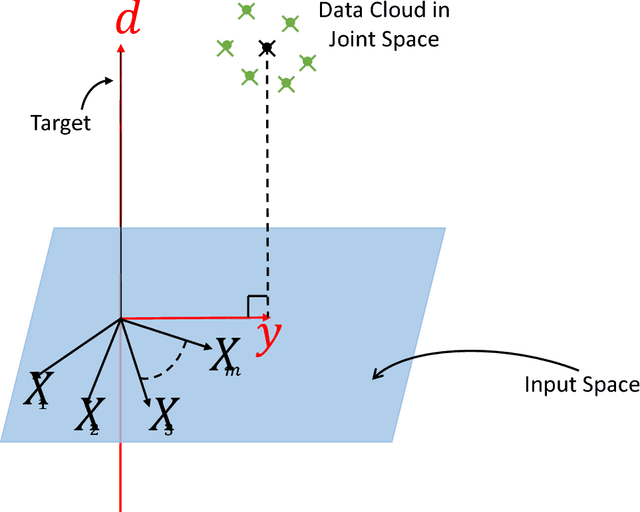
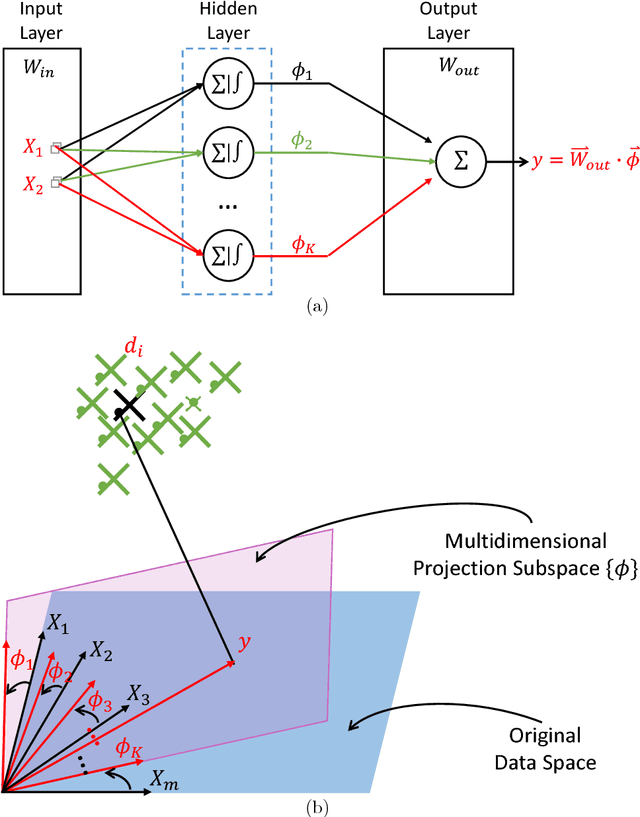
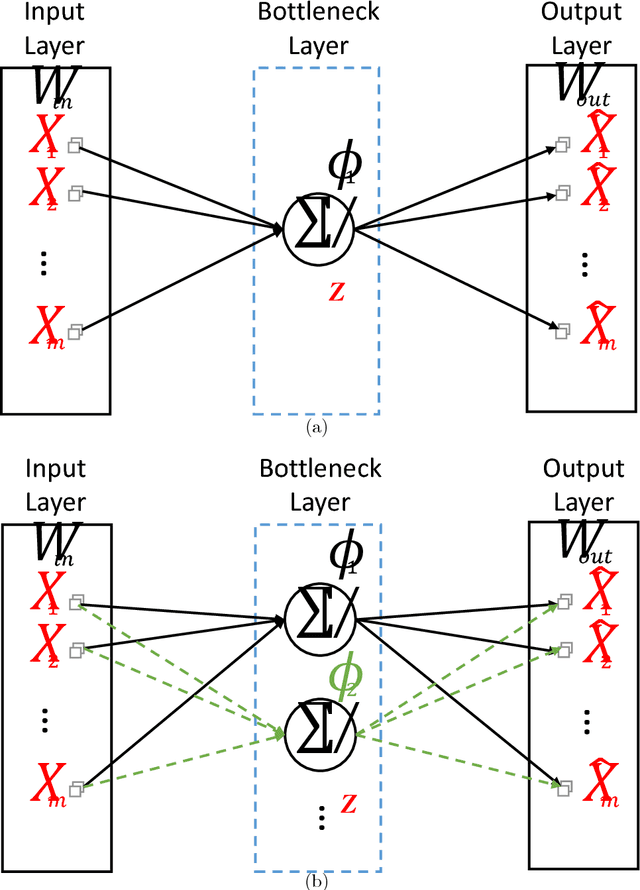
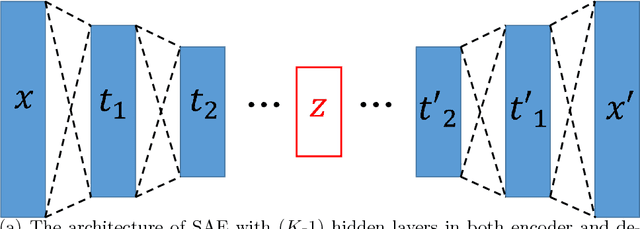
Despite their great success in practical applications, there is still a lack of theoretical and systematic methods to analyze deep neural networks. In this paper, we illustrate an advanced information theoretic methodology to understand the dynamics of learning and the design of autoencoders, a special type of deep learning architectures that resembles a communication channel. By generalizing the information plane to any cost function, and inspecting the roles and dynamics of different layers using layer-wise information quantities, we emphasize the role that mutual information plays in quantifying learning from data. We further suggest and also experimentally validate, for mean square error training, three fundamental properties regarding the layer-wise flow of information and intrinsic dimensionality of the bottleneck layer, using respectively the data processing inequality and the identification of a bifurcation point in the information plane that is controlled by the given data. Our observations have direct impact on the optimal design of autoencoders, the design of alternative feedforward training methods, and even in the problem of generalization.
FOMO: Topics versus documents in legal eDiscovery
Sep 16, 2021
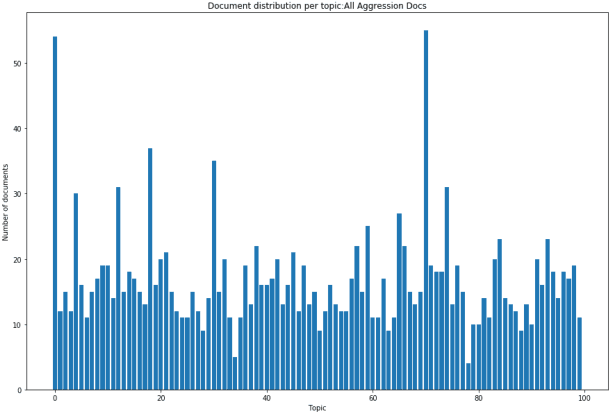
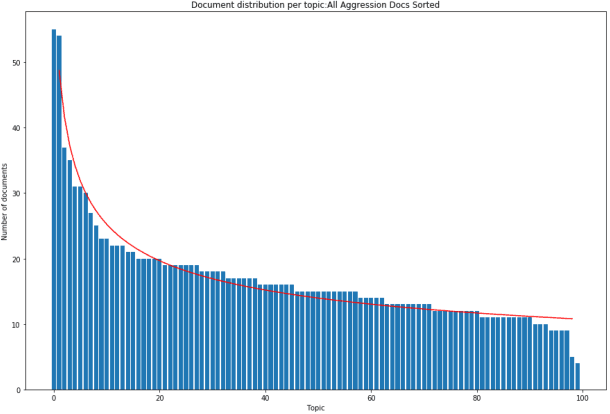
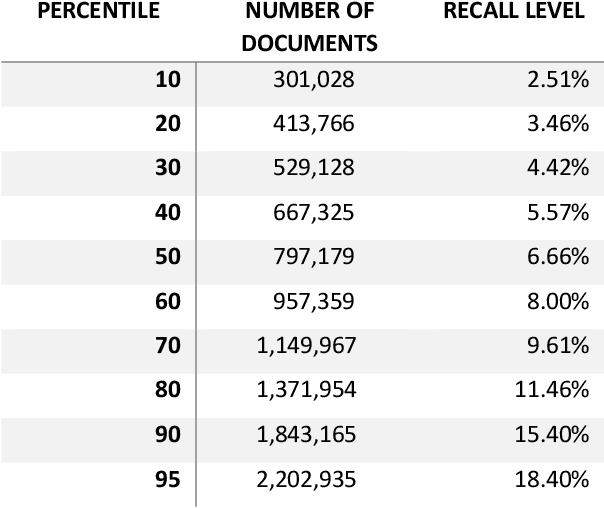
In the United States, the parties to a lawsuit are required to search through their electronically stored information to find documents that are relevant to the specific case and produce them to their opposing party. Negotiations over the scope of these searches often reflect a fear that something will be missed (Fear of Missing Out: FOMO). A Recall level of 80%, for example, means that 20% of the relevant documents will be left unproduced. This paper makes the argument that eDiscovery is the process of identifying responsive information, not identifying documents. Documents are the carriers of the information; they are not the direct targets of the process. A given document may contain one or more topics or factoids and a factoid may appear in more than one document. The coupon collector's problem, Heaps law, and other analyses provide ways to model the problem of finding information from among documents. In eDiscovery, however, the parties do not know how many factoids there might be in a collection or their probabilities. This paper describes a simple model that estimates the confidence that a fact will be omitted from the produced set (the identified set), while being contained in the missed set. Two data sets are then analyzed, a small set involving microaggressions and larger set involving classification of web pages. Both show that it is possible to discover at least one example of each available topic within a relatively small number of documents, meaning the further effort will not return additional novel information. The smaller data set is also used to investigate whether the non-random order of searching for responsive documents commonly used in eDiscovery (called continuous active learning) affects the distribution of topics-it does not.
MDPose: Human Skeletal Motion Reconstruction Using WiFi Micro-Doppler Signatures
Jan 11, 2022
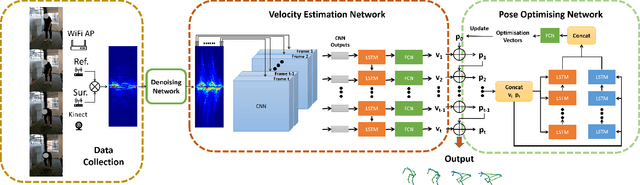

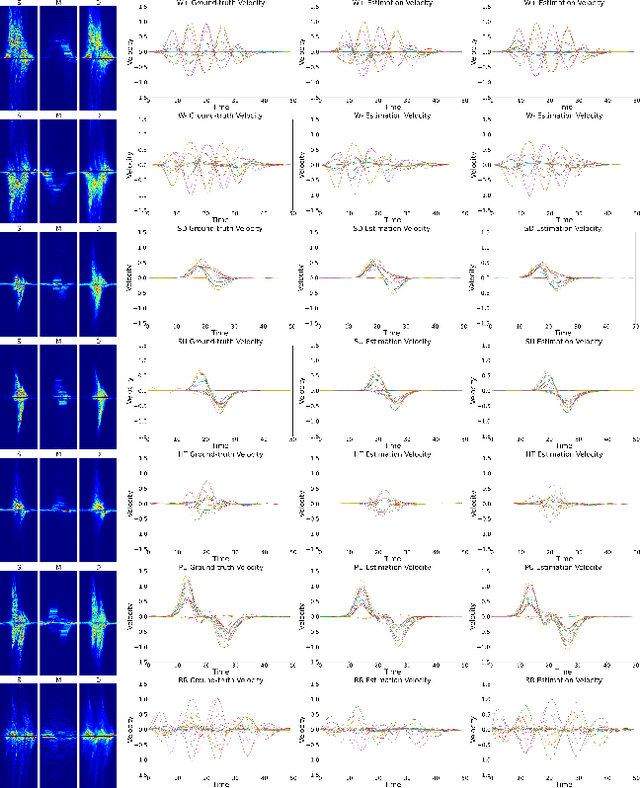
Motion tracking systems based on optical sensors typically often suffer from issues, such as poor lighting conditions, occlusion, limited coverage, and may raise privacy concerns. More recently, radio frequency (RF)-based approaches using commercial WiFi devices have emerged which offer low-cost ubiquitous sensing whilst preserving privacy. However, the output of an RF sensing system, such as Range-Doppler spectrograms, cannot represent human motion intuitively and usually requires further processing. In this study, MDPose, a novel framework for human skeletal motion reconstruction based on WiFi micro-Doppler signatures, is proposed. It provides an effective solution to track human activities by reconstructing a skeleton model with 17 key points, which can assist with the interpretation of conventional RF sensing outputs in a more understandable way. Specifically, MDPose has various incremental stages to gradually address a series of challenges: First, a denoising algorithm is implemented to remove any unwanted noise that may affect the feature extraction and enhance weak Doppler signatures. Secondly, the convolutional neural network (CNN)-recurrent neural network (RNN) architecture is applied to learn temporal-spatial dependency from clean micro-Doppler signatures and restore key points' velocity information. Finally, a pose optimising mechanism is employed to estimate the initial state of the skeleton and to limit the increase of error. We have conducted comprehensive tests in a variety of environments using numerous subjects with a single receiver radar system to demonstrate the performance of MDPose, and report 29.4mm mean absolute error over all key points positions, which outperforms state-of-the-art RF-based pose estimation systems.
Adaptive Beamwidth Configuration for Millimeter Wave V2X Scheduling
Dec 14, 2021
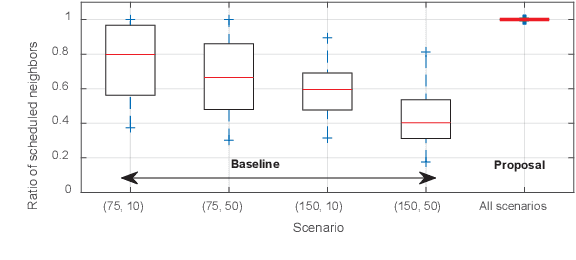
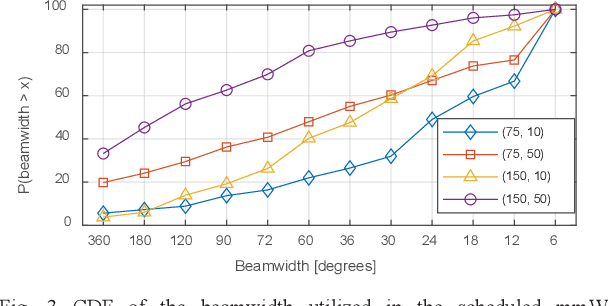
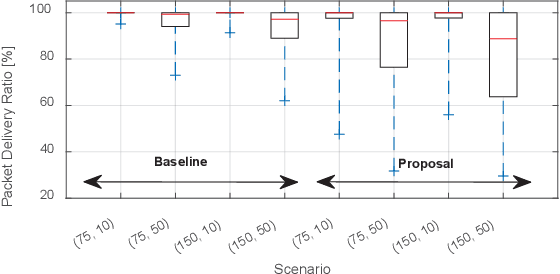
Millimeter wave (mmWave) technologies will support the high bandwidth and data rate requirements of V2X services demanded by connected and automated vehicles (CAVs). MmWave V2X technologies will leverage directional antennas that challenge the management of the communications in dynamic scenarios including the identification of available links, beams alignment, and scheduling. Previous studies have shown that these challenges can be reduced when mmWave communications are supported by side information like the one transmitted in sub-6GHz V2X technologies. In this context, this paper proposes a beamwidth-aware mmWave scheduling scheme for V2V communications supported by sub-6GHz V2X technologies. The proposal enables mmWave transmitters to schedule a mmWave transmission to several neighboring vehicles at the same time by adapting the beamwidth configuration. In addition, the proposal derives the minimum beamwidth that mmWave transmitters should use to contact their neighboring vehicles in a limited number of scheduling intervals. The obtained results demonstrate that the proposal helps increasing the amount of mmWave data that can be transmitted to neighboring vehicles.
* 4 pages, 4 figures, 1 table
PANet: Perspective-Aware Network with Dynamic Receptive Fields and Self-Distilling Supervision for Crowd Counting
Oct 31, 2021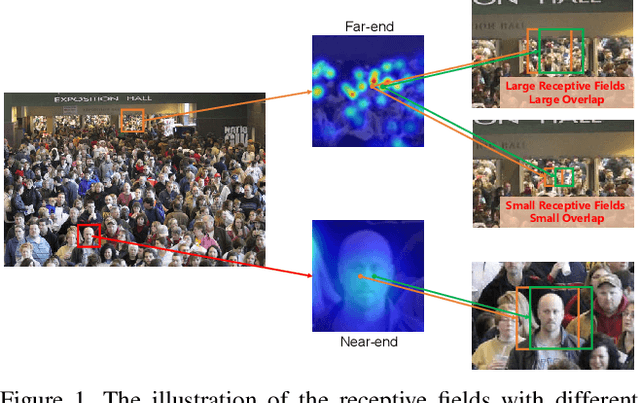
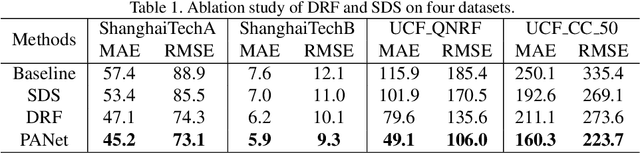
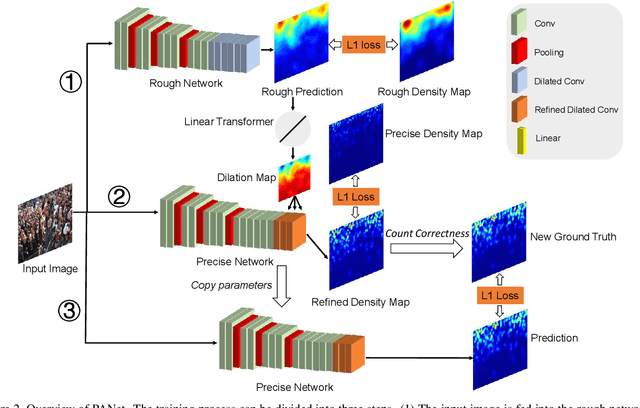

Crowd counting aims to learn the crowd density distributions and estimate the number of objects (e.g. persons) in images. The perspective effect, which significantly influences the distribution of data points, plays an important role in crowd counting. In this paper, we propose a novel perspective-aware approach called PANet to address the perspective problem. Based on the observation that the size of the objects varies greatly in one image due to the perspective effect, we propose the dynamic receptive fields (DRF) framework. The framework is able to adjust the receptive field by the dilated convolution parameters according to the input image, which helps the model to extract more discriminative features for each local region. Different from most previous works which use Gaussian kernels to generate the density map as the supervised information, we propose the self-distilling supervision (SDS) training method. The ground-truth density maps are refined from the first training stage and the perspective information is distilled to the model in the second stage. The experimental results on ShanghaiTech Part_A and Part_B, UCF_QNRF, and UCF_CC_50 datasets demonstrate that our proposed PANet outperforms the state-of-the-art methods by a large margin.
Neural Medication Extraction: A Comparison of Recent Models in Supervised and Semi-supervised Learning Settings
Oct 19, 2021

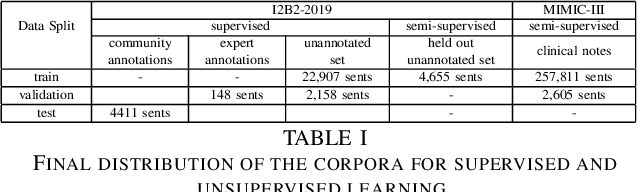
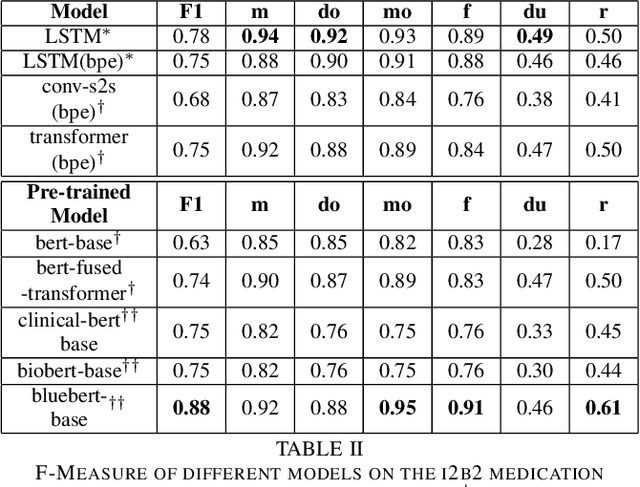
Drug prescriptions are essential information that must be encoded in electronic medical records. However, much of this information is hidden within free-text reports. This is why the medication extraction task has emerged. To date, most of the research effort has focused on small amount of data and has only recently considered deep learning methods. In this paper, we present an independent and comprehensive evaluation of state-of-the-art neural architectures on the I2B2 medical prescription extraction task both in the supervised and semi-supervised settings. The study shows the very competitive performance of simple DNN models on the task as well as the high interest of pre-trained models. Adapting the latter models on the I2B2 dataset enables to push medication extraction performances above the state-of-the-art. Finally, the study also confirms that semi-supervised techniques are promising to leverage large amounts of unlabeled data in particular in low resource setting when labeled data is too costly to acquire.
SegDiff: Image Segmentation with Diffusion Probabilistic Models
Dec 01, 2021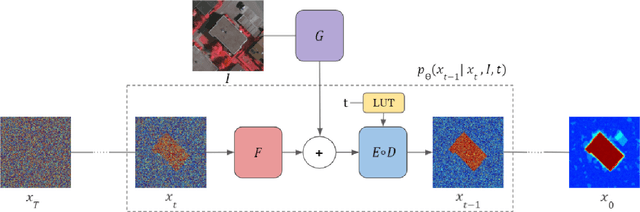
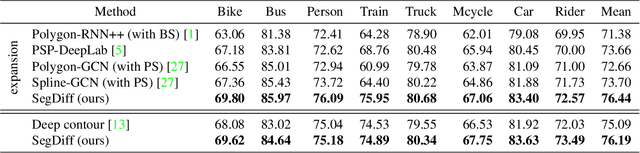

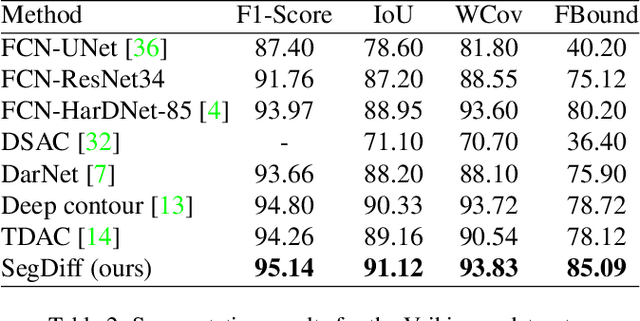
Diffusion Probabilistic Methods are employed for state-of-the-art image generation. In this work, we present a method for extending such models for performing image segmentation. The method learns end-to-end, without relying on a pre-trained backbone. The information in the input image and in the current estimation of the segmentation map is merged by summing the output of two encoders. Additional encoding layers and a decoder are then used to iteratively refine the segmentation map using a diffusion model. Since the diffusion model is probabilistic, it is applied multiple times and the results are merged into a final segmentation map. The new method obtains state-of-the-art results on the Cityscapes validation set, the Vaihingen building segmentation benchmark, and the MoNuSeg dataset.