 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSome things to know about achieving artificial general intelligence
Feb 10, 2025Current and foreseeable GenAI models are not capable of achieving artificial general intelligence because they are burdened with anthropogenic debt. They depend heavily on human input to provide well-structured problems, architecture, and training data. They cast every problem as a language pattern learning problem and are thus not capable of the kind of autonomy needed to achieve artificial general intelligence. Current models succeed at their tasks because people solve most of the problems to which these models are directed, leaving only simple computations for the model to perform, such as gradient descent. Another barrier is the need to recognize that there are multiple kinds of problems, some of which cannot be solved by available computational methods (for example, "insight problems"). Current methods for evaluating models (benchmarks and tests) are not adequate to identify the generality of the solutions, because it is impossible to infer the means by which a problem was solved from the fact of its solution. A test could be passed, for example, by a test-specific or a test-general method. It is a logical fallacy (affirming the consequent) to infer a method of solution from the observation of success.
FOMO: Topics versus documents in legal eDiscovery
Sep 16, 2021
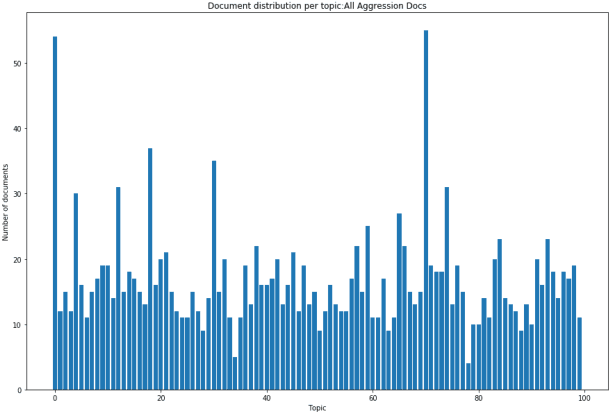
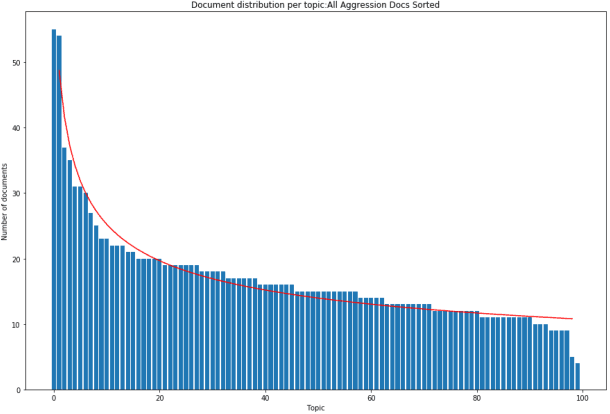
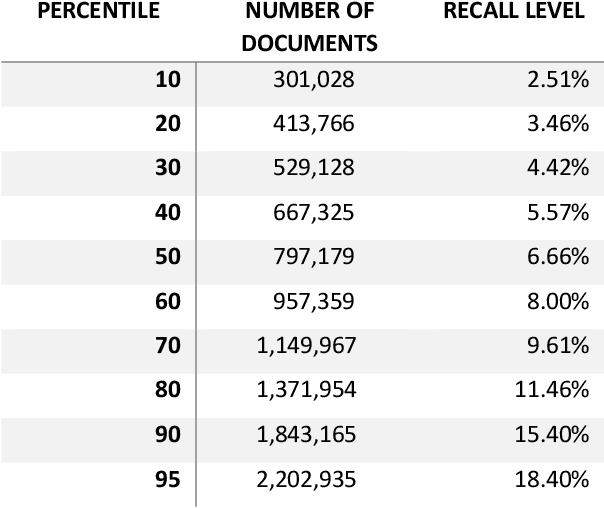
In the United States, the parties to a lawsuit are required to search through their electronically stored information to find documents that are relevant to the specific case and produce them to their opposing party. Negotiations over the scope of these searches often reflect a fear that something will be missed (Fear of Missing Out: FOMO). A Recall level of 80%, for example, means that 20% of the relevant documents will be left unproduced. This paper makes the argument that eDiscovery is the process of identifying responsive information, not identifying documents. Documents are the carriers of the information; they are not the direct targets of the process. A given document may contain one or more topics or factoids and a factoid may appear in more than one document. The coupon collector's problem, Heaps law, and other analyses provide ways to model the problem of finding information from among documents. In eDiscovery, however, the parties do not know how many factoids there might be in a collection or their probabilities. This paper describes a simple model that estimates the confidence that a fact will be omitted from the produced set (the identified set), while being contained in the missed set. Two data sets are then analyzed, a small set involving microaggressions and larger set involving classification of web pages. Both show that it is possible to discover at least one example of each available topic within a relatively small number of documents, meaning the further effort will not return additional novel information. The smaller data set is also used to investigate whether the non-random order of searching for responsive documents commonly used in eDiscovery (called continuous active learning) affects the distribution of topics-it does not.