 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Recurrence along Depth: Deep Convolutional Neural Networks with Recurrent Layer Aggregation
Oct 22, 2021
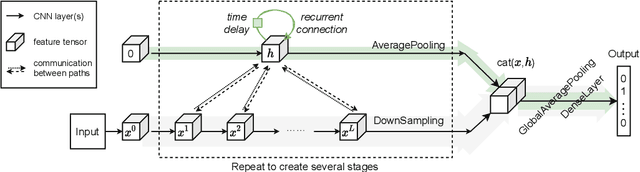
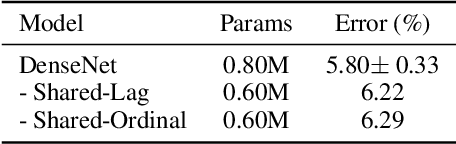
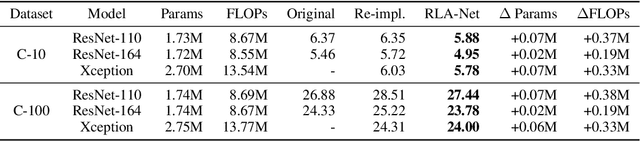
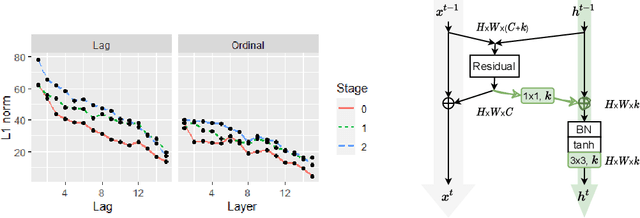
This paper introduces a concept of layer aggregation to describe how information from previous layers can be reused to better extract features at the current layer. While DenseNet is a typical example of the layer aggregation mechanism, its redundancy has been commonly criticized in the literature. This motivates us to propose a very light-weighted module, called recurrent layer aggregation (RLA), by making use of the sequential structure of layers in a deep CNN. Our RLA module is compatible with many mainstream deep CNNs, including ResNets, Xception and MobileNetV2, and its effectiveness is verified by our extensive experiments on image classification, object detection and instance segmentation tasks. Specifically, improvements can be uniformly observed on CIFAR, ImageNet and MS COCO datasets, and the corresponding RLA-Nets can surprisingly boost the performances by 2-3% on the object detection task. This evidences the power of our RLA module in helping main CNNs better learn structural information in images.
3D Siamese Voxel-to-BEV Tracker for Sparse Point Clouds
Nov 17, 2021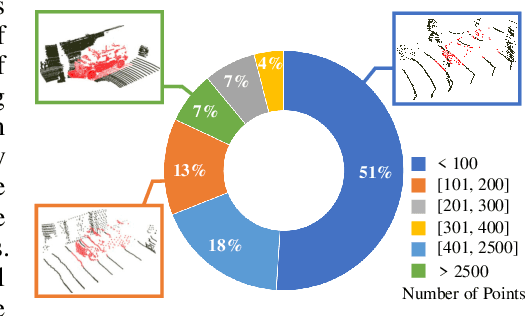
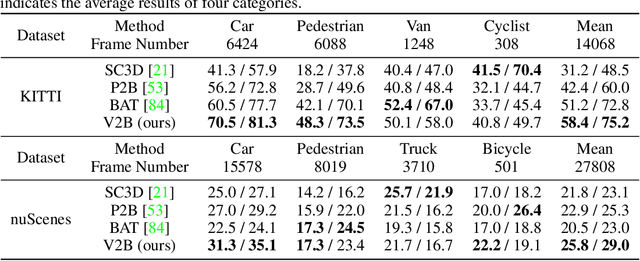
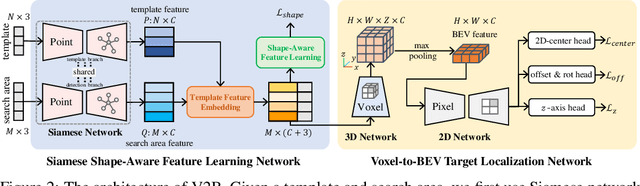
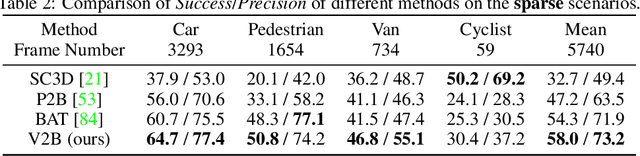
3D object tracking in point clouds is still a challenging problem due to the sparsity of LiDAR points in dynamic environments. In this work, we propose a Siamese voxel-to-BEV tracker, which can significantly improve the tracking performance in sparse 3D point clouds. Specifically, it consists of a Siamese shape-aware feature learning network and a voxel-to-BEV target localization network. The Siamese shape-aware feature learning network can capture 3D shape information of the object to learn the discriminative features of the object so that the potential target from the background in sparse point clouds can be identified. To this end, we first perform template feature embedding to embed the template's feature into the potential target and then generate a dense 3D shape to characterize the shape information of the potential target. For localizing the tracked target, the voxel-to-BEV target localization network regresses the target's 2D center and the $z$-axis center from the dense bird's eye view (BEV) feature map in an anchor-free manner. Concretely, we compress the voxelized point cloud along $z$-axis through max pooling to obtain a dense BEV feature map, where the regression of the 2D center and the $z$-axis center can be performed more effectively. Extensive evaluation on the KITTI and nuScenes datasets shows that our method significantly outperforms the current state-of-the-art methods by a large margin.
Skeleton-Based Mutually Assisted Interacted Object Localization and Human Action Recognition
Oct 28, 2021
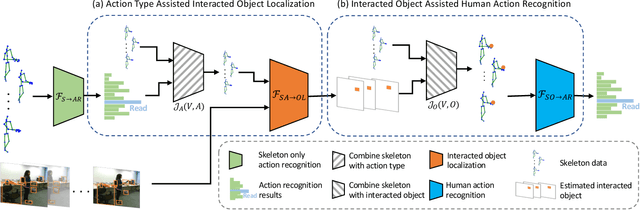

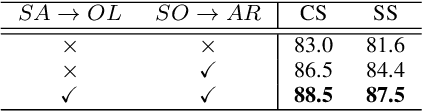
Skeleton data carries valuable motion information and is widely explored in human action recognition. However, not only the motion information but also the interaction with the environment provides discriminative cues to recognize the action of persons. In this paper, we propose a joint learning framework for mutually assisted "interacted object localization" and "human action recognition" based on skeleton data. The two tasks are serialized together and collaborate to promote each other, where preliminary action type derived from skeleton alone helps improve interacted object localization, which in turn provides valuable cues for the final human action recognition. Besides, we explore the temporal consistency of interacted object as constraint to better localize the interacted object with the absence of ground-truth labels. Extensive experiments on the datasets of SYSU-3D, NTU60 RGB+D and Northwestern-UCLA show that our method achieves the best or competitive performance with the state-of-the-art methods for human action recognition. Visualization results show that our method can also provide reasonable interacted object localization results.
Image denoising by Super Neurons: Why go deep?
Nov 29, 2021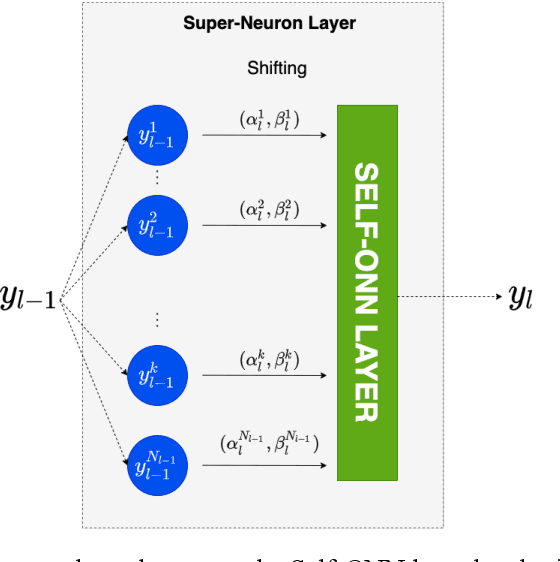

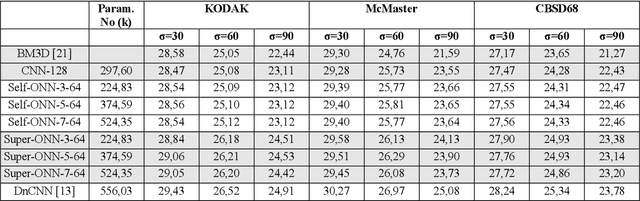
Classical image denoising methods utilize the non-local self-similarity principle to effectively recover image content from noisy images. Current state-of-the-art methods use deep convolutional neural networks (CNNs) to effectively learn the mapping from noisy to clean images. Deep denoising CNNs manifest a high learning capacity and integrate non-local information owing to the large receptive field yielded by numerous cascade of hidden layers. However, deep networks are also computationally complex and require large data for training. To address these issues, this study draws the focus on the Self-organized Operational Neural Networks (Self-ONNs) empowered by a novel neuron model that can achieve a similar or better denoising performance with a compact and shallow model. Recently, the concept of super-neurons has been introduced which augment the non-linear transformations of generative neurons by utilizing non-localized kernel locations for an enhanced receptive field size. This is the key accomplishment which renders the need for a deep network configuration. As the integration of non-local information is known to benefit denoising, in this work we investigate the use of super neurons for both synthetic and real-world image denoising. We also discuss the practical issues in implementing the super neuron model on GPUs and propose a trade-off between the heterogeneity of non-localized operations and computational complexity. Our results demonstrate that with the same width and depth, Self-ONNs with super neurons provide a significant boost of denoising performance over the networks with generative and convolutional neurons for both denoising tasks. Moreover, results demonstrate that Self-ONNs with super neurons can achieve a competitive and superior synthetic denoising performances than well-known deep CNN denoisers for synthetic and real-world denoising, respectively.
Boosted GAN with Semantically Interpretable Information for Image Inpainting
Aug 13, 2019
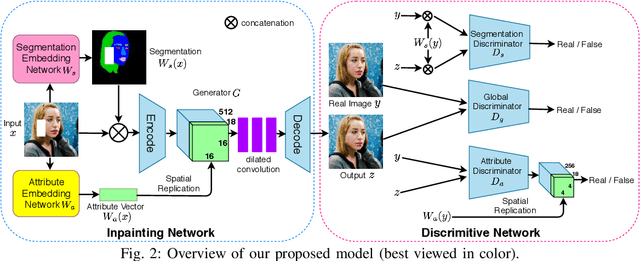


Image inpainting aims at restoring missing region of corrupted images, which has many applications such as image restoration and object removal. However, current GAN-based inpainting models fail to explicitly consider the semantic consistency between restored images and original images. Forexample, given a male image with image region of one eye missing, current models may restore it with a female eye. This is due to the ambiguity of GAN-based inpainting models: these models can generate many possible restorations given a missing region. To address this limitation, our key insight is that semantically interpretable information (such as attribute and segmentation information) of input images (with missing regions) can provide essential guidance for the inpainting process. Based on this insight, we propose a boosted GAN with semantically interpretable information for image inpainting that consists of an inpainting network and a discriminative network. The inpainting network utilizes two auxiliary pretrained networks to discover the attribute and segmentation information of input images and incorporates them into the inpainting process to provide explicit semantic-level guidance. The discriminative network adopts a multi-level design that can enforce regularizations not only on overall realness but also on attribute and segmentation consistency with the original images. Experimental results show that our proposed model can preserve consistency on both attribute and segmentation level, and significantly outperforms the state-of-the-art models.
EFENet: Reference-based Video Super-Resolution with Enhanced Flow Estimation
Oct 28, 2021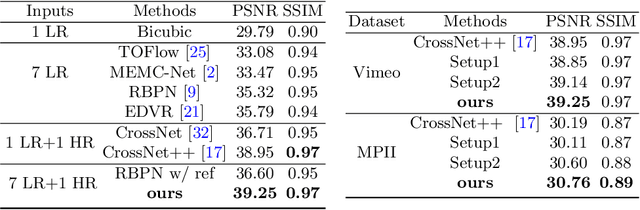
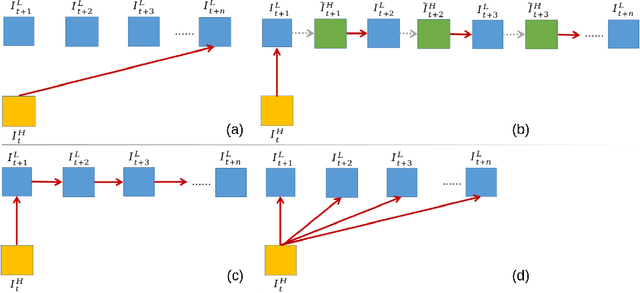

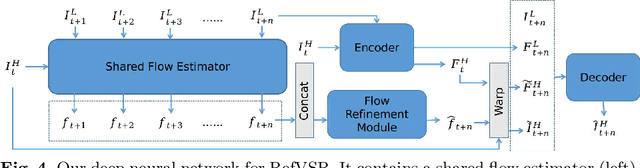
In this paper, we consider the problem of reference-based video super-resolution(RefVSR), i.e., how to utilize a high-resolution (HR) reference frame to super-resolve a low-resolution (LR) video sequence. The existing approaches to RefVSR essentially attempt to align the reference and the input sequence, in the presence of resolution gap and long temporal range. However, they either ignore temporal structure within the input sequence, or suffer accumulative alignment errors. To address these issues, we propose EFENet to exploit simultaneously the visual cues contained in the HR reference and the temporal information contained in the LR sequence. EFENet first globally estimates cross-scale flow between the reference and each LR frame. Then our novel flow refinement module of EFENet refines the flow regarding the furthest frame using all the estimated flows, which leverages the global temporal information within the sequence and therefore effectively reduces the alignment errors. We provide comprehensive evaluations to validate the strengths of our approach, and to demonstrate that the proposed framework outperforms the state-of-the-art methods. Code is available at https://github.com/IndigoPurple/EFENet.
Topic Aware Contextualized Embeddings for High Quality Phrase Extraction
Jan 17, 2022Keyphrase extraction from a given document is the task of automatically extracting salient phrases that best describe the document. This paper proposes a novel unsupervised graph-based ranking method to extract high-quality phrases from a given document. We obtain the contextualized embeddings from pre-trained language models enriched with topic vectors from Latent Dirichlet Allocation (LDA) to represent the candidate phrases and the document. We introduce a scoring mechanism for the phrases using the information obtained from contextualized embeddings and the topic vectors. The salient phrases are extracted using a ranking algorithm on an undirected graph constructed for the given document. In the undirected graph, the nodes represent the phrases, and the edges between the phrases represent the semantic relatedness between them, weighted by a score obtained from the scoring mechanism. To demonstrate the efficacy of our proposed method, we perform several experiments on open source datasets in the science domain and observe that our novel method outperforms existing unsupervised embedding based keyphrase extraction methods. For instance, on the SemEval2017 dataset, our method advances the F1 score from 0.2195 (EmbedRank) to 0.2819 at the top 10 extracted keyphrases. Several variants of the proposed algorithm are investigated to determine their effect on the quality of keyphrases. We further demonstrate the ability of our proposed method to collect additional high-quality keyphrases that are not present in the document from external knowledge bases like Wikipedia for enriching the document with newly discovered keyphrases. We evaluate this step on a collection of annotated documents. The F1-score at the top 10 expanded keyphrases is 0.60, indicating that our algorithm can also be used for 'concept' expansion using external knowledge.
Improving Pneumonia Localization via Cross-Attention on Medical Images and Reports
Oct 06, 2021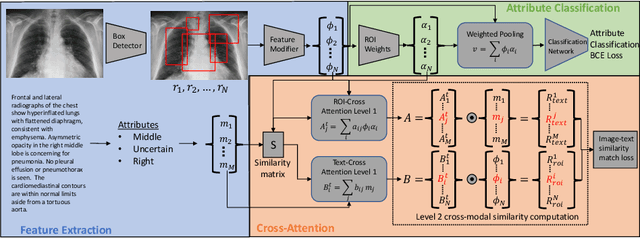
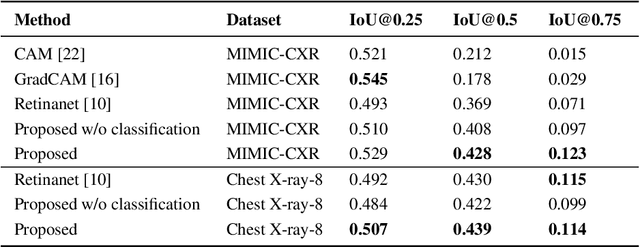
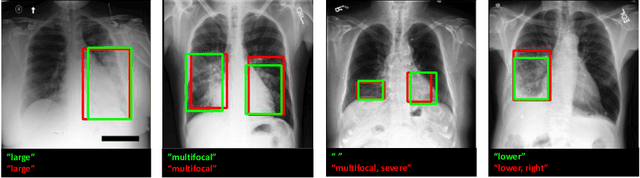

Localization and characterization of diseases like pneumonia are primary steps in a clinical pipeline, facilitating detailed clinical diagnosis and subsequent treatment planning. Additionally, such location annotated datasets can provide a pathway for deep learning models to be used for downstream tasks. However, acquiring quality annotations is expensive on human resources and usually requires domain expertise. On the other hand, medical reports contain a plethora of information both about pneumonia characteristics and its location. In this paper, we propose a novel weakly-supervised attention-driven deep learning model that leverages encoded information in medical reports during training to facilitate better localization. Our model also performs classification of attributes that are associated to pneumonia and extracted from medical reports for supervision. Both the classification and localization are trained in conjunction and once trained, the model can be utilized for both the localization and characterization of pneumonia using only the input image. In this paper, we explore and analyze the model using chest X-ray datasets and demonstrate qualitatively and quantitatively that the introduction of textual information improves pneumonia localization. We showcase quantitative results on two datasets, MIMIC-CXR and Chest X-ray-8, and we also showcase severity characterization on the COVID-19 dataset.
Asymptotic Finite Sample Information Losses in Neural Classifiers
Feb 15, 2019
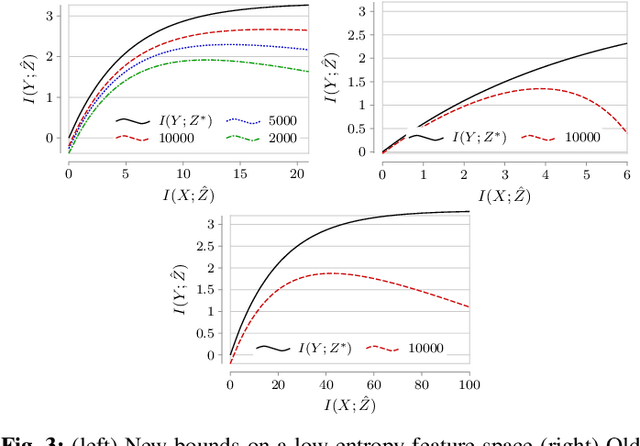
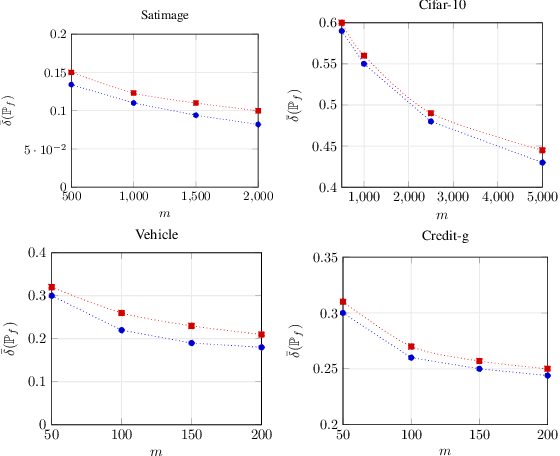
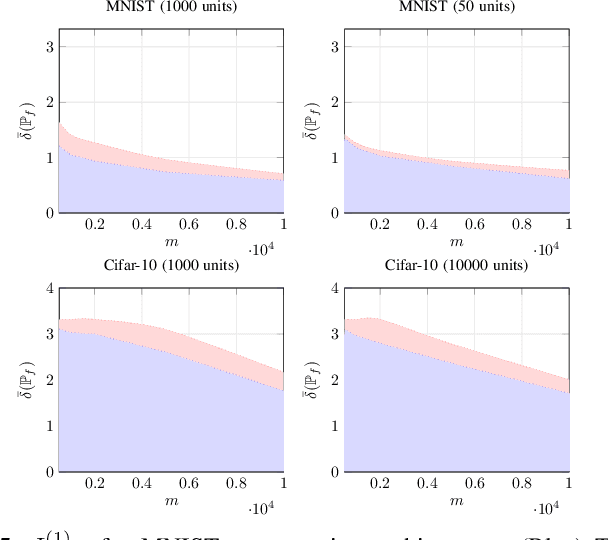
This paper considers the subject of information losses arising from finite datasets used in the training of neural classifiers. It proves a relationship between such losses and the product of the expected total variation of the estimated neural model with the information about the feature space contained in the hidden representation of that model. It then shows that this total variation drops extremely quickly with sample size. It ultimately obtains bounds on information losses that are less sensitive to input compression and much tighter than existing bounds. This brings about a tighter relevance of information theory to the training of neural networks, so a review of techniques for information estimation and control is provided. The paper then explains some potential uses of these bounds in the field of active learning, and then uses them to explain some recent experimental findings of information compression in neural networks which cannot be explained by previous work. It then uses the bounds to justify an information regularization term in the training of neural networks for low entropy feature space problems. Finally, the paper shows that, not only are these bounds much tighter than existing ones, but that these bounds correspond with experiments as well.
Multi-View Video-Based 3D Hand Pose Estimation
Sep 24, 2021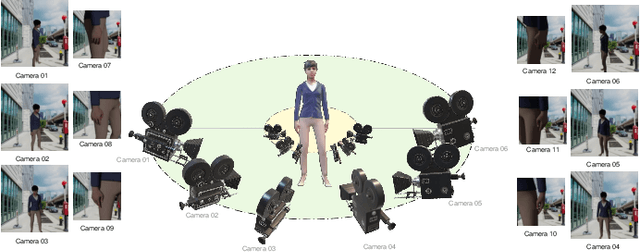
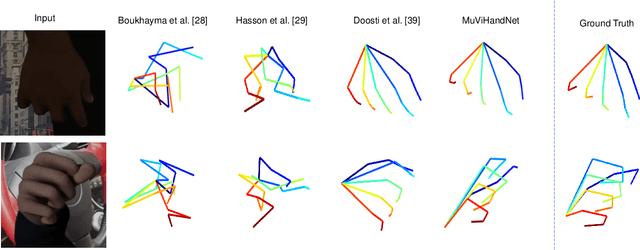
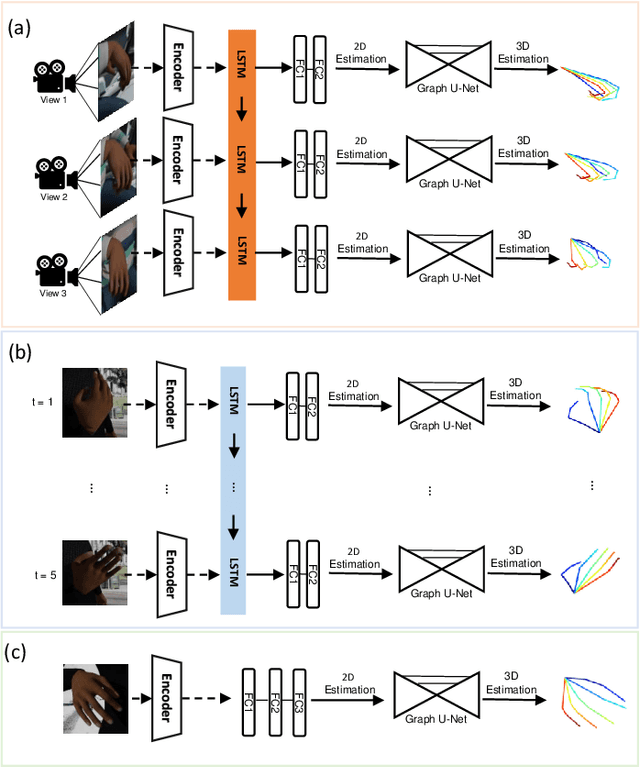
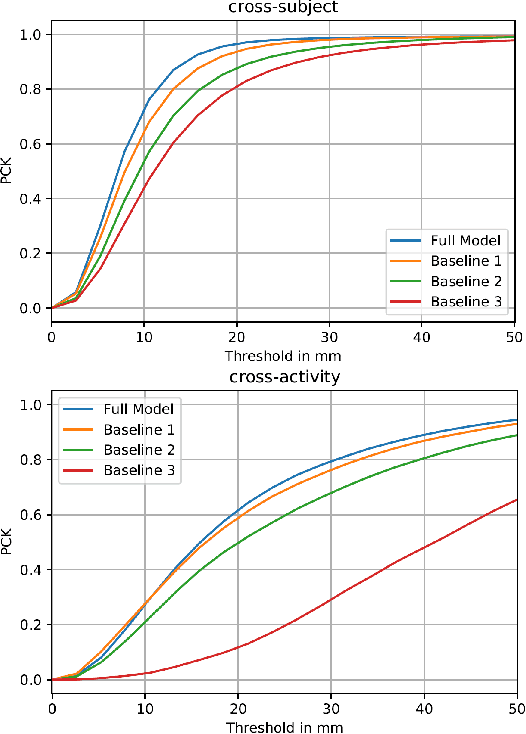
Hand pose estimation (HPE) can be used for a variety of human-computer interaction applications such as gesture-based control for physical or virtual/augmented reality devices. Recent works have shown that videos or multi-view images carry rich information regarding the hand, allowing for the development of more robust HPE systems. In this paper, we present the Multi-View Video-Based 3D Hand (MuViHand) dataset, consisting of multi-view videos of the hand along with ground-truth 3D pose labels. Our dataset includes more than 402,000 synthetic hand images available in 4,560 videos. The videos have been simultaneously captured from six different angles with complex backgrounds and random levels of dynamic lighting. The data has been captured from 10 distinct animated subjects using 12 cameras in a semi-circle topology where six tracking cameras only focus on the hand and the other six fixed cameras capture the entire body. Next, we implement MuViHandNet, a neural pipeline consisting of image encoders for obtaining visual embeddings of the hand, recurrent learners to learn both temporal and angular sequential information, and graph networks with U-Net architectures to estimate the final 3D pose information. We perform extensive experiments and show the challenging nature of this new dataset as well as the effectiveness of our proposed method. Ablation studies show the added value of each component in MuViHandNet, as well as the benefit of having temporal and sequential information in the dataset.