 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkeleton-Based Mutually Assisted Interacted Object Localization and Human Action Recognition
Paper and Code
Oct 28, 2021
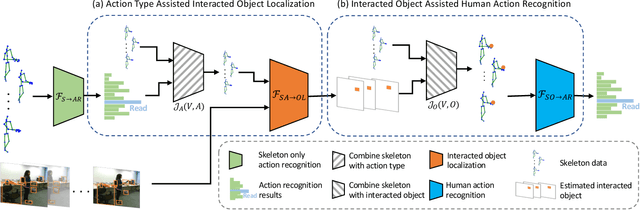

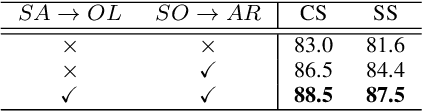
Skeleton data carries valuable motion information and is widely explored in human action recognition. However, not only the motion information but also the interaction with the environment provides discriminative cues to recognize the action of persons. In this paper, we propose a joint learning framework for mutually assisted "interacted object localization" and "human action recognition" based on skeleton data. The two tasks are serialized together and collaborate to promote each other, where preliminary action type derived from skeleton alone helps improve interacted object localization, which in turn provides valuable cues for the final human action recognition. Besides, we explore the temporal consistency of interacted object as constraint to better localize the interacted object with the absence of ground-truth labels. Extensive experiments on the datasets of SYSU-3D, NTU60 RGB+D and Northwestern-UCLA show that our method achieves the best or competitive performance with the state-of-the-art methods for human action recognition. Visualization results show that our method can also provide reasonable interacted object localization results.