 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Differentially-Private Clustering of Easy Instances
Dec 29, 2021


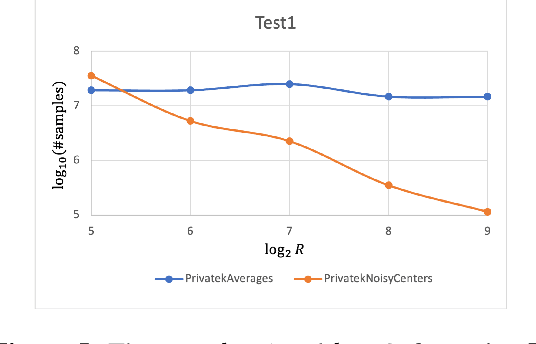
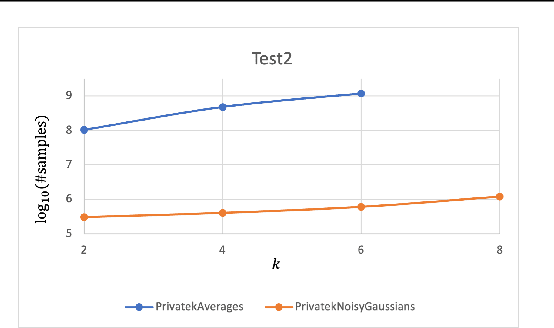
Clustering is a fundamental problem in data analysis. In differentially private clustering, the goal is to identify $k$ cluster centers without disclosing information on individual data points. Despite significant research progress, the problem had so far resisted practical solutions. In this work we aim at providing simple implementable differentially private clustering algorithms that provide utility when the data is "easy," e.g., when there exists a significant separation between the clusters. We propose a framework that allows us to apply non-private clustering algorithms to the easy instances and privately combine the results. We are able to get improved sample complexity bounds in some cases of Gaussian mixtures and $k$-means. We complement our theoretical analysis with an empirical evaluation on synthetic data.
SpectraNet: Learned Recognition of Artificial Satellites From High Contrast Spectroscopic Imagery
Jan 10, 2022
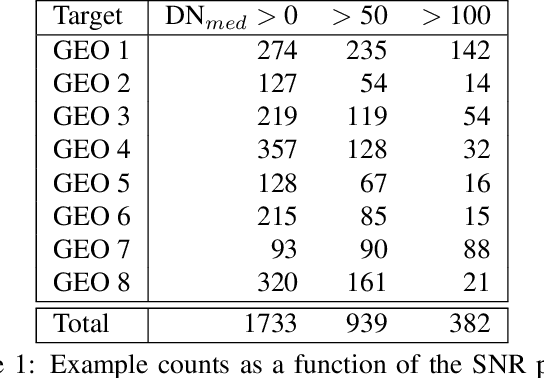
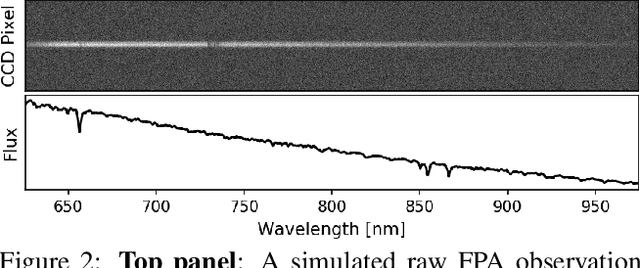
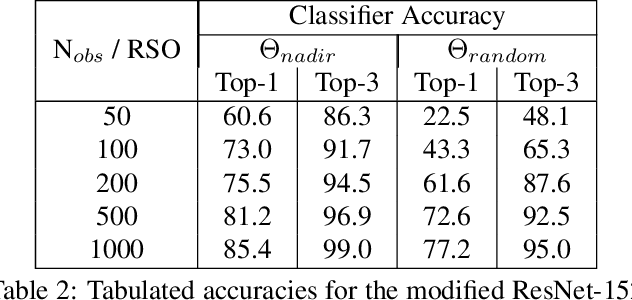
Effective space traffic management requires positive identification of artificial satellites. Current methods for extracting object identification from observed data require spatially resolved imagery which limits identification to objects in low earth orbits. Most artificial satellites, however, operate in geostationary orbits at distances which prohibit ground based observatories from resolving spatial information. This paper demonstrates an object identification solution leveraging modified residual convolutional neural networks to map distance-invariant spectroscopic data to object identity. We report classification accuracies exceeding 80% for a simulated 64-class satellite problem--even in the case of satellites undergoing constant, random re-orientation. An astronomical observing campaign driven by these results returned accuracies of 72% for a nine-class problem with an average of 100 examples per class, performing as expected from simulation. We demonstrate the application of variational Bayesian inference by dropout, stochastic weight averaging (SWA), and SWA-focused deep ensembling to measure classification uncertainties--critical components in space traffic management where routine decisions risk expensive space assets and carry geopolitical consequences.
* 8 pages, 8 figures, 5 tables. Published at WACV 2022
Nonuniform Negative Sampling and Log Odds Correction with Rare Events Data
Oct 25, 2021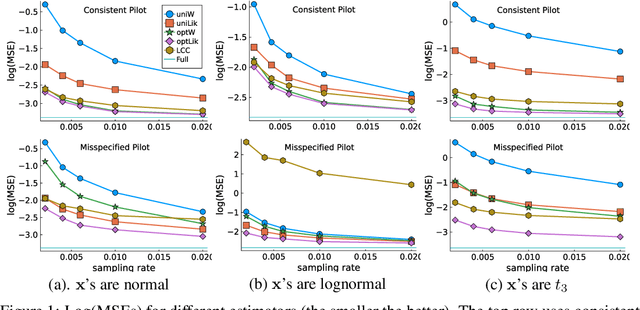

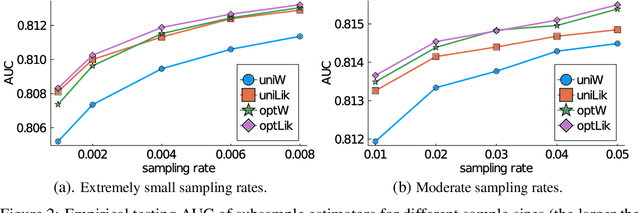
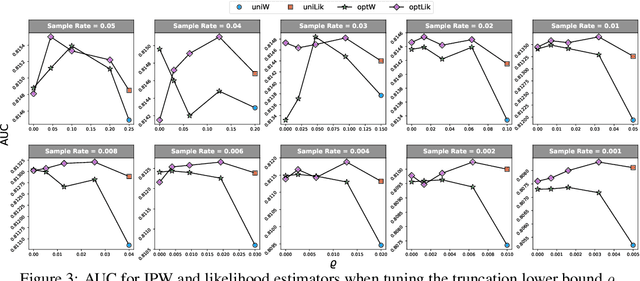
We investigate the issue of parameter estimation with nonuniform negative sampling for imbalanced data. We first prove that, with imbalanced data, the available information about unknown parameters is only tied to the relatively small number of positive instances, which justifies the usage of negative sampling. However, if the negative instances are subsampled to the same level of the positive cases, there is information loss. To maintain more information, we derive the asymptotic distribution of a general inverse probability weighted (IPW) estimator and obtain the optimal sampling probability that minimizes its variance. To further improve the estimation efficiency over the IPW method, we propose a likelihood-based estimator by correcting log odds for the sampled data and prove that the improved estimator has the smallest asymptotic variance among a large class of estimators. It is also more robust to pilot misspecification. We validate our approach on simulated data as well as a real click-through rate dataset with more than 0.3 trillion instances, collected over a period of a month. Both theoretical and empirical results demonstrate the effectiveness of our method.
SIA-GCN: A Spatial Information Aware Graph Neural Network with 2D Convolutions for Hand Pose Estimation
Sep 25, 2020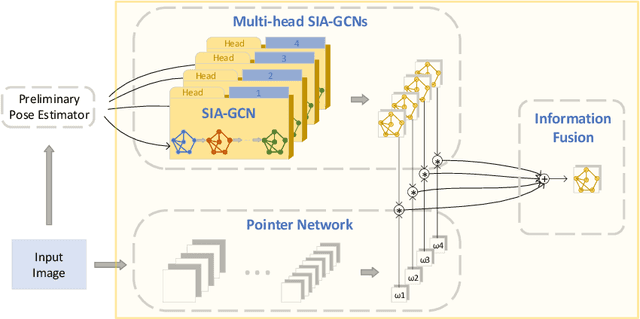
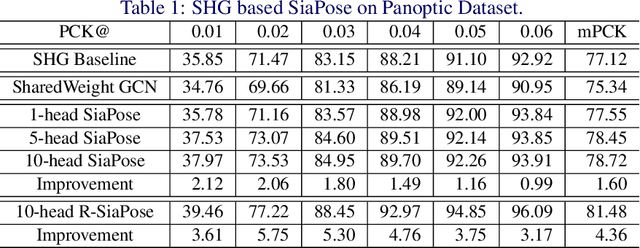
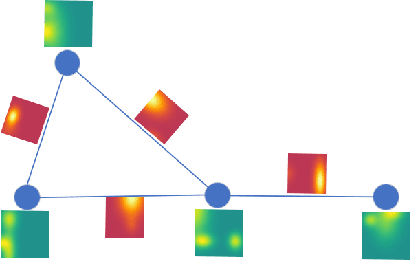
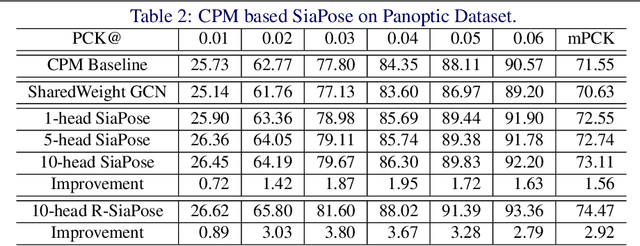
Graph Neural Networks (GNNs) generalize neural networks from applications on regular structures to applications on arbitrary graphs, and have shown success in many application domains such as computer vision, social networks and chemistry. In this paper, we extend GNNs along two directions: a) allowing features at each node to be represented by 2D spatial confidence maps instead of 1D vectors; and b) proposing an efficient operation to integrate information from neighboring nodes through 2D convolutions with different learnable kernels at each edge. The proposed SIA-GCN can efficiently extract spatial information from 2D maps at each node and propagate them through graph convolution. By associating each edge with a designated convolution kernel, the SIA-GCN could capture different spatial relationships for different pairs of neighboring nodes. We demonstrate the utility of SIA-GCN on the task of estimating hand keypoints from single-frame images, where the nodes represent the 2D coordinate heatmaps of keypoints and the edges denote the kinetic relationships between keypoints. Experiments on multiple datasets show that SIA-GCN provides a flexible and yet powerful framework to account for structural constraints between keypoints, and can achieve state-of-the-art performance on the task of hand pose estimation.
Decoupling Visual-Semantic Feature Learning for Robust Scene Text Recognition
Nov 24, 2021
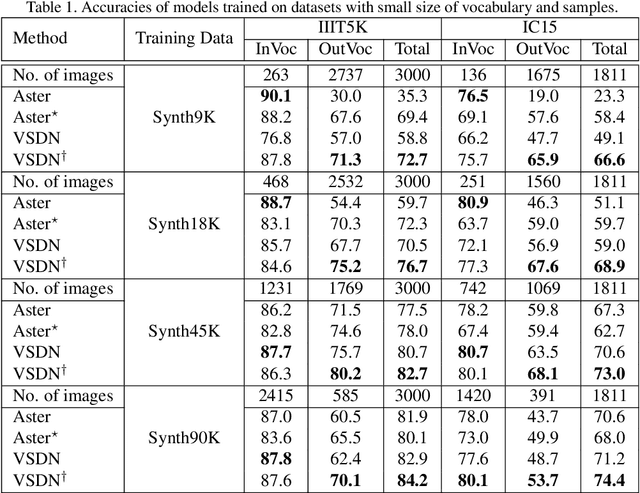
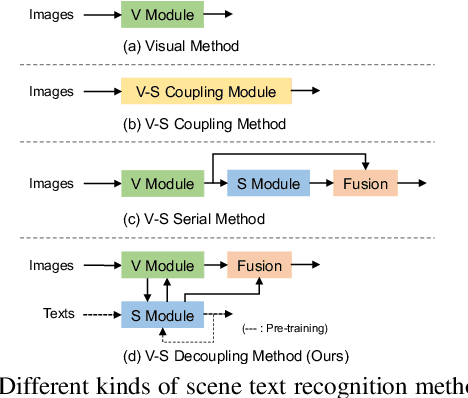
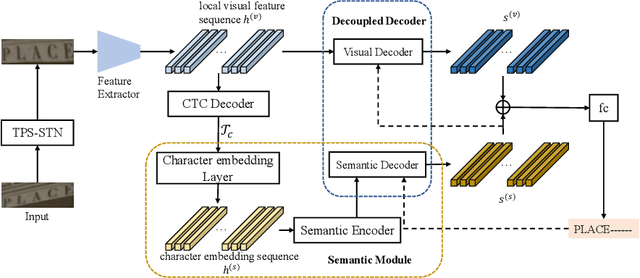
Semantic information has been proved effective in scene text recognition. Most existing methods tend to couple both visual and semantic information in an attention-based decoder. As a result, the learning of semantic features is prone to have a bias on the limited vocabulary of the training set, which is called vocabulary reliance. In this paper, we propose a novel Visual-Semantic Decoupling Network (VSDN) to address the problem. Our VSDN contains a Visual Decoder (VD) and a Semantic Decoder (SD) to learn purer visual and semantic feature representation respectively. Besides, a Semantic Encoder (SE) is designed to match SD, which can be pre-trained together by additional inexpensive large vocabulary via a simple word correction task. Thus the semantic feature is more unbiased and precise to guide the visual feature alignment and enrich the final character representation. Experiments show that our method achieves state-of-the-art or competitive results on the standard benchmarks, and outperforms the popular baseline by a large margin under circumstances where the training set has a small size of vocabulary.
A Novel Two-stage Design Scheme of Equalizers for Uplink FBMC/OQAM-based Massive MIMO Systems
Dec 04, 2021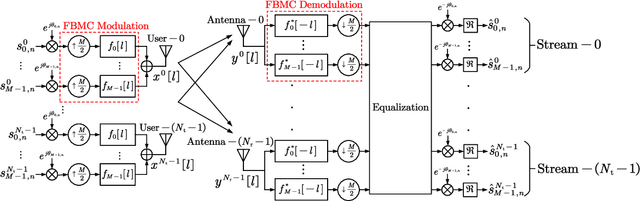
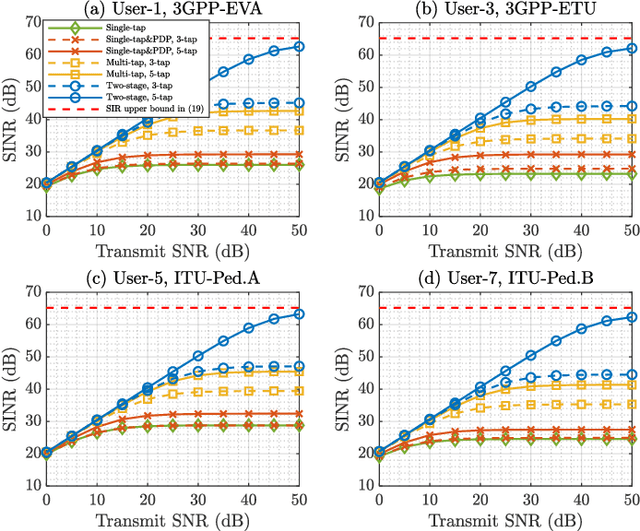
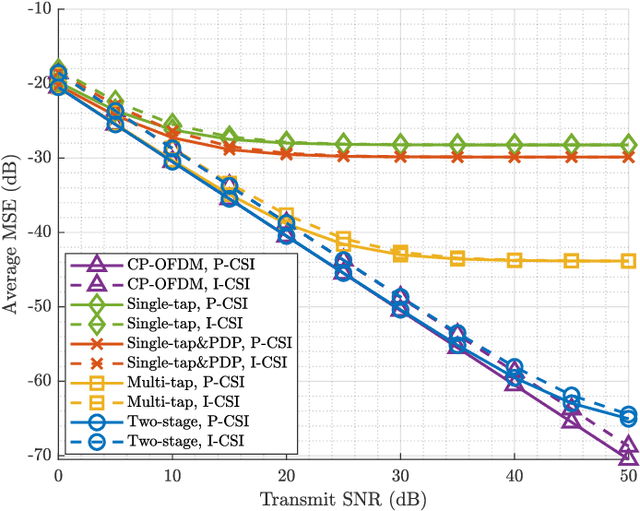
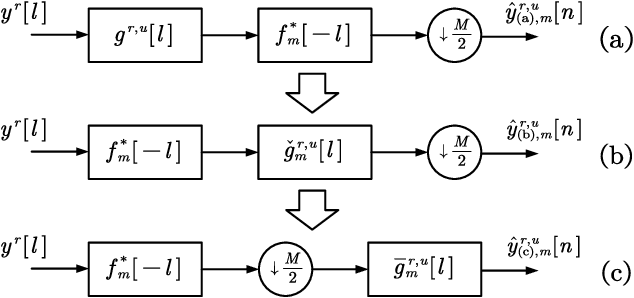
The self-equalization property has raised great concern in the combination of offset-quadratic-amplitude-modulation-based filter bank multi-carrier (FBMC/OQAM) and massive multiple-input multiple-output (MIMO) system, which enables to decrease the interference brought by the highly frequency-selective channels as the number of base station (BS) antennas increases. However, existing works show that there remains residual interference after single-tap equalization even with infinite number of BS antennas, leading to a limitation of achievable signal-to-interference-plus-noise ratio (SINR) performance. In this paper, we propose a two-stage design scheme of equalizers to remove the above limitation. In the first stage, we design high-rate equalizers working before FBMC demodulation to avoid the potential loss of channel information obtained at the BS. In the second stage, we transform the high-rate equalizers into the low-rate equalizers after FBMC demodulation to reduce the implementation complexity. Compared with prior works, the proposed scheme has affordable complexity under massive MIMO and only requires instantaneous channel state information (CSI) without statistical CSI and additional equalizers. Simulation results show that the scheme can bring improved SINR performance. Moreover, even with finite number of BS antennas, the interference brought by the channels can be almost eliminated.
MI^2GAN: Generative Adversarial Network for Medical Image Domain Adaptation using Mutual Information Constraint
Jul 22, 2020
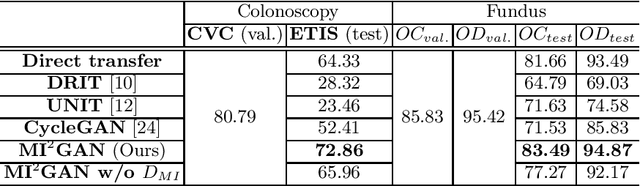
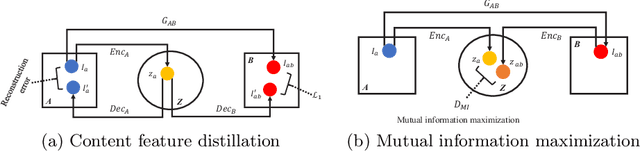
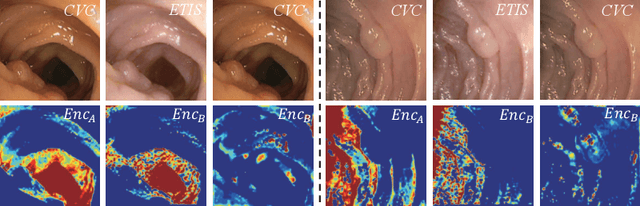
Domain shift between medical images from multicentres is still an open question for the community, which degrades the generalization performance of deep learning models. Generative adversarial network (GAN), which synthesize plausible images, is one of the potential solutions to address the problem. However, the existing GAN-based approaches are prone to fail at preserving image-objects in image-to-image (I2I) translation, which reduces their practicality on domain adaptation tasks. In this paper, we propose a novel GAN (namely MI$^2$GAN) to maintain image-contents during cross-domain I2I translation. Particularly, we disentangle the content features from domain information for both the source and translated images, and then maximize the mutual information between the disentangled content features to preserve the image-objects. The proposed MI$^2$GAN is evaluated on two tasks---polyp segmentation using colonoscopic images and the segmentation of optic disc and cup in fundus images. The experimental results demonstrate that the proposed MI$^2$GAN can not only generate elegant translated images, but also significantly improve the generalization performance of widely used deep learning networks (e.g., U-Net).
SequentialPointNet: A strong parallelized point cloud sequence network for 3D action recognition
Nov 16, 2021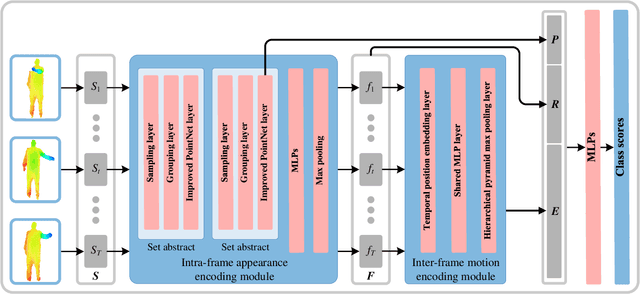
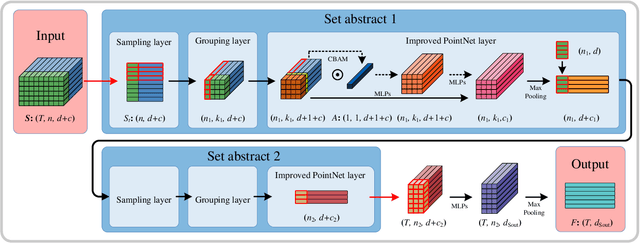
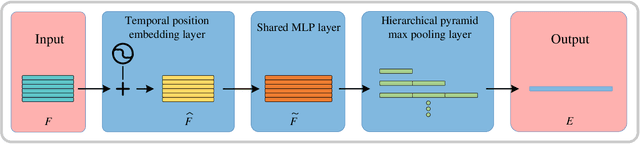
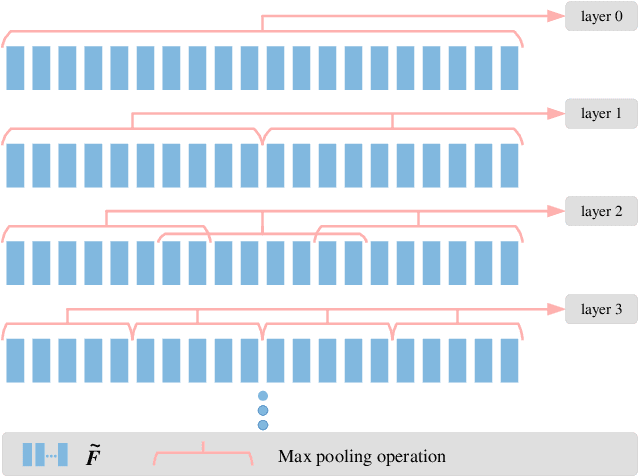
Point cloud sequences of 3D human actions exhibit unordered intra-frame spatial information and ordered interframe temporal information. In order to capture the spatiotemporal structures of the point cloud sequences, cross-frame spatio-temporal local neighborhoods around the centroids are usually constructed. However, the computationally expensive construction procedure of spatio-temporal local neighborhoods severely limits the parallelism of models. Moreover, it is unreasonable to treat spatial and temporal information equally in spatio-temporal local learning, because human actions are complicated along the spatial dimensions and simple along the temporal dimension. In this paper, to avoid spatio-temporal local encoding, we propose a strong parallelized point cloud sequence network referred to as SequentialPointNet for 3D action recognition. SequentialPointNet is composed of two serial modules, i.e., an intra-frame appearance encoding module and an inter-frame motion encoding module. For modeling the strong spatial structures of human actions, each point cloud frame is processed in parallel in the intra-frame appearance encoding module and the feature vector of each frame is output to form a feature vector sequence that characterizes static appearance changes along the temporal dimension. For modeling the weak temporal changes of human actions, in the inter-frame motion encoding module, the temporal position encoding and the hierarchical pyramid pooling strategy are implemented on the feature vector sequence. In addition, in order to better explore spatio-temporal content, multiple level features of human movements are aggregated before performing the end-to-end 3D action recognition. Extensive experiments conducted on three public datasets show that SequentialPointNet outperforms stateof-the-art approaches.
Using Spatio-temporal Deep Learning for Forecasting Demand and Supply-demand Gap in Ride-hailing System with Anonymized Spatial Adjacency Information
Dec 16, 2020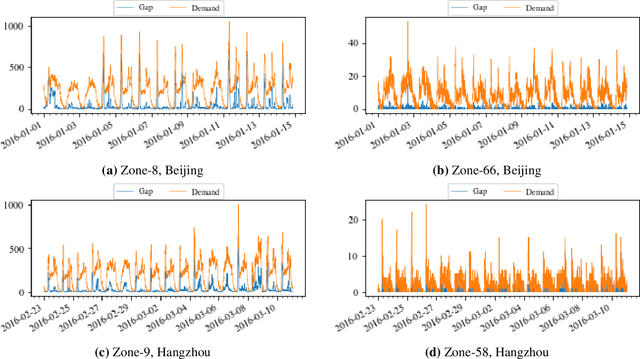

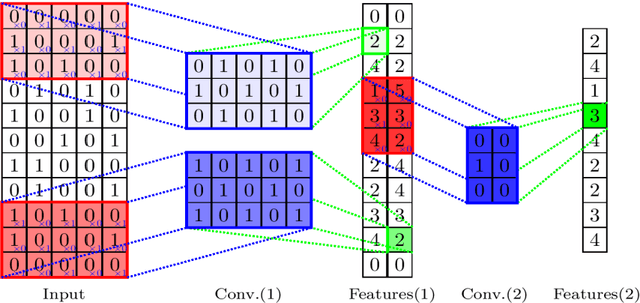
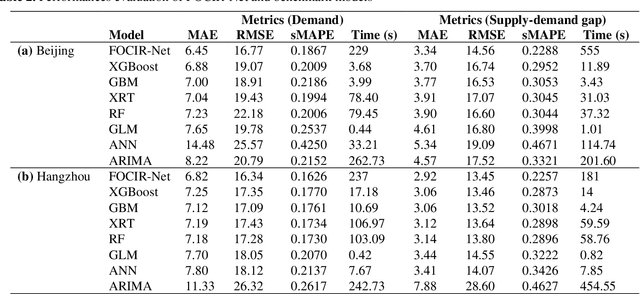
To reduce passenger waiting time and driver search friction, ride-hailing companies need to accurately forecast spatio-temporal demand and supply-demand gap. However, due to spatio-temporal dependencies pertaining to demand and supply-demand gap in a ride-hailing system, making accurate forecasts for both demand and supply-demand gap is a difficult task. Furthermore, due to confidentiality and privacy issues, ride-hailing data are sometimes released to the researchers by removing spatial adjacency information of the zones, which hinders the detection of spatio-temporal dependencies. To that end, a novel spatio-temporal deep learning architecture is proposed in this paper for forecasting demand and supply-demand gap in a ride-hailing system with anonymized spatial adjacency information, which integrates feature importance layer with a spatio-temporal deep learning architecture containing one-dimensional convolutional neural network (CNN) and zone-distributed independently recurrent neural network (IndRNN). The developed architecture is tested with real-world datasets of Didi Chuxing, which shows that our models based on the proposed architecture can outperform conventional time-series models (e.g., ARIMA) and machine learning models (e.g., gradient boosting machine, distributed random forest, generalized linear model, artificial neural network). Additionally, the feature importance layer provides an interpretation of the model by revealing the contribution of the input features utilized in prediction.
Learning Population-level Shape Statistics and Anatomy Segmentation From Images: A Joint Deep Learning Model
Jan 10, 2022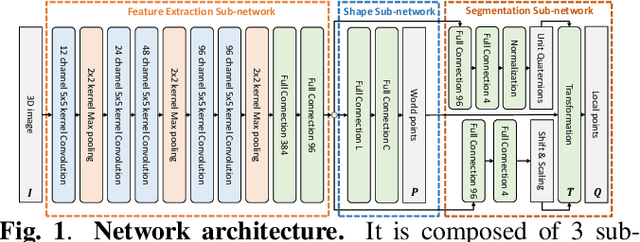
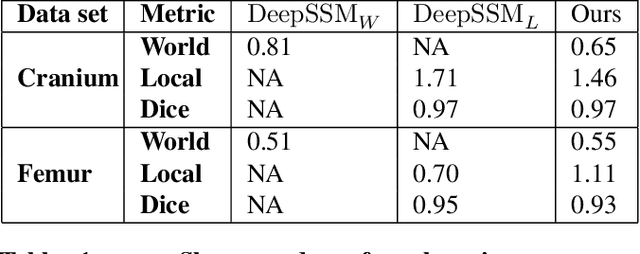
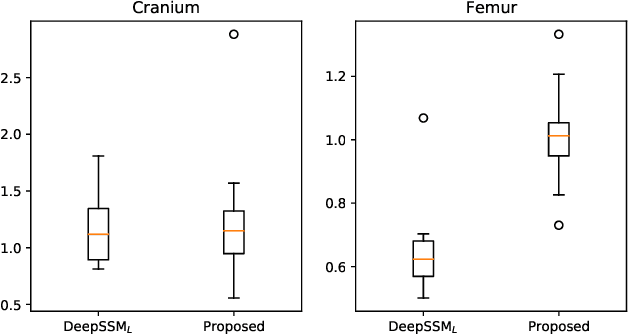
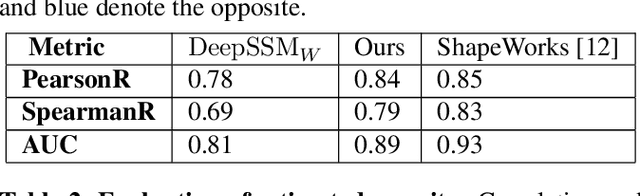
Statistical shape modeling is an essential tool for the quantitative analysis of anatomical populations. Point distribution models (PDMs) represent the anatomical surface via a dense set of correspondences, an intuitive and easy-to-use shape representation for subsequent applications. These correspondences are exhibited in two coordinate spaces: the local coordinates describing the geometrical features of each individual anatomical surface and the world coordinates representing the population-level statistical shape information after removing global alignment differences across samples in the given cohort. We propose a deep-learning-based framework that simultaneously learns these two coordinate spaces directly from the volumetric images. The proposed joint model serves a dual purpose; the world correspondences can directly be used for shape analysis applications, circumventing the heavy pre-processing and segmentation involved in traditional PDM models. Additionally, the local correspondences can be used for anatomy segmentation. We demonstrate the efficacy of this joint model for both shape modeling applications on two datasets and its utility in inferring the anatomical surface.