 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectraNet: Learned Recognition of Artificial Satellites From High Contrast Spectroscopic Imagery
Jan 10, 2022
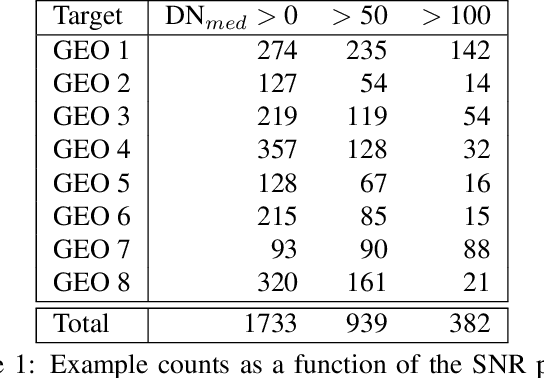
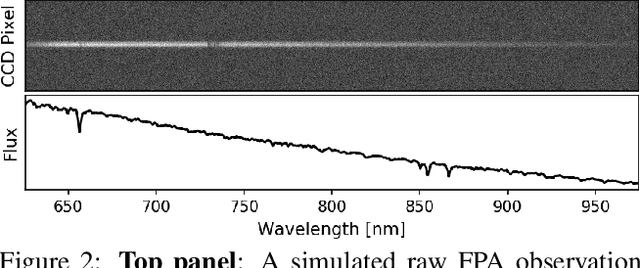
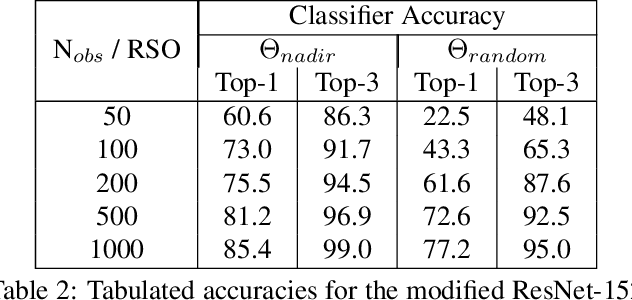
Effective space traffic management requires positive identification of artificial satellites. Current methods for extracting object identification from observed data require spatially resolved imagery which limits identification to objects in low earth orbits. Most artificial satellites, however, operate in geostationary orbits at distances which prohibit ground based observatories from resolving spatial information. This paper demonstrates an object identification solution leveraging modified residual convolutional neural networks to map distance-invariant spectroscopic data to object identity. We report classification accuracies exceeding 80% for a simulated 64-class satellite problem--even in the case of satellites undergoing constant, random re-orientation. An astronomical observing campaign driven by these results returned accuracies of 72% for a nine-class problem with an average of 100 examples per class, performing as expected from simulation. We demonstrate the application of variational Bayesian inference by dropout, stochastic weight averaging (SWA), and SWA-focused deep ensembling to measure classification uncertainties--critical components in space traffic management where routine decisions risk expensive space assets and carry geopolitical consequences.
* 8 pages, 8 figures, 5 tables. Published at WACV 2022
Self-Attending Task Generative Adversarial Network for Realistic Satellite Image Creation
Nov 18, 2021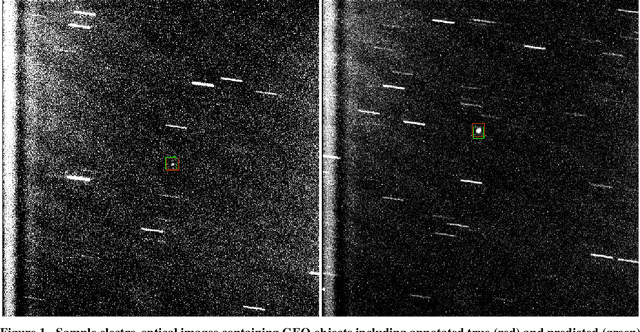
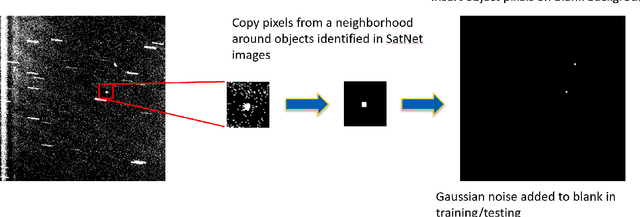
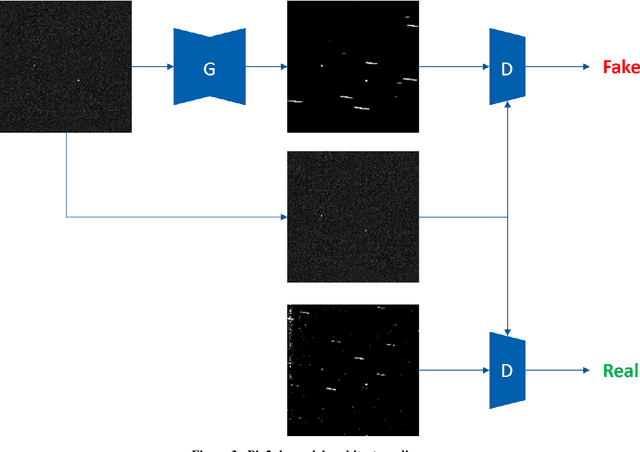
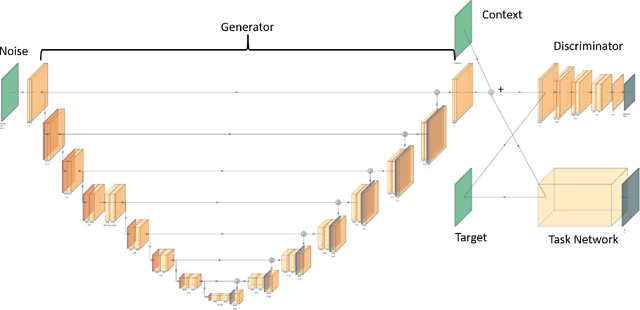
We introduce a self-attending task generative adversarial network (SATGAN) and apply it to the problem of augmenting synthetic high contrast scientific imagery of resident space objects with realistic noise patterns and sensor characteristics learned from collected data. Augmenting these synthetic data is challenging due to the highly localized nature of semantic content in the data that must be preserved. Real collected images are used to train a network what a given class of sensor's images should look like. The trained network then acts as a filter on noiseless context images and outputs realistic-looking fakes with semantic content unaltered. The architecture is inspired by conditional GANs but is modified to include a task network that preserves semantic information through augmentation. Additionally, the architecture is shown to reduce instances of hallucinatory objects or obfuscation of semantic content in context images representing space observation scenes.