 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Distributed Adaptive Learning Under Communication Constraints
Dec 03, 2021

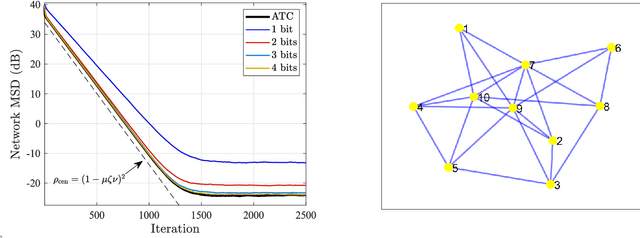
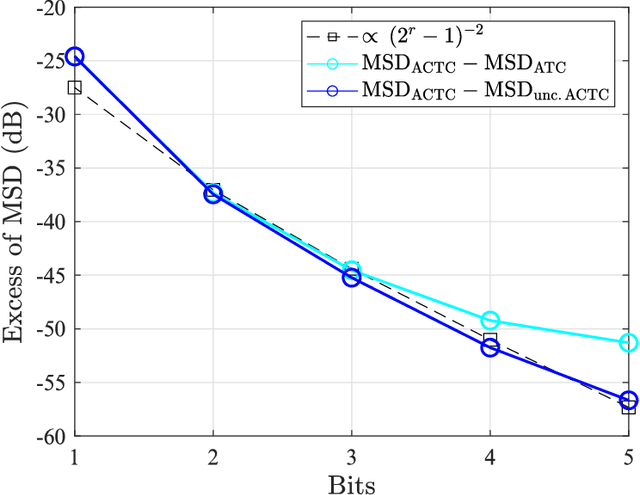
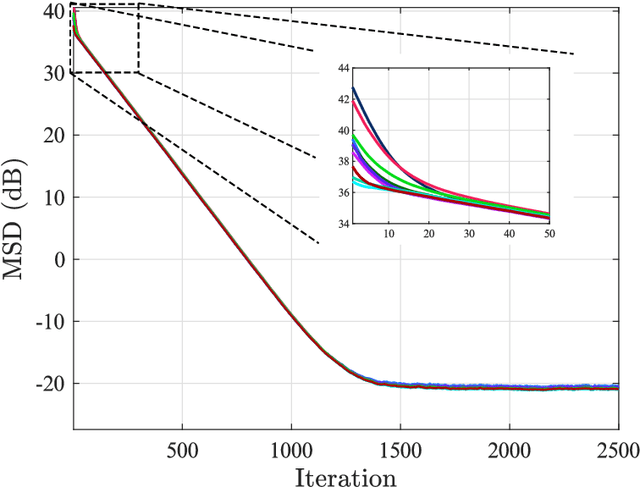
This work examines adaptive distributed learning strategies designed to operate under communication constraints. We consider a network of agents that must solve an online optimization problem from continual observation of streaming data. The agents implement a distributed cooperative strategy where each agent is allowed to perform local exchange of information with its neighbors. In order to cope with communication constraints, the exchanged information must be unavoidably compressed. We propose a diffusion strategy nicknamed as ACTC (Adapt-Compress-Then-Combine), which relies on the following steps: i) an adaptation step where each agent performs an individual stochastic-gradient update with constant step-size; ii) a compression step that leverages a recently introduced class of stochastic compression operators; and iii) a combination step where each agent combines the compressed updates received from its neighbors. The distinguishing elements of this work are as follows. First, we focus on adaptive strategies, where constant (as opposed to diminishing) step-sizes are critical to respond in real time to nonstationary variations. Second, we consider the general class of directed graphs and left-stochastic combination policies, which allow us to enhance the interplay between topology and learning. Third, in contrast with related works that assume strong convexity for all individual agents' cost functions, we require strong convexity only at a network level, a condition satisfied even if a single agent has a strongly-convex cost and the remaining agents have non-convex costs. Fourth, we focus on a diffusion (as opposed to consensus) strategy. Under the demanding setting of compressed information, we establish that the ACTC iterates fluctuate around the desired optimizer, achieving remarkable savings in terms of bits exchanged between neighboring agents.
Graph-GAN: A spatial-temporal neural network for short-term passenger flow prediction in urban rail transit systems
Feb 10, 2022Short-term passenger flow prediction plays an important role in better managing the urban rail transit (URT) systems. Emerging deep learning models provide good insights to improve short-term prediction accuracy. However, a large number of existing prediction models combine diverse neural network layers to improve accuracy, making their model structures extremely complex and difficult to be applied to the real world. Therefore, it is necessary to trade off between the model complexity and prediction performance from the perspective of real-world applications. To this end, we propose a deep learning-based Graph-GAN model with a simple structure and high prediction accuracy to predict short-term passenger flows of the URT network. The Graph-GAN consists of two major parts: (1) a simplified and static version of the graph convolution network (GCN) used to extract network topological information; (2) a generative adversarial network (GAN) used to predict passenger flows, with generators and discriminators in GAN just composed of simple fully connected neural networks. The Graph-GAN is tested on two large-scale real-world datasets from Beijing Subway. A comparison of the prediction performance of Graph-GAN with those of several state-of-the-art models illustrates its superiority and robustness. This study can provide critical experience in conducting short-term passenger flow predictions, especially from the perspective of real-world applications.
Information Directed Sampling for Linear Partial Monitoring
Feb 25, 2020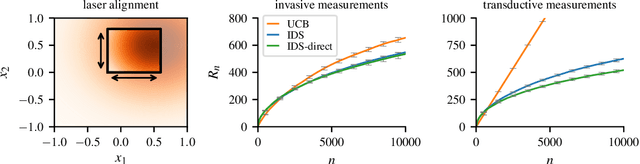
Partial monitoring is a rich framework for sequential decision making under uncertainty that generalizes many well known bandit models, including linear, combinatorial and dueling bandits. We introduce information directed sampling (IDS) for stochastic partial monitoring with a linear reward and observation structure. IDS achieves adaptive worst-case regret rates that depend on precise observability conditions of the game. Moreover, we prove lower bounds that classify the minimax regret of all finite games into four possible regimes. IDS achieves the optimal rate in all cases up to logarithmic factors, without tuning any hyper-parameters. We further extend our results to the contextual and the kernelized setting, which significantly increases the range of possible applications.
Opinions Vary? Diagnosis First!
Feb 14, 2022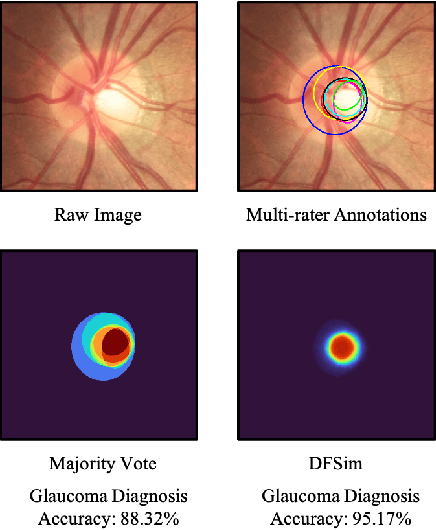
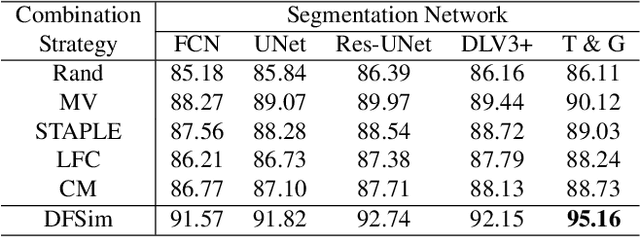
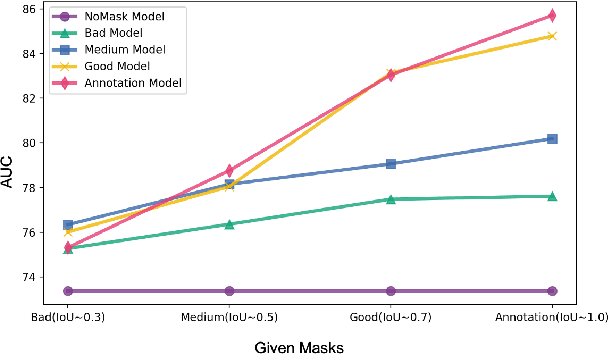
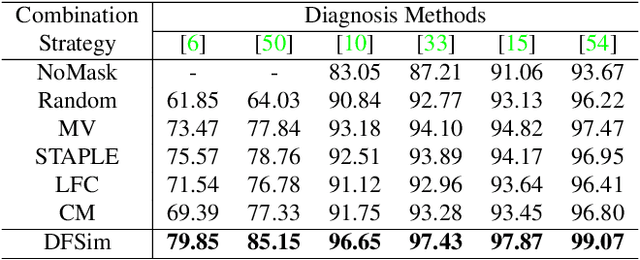
In medical image segmentation, images are usually annotated by several different clinical experts. This clinical routine helps to mitigate the personal bias. However, Computer Vision models often assume there has a unique ground-truth for each of the instance. This research gap between Computer Vision and medical routine is commonly existed but less explored by the current research.In this paper, we try to answer the following two questions: 1. How to learn an optimal combination of the multiple segmentation labels? and 2. How to estimate this segmentation mask from the raw image? We note that in clinical practice, the image segmentation mask usually exists as an auxiliary information for disease diagnosis. Adhering to this mindset, we propose a framework taking the diagnosis result as the gold standard, to estimate the segmentation mask upon the multi-rater segmentation labels, named DiFF (Diagnosis First segmentation Framework).DiFF is implemented by two novelty techniques. First, DFSim (Diagnosis First Simulation of gold label) is learned as an optimal combination of multi-rater segmentation labels for the disease diagnosis. Then, toward estimating DFSim mask from the raw image, we further propose T\&G Module (Take and Give Module) to instill the diagnosis knowledge into the segmentation network. The experiments show that compared with commonly used majority vote, the proposed DiFF is able to segment the masks with 6% improvement on diagnosis AUC score, which also outperforms various state-of-the-art multi-rater methods by a large margin.
Learning and Evaluating Graph Neural Network Explanations based on Counterfactual and Factual Reasoning
Feb 17, 2022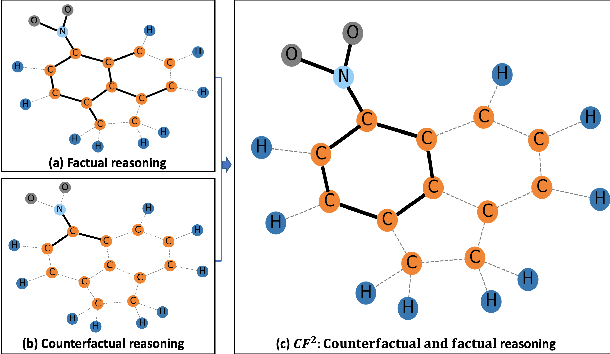
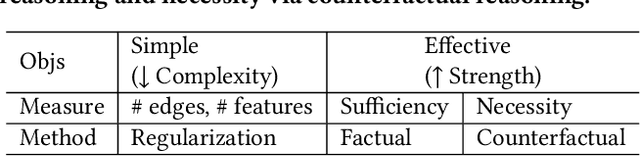

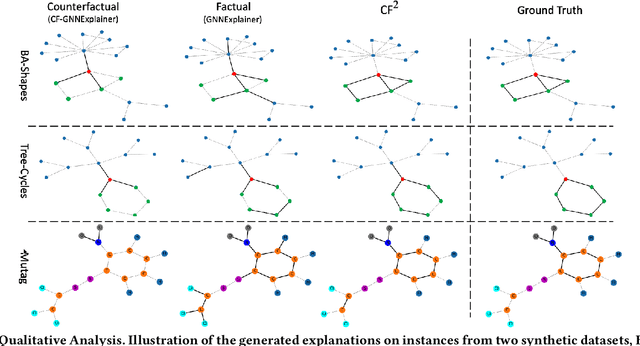
Structural data well exists in Web applications, such as social networks in social media, citation networks in academic websites, and threads data in online forums. Due to the complex topology, it is difficult to process and make use of the rich information within such data. Graph Neural Networks (GNNs) have shown great advantages on learning representations for structural data. However, the non-transparency of the deep learning models makes it non-trivial to explain and interpret the predictions made by GNNs. Meanwhile, it is also a big challenge to evaluate the GNN explanations, since in many cases, the ground-truth explanations are unavailable. In this paper, we take insights of Counterfactual and Factual (CF^2) reasoning from causal inference theory, to solve both the learning and evaluation problems in explainable GNNs. For generating explanations, we propose a model-agnostic framework by formulating an optimization problem based on both of the two casual perspectives. This distinguishes CF^2 from previous explainable GNNs that only consider one of them. Another contribution of the work is the evaluation of GNN explanations. For quantitatively evaluating the generated explanations without the requirement of ground-truth, we design metrics based on Counterfactual and Factual reasoning to evaluate the necessity and sufficiency of the explanations. Experiments show that no matter ground-truth explanations are available or not, CF^2 generates better explanations than previous state-of-the-art methods on real-world datasets. Moreover, the statistic analysis justifies the correlation between the performance on ground-truth evaluation and our proposed metrics.
Recognizing Concepts and Recognizing Musical Themes. A Quantum Semantic Analysis
Feb 17, 2022



How are abstract concepts and musical themes recognized on the basis of some previous experience? It is interesting to compare the different behaviors of human and of artificial intelligences with respect to this problem. Generally, a human mind that abstracts a concept (say, table) from a given set of known examples creates a table-Gestalt: a kind of vague and out of focus image that does not fully correspond to a particular table with well determined features. A similar situation arises in the case of musical themes. Can the construction of a gestaltic pattern, which is so natural for human minds, be taught to an intelligent machine? This problem can be successfully discussed in the framework of a quantum approach to pattern recognition and to machine learning. The basic idea is replacing classical data sets with quantum data sets, where either objects or musical themes can be formally represented as pieces of quantum information, involving the uncertainties and the ambiguities that characterize the quantum world. In this framework, the intuitive concept of Gestalt can be simulated by the mathematical concept of positive centroid of a given quantum data set. Accordingly, the crucial problem "how can we classify a new object or a new musical theme (we have listened to) on the basis of a previous experience?" can be dealt with in terms of some special quantum similarity-relations. Although recognition procedures are different for human and for artificial intelligences, there is a common method of "facing the problems" that seems to work in both cases.
Graph-based Algorithm Unfolding for Energy-aware Power Allocation in Wireless Networks
Jan 27, 2022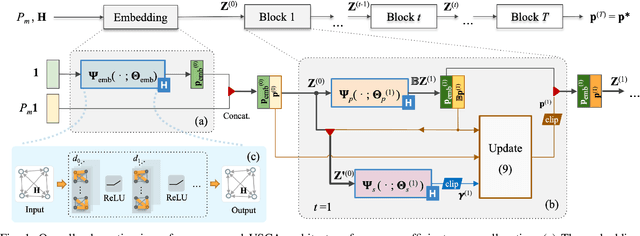
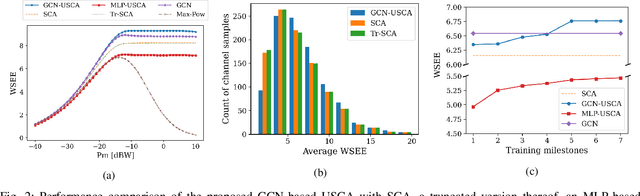
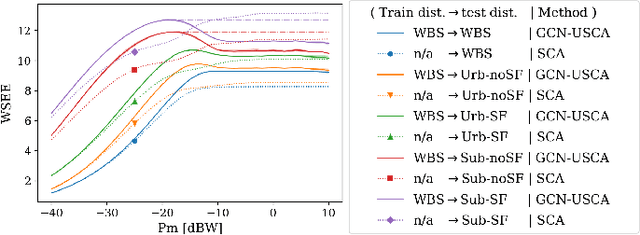
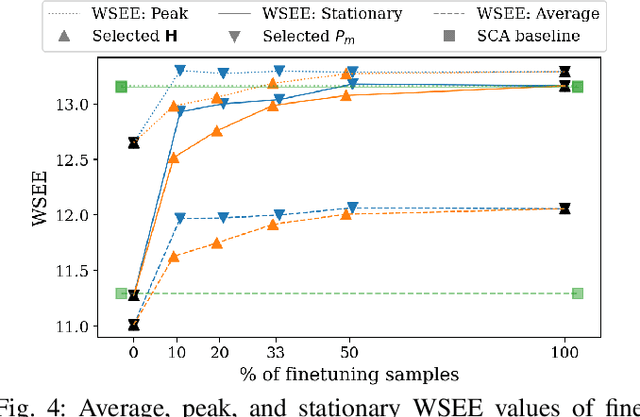
We develop a novel graph-based trainable framework to maximize the weighted sum energy efficiency (WSEE) for power allocation in wireless communication networks. To address the non-convex nature of the problem, the proposed method consists of modular structures inspired by a classical iterative suboptimal approach and enhanced with learnable components. More precisely, we propose a deep unfolding of the successive concave approximation (SCA) method. In our unfolded SCA (USCA) framework, the originally preset parameters are now learnable via graph convolutional neural networks (GCNs) that directly exploit multi-user channel state information as the underlying graph adjacency matrix. We show the permutation equivariance of the proposed architecture, which promotes generalizability across different network topologies of varying size, density, and channel distribution. The USCA framework is trained through a stochastic gradient descent approach using a progressive training strategy. The unsupervised loss is carefully devised to feature the monotonic property of the objective under maximum power constraints. Comprehensive numerical results demonstrate outstanding performance and robustness of USCA over state-of-the-art benchmarks.
Multi-cell Non-coherent Over-the-Air Computation for Federated Edge Learning
Feb 01, 2022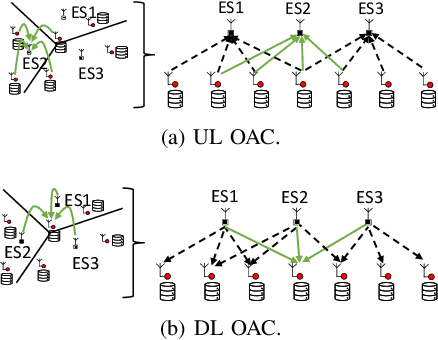
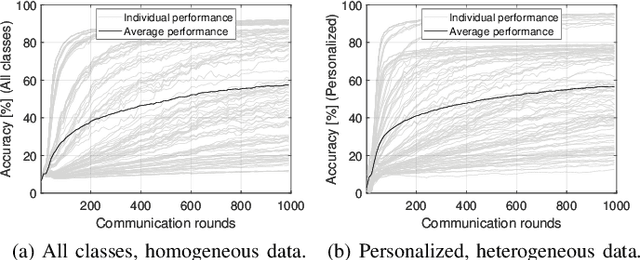
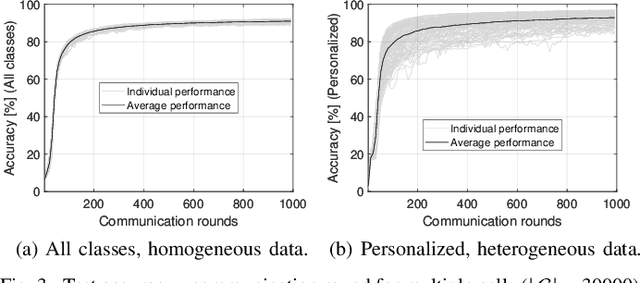
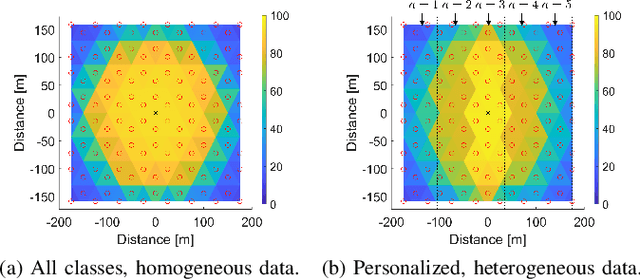
In this paper, we propose a framework where over-the-air computation (OAC) occurs in both uplink (UL) and downlink (DL), sequentially, in a multi-cell environment to address the latency and the scalability issues of federated edge learning (FEEL). To eliminate the channel state information (CSI) at the edge devices (EDs) and edge servers (ESs) and relax the time-synchronization requirement for the OAC, we use a non-coherent computation scheme, i.e., frequency-shift keying (FSK)-based majority vote (MV) (FSK-MV). With the proposed framework, multiple ESs function as the aggregation nodes in the UL and each ES determines the MVs independently. After the ESs broadcast the detected MVs, the EDs determine the sign of the gradient through another OAC in the DL. Hence, inter-cell interference is exploited for the OAC. In this study, we prove the convergence of the non-convex optimization problem for the FEEL with the proposed OAC framework. We also numerically evaluate the efficacy of the proposed method by comparing the test accuracy in both multi-cell and single-cell scenarios for both homogeneous and heterogeneous data distributions.
Code Sophistication: From Code Recommendation to Logic Recommendation
Jan 19, 2022A typical approach to programming is to first code the main execution scenario, and then focus on filling out alternative behaviors and corner cases. But, almost always, there exist unusual conditions that trigger atypical behaviors, which are hard to predict in program specifications, and are thus often not coded. In this paper, we consider the problem of detecting and recommending such missing behaviors, a task that we call code sophistication. Previous research on coding assistants usually focuses on recommending code fragments based on specifications of the intended behavior. In contrast, code sophistication happens in the absence of a specification, aiming to help developers complete the logic of their programs with missing and unspecified behaviors. We outline the research challenges to this problem and present early results showing how program logic can be completed by leveraging code structure and information about the usage of input parameters.
Consistency and Diversity induced Human Motion Segmentation
Feb 10, 2022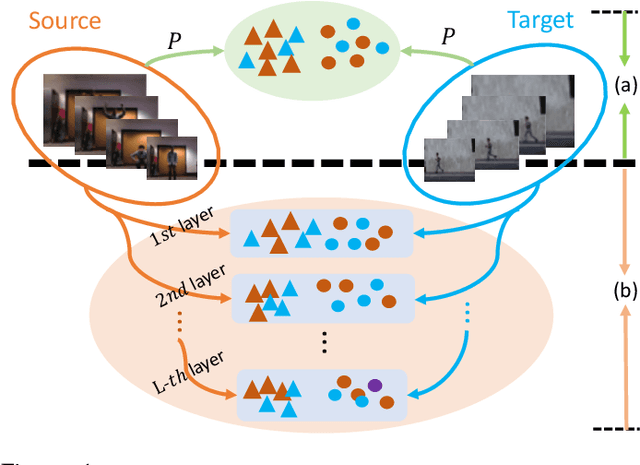

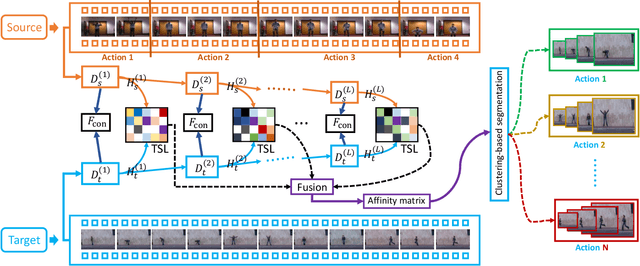
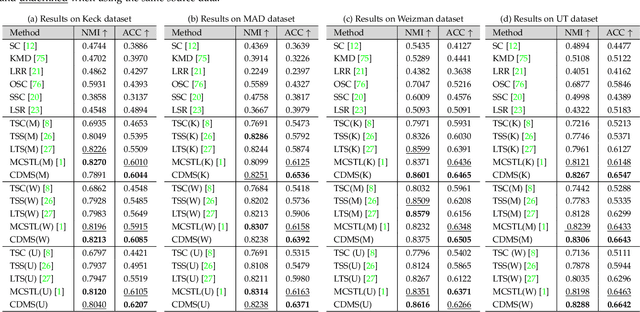
Subspace clustering is a classical technique that has been widely used for human motion segmentation and other related tasks. However, existing segmentation methods often cluster data without guidance from prior knowledge, resulting in unsatisfactory segmentation results. To this end, we propose a novel Consistency and Diversity induced human Motion Segmentation (CDMS) algorithm. Specifically, our model factorizes the source and target data into distinct multi-layer feature spaces, in which transfer subspace learning is conducted on different layers to capture multi-level information. A multi-mutual consistency learning strategy is carried out to reduce the domain gap between the source and target data. In this way, the domain-specific knowledge and domain-invariant properties can be explored simultaneously. Besides, a novel constraint based on the Hilbert Schmidt Independence Criterion (HSIC) is introduced to ensure the diversity of multi-level subspace representations, which enables the complementarity of multi-level representations to be explored to boost the transfer learning performance. Moreover, to preserve the temporal correlations, an enhanced graph regularizer is imposed on the learned representation coefficients and the multi-level representations of the source data. The proposed model can be efficiently solved using the Alternating Direction Method of Multipliers (ADMM) algorithm. Extensive experimental results on public human motion datasets demonstrate the effectiveness of our method against several state-of-the-art approaches.