 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Build: Autonomous Robotic Assembly of Stable Structures Without Predefined Plans
Feb 27, 2026This paper presents a novel autonomous robotic assembly framework for constructing stable structures without relying on predefined architectural blueprints. Instead of following fixed plans, construction tasks are defined through targets and obstacles, allowing the system to adapt more flexibly to environmental uncertainty and variations during the building process. A reinforcement learning (RL) policy, trained using deep Q-learning with successor features, serves as the decision-making component. As a proof of concept, we evaluate the approach on a benchmark of 15 2D robotic assembly tasks of discrete block construction. Experiments using a real-world closed-loop robotic setup demonstrate the feasibility of the method and its ability to handle construction noise. The results suggest that our framework offers a promising direction for more adaptable and robust robotic construction in real-world environments.
Principled Confidence Estimation for Deep Computed Tomography
Feb 05, 2026We present a principled framework for confidence estimation in computed tomography (CT) reconstruction. Based on the sequential likelihood mixing framework (Kirschner et al., 2025), we establish confidence regions with theoretical coverage guarantees for deep-learning-based CT reconstructions. We consider a realistic forward model following the Beer-Lambert law, i.e., a log-linear forward model with Poisson noise, closely reflecting clinical and scientific imaging conditions. The framework is general and applies to both classical algorithms and deep learning reconstruction methods, including U-Nets, U-Net ensembles, and generative Diffusion models. Empirically, we demonstrate that deep reconstruction methods yield substantially tighter confidence regions than classical reconstructions, without sacrificing theoretical coverage guarantees. Our approach allows the detection of hallucinations in reconstructed images and provides interpretable visualizations of confidence regions. This establishes deep models not only as powerful estimators, but also as reliable tools for uncertainty-aware medical imaging.
Diffusion Active Learning: Towards Data-Driven Experimental Design in Computed Tomography
Apr 04, 2025We introduce Diffusion Active Learning, a novel approach that combines generative diffusion modeling with data-driven sequential experimental design to adaptively acquire data for inverse problems. Although broadly applicable, we focus on scientific computed tomography (CT) for experimental validation, where structured prior datasets are available, and reducing data requirements directly translates to shorter measurement times and lower X-ray doses. We first pre-train an unconditional diffusion model on domain-specific CT reconstructions. The diffusion model acts as a learned prior that is data-dependent and captures the structure of the underlying data distribution, which is then used in two ways: It drives the active learning process and also improves the quality of the reconstructions. During the active learning loop, we employ a variant of diffusion posterior sampling to generate conditional data samples from the posterior distribution, ensuring consistency with the current measurements. Using these samples, we quantify the uncertainty in the current estimate to select the most informative next measurement. Our results show substantial reductions in data acquisition requirements, corresponding to lower X-ray doses, while simultaneously improving image reconstruction quality across multiple real-world tomography datasets.
Confidence Estimation via Sequential Likelihood Mixing
Feb 20, 2025We present a universal framework for constructing confidence sets based on sequential likelihood mixing. Building upon classical results from sequential analysis, we provide a unifying perspective on several recent lines of work, and establish fundamental connections between sequential mixing, Bayesian inference and regret inequalities from online estimation. The framework applies to any realizable family of likelihood functions and allows for non-i.i.d. data and anytime validity. Moreover, the framework seamlessly integrates standard approximate inference techniques, such as variational inference and sampling-based methods, and extends to misspecified model classes, while preserving provable coverage guarantees. We illustrate the power of the framework by deriving tighter confidence sequences for classical settings, including sequential linear regression and sparse estimation, with simplified proofs.
Regret Minimization via Saddle Point Optimization
Mar 15, 2024A long line of works characterizes the sample complexity of regret minimization in sequential decision-making by min-max programs. In the corresponding saddle-point game, the min-player optimizes the sampling distribution against an adversarial max-player that chooses confusing models leading to large regret. The most recent instantiation of this idea is the decision-estimation coefficient (DEC), which was shown to provide nearly tight lower and upper bounds on the worst-case expected regret in structured bandits and reinforcement learning. By re-parametrizing the offset DEC with the confidence radius and solving the corresponding min-max program, we derive an anytime variant of the Estimation-To-Decisions (E2D) algorithm. Importantly, the algorithm optimizes the exploration-exploitation trade-off online instead of via the analysis. Our formulation leads to a practical algorithm for finite model classes and linear feedback models. We further point out connections to the information ratio, decoupling coefficient and PAC-DEC, and numerically evaluate the performance of E2D on simple examples.
Efficient Planning in Combinatorial Action Spaces with Applications to Cooperative Multi-Agent Reinforcement Learning
Feb 08, 2023A practical challenge in reinforcement learning are combinatorial action spaces that make planning computationally demanding. For example, in cooperative multi-agent reinforcement learning, a potentially large number of agents jointly optimize a global reward function, which leads to a combinatorial blow-up in the action space by the number of agents. As a minimal requirement, we assume access to an argmax oracle that allows to efficiently compute the greedy policy for any Q-function in the model class. Building on recent work in planning with local access to a simulator and linear function approximation, we propose efficient algorithms for this setting that lead to polynomial compute and query complexity in all relevant problem parameters. For the special case where the feature decomposition is additive, we further improve the bounds and extend the results to the kernelized setting with an efficient algorithm.
Linear Partial Monitoring for Sequential Decision-Making: Algorithms, Regret Bounds and Applications
Feb 07, 2023Partial monitoring is an expressive framework for sequential decision-making with an abundance of applications, including graph-structured and dueling bandits, dynamic pricing and transductive feedback models. We survey and extend recent results on the linear formulation of partial monitoring that naturally generalizes the standard linear bandit setting. The main result is that a single algorithm, information-directed sampling (IDS), is (nearly) worst-case rate optimal in all finite-action games. We present a simple and unified analysis of stochastic partial monitoring, and further extend the model to the contextual and kernelized setting.
Near-optimal Policy Identification in Active Reinforcement Learning
Dec 19, 2022



Many real-world reinforcement learning tasks require control of complex dynamical systems that involve both costly data acquisition processes and large state spaces. In cases where the transition dynamics can be readily evaluated at specified states (e.g., via a simulator), agents can operate in what is often referred to as planning with a \emph{generative model}. We propose the AE-LSVI algorithm for best-policy identification, a novel variant of the kernelized least-squares value iteration (LSVI) algorithm that combines optimism with pessimism for active exploration (AE). AE-LSVI provably identifies a near-optimal policy \emph{uniformly} over an entire state space and achieves polynomial sample complexity guarantees that are independent of the number of states. When specialized to the recently introduced offline contextual Bayesian optimization setting, our algorithm achieves improved sample complexity bounds. Experimentally, we demonstrate that AE-LSVI outperforms other RL algorithms in a variety of environments when robustness to the initial state is required.
Managing Temporal Resolution in Continuous Value Estimation: A Fundamental Trade-off
Dec 17, 2022



A default assumption in reinforcement learning and optimal control is that experience arrives at discrete time points on a fixed clock cycle. Many applications, however, involve continuous systems where the time discretization is not fixed but instead can be managed by a learning algorithm. By analyzing Monte-Carlo value estimation for LQR systems in both finite-horizon and infinite-horizon settings, we uncover a fundamental trade-off between approximation and statistical error in value estimation. Importantly, these two errors behave differently with respect to time discretization, which implies that there is an optimal choice for the temporal resolution that depends on the data budget. These findings show how adapting the temporal resolution can provably improve value estimation quality in LQR systems from finite data. Empirically, we demonstrate the trade-off in numerical simulations of LQR instances and several non-linear environments.
Tuning Particle Accelerators with Safety Constraints using Bayesian Optimization
Mar 29, 2022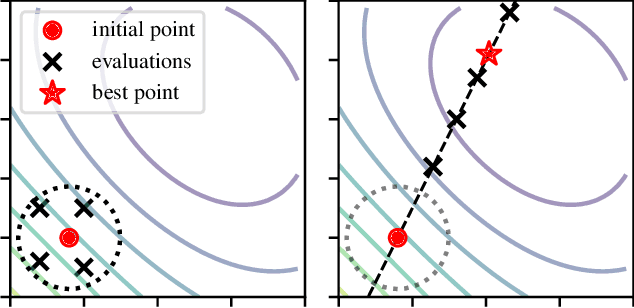
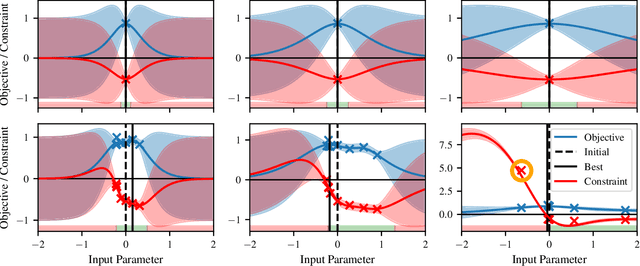
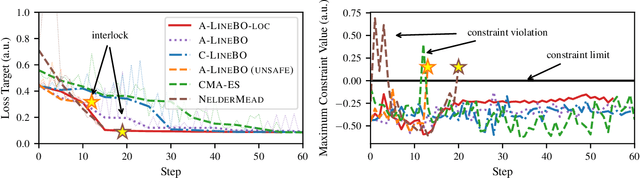
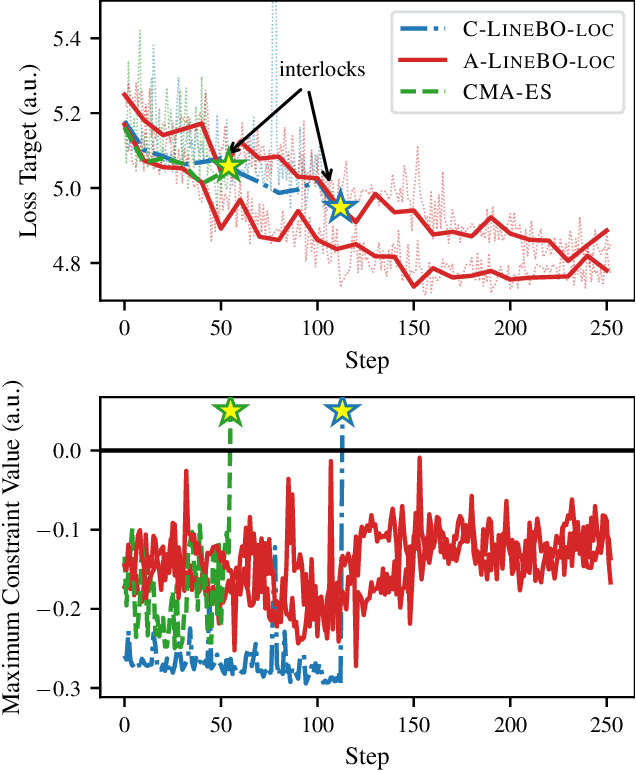
Tuning machine parameters of particle accelerators is a repetitive and time-consuming task, that is challenging to automate. While many off-the-shelf optimization algorithms are available, in practice their use is limited because most methods do not account for safety-critical constraints that apply to each iteration, including loss signals or step-size limitations. One notable exception is safe Bayesian optimization, which is a data-driven tuning approach for global optimization with noisy feedback. We propose and evaluate a step size-limited variant of safe Bayesian optimization on two research faculties of the Paul Scherrer Institut (PSI): a) the Swiss Free Electron Laser (SwissFEL) and b) the High-Intensity Proton Accelerator (HIPA). We report promising experimental results on both machines, tuning up to 16 parameters subject to more than 200 constraints.