 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Unified theory of atom-centered representations and graph convolutional machine-learning schemes
Feb 03, 2022
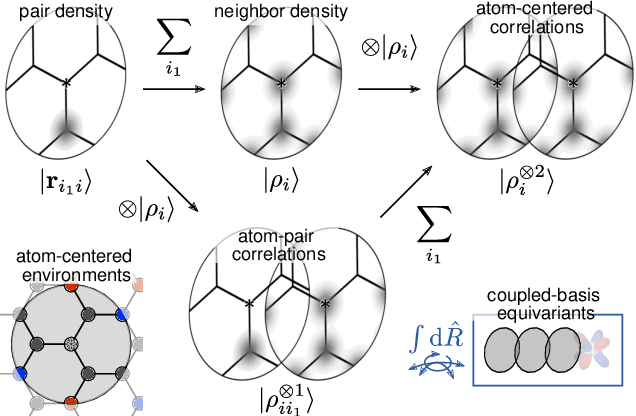
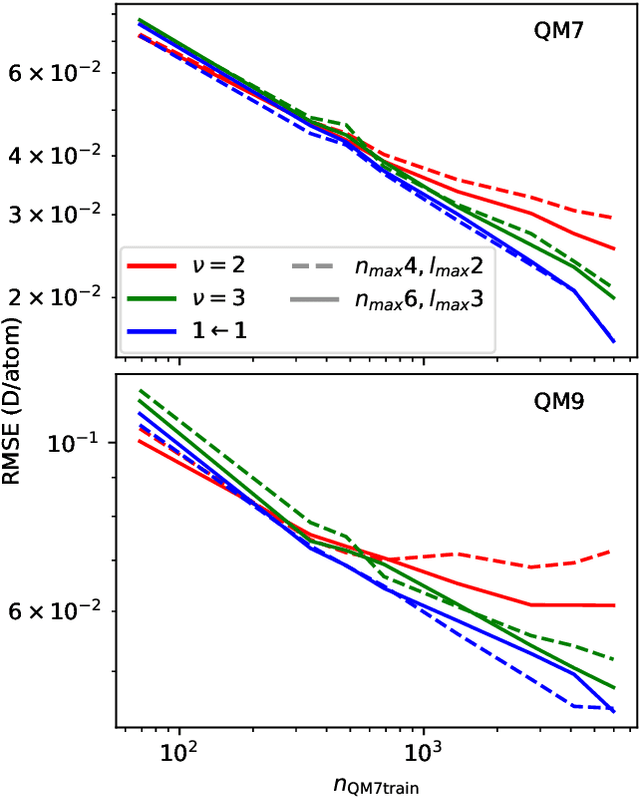

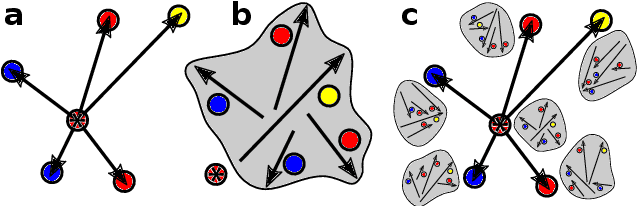
Data-driven schemes that associate molecular and crystal structures with their microscopic properties share the need for a concise, effective description of the arrangement of their atomic constituents. Many types of models rely on descriptions of atom-centered environments, that are associated with an atomic property or with an atomic contribution to an extensive macroscopic quantity. Frameworks in this class can be understood in terms of atom-centered density correlations (ACDC), that are used as a basis for a body-ordered, symmetry-adapted expansion of the targets. Several other schemes, that gather information on the relationship between neighboring atoms using graph-convolutional (or message-passing) ideas, cannot be directly mapped to correlations centered around a single atom. We generalize the ACDC framework to include multi-centered information, generating representations that provide a complete linear basis to regress symmetric functions of atomic coordinates, and form the basis to systematize our understanding of both atom-centered and graph-convolutional machine-learning schemes.
Temporal Walk Centrality: Ranking Nodes in Evolving Networks
Feb 08, 2022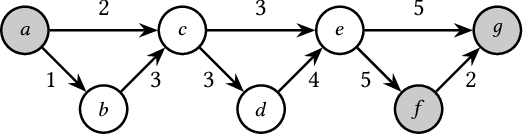



We propose the Temporal Walk Centrality, which quantifies the importance of a node by measuring its ability to obtain and distribute information in a temporal network. In contrast to the widely-used betweenness centrality, we assume that information does not necessarily spread on shortest paths but on temporal random walks that satisfy the time constraints of the network. We show that temporal walk centrality can identify nodes playing central roles in dissemination processes that might not be detected by related betweenness concepts and other common static and temporal centrality measures. We propose exact and approximation algorithms with different running times depending on the properties of the temporal network and parameters of our new centrality measure. A technical contribution is a general approach to lift existing algebraic methods for counting walks in static networks to temporal networks. Our experiments on real-world temporal networks show the efficiency and accuracy of our algorithms. Finally, we demonstrate that the rankings by temporal walk centrality often differ significantly from those of other state-of-the-art temporal centralities.
Fortuitous Forgetting in Connectionist Networks
Feb 01, 2022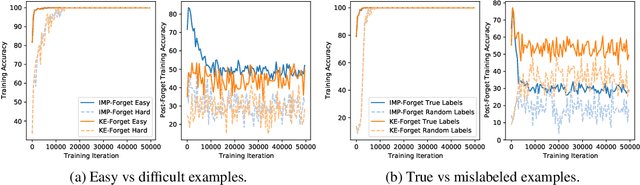
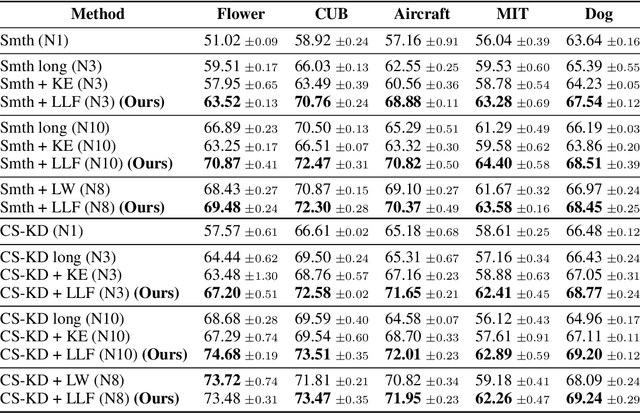
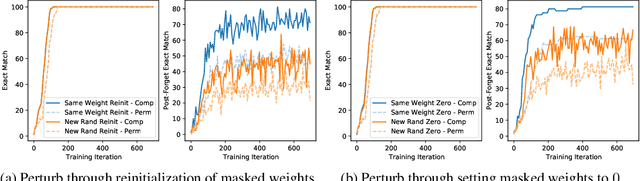
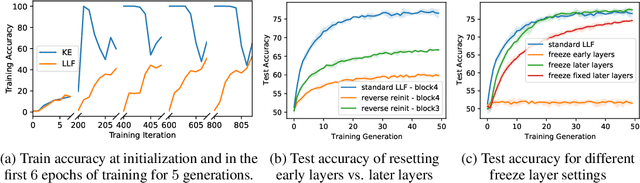
Forgetting is often seen as an unwanted characteristic in both human and machine learning. However, we propose that forgetting can in fact be favorable to learning. We introduce "forget-and-relearn" as a powerful paradigm for shaping the learning trajectories of artificial neural networks. In this process, the forgetting step selectively removes undesirable information from the model, and the relearning step reinforces features that are consistently useful under different conditions. The forget-and-relearn framework unifies many existing iterative training algorithms in the image classification and language emergence literature, and allows us to understand the success of these algorithms in terms of the disproportionate forgetting of undesirable information. We leverage this understanding to improve upon existing algorithms by designing more targeted forgetting operations. Insights from our analysis provide a coherent view on the dynamics of iterative training in neural networks and offer a clear path towards performance improvements.
* ICLR Camera Ready
Estimating Model Uncertainty of Neural Networks in Sparse Information Form
Jun 20, 2020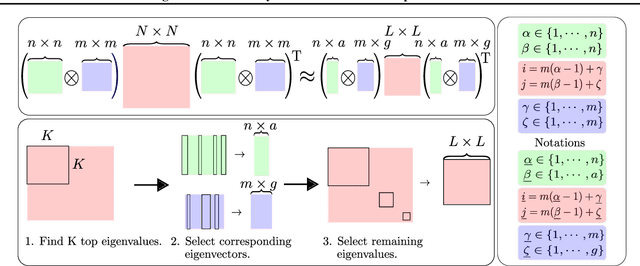
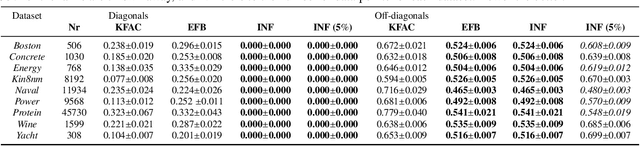
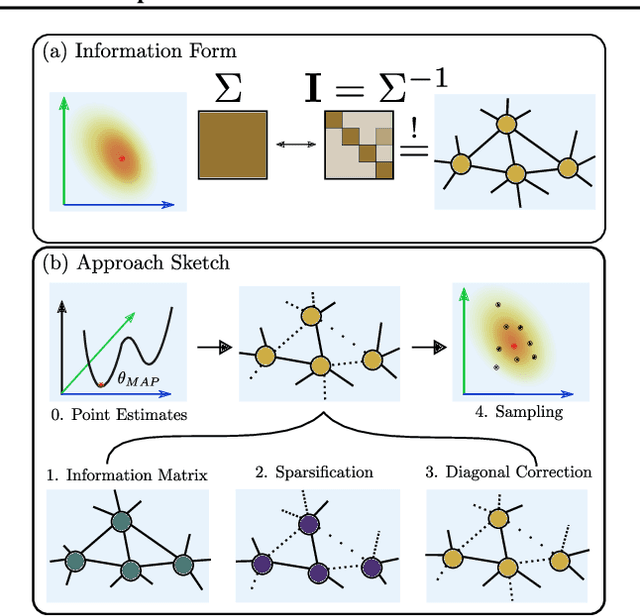

We present a sparse representation of model uncertainty for Deep Neural Networks (DNNs) where the parameter posterior is approximated with an inverse formulation of the Multivariate Normal Distribution (MND), also known as the information form. The key insight of our work is that the information matrix, i.e. the inverse of the covariance matrix tends to be sparse in its spectrum. Therefore, dimensionality reduction techniques such as low rank approximations (LRA) can be effectively exploited. To achieve this, we develop a novel sparsification algorithm and derive a cost-effective analytical sampler. As a result, we show that the information form can be scalably applied to represent model uncertainty in DNNs. Our exhaustive theoretical analysis and empirical evaluations on various benchmarks show the competitiveness of our approach over the current methods.
Gait Events Prediction using Hybrid CNN-RNN-based Deep Learning models through a Single Waist-worn Wearable Sensor
Feb 28, 2022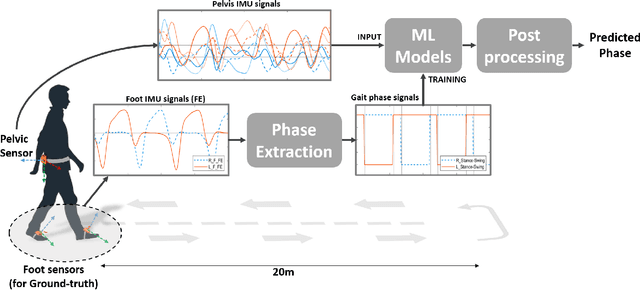
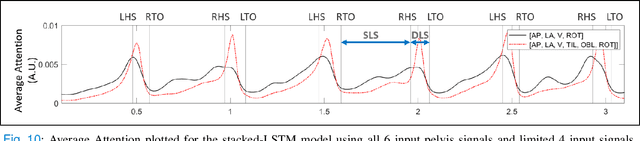
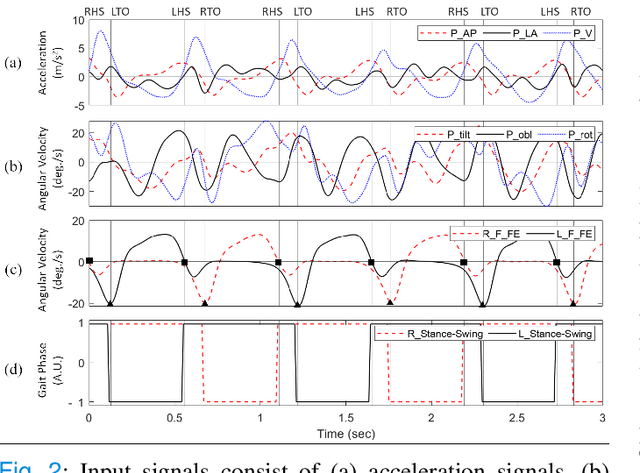

Elderly gait is a source of rich information about their physical and mental health condition. As an alternative to the multiple sensors on the lower body parts, a single sensor on the pelvis has a positional advantage and an abundance of information acquirable. This study aimed to explore a way of improving the accuracy of gait event detection in the elderly using a single sensor on the waist and deep learning models. Data was gathered from elderly subjects equipped with three IMU sensors while they walked. The input was taken only from the waist sensor was used to train 16 deep-learning models including CNN, RNN, and CNN-RNN hybrid with or without the Bidirectional and Attention mechanism. The groundtruth was extracted from foot IMU sensors. Fairly high accuracy of 99.73% and 93.89% was achieved by the CNN-BiGRU-Att model at the tolerance window of $\pm$6TS ($\pm$6ms) and $\pm$1TS ($\pm$1ms) respectively. Advancing from the previous studies exploring gait event detection, the model showed a great improvement in terms of its prediction error having an MAE of 6.239ms and 5.24ms for HS and TO events respectively at the tolerance window of $\pm$1TS. The results showed that the use of CNN-RNN hybrid models with Attention and Bidirectional mechanisms is promising for accurate gait event detection using a single waist sensor. The study can contribute to reducing the burden of gait detection and increase its applicability in future wearable devices that can be used for remote health monitoring (RHM) or diagnosis based thereon.
PatchTrack: Multiple Object Tracking Using Frame Patches
Jan 01, 2022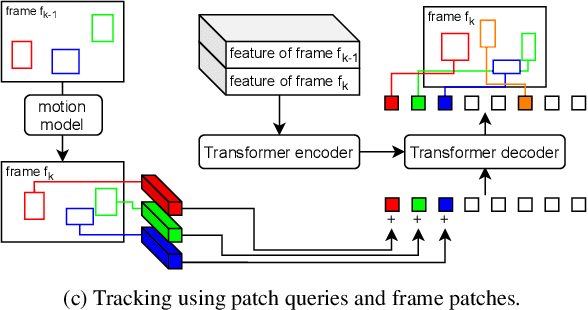
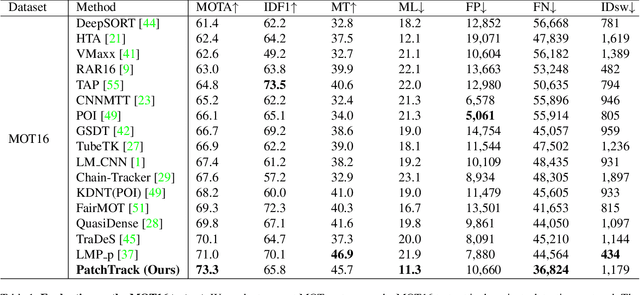
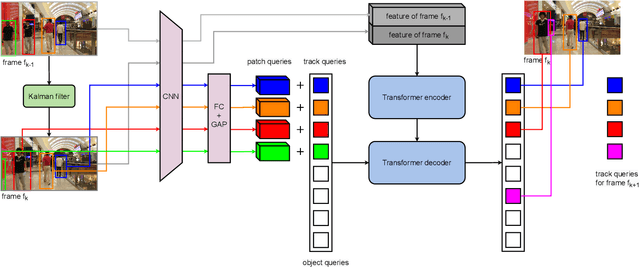
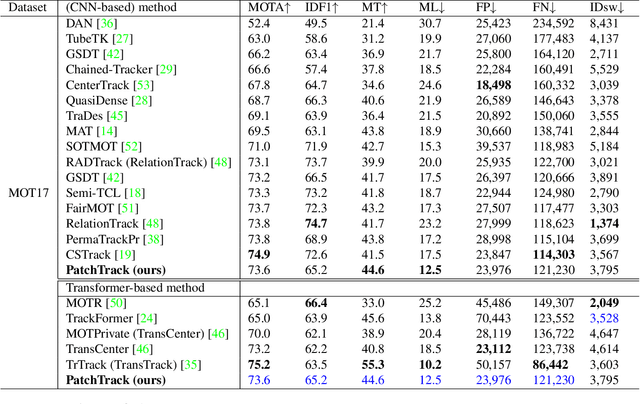
Object motion and object appearance are commonly used information in multiple object tracking (MOT) applications, either for associating detections across frames in tracking-by-detection methods or direct track predictions for joint-detection-and-tracking methods. However, not only are these two types of information often considered separately, but also they do not help optimize the usage of visual information from the current frame of interest directly. In this paper, we present PatchTrack, a Transformer-based joint-detection-and-tracking system that predicts tracks using patches of the current frame of interest. We use the Kalman filter to predict the locations of existing tracks in the current frame from the previous frame. Patches cropped from the predicted bounding boxes are sent to the Transformer decoder to infer new tracks. By utilizing both object motion and object appearance information encoded in patches, the proposed method pays more attention to where new tracks are more likely to occur. We show the effectiveness of PatchTrack on recent MOT benchmarks, including MOT16 (MOTA 73.71%, IDF1 65.77%) and MOT17 (MOTA 73.59%, IDF1 65.23%). The results are published on https://motchallenge.net/method/MOT=4725&chl=10.
ScalableViT: Rethinking the Context-oriented Generalization of Vision Transformer
Mar 21, 2022

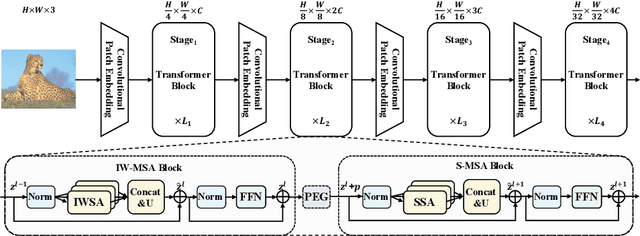
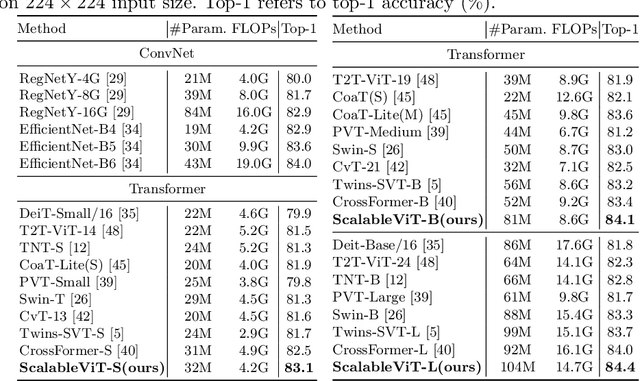
The vanilla self-attention mechanism inherently relies on pre-defined and steadfast computational dimensions. Such inflexibility restricts it from possessing context-oriented generalization that can bring more contextual cues and global representations. To mitigate this issue, we propose a Scalable Self-Attention (SSA) mechanism that leverages two scaling factors to release dimensions of query, key, and value matrix while unbinding them with the input. This scalability fetches context-oriented generalization and enhances object sensitivity, which pushes the whole network into a more effective trade-off state between accuracy and cost. Furthermore, we propose an Interactive Window-based Self-Attention (IWSA), which establishes interaction between non-overlapping regions by re-merging independent value tokens and aggregating spatial information from adjacent windows. By stacking the SSA and IWSA alternately, the Scalable Vision Transformer (ScalableViT) achieves state-of-the-art performance in general-purpose vision tasks. For example, ScalableViT-S outperforms Twins-SVT-S by 1.4% and Swin-T by 1.8% on ImageNet-1K classification.
Collapse by Conditioning: Training Class-conditional GANs with Limited Data
Jan 17, 2022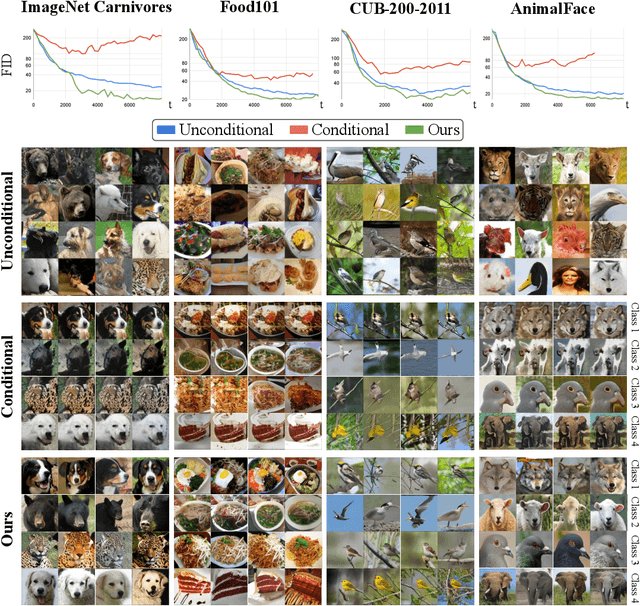
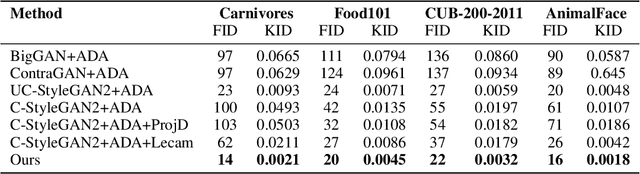

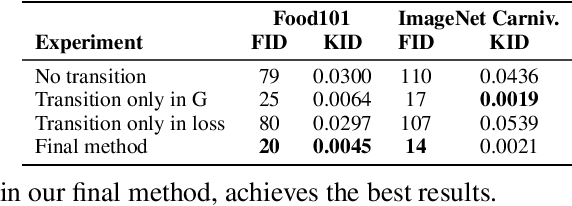
Class-conditioning offers a direct means of controlling a Generative Adversarial Network (GAN) based on a discrete input variable. While necessary in many applications, the additional information provided by the class labels could even be expected to benefit the training of the GAN itself. Contrary to this belief, we observe that class-conditioning causes mode collapse in limited data settings, where unconditional learning leads to satisfactory generative ability. Motivated by this observation, we propose a training strategy for conditional GANs (cGANs) that effectively prevents the observed mode-collapse by leveraging unconditional learning. Our training strategy starts with an unconditional GAN and gradually injects conditional information into the generator and the objective function. The proposed method for training cGANs with limited data results not only in stable training but also in generating high-quality images, thanks to the early-stage exploitation of the shared information across classes. We analyze the aforementioned mode collapse problem in comprehensive experiments on four datasets. Our approach demonstrates outstanding results compared with state-of-the-art methods and established baselines. The code is available at: https://github.com/mshahbazi72/transitional-cGAN
Article Reranking by Memory-Enhanced Key Sentence Matching for Detecting Previously Fact-Checked Claims
Dec 20, 2021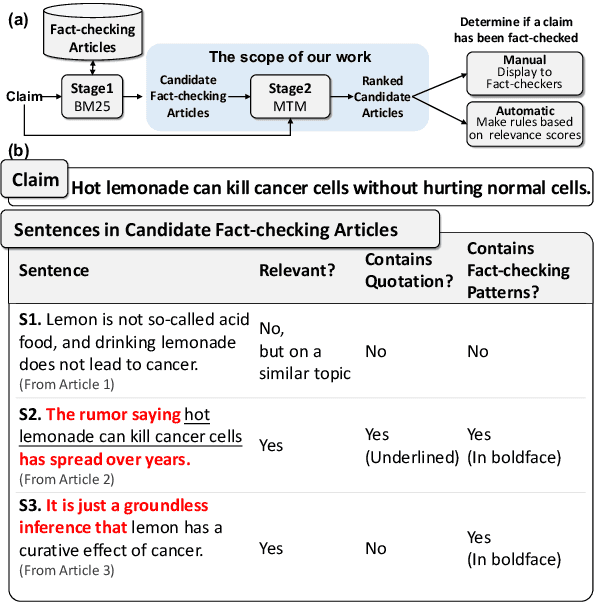
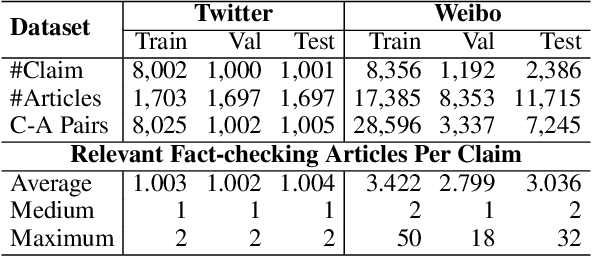
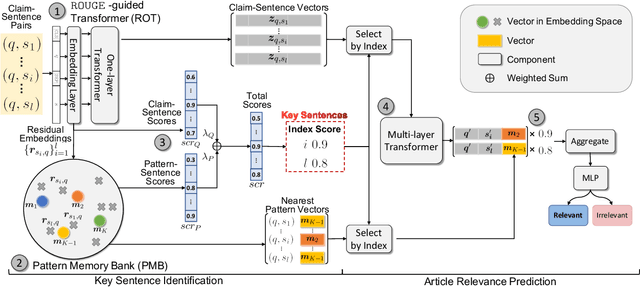
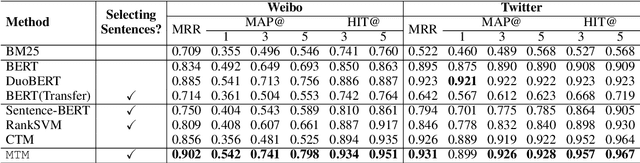
False claims that have been previously fact-checked can still spread on social media. To mitigate their continual spread, detecting previously fact-checked claims is indispensable. Given a claim, existing works focus on providing evidence for detection by reranking candidate fact-checking articles (FC-articles) retrieved by BM25. However, these performances may be limited because they ignore the following characteristics of FC-articles: (1) claims are often quoted to describe the checked events, providing lexical information besides semantics; (2) sentence templates to introduce or debunk claims are common across articles, providing pattern information. Models that ignore the two aspects only leverage semantic relevance and may be misled by sentences that describe similar but irrelevant events. In this paper, we propose a novel reranker, MTM (Memory-enhanced Transformers for Matching) to rank FC-articles using key sentences selected with event (lexical and semantic) and pattern information. For event information, we propose a ROUGE-guided Transformer which is finetuned with regression of ROUGE. For pattern information, we generate pattern vectors for matching with sentences. By fusing event and pattern information, we select key sentences to represent an article and then predict if the article fact-checks the given claim using the claim, key sentences, and patterns. Experiments on two real-world datasets show that MTM outperforms existing methods. Human evaluation proves that MTM can capture key sentences for explanations. The code and the dataset are at https://github.com/ICTMCG/MTM.
OmiEmbed: reconstruct comprehensive phenotypic information from multi-omics data using multi-task deep learning
Feb 03, 2021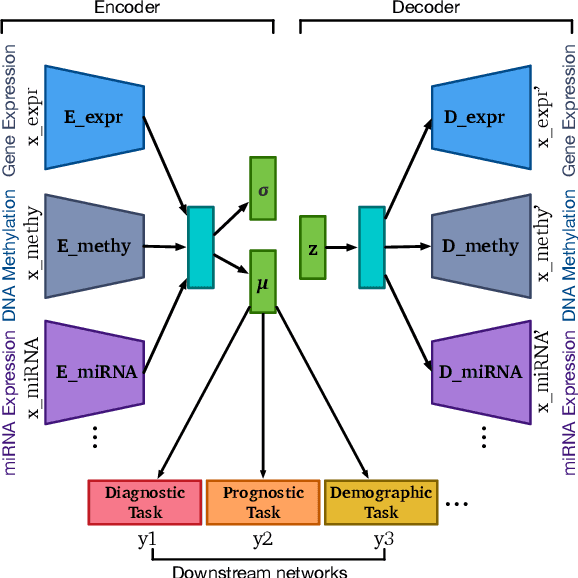
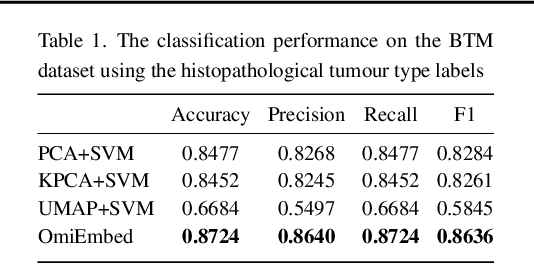
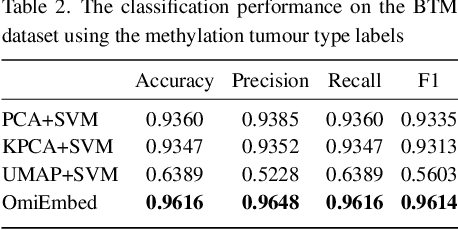
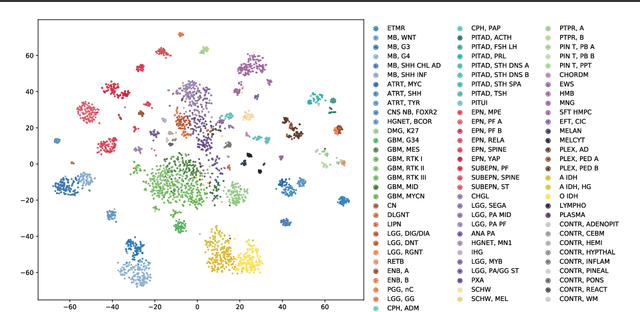
High-dimensional omics data contains intrinsic biomedical information that is crucial for personalised medicine. Nevertheless, it is challenging to capture them from the genome-wide data due to the large number of molecular features and small number of available samples, which is also called "the curse of dimensionality" in machine learning. To tackle this problem and pave the way for machine learning aided precision medicine, we proposed a unified multi-task deep learning framework called OmiEmbed to capture a holistic and relatively precise profile of phenotype from high-dimensional omics data. The deep embedding module of OmiEmbed learnt an omics embedding that mapped multiple omics data types into a latent space with lower dimensionality. Based on the new representation of multi-omics data, different downstream networks of OmiEmbed were trained together with the multi-task strategy to predict the comprehensive phenotype profile of each sample. We trained the model on two publicly available omics datasets to evaluate the performance of OmiEmbed. The OmiEmbed model achieved promising results for multiple downstream tasks including dimensionality reduction, tumour type classification, multi-omics integration, demographic and clinical feature reconstruction, and survival prediction. Instead of training and applying different downstream networks separately, the multi-task strategy combined them together and conducted multiple tasks simultaneously and efficiently. The model achieved better performance with the multi-task strategy comparing to training them individually. OmiEmbed is a powerful tool to accurately capture comprehensive phenotypic information from high-dimensional omics data and has a great potential to facilitate more accurate and personalised clinical decision making.