 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Zealous and Restrained AI Recommendations in a Real-World Human-AI Collaboration Task
Oct 06, 2024



When designing an AI-assisted decision-making system, there is often a tradeoff between precision and recall in the AI's recommendations. We argue that careful exploitation of this tradeoff can harness the complementary strengths in the human-AI collaboration to significantly improve team performance. We investigate a real-world video anonymization task for which recall is paramount and more costly to improve. We analyze the performance of 78 professional annotators working with a) no AI assistance, b) a high-precision "restrained" AI, and c) a high-recall "zealous" AI in over 3,466 person-hours of annotation work. In comparison, the zealous AI helps human teammates achieve significantly shorter task completion time and higher recall. In a follow-up study, we remove AI assistance for everyone and find negative training effects on annotators trained with the restrained AI. These findings and our analysis point to important implications for the design of AI assistance in recall-demanding scenarios.
* 15 pages, 14 figures, accepted to ACM CHI 2023
TiNO-Edit: Timestep and Noise Optimization for Robust Diffusion-Based Image Editing
Apr 17, 2024Despite many attempts to leverage pre-trained text-to-image models (T2I) like Stable Diffusion (SD) for controllable image editing, producing good predictable results remains a challenge. Previous approaches have focused on either fine-tuning pre-trained T2I models on specific datasets to generate certain kinds of images (e.g., with a specific object or person), or on optimizing the weights, text prompts, and/or learning features for each input image in an attempt to coax the image generator to produce the desired result. However, these approaches all have shortcomings and fail to produce good results in a predictable and controllable manner. To address this problem, we present TiNO-Edit, an SD-based method that focuses on optimizing the noise patterns and diffusion timesteps during editing, something previously unexplored in the literature. With this simple change, we are able to generate results that both better align with the original images and reflect the desired result. Furthermore, we propose a set of new loss functions that operate in the latent domain of SD, greatly speeding up the optimization when compared to prior approaches, which operate in the pixel domain. Our method can be easily applied to variations of SD including Textual Inversion and DreamBooth that encode new concepts and incorporate them into the edited results. We present a host of image-editing capabilities enabled by our approach. Our code is publicly available at https://github.com/SherryXTChen/TiNO-Edit.
Pair DETR: Contrastive Learning Speeds Up DETR Training
Nov 11, 2022



The DETR object detection approach applies the transformer encoder and decoder architecture to detect objects and achieves promising performance. In this paper, we present a simple approach to address the main problem of DETR, the slow convergence, by using representation learning technique. In this approach, we detect an object bounding box as a pair of keypoints, the top-left corner and the center, using two decoders. By detecting objects as paired keypoints, the model builds up a joint classification and pair association on the output queries from two decoders. For the pair association we propose utilizing contrastive self-supervised learning algorithm without requiring specialized architecture. Experimental results on MS COCO dataset show that Pair DETR can converge at least 10x faster than original DETR and 1.5x faster than Conditional DETR during training, while having consistently higher Average Precision scores.
PatchTrack: Multiple Object Tracking Using Frame Patches
Jan 01, 2022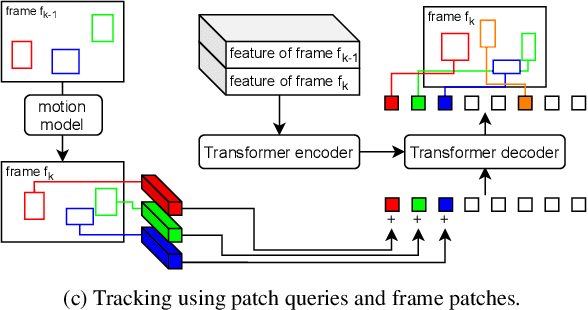
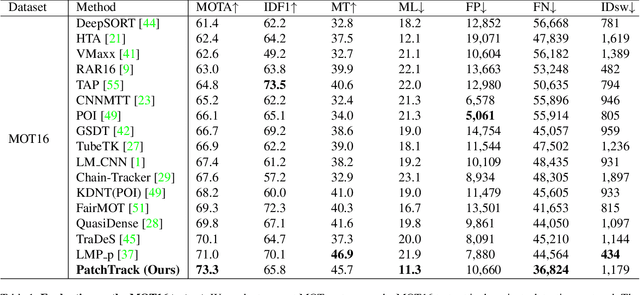
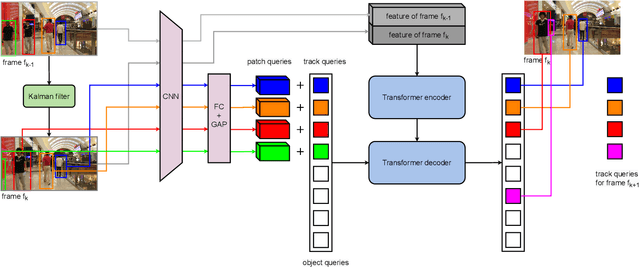
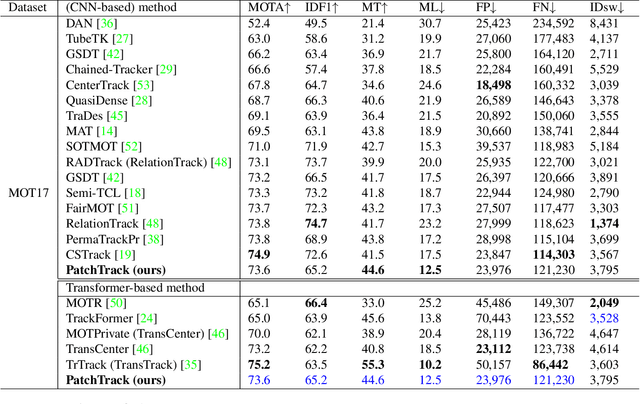
Object motion and object appearance are commonly used information in multiple object tracking (MOT) applications, either for associating detections across frames in tracking-by-detection methods or direct track predictions for joint-detection-and-tracking methods. However, not only are these two types of information often considered separately, but also they do not help optimize the usage of visual information from the current frame of interest directly. In this paper, we present PatchTrack, a Transformer-based joint-detection-and-tracking system that predicts tracks using patches of the current frame of interest. We use the Kalman filter to predict the locations of existing tracks in the current frame from the previous frame. Patches cropped from the predicted bounding boxes are sent to the Transformer decoder to infer new tracks. By utilizing both object motion and object appearance information encoded in patches, the proposed method pays more attention to where new tracks are more likely to occur. We show the effectiveness of PatchTrack on recent MOT benchmarks, including MOT16 (MOTA 73.71%, IDF1 65.77%) and MOT17 (MOTA 73.59%, IDF1 65.23%). The results are published on https://motchallenge.net/method/MOT=4725&chl=10.
Structure-Attentioned Memory Network for Monocular Depth Estimation
Sep 10, 2019
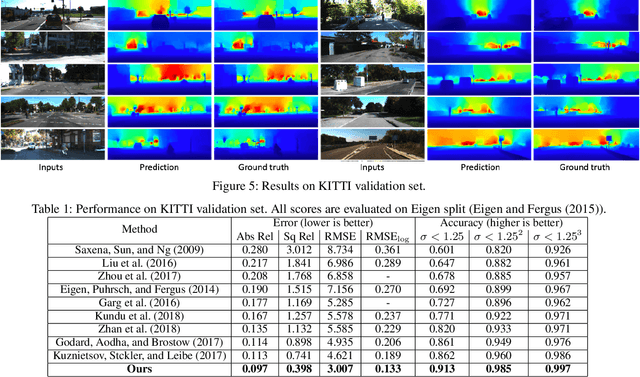
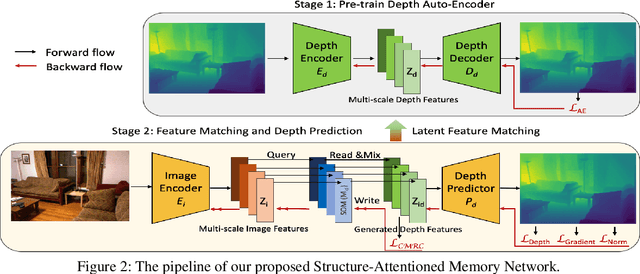
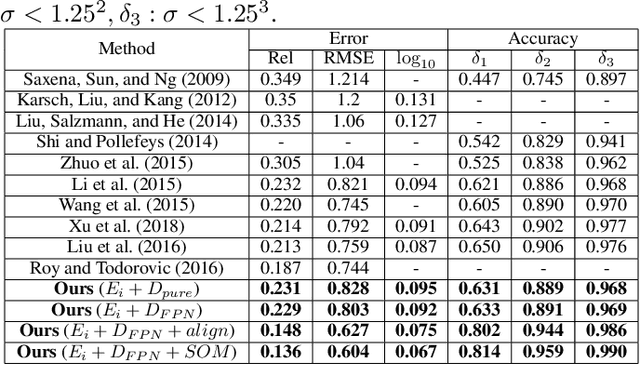
Monocular depth estimation is a challenging task that aims to predict a corresponding depth map from a given single RGB image. Recent deep learning models have been proposed to predict the depth from the image by learning the alignment of deep features between the RGB image and the depth domains. In this paper, we present a novel approach, named Structure-Attentioned Memory Network, to more effectively transfer domain features for monocular depth estimation by taking into account the common structure regularities (e.g., repetitive structure patterns, planar surfaces, symmetries) in domain adaptation. To this end, we introduce a new Structure-Oriented Memory (SOM) module to learn and memorize the structure-specific information between RGB image domain and the depth domain. More specifically, in the SOM module, we develop a Memorable Bank of Filters (MBF) unit to learn a set of filters that memorize the structure-aware image-depth residual pattern, and also an Attention Guided Controller (AGC) unit to control the filter selection in the MBF given image features queries. Given the query image feature, the trained SOM module is able to adaptively select the best customized filters for cross-domain feature transferring with an optimal structural disparity between image and depth. In summary, we focus on addressing this structure-specific domain adaption challenge by proposing a novel end-to-end multi-scale memorable network for monocular depth estimation. The experiments show that our proposed model demonstrates the superior performance compared to the existing supervised monocular depth estimation approaches on the challenging KITTI and NYU Depth V2 benchmarks.
Learning Object-specific Distance from a Monocular Image
Sep 09, 2019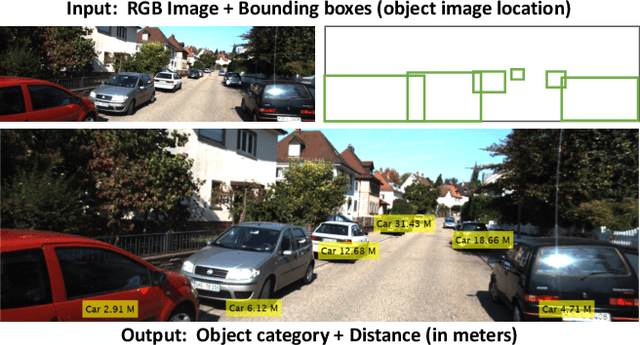
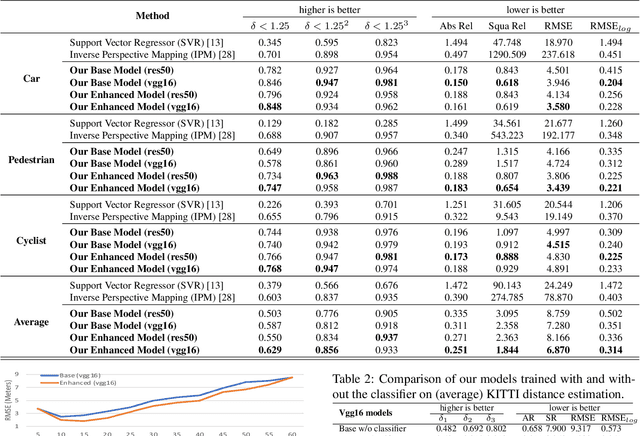
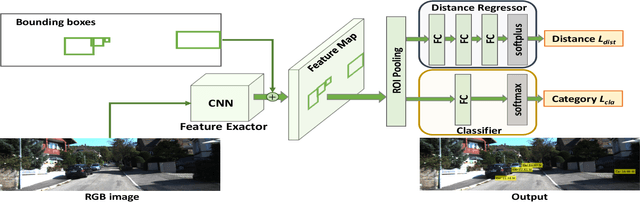
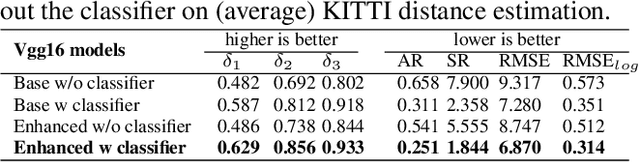
Environment perception, including object detection and distance estimation, is one of the most crucial tasks for autonomous driving. Many attentions have been paid on the object detection task, but distance estimation only arouse few interests in the computer vision community. Observing that the traditional inverse perspective mapping algorithm performs poorly for objects far away from the camera or on the curved road, in this paper, we address the challenging distance estimation problem by developing the first end-to-end learning-based model to directly predict distances for given objects in the images. Besides the introduction of a learning-based base model, we further design an enhanced model with a keypoint regressor, where a projection loss is defined to enforce a better distance estimation, especially for objects close to the camera. To facilitate the research on this task, we construct the extented KITTI and nuScenes (mini) object detection datasets with a distance for each object. Our experiments demonstrate that our proposed methods outperform alternative approaches (e.g., the traditional IPM, SVR) on object-specific distance estimation, particularly for the challenging cases that objects are on a curved road. Moreover, the performance margin implies the effectiveness of our enhanced method.