 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Visible-Thermal UAV Tracking: A Large-Scale Benchmark and New Baseline
Apr 08, 2022

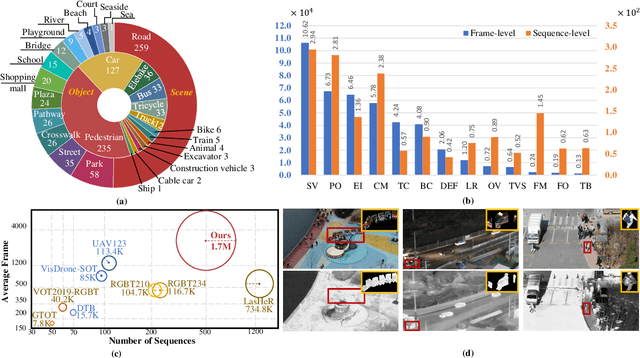
With the popularity of multi-modal sensors, visible-thermal (RGB-T) object tracking is to achieve robust performance and wider application scenarios with the guidance of objects' temperature information. However, the lack of paired training samples is the main bottleneck for unlocking the power of RGB-T tracking. Since it is laborious to collect high-quality RGB-T sequences, recent benchmarks only provide test sequences. In this paper, we construct a large-scale benchmark with high diversity for visible-thermal UAV tracking (VTUAV), including 500 sequences with 1.7 million high-resolution (1920 $\times$ 1080 pixels) frame pairs. In addition, comprehensive applications (short-term tracking, long-term tracking and segmentation mask prediction) with diverse categories and scenes are considered for exhaustive evaluation. Moreover, we provide a coarse-to-fine attribute annotation, where frame-level attributes are provided to exploit the potential of challenge-specific trackers. In addition, we design a new RGB-T baseline, named Hierarchical Multi-modal Fusion Tracker (HMFT), which fuses RGB-T data in various levels. Numerous experiments on several datasets are conducted to reveal the effectiveness of HMFT and the complement of different fusion types. The project is available at here.
Spatio-Temporal Outdoor Lighting Aggregation on Image Sequences using Transformer Networks
Feb 18, 2022In this work, we focus on outdoor lighting estimation by aggregating individual noisy estimates from images, exploiting the rich image information from wide-angle cameras and/or temporal image sequences. Photographs inherently encode information about the scene's lighting in the form of shading and shadows. Recovering the lighting is an inverse rendering problem and as that ill-posed. Recent work based on deep neural networks has shown promising results for single image lighting estimation, but suffers from robustness. We tackle this problem by combining lighting estimates from several image views sampled in the angular and temporal domain of an image sequence. For this task, we introduce a transformer architecture that is trained in an end-2-end fashion without any statistical post-processing as required by previous work. Thereby, we propose a positional encoding that takes into account the camera calibration and ego-motion estimation to globally register the individual estimates when computing attention between visual words. We show that our method leads to improved lighting estimation while requiring less hyper-parameters compared to the state-of-the-art.
UoB at SemEval-2020 Task 12: Boosting BERT with Corpus Level Information
Aug 19, 2020
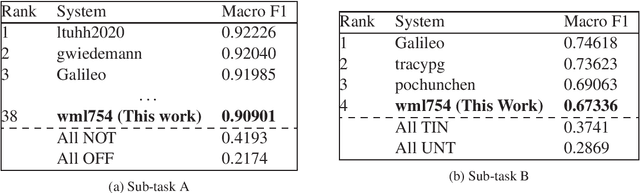
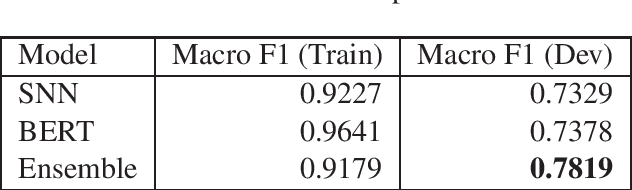
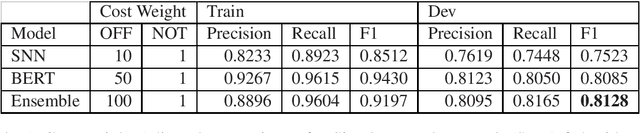
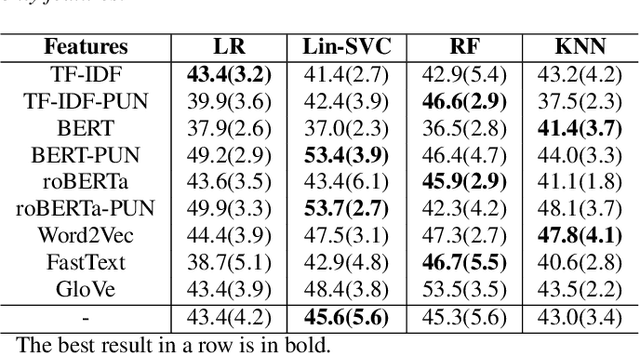
Pre-trained language model word representation, such as BERT, have been extremely successful in several Natural Language Processing tasks significantly improving on the state-of-the-art. This can largely be attributed to their ability to better capture semantic information contained within a sentence. Several tasks, however, can benefit from information available at a corpus level, such as Term Frequency-Inverse Document Frequency (TF-IDF). In this work we test the effectiveness of integrating this information with BERT on the task of identifying abuse on social media and show that integrating this information with BERT does indeed significantly improve performance. We participate in Sub-Task A (abuse detection) wherein we achieve a score within two points of the top performing team and in Sub-Task B (target detection) wherein we are ranked 4 of the 44 participating teams.
Automatic Detection of Expressed Emotion from Five-Minute Speech Samples: Challenges and Opportunities
Mar 30, 2022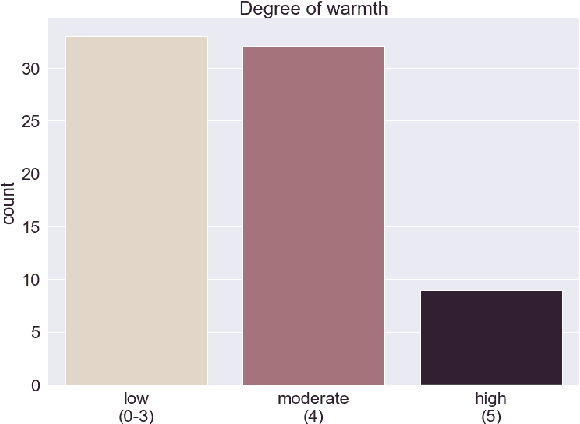
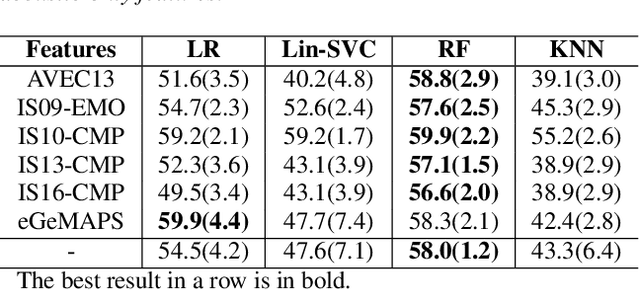
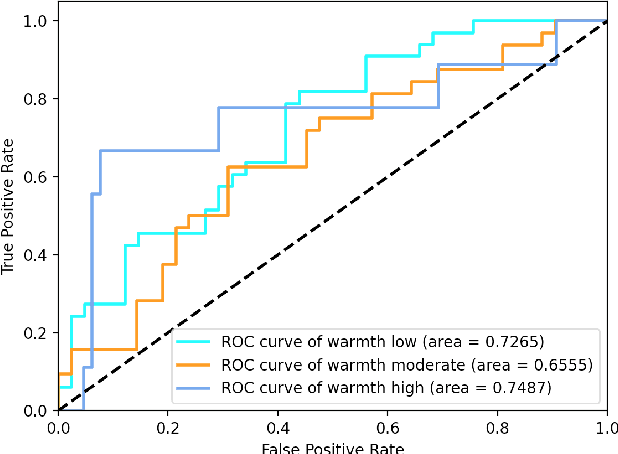
We present a novel feasibility study on the automatic recognition of Expressed Emotion (EE), a family environment concept based on caregivers speaking freely about their relative/family member. We describe an automated approach for determining the \textit{degree of warmth}, a key component of EE, from acoustic and text features acquired from a sample of 37 recorded interviews. These recordings, collected over 20 years ago, are derived from a nationally representative birth cohort of 2,232 British twin children and were manually coded for EE. We outline the core steps of extracting usable information from recordings with highly variable audio quality and assess the efficacy of four machine learning approaches trained with different combinations of acoustic and text features. Despite the challenges of working with this legacy data, we demonstrated that the degree of warmth can be predicted with an $F_{1}$-score of \textbf{61.5\%}. In this paper, we summarise our learning and provide recommendations for future work using real-world speech samples.
Into-TTS : Intonation Template based Prosody Control System
Apr 04, 2022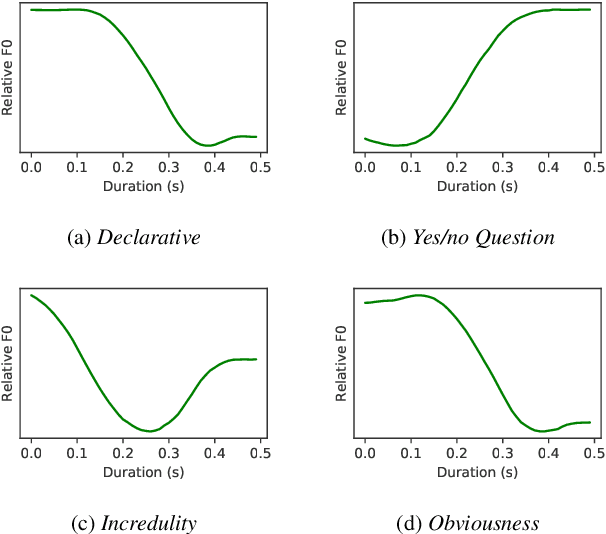

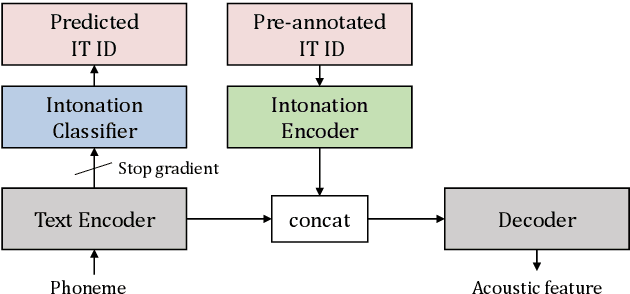
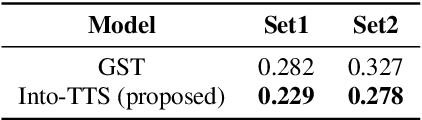
Intonations take an important role in delivering the intention of the speaker. However, current end-to-end TTS systems often fail to model proper intonations. To alleviate this problem, we propose a novel, intuitive method to synthesize speech in different intonations using predefined intonation templates. Prior to the acoustic model training, speech data are automatically grouped into intonation templates by k-means clustering, according to their sentence-final F0 contour. Two proposed modules are added to the end-to-end TTS framework: intonation classifier and intonation encoder. The intonation classifier recommends a suitable intonation template to the given text. The intonation encoder, attached to the text encoder output, synthesizes speech abiding the requested intonation template. Main contributions of our paper are: (a) an easy-to-use intonation control system covering a wide range of users; (b) better performance in wrapping speech in a requested intonation with improved pitch distance and MOS; and (c) feasibility to future integration between TTS and NLP, TTS being able to utilize contextual information. Audio samples are available at https://srtts.github.io/IntoTTS.
Three-Stream Joint Network for Zero-Shot Sketch-Based Image Retrieval
Apr 12, 2022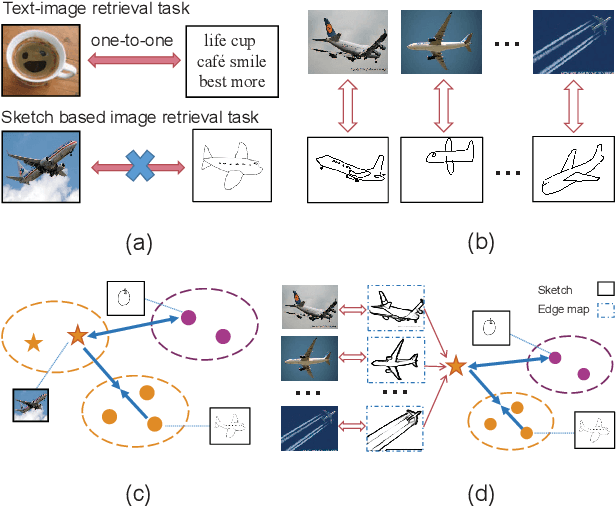
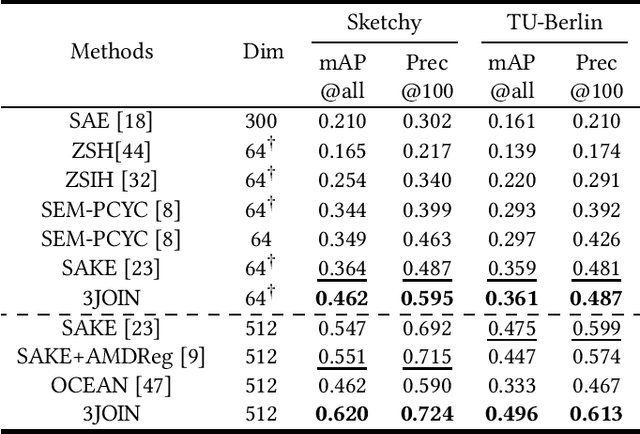
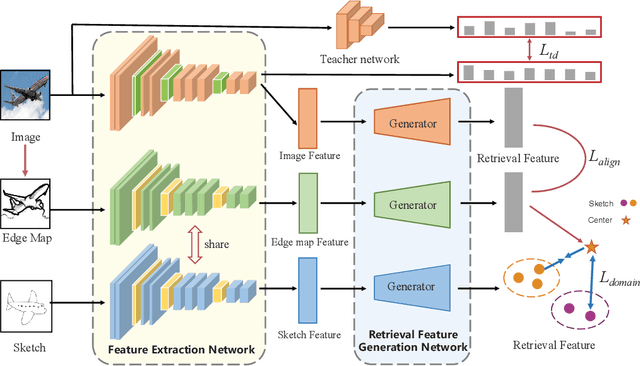
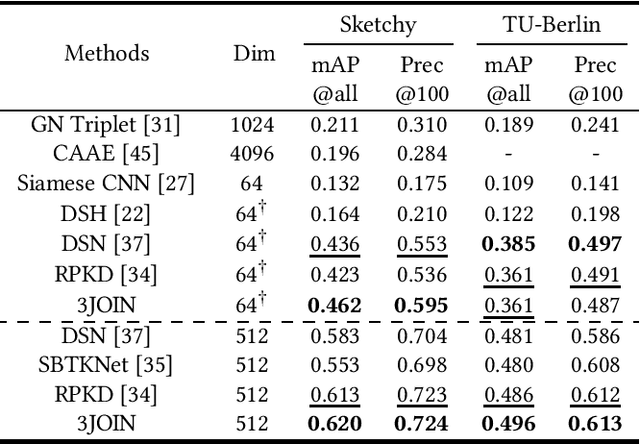
The Zero-Shot Sketch-based Image Retrieval (ZS-SBIR) is a challenging task because of the large domain gap between sketches and natural images as well as the semantic inconsistency between seen and unseen categories. Previous literature bridges seen and unseen categories by semantic embedding, which requires prior knowledge of the exact class names and additional extraction efforts. And most works reduce domain gap by mapping sketches and natural images into a common high-level space using constructed sketch-image pairs, which ignore the unpaired information between images and sketches. To address these issues, in this paper, we propose a novel Three-Stream Joint Training Network (3JOIN) for the ZS-SBIR task. To narrow the domain differences between sketches and images, we extract edge maps for natural images and treat them as a bridge between images and sketches, which have similar content to images and similar style to sketches. For exploiting a sufficient combination of sketches, natural images, and edge maps, a novel three-stream joint training network is proposed. In addition, we use a teacher network to extract the implicit semantics of the samples without the aid of other semantics and transfer the learned knowledge to unseen classes. Extensive experiments conducted on two real-world datasets demonstrate the superiority of our proposed method.
UTIL: An Ultra-wideband Time-difference-of-arrival Indoor Localization Dataset
Mar 28, 2022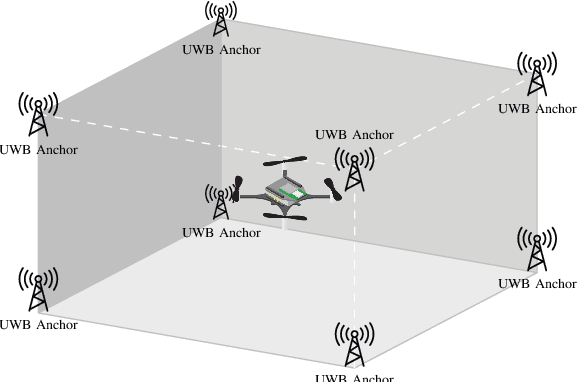
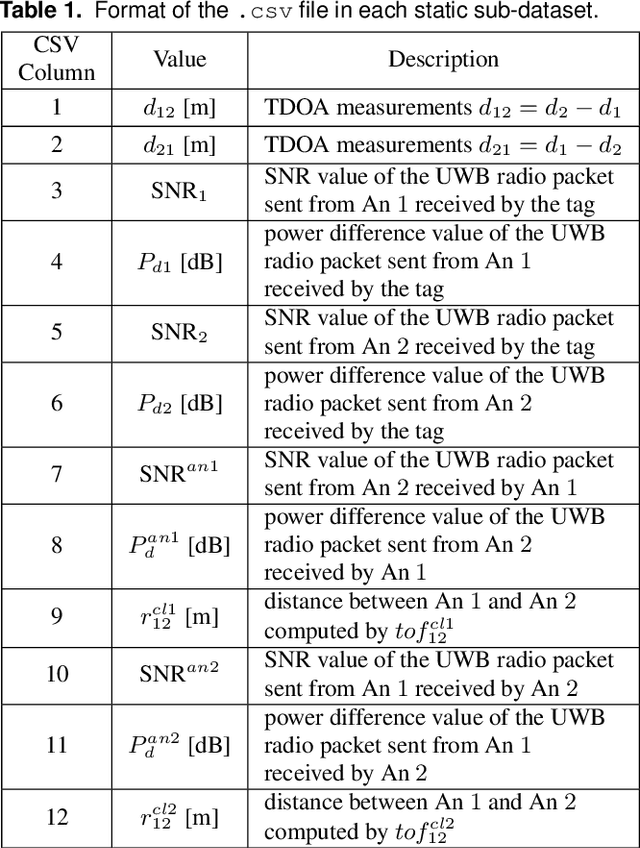
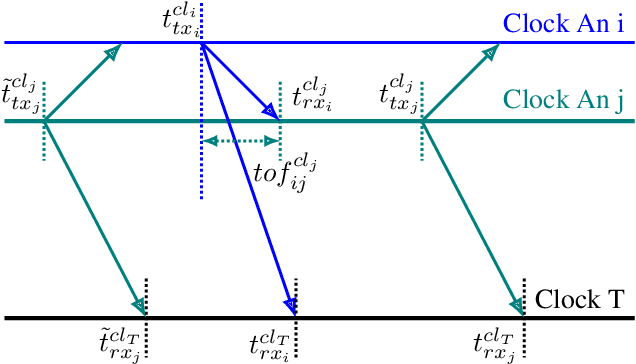
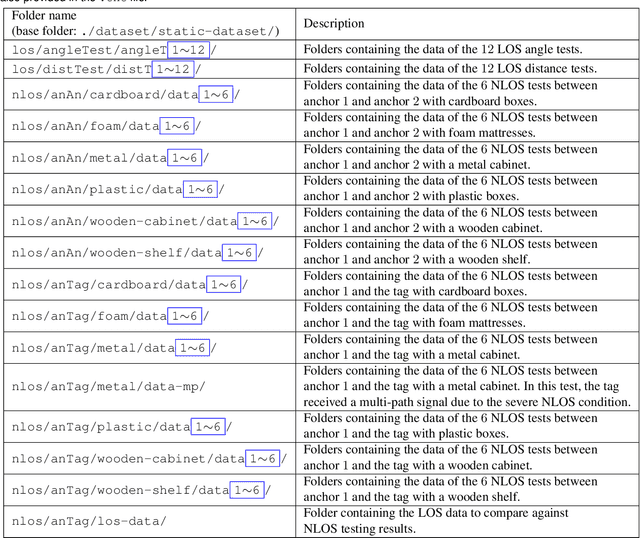
This paper presents an ultra-wideband (UWB) time-difference-of-arrival (TDOA) dataset collected from a quadrotor for research purposes. The dataset consists of low-level signal information from static experiments and UWB TDOA measurements and additional onboard sensor data from flight experiments on a quadrotor. The data collection process is discussed in detail, including the equipment used, measurement collection procedure, and the calibration of the quadrotor platform. All the data is made available as plain text files and we provide both Matlab and Python scripts to parse and analyze the data. We provide a thorough description of the data format and some pointers on the potential usage of each sub-dataset. The dataset is available for download at https://utiasdsl.github.io/util-uwb-dataset/. We hope this dataset will help researchers develop and compare reliable estimation methods for the emerging UWB TDOA-based indoor localization technology.
Learning Robust Representations via Multi-View Information Bottleneck
Feb 18, 2020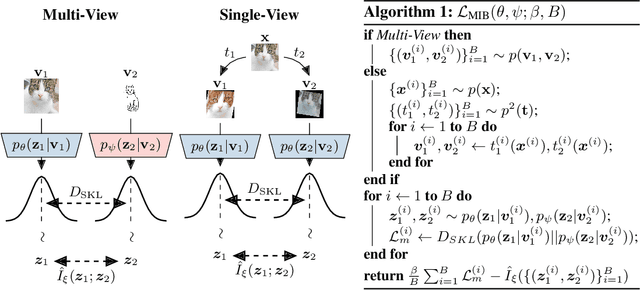
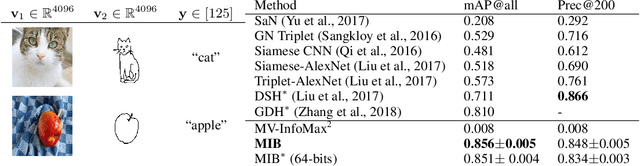
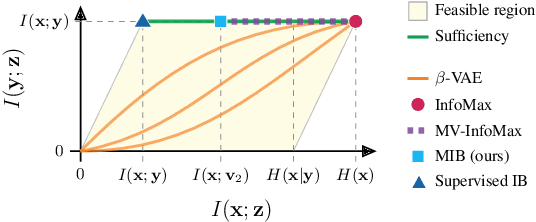

The information bottleneck principle provides an information-theoretic method for representation learning, by training an encoder to retain all information which is relevant for predicting the label while minimizing the amount of other, excess information in the representation. The original formulation, however, requires labeled data to identify the superfluous information. In this work, we extend this ability to the multi-view unsupervised setting, where two views of the same underlying entity are provided but the label is unknown. This enables us to identify superfluous information as that not shared by both views. A theoretical analysis leads to the definition of a new multi-view model that produces state-of-the-art results on the Sketchy dataset and label-limited versions of the MIR-Flickr dataset. We also extend our theory to the single-view setting by taking advantage of standard data augmentation techniques, empirically showing better generalization capabilities when compared to common unsupervised approaches for representation learning.
AMS_ADRN at SemEval-2022 Task 5: A Suitable Image-text Multimodal Joint Modeling Method for Multi-task Misogyny Identification
Feb 18, 2022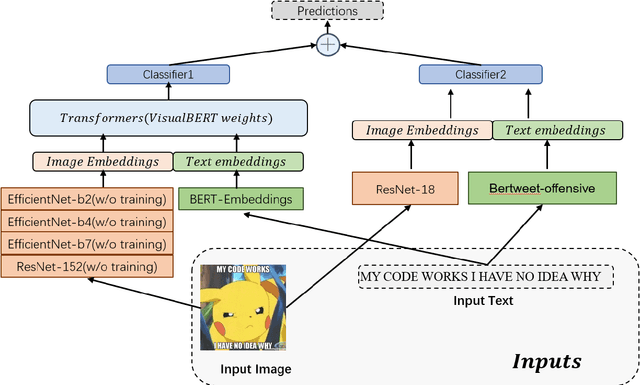

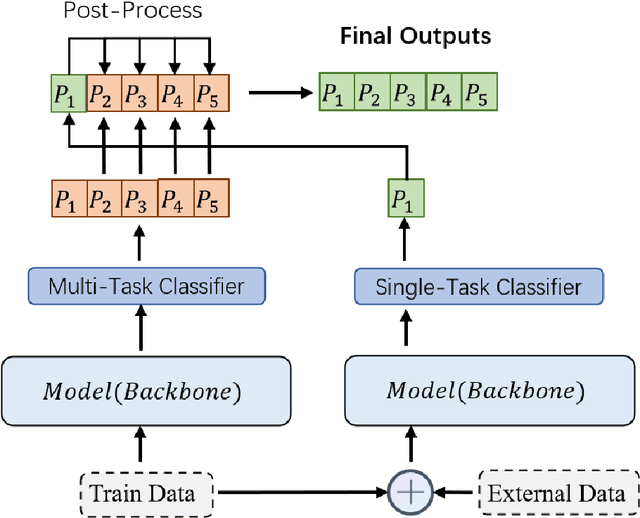
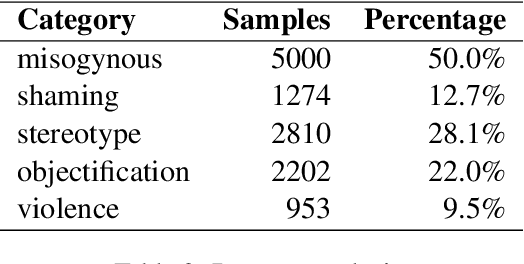
Women are influential online, especially in image-based social media such as Twitter and Instagram. However, many in the network environment contain gender discrimination and aggressive information, which magnify gender stereotypes and gender inequality. Therefore, the filtering of illegal content such as gender discrimination is essential to maintain a healthy social network environment. In this paper, we describe the system developed by our team for SemEval-2022 Task 5: Multimedia Automatic Misogyny Identification. More specifically, we introduce two novel system to analyze these posts: a multimodal multi-task learning architecture that combines Bertweet for text encoding with ResNet-18 for image representation, and a single-flow transformer structure which combines text embeddings from BERT-Embeddings and image embeddings from several different modules such as EfficientNet and ResNet. In this manner, we show that the information behind them can be properly revealed. Our approach achieves good performance on each of the two subtasks of the current competition, ranking 15th for Subtask A (0.746 macro F1-score), 11th for Subtask B (0.706 macro F1-score) while exceeding the official baseline results by high margins.
CAT-Det: Contrastively Augmented Transformer for Multi-modal 3D Object Detection
Apr 04, 2022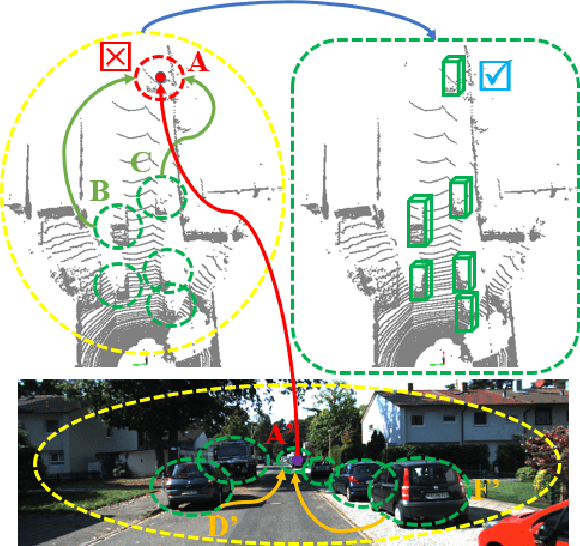
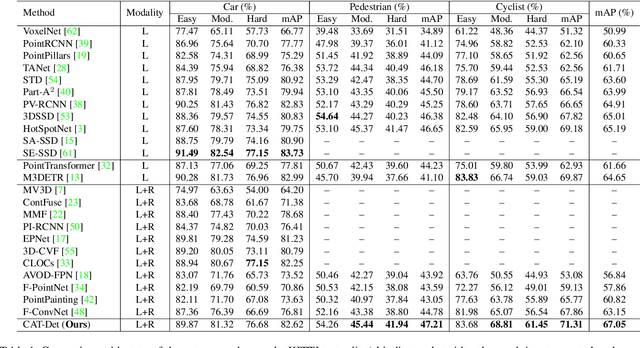
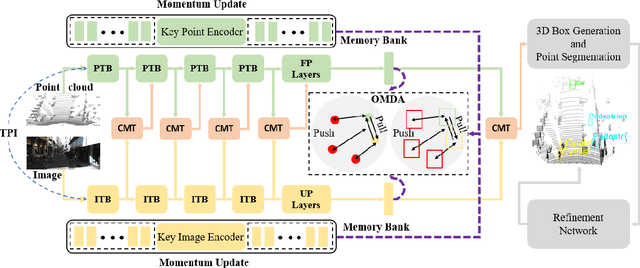
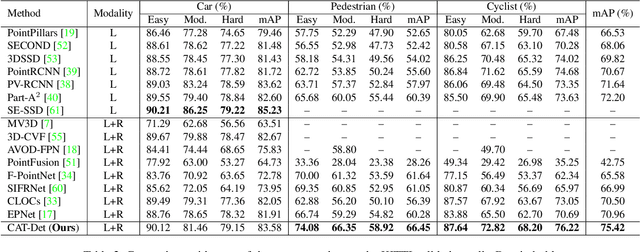
In autonomous driving, LiDAR point-clouds and RGB images are two major data modalities with complementary cues for 3D object detection. However, it is quite difficult to sufficiently use them, due to large inter-modal discrepancies. To address this issue, we propose a novel framework, namely Contrastively Augmented Transformer for multi-modal 3D object Detection (CAT-Det). Specifically, CAT-Det adopts a two-stream structure consisting of a Pointformer (PT) branch, an Imageformer (IT) branch along with a Cross-Modal Transformer (CMT) module. PT, IT and CMT jointly encode intra-modal and inter-modal long-range contexts for representing an object, thus fully exploring multi-modal information for detection. Furthermore, we propose an effective One-way Multi-modal Data Augmentation (OMDA) approach via hierarchical contrastive learning at both the point and object levels, significantly improving the accuracy only by augmenting point-clouds, which is free from complex generation of paired samples of the two modalities. Extensive experiments on the KITTI benchmark show that CAT-Det achieves a new state-of-the-art, highlighting its effectiveness.