 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Lexical Feature Analysis of Spoken Language for Predicting Major Depression Symptom Severity
Nov 10, 2025Background: Captured between clinical appointments using mobile devices, spoken language has potential for objective, more regular assessment of symptom severity and earlier detection of relapse in major depressive disorder. However, research to date has largely been in non-clinical cross-sectional samples of written language using complex machine learning (ML) approaches with limited interpretability. Methods: We describe an initial exploratory analysis of longitudinal speech data and PHQ-8 assessments from 5,836 recordings of 586 participants in the UK, Netherlands, and Spain, collected in the RADAR-MDD study. We sought to identify interpretable lexical features associated with MDD symptom severity with linear mixed-effects modelling. Interpretable features and high-dimensional vector embeddings were also used to test the prediction performance of four regressor ML models. Results: In English data, MDD symptom severity was associated with 7 features including lexical diversity measures and absolutist language. In Dutch, associations were observed with words per sentence and positive word frequency; no associations were observed in recordings collected in Spain. The predictive power of lexical features and vector embeddings was near chance level across all languages. Limitations: Smaller samples in non-English speech and methodological choices, such as the elicitation prompt, may have also limited the effect sizes observable. A lack of NLP tools in languages other than English restricted our feature choice. Conclusion: To understand the value of lexical markers in clinical research and practice, further research is needed in larger samples across several languages using improved protocols, and ML models that account for within- and between-individual variations in language.
Meta-Learning Approaches for Speaker-Dependent Voice Fatigue Models
May 29, 2025Speaker-dependent modelling can substantially improve performance in speech-based health monitoring applications. While mixed-effect models are commonly used for such speaker adaptation, they require computationally expensive retraining for each new observation, making them impractical in a production environment. We reformulate this task as a meta-learning problem and explore three approaches of increasing complexity: ensemble-based distance models, prototypical networks, and transformer-based sequence models. Using pre-trained speech embeddings, we evaluate these methods on a large longitudinal dataset of shift workers (N=1,185, 10,286 recordings), predicting time since sleep from speech as a function of fatigue, a symptom commonly associated with ill-health. Our results demonstrate that all meta-learning approaches tested outperformed both cross-sectional and conventional mixed-effects models, with a transformer-based method achieving the strongest performance.
A Tutorial on Clinical Speech AI Development: From Data Collection to Model Validation
Oct 29, 2024There has been a surge of interest in leveraging speech as a marker of health for a wide spectrum of conditions. The underlying premise is that any neurological, mental, or physical deficits that impact speech production can be objectively assessed via automated analysis of speech. Recent advances in speech-based Artificial Intelligence (AI) models for diagnosing and tracking mental health, cognitive, and motor disorders often use supervised learning, similar to mainstream speech technologies like recognition and verification. However, clinical speech AI has distinct challenges, including the need for specific elicitation tasks, small available datasets, diverse speech representations, and uncertain diagnostic labels. As a result, application of the standard supervised learning paradigm may lead to models that perform well in controlled settings but fail to generalize in real-world clinical deployments. With translation into real-world clinical scenarios in mind, this tutorial paper provides an overview of the key components required for robust development of clinical speech AI. Specifically, this paper will cover the design of speech elicitation tasks and protocols most appropriate for different clinical conditions, collection of data and verification of hardware, development and validation of speech representations designed to measure clinical constructs of interest, development of reliable and robust clinical prediction models, and ethical and participant considerations for clinical speech AI. The goal is to provide comprehensive guidance on building models whose inputs and outputs link to the more interpretable and clinically meaningful aspects of speech, that can be interrogated and clinically validated on clinical datasets, and that adhere to ethical, privacy, and security considerations by design.
A pilot protocol and cohort for the investigation of non-pathological variability in speech
Jun 11, 2024



Background Speech-based biomarkers have potential as a means for regular, objective assessment of symptom severity, remotely and in-clinic in combination with advanced analytical models. However, the complex nature of speech and the often subtle changes associated with health mean that findings are highly dependent on methodological and cohort choices. These are often not reported adequately in studies investigating speech-based health assessment Objective To develop and apply an exemplar protocol to generate a pilot dataset of healthy speech with detailed metadata for the assessment of factors in the speech recording-analysis pipeline, including device choice, speech elicitation task and non-pathological variability. Methods We developed our collection protocol and choice of exemplar speech features based on a thematic literature review. Our protocol includes the elicitation of three different speech types. With a focus towards remote applications, we also choose to collect speech with three different microphone types. We developed a pipeline to extract a set of 14 exemplar speech features. Results We collected speech from 28 individuals three times in one day, repeated at the same times 8-11 weeks later, and from 25 healthy individuals three times in one week. Participant characteristics collected included sex, age, native language status and voice use habits of the participant. A preliminary set of 14 speech features covering timing, prosody, voice quality, articulation and spectral moment characteristics were extracted that provide a resource of normative values. Conclusions There are multiple methodological factors involved in the collection, processing and analysis of speech recordings. Consistent reporting and greater harmonisation of study protocols are urgently required to aid the translation of speech processing into clinical research and practice.
Identifying depression-related topics in smartphone-collected free-response speech recordings using an automatic speech recognition system and a deep learning topic model
Sep 05, 2023



Language use has been shown to correlate with depression, but large-scale validation is needed. Traditional methods like clinic studies are expensive. So, natural language processing has been employed on social media to predict depression, but limitations remain-lack of validated labels, biased user samples, and no context. Our study identified 29 topics in 3919 smartphone-collected speech recordings from 265 participants using the Whisper tool and BERTopic model. Six topics with a median PHQ-8 greater than or equal to 10 were regarded as risk topics for depression: No Expectations, Sleep, Mental Therapy, Haircut, Studying, and Coursework. To elucidate the topic emergence and associations with depression, we compared behavioral (from wearables) and linguistic characteristics across identified topics. The correlation between topic shifts and changes in depression severity over time was also investigated, indicating the importance of longitudinally monitoring language use. We also tested the BERTopic model on a similar smaller dataset (356 speech recordings from 57 participants), obtaining some consistent results. In summary, our findings demonstrate specific speech topics may indicate depression severity. The presented data-driven workflow provides a practical approach to collecting and analyzing large-scale speech data from real-world settings for digital health research.
Towards robust paralinguistic assessment for real-world mobile health (mHealth) monitoring: an initial study of reverberation effects on speech
May 21, 2023



Speech is promising as an objective, convenient tool to monitor health remotely over time using mobile devices. Numerous paralinguistic features have been demonstrated to contain salient information related to an individual's health. However, mobile device specification and acoustic environments vary widely, risking the reliability of the extracted features. In an initial step towards quantifying these effects, we report the variability of 13 exemplar paralinguistic features commonly reported in the speech-health literature and extracted from the speech of 42 healthy volunteers recorded consecutively in rooms with low and high reverberation with one budget and two higher-end smartphones and a condenser microphone. Our results show reverberation has a clear effect on several features, in particular voice quality markers. They point to new research directions investigating how best to record and process in-the-wild speech for reliable longitudinal health state assessment.
Utilising Bayesian Networks to combine multimodal data and expert opinion for the robust prediction of depression and its symptoms
Nov 09, 2022



Predicting the presence of major depressive disorder (MDD) using behavioural and cognitive signals is a highly non-trivial task. The heterogeneous clinical profile of MDD means that any given speech, facial expression and/or observed cognitive pattern may be associated with a unique combination of depressive symptoms. Conventional discriminative machine learning models potentially lack the complexity to robustly model this heterogeneity. Bayesian networks, however, may instead be well-suited to such a scenario. These networks are probabilistic graphical models that efficiently describe the joint probability distribution over a set of random variables by explicitly capturing their conditional dependencies. This framework provides further advantages over standard discriminative modelling by offering the possibility to incorporate expert opinion in the graphical structure of the models, generating explainable model predictions, informing about the uncertainty of predictions, and naturally handling missing data. In this study, we apply a Bayesian framework to capture the relationships between depression, depression symptoms, and features derived from speech, facial expression and cognitive game data collected at thymia.
Detecting the Severity of Major Depressive Disorder from Speech: A Novel HARD-Training Methodology
Jun 02, 2022
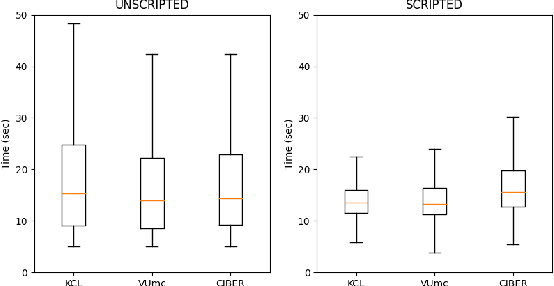
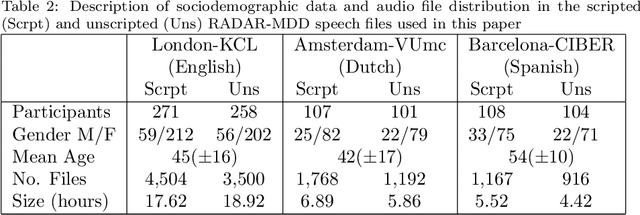
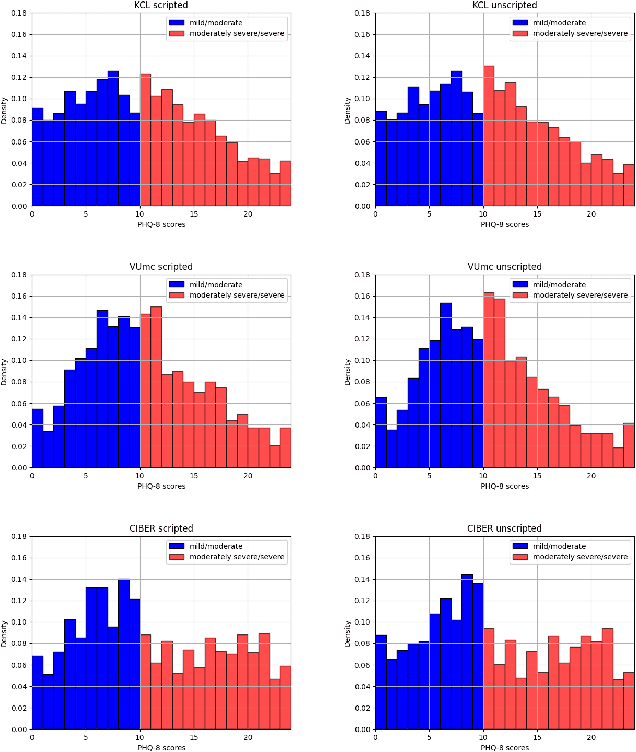
Major Depressive Disorder (MDD) is a common worldwide mental health issue with high associated socioeconomic costs. The prediction and automatic detection of MDD can, therefore, make a huge impact on society. Speech, as a non-invasive, easy to collect signal, is a promising marker to aid the diagnosis and assessment of MDD. In this regard, speech samples were collected as part of the Remote Assessment of Disease and Relapse in Major Depressive Disorder (RADAR-MDD) research programme. RADAR-MDD was an observational cohort study in which speech and other digital biomarkers were collected from a cohort of individuals with a history of MDD in Spain, United Kingdom and the Netherlands. In this paper, the RADAR-MDD speech corpus was taken as an experimental framework to test the efficacy of a Sequence-to-Sequence model with a local attention mechanism in a two-class depression severity classification paradigm. Additionally, a novel training method, HARD-Training, is proposed. It is a methodology based on the selection of more ambiguous samples for the model training, and inspired by the curriculum learning paradigm. HARD-Training was found to consistently improve - with an average increment of 8.6% - the performance of our classifiers for both of two speech elicitation tasks used and each collection site of the RADAR-MDD speech corpus. With this novel methodology, our Sequence-to-Sequence model was able to effectively detect MDD severity regardless of language. Finally, recognising the need for greater awareness of potential algorithmic bias, we conduct an additional analysis of our results separately for each gender.
Automatic Detection of Expressed Emotion from Five-Minute Speech Samples: Challenges and Opportunities
Mar 30, 2022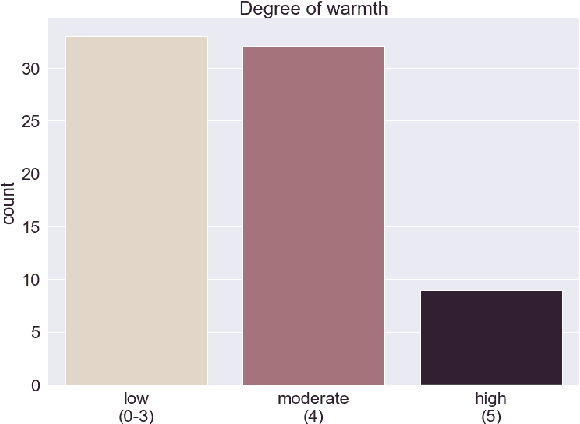
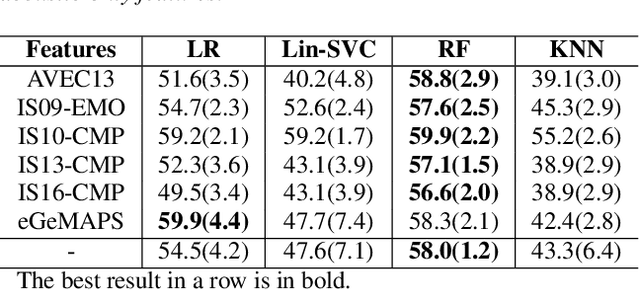
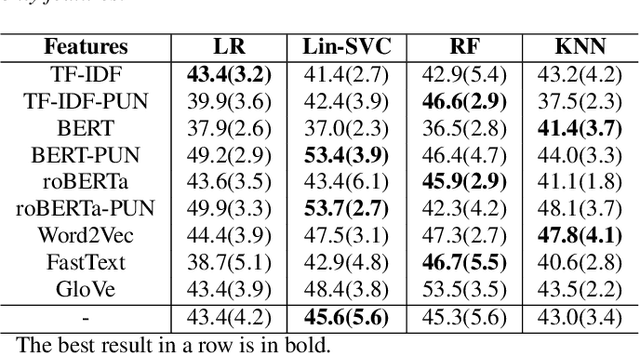
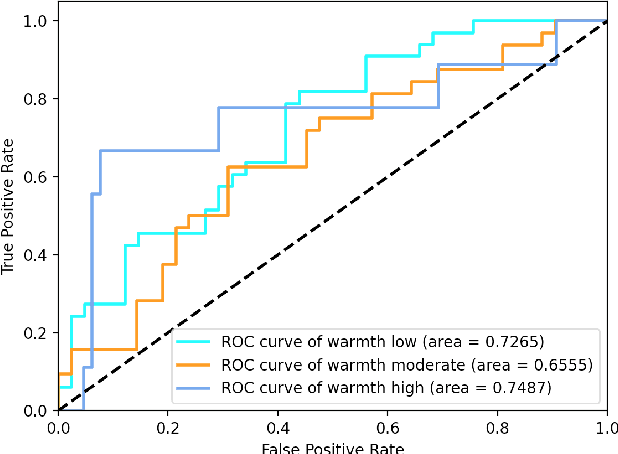
We present a novel feasibility study on the automatic recognition of Expressed Emotion (EE), a family environment concept based on caregivers speaking freely about their relative/family member. We describe an automated approach for determining the \textit{degree of warmth}, a key component of EE, from acoustic and text features acquired from a sample of 37 recorded interviews. These recordings, collected over 20 years ago, are derived from a nationally representative birth cohort of 2,232 British twin children and were manually coded for EE. We outline the core steps of extracting usable information from recordings with highly variable audio quality and assess the efficacy of four machine learning approaches trained with different combinations of acoustic and text features. Despite the challenges of working with this legacy data, we demonstrated that the degree of warmth can be predicted with an $F_{1}$-score of \textbf{61.5\%}. In this paper, we summarise our learning and provide recommendations for future work using real-world speech samples.
Speech and the n-Back task as a lens into depression. How combining both may allow us to isolate different core symptoms of depression
Mar 30, 2022
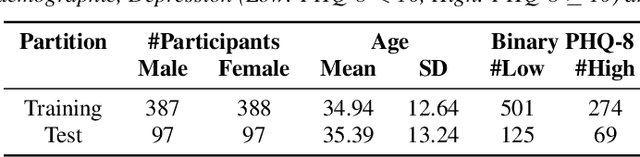
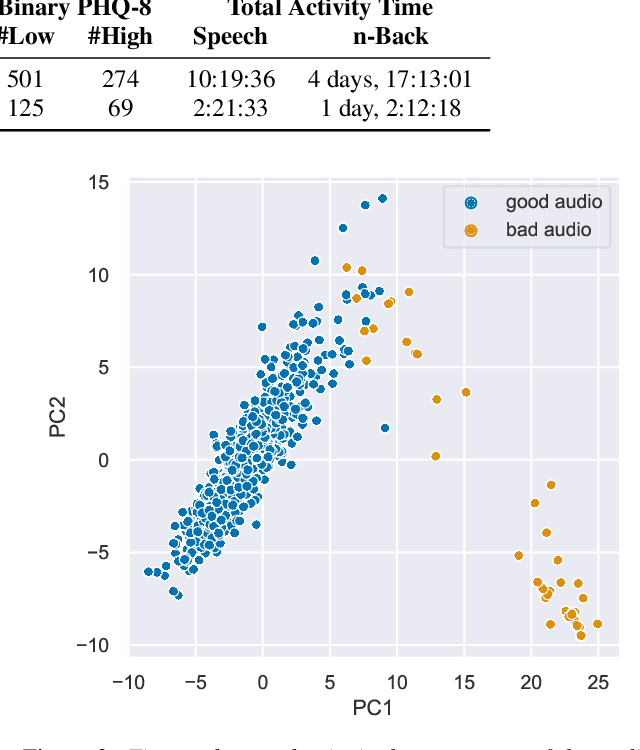
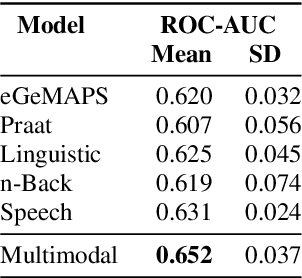
Embedded in any speech signal is a rich combination of cognitive, neuromuscular and physiological information. This richness makes speech a powerful signal in relation to a range of different health conditions, including major depressive disorders (MDD). One pivotal issue in speech-depression research is the assumption that depressive severity is the dominant measurable effect. However, given the heterogeneous clinical profile of MDD, it may actually be the case that speech alterations are more strongly associated with subsets of key depression symptoms. This paper presents strong evidence in support of this argument. First, we present a novel large, cross-sectional, multi-modal dataset collected at Thymia. We then present a set of machine learning experiments that demonstrate that combining speech with features from an n-Back working memory assessment improves classifier performance when predicting the popular eight-item Patient Health Questionnaire depression scale (PHQ-8). Finally, we present a set of experiments that highlight the association between different speech and n-Back markers at the PHQ-8 item level. Specifically, we observe that somatic and psychomotor symptoms are more strongly associated with n-Back performance scores, whilst the other items: anhedonia, depressed mood, change in appetite, feelings of worthlessness and trouble concentrating are more strongly associated with speech changes.