 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUoB at SemEval-2020 Task 12: Boosting BERT with Corpus Level Information
Paper and Code
Aug 19, 2020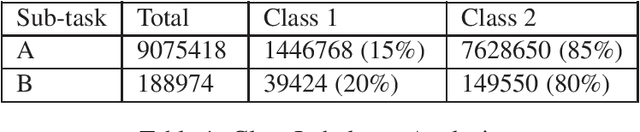
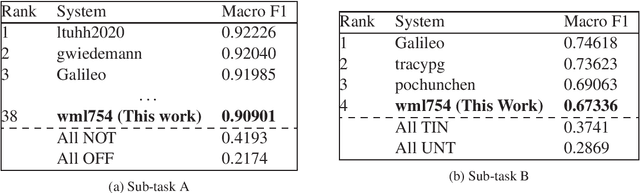
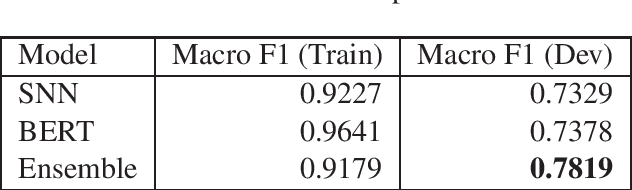
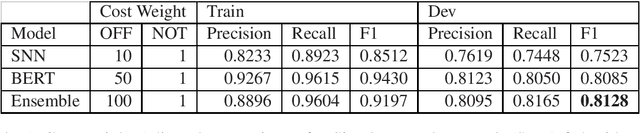
Pre-trained language model word representation, such as BERT, have been extremely successful in several Natural Language Processing tasks significantly improving on the state-of-the-art. This can largely be attributed to their ability to better capture semantic information contained within a sentence. Several tasks, however, can benefit from information available at a corpus level, such as Term Frequency-Inverse Document Frequency (TF-IDF). In this work we test the effectiveness of integrating this information with BERT on the task of identifying abuse on social media and show that integrating this information with BERT does indeed significantly improve performance. We participate in Sub-Task A (abuse detection) wherein we achieve a score within two points of the top performing team and in Sub-Task B (target detection) wherein we are ranked 4 of the 44 participating teams.