 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning Language Models to Know What They Know
Feb 02, 2026Metacognition is a critical component of intelligence, specifically regarding the awareness of one's own knowledge. While humans rely on shared internal memory for both answering questions and reporting their knowledge state, this dependency in LLMs remains underexplored. This study proposes a framework to measure metacognitive ability $d_{\rm{type2}}'$ using a dual-prompt method, followed by the introduction of Evolution Strategy for Metacognitive Alignment (ESMA) to bind a model's internal knowledge to its explicit behaviors. ESMA demonstrates robust generalization across diverse untrained settings, indicating a enhancement in the model's ability to reference its own knowledge. Furthermore, parameter analysis attributes these improvements to a sparse set of significant modifications.
CReSt: A Comprehensive Benchmark for Retrieval-Augmented Generation with Complex Reasoning over Structured Documents
May 23, 2025



Large Language Models (LLMs) have made substantial progress in recent years, yet evaluating their capabilities in practical Retrieval-Augmented Generation (RAG) scenarios remains challenging. In practical applications, LLMs must demonstrate complex reasoning, refuse to answer appropriately, provide precise citations, and effectively understand document layout. These capabilities are crucial for advanced task handling, uncertainty awareness, maintaining reliability, and structural understanding. While some of the prior works address these aspects individually, there is a need for a unified framework that evaluates them collectively in practical RAG scenarios. To address this, we present CReSt (A Comprehensive Benchmark for Retrieval-Augmented Generation with Complex Reasoning over Structured Documents), a benchmark designed to assess these key dimensions holistically. CReSt comprises 2,245 human-annotated examples in English and Korean, designed to capture practical RAG scenarios that require complex reasoning over structured documents. It also introduces a tailored evaluation methodology to comprehensively assess model performance in these critical areas. Our evaluation shows that even advanced LLMs struggle to perform consistently across these dimensions, underscoring key areas for improvement. We release CReSt to support further research and the development of more robust RAG systems. The dataset and code are available at: https://github.com/UpstageAI/CReSt.
Federated Learning Meets Fluid Antenna: Towards Robust and Scalable Edge Intelligence
Mar 04, 2025



Federated learning (FL) is an emerging machine learning paradigm with immense potential to support advanced services and applications in future industries. However, when deployed over wireless communication systems, FL suffers from significant communication overhead, which can be alleviated by integrating over-the-air computation (AirComp). Despite its advantages, AirComp introduces learning inaccuracies due to the inherent randomness of wireless channels, which can degrade overall learning performance. To address this issue, this paper explores the integration of fluid antenna systems (FAS) into AirComp-based FL to enhance system robustness and efficiency. Fluid antennas offer dynamic spatial diversity by adaptively selecting antenna ports, thereby mitigating channel variations and improving signal aggregation. Specifically, we propose an antenna selection rule for fluid-antenna-equipped devices that optimally enhances learning robustness or training performance. Building on this, we develop a learning algorithm and provide a theoretical convergence analysis. The simulation results validate the effectiveness of fluid antennas in improving FL performance, demonstrating their potential as a key enabler for wireless AI applications.
MentalAgora: A Gateway to Advanced Personalized Care in Mental Health through Multi-Agent Debating and Attribute Control
Jul 03, 2024As mental health issues globally escalate, there is a tremendous need for advanced digital support systems. We introduce MentalAgora, a novel framework employing large language models enhanced by interaction between multiple agents for tailored mental health support. This framework operates through three stages: strategic debating, tailored counselor creation, and response generation, enabling the dynamic customization of responses based on individual user preferences and therapeutic needs. We conduct experiments utilizing a high-quality evaluation dataset TherapyTalk crafted with mental health professionals, shwoing that MentalAgora generates expert-aligned and user preference-enhanced responses. Our evaluations, including experiments and user studies, demonstrate that MentalAgora aligns with professional standards and effectively meets user preferences, setting a new benchmark for digital mental health interventions.
Memoria: Hebbian Memory Architecture for Human-Like Sequential Processing
Oct 04, 2023



Transformers have demonstrated their success in various domains and tasks. However, Transformers struggle with long input sequences due to their limited capacity. While one solution is to increase input length, endlessly stretching the length is unrealistic. Furthermore, humans selectively remember and use only relevant information from inputs, unlike Transformers which process all raw data from start to end. We introduce Memoria, a general memory network that applies Hebbian theory which is a major theory explaining human memory formulation to enhance long-term dependencies in neural networks. Memoria stores and retrieves information called engram at multiple memory levels of working memory, short-term memory, and long-term memory, using connection weights that change according to Hebb's rule. Through experiments with popular Transformer-based models like BERT and GPT, we present that Memoria significantly improves the ability to consider long-term dependencies in various tasks. Results show that Memoria outperformed existing methodologies in sorting and language modeling, and long text classification.
Into-TTS : Intonation Template based Prosody Control System
Apr 04, 2022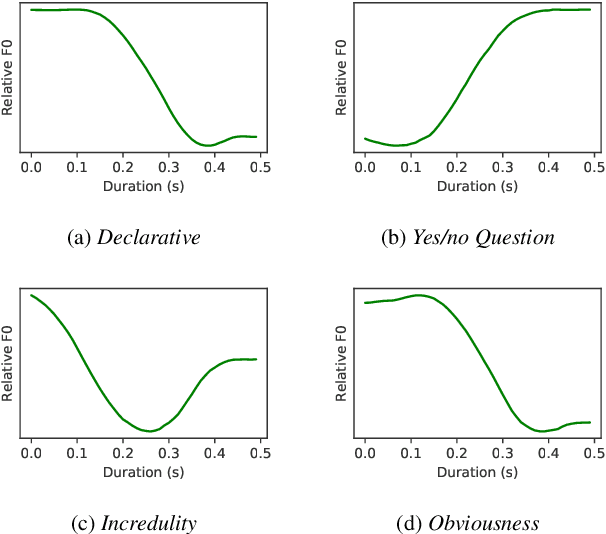

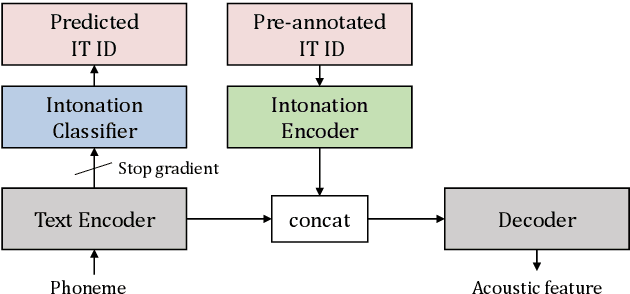
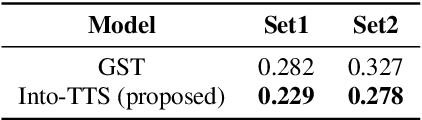
Intonations take an important role in delivering the intention of the speaker. However, current end-to-end TTS systems often fail to model proper intonations. To alleviate this problem, we propose a novel, intuitive method to synthesize speech in different intonations using predefined intonation templates. Prior to the acoustic model training, speech data are automatically grouped into intonation templates by k-means clustering, according to their sentence-final F0 contour. Two proposed modules are added to the end-to-end TTS framework: intonation classifier and intonation encoder. The intonation classifier recommends a suitable intonation template to the given text. The intonation encoder, attached to the text encoder output, synthesizes speech abiding the requested intonation template. Main contributions of our paper are: (a) an easy-to-use intonation control system covering a wide range of users; (b) better performance in wrapping speech in a requested intonation with improved pitch distance and MOS; and (c) feasibility to future integration between TTS and NLP, TTS being able to utilize contextual information. Audio samples are available at https://srtts.github.io/IntoTTS.
Bunched LPCNet2: Efficient Neural Vocoders Covering Devices from Cloud to Edge
Mar 27, 2022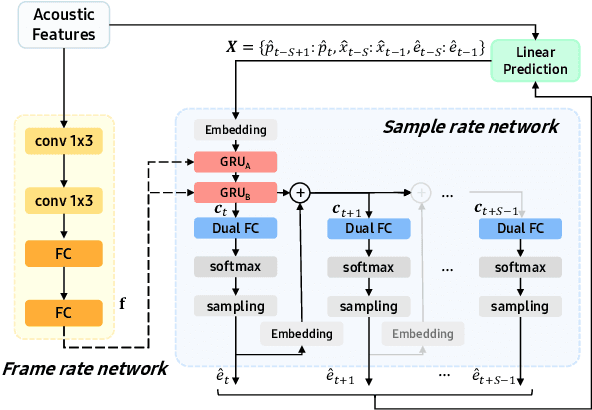

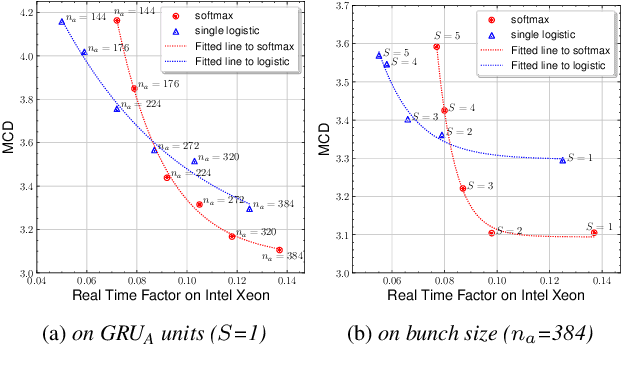
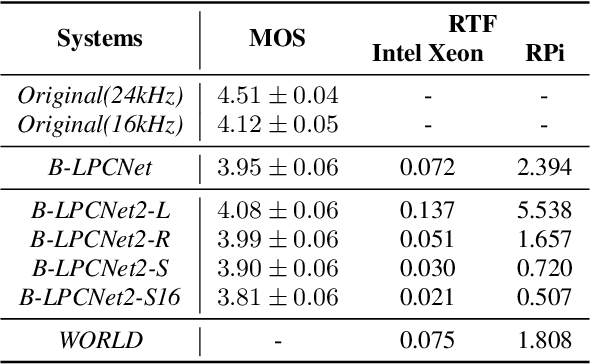
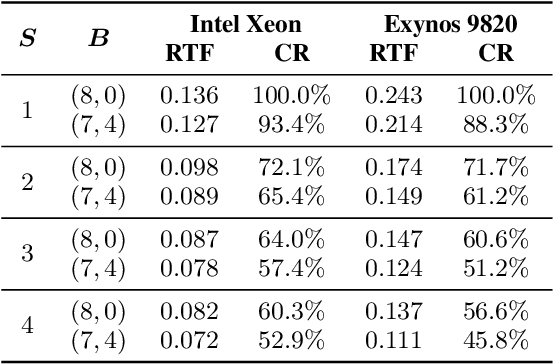
Text-to-Speech (TTS) services that run on edge devices have many advantages compared to cloud TTS, e.g., latency and privacy issues. However, neural vocoders with a low complexity and small model footprint inevitably generate annoying sounds. This study proposes a Bunched LPCNet2, an improved LPCNet architecture that provides highly efficient performance in high-quality for cloud servers and in a low-complexity for low-resource edge devices. Single logistic distribution achieves computational efficiency, and insightful tricks reduce the model footprint while maintaining speech quality. A DualRate architecture, which generates a lower sampling rate from a prosody model, is also proposed to reduce maintenance costs. The experiments demonstrate that Bunched LPCNet2 generates satisfactory speech quality with a model footprint of 1.1MB while operating faster than real-time on a RPi 3B. Our audio samples are available at https://srtts.github.io/bunchedLPCNet2.
Bunched LPCNet : Vocoder for Low-cost Neural Text-To-Speech Systems
Aug 11, 2020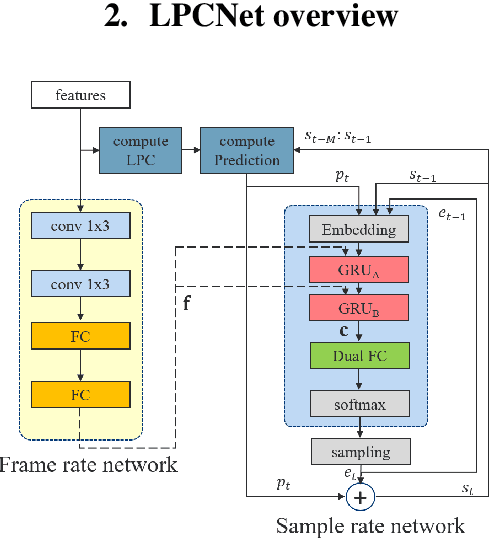
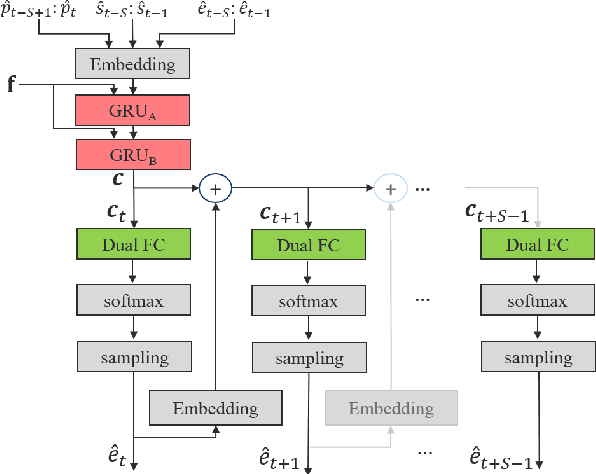
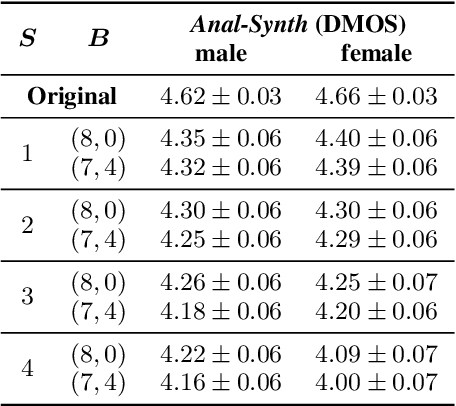
LPCNet is an efficient vocoder that combines linear prediction and deep neural network modules to keep the computational complexity low. In this work, we present two techniques to further reduce it's complexity, aiming for a low-cost LPCNet vocoder-based neural Text-to-Speech (TTS) System. These techniques are: 1) Sample-bunching, which allows LPCNet to generate more than one audio sample per inference; and 2) Bit-bunching, which reduces the computations in the final layer of LPCNet. With the proposed bunching techniques, LPCNet, in conjunction with a Deep Convolutional TTS (DCTTS) acoustic model, shows a 2.19x improvement over the baseline run-time when running on a mobile device, with a less than 0.1 decrease in TTS mean opinion score (MOS).