 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
One-step Method for Material Quantitation using In-line Tomography with Single Scanning
Apr 17, 2022
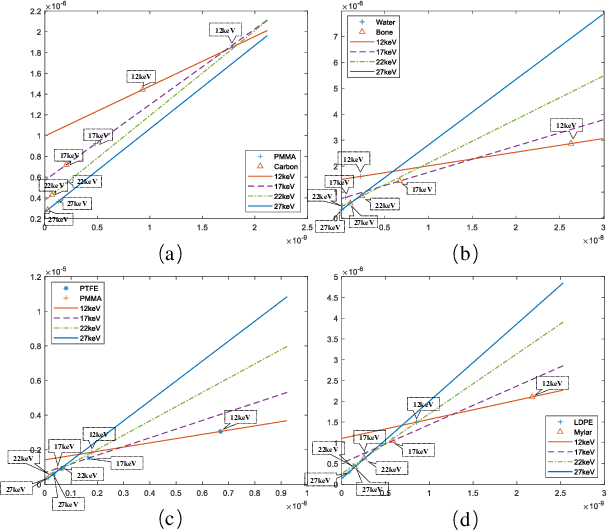

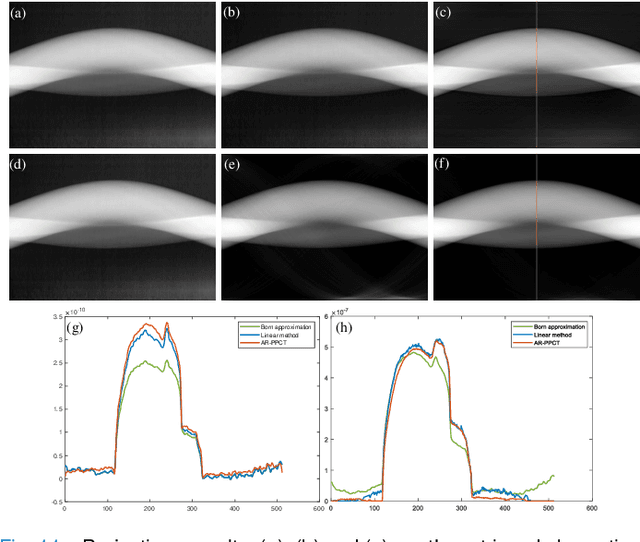
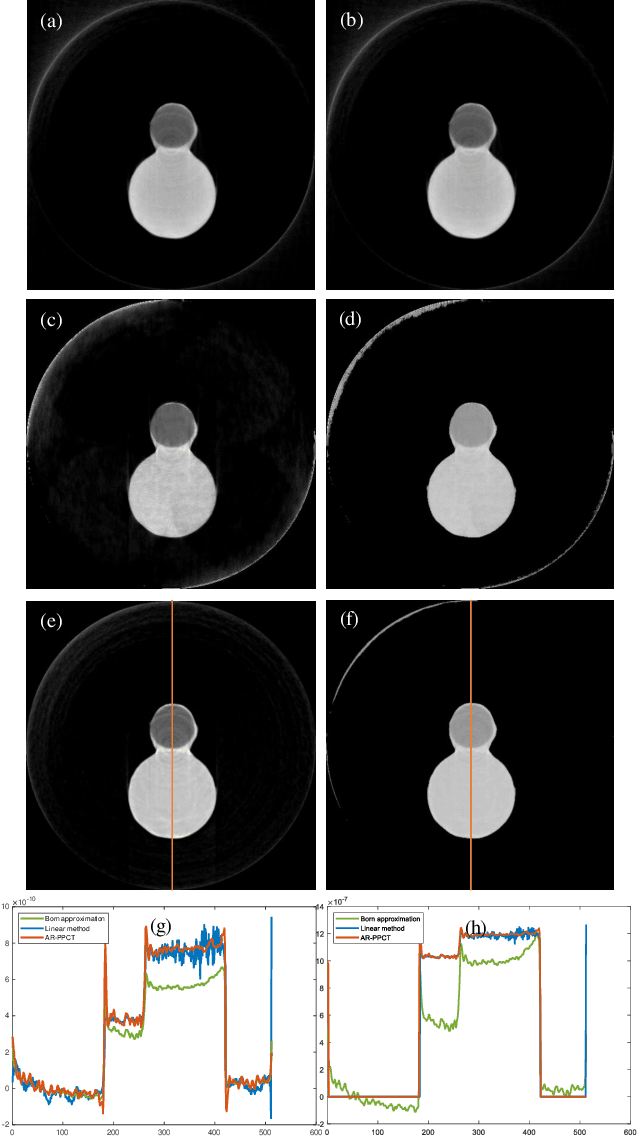
Objective: Quantitative technique based on In-line phase-contrast computed tomography with single scanning attracts more attention in application due to the flexibility of the implementation. However, the quantitative results usually suffer from artifacts and noise, since the phase retrieval and reconstruction are independent ("two-steps") without feedback from the original data. Our goal is to develop a method for material quantitative imaging based on a priori information specifically for the single-scanning data. Method: An iterative method that directly reconstructs the refractive index decrement delta and imaginary beta of the object from observed data ("one-step") within single object-to-detector distance (ODD) scanning. Simultaneously, high-quality quantitative reconstruction results are obtained by using a linear approximation that achieves material decomposition in the iterative process. Results: By comparing the equivalent atomic number of the material decomposition results in experiments, the accuracy of the proposed method is greater than 97.2%. Conclusion: The quantitative reconstruction and decomposition results are effectively improved, and there are feedback and corrections during the iteration, which effectively reduce the impact of noise and errors. Significance: This algorithm has the potential for quantitative imaging research, especially for imaging live samples and human breast preclinical studies.
A World-Self Model Towards Understanding Intelligence
Apr 13, 2022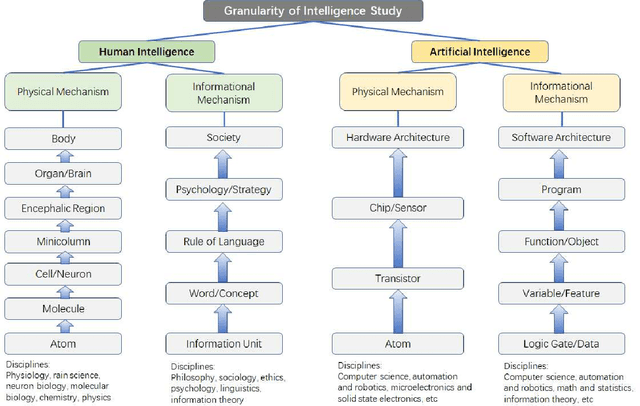
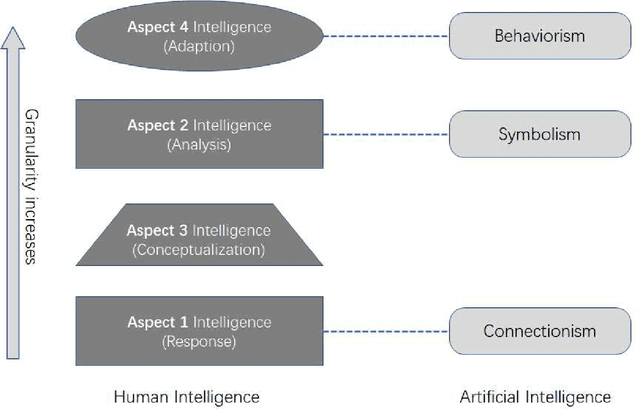
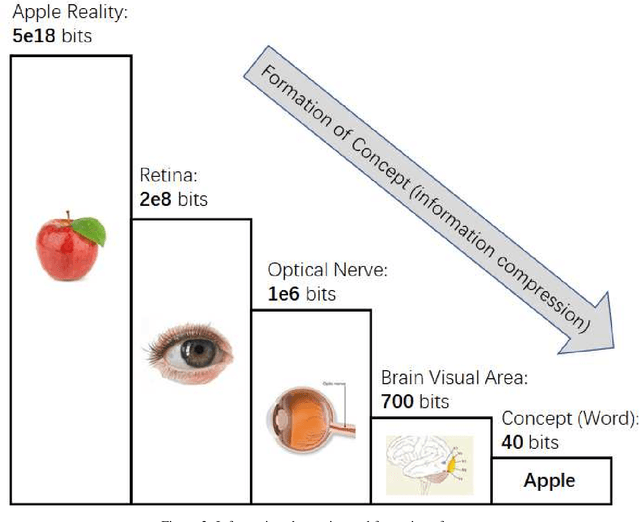
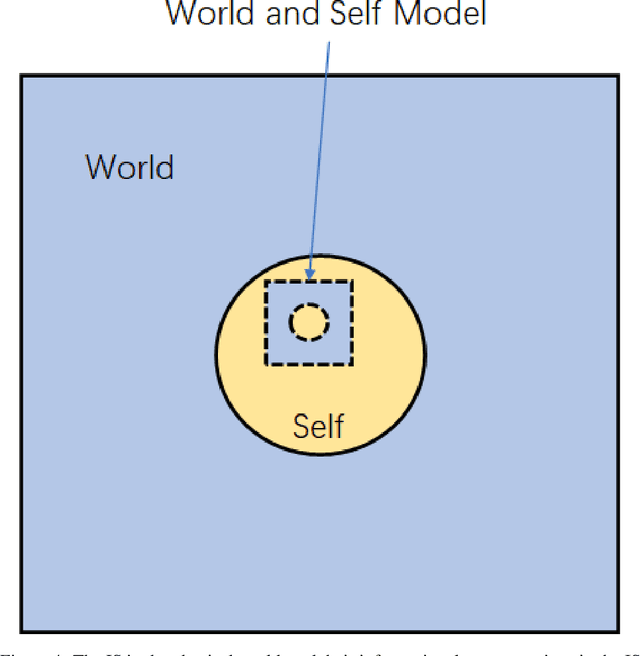
Artificial intelligence has achieved tremendous successes in various tasks, while it is still out of question that there are big gaps between artificial and human intelligence, and the nature of intelligence is still in darkness. In this work we will first stress the importance of defining the scope of discussion and choosing the right physical and informational granularity of investigation. We will carefully compare human and artificial intelligence, and propose that the information abstraction mechanism of human intelligence is the key to connect perception and cognition, and the lack of a new model is preventing the understanding and next-level implementation of intelligence. We will present the broader idea of "concept", the principles and mathematical frameworks of the new model World-Self Model (WSM) of intelligence, and finally an unified general framework of intelligence based on WSM. Rather than focusing on solving a specific problem or discussing a certain kind of intelligence, our work is instead towards a better understanding of the nature of the general phenomenon of intelligence, independent of the task or system of investigation.
Transformer Memory as a Differentiable Search Index
Feb 16, 2022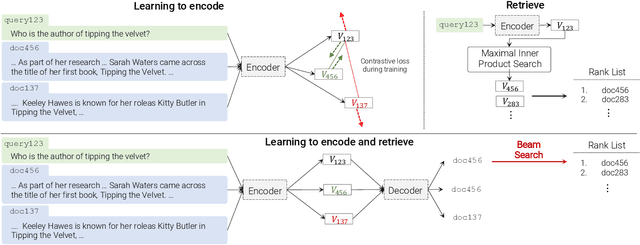
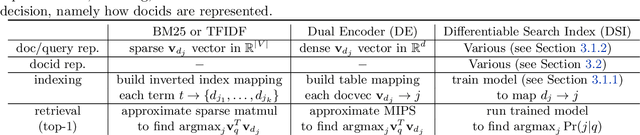
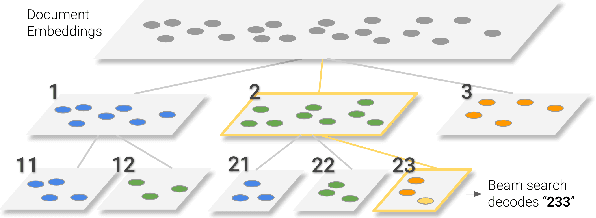
In this paper, we demonstrate that information retrieval can be accomplished with a single Transformer, in which all information about the corpus is encoded in the parameters of the model. To this end, we introduce the Differentiable Search Index (DSI), a new paradigm that learns a text-to-text model that maps string queries directly to relevant docids; in other words, a DSI model answers queries directly using only its parameters, dramatically simplifying the whole retrieval process. We study variations in how documents and their identifiers are represented, variations in training procedures, and the interplay between models and corpus sizes. Experiments demonstrate that given appropriate design choices, DSI significantly outperforms strong baselines such as dual encoder models. Moreover, DSI demonstrates strong generalization capabilities, outperforming a BM25 baseline in a zero-shot setup.
Explaining black-box text classifiers for disease-treatment information extraction
Oct 21, 2020
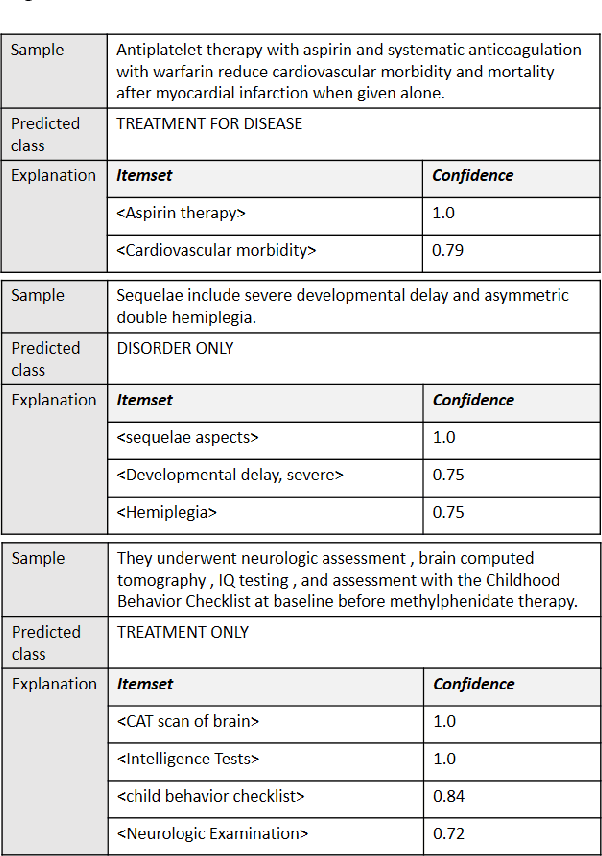
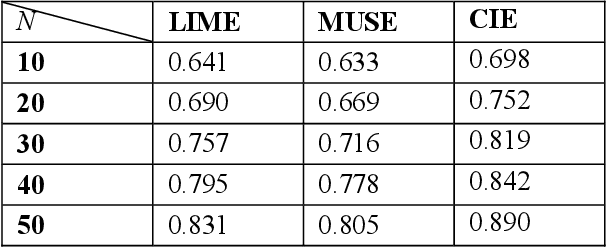
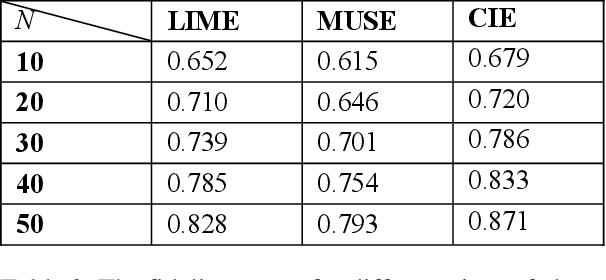
Deep neural networks and other intricate Artificial Intelligence (AI) models have reached high levels of accuracy on many biomedical natural language processing tasks. However, their applicability in real-world use cases may be limited due to their vague inner working and decision logic. A post-hoc explanation method can approximate the behavior of a black-box AI model by extracting relationships between feature values and outcomes. In this paper, we introduce a post-hoc explanation method that utilizes confident itemsets to approximate the behavior of black-box classifiers for medical information extraction. Incorporating medical concepts and semantics into the explanation process, our explanator finds semantic relations between inputs and outputs in different parts of the decision space of a black-box classifier. The experimental results show that our explanation method can outperform perturbation and decision set based explanators in terms of fidelity and interpretability of explanations produced for predictions on a disease-treatment information extraction task.
Fast Semantic-Assisted Outlier Removal for Large-scale Point Cloud Registration
Feb 21, 2022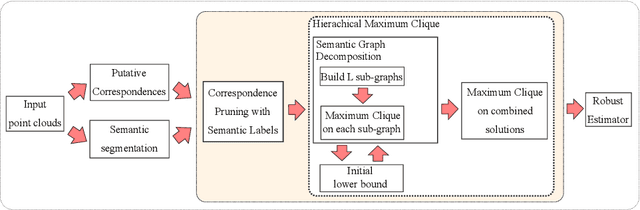
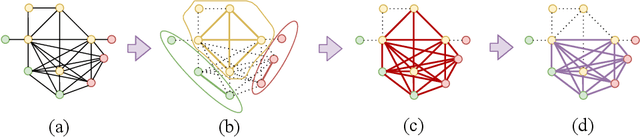

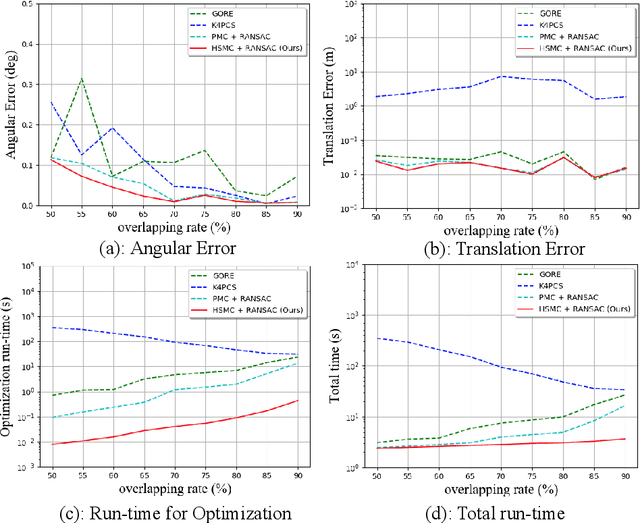
With current trends in sensors (cheaper, more volume of data) and applications (increasing affordability for new tasks, new ideas in what 3D data could be useful for); there is corresponding increasing interest in the ability to automatically, reliably, and cheaply, register together individual point clouds. The volume of data to handle, and still elusive need to have the registration occur fully reliably and fully automatically, mean there is a need to innovate further. One largely untapped area of innovation is that of exploiting the {\em semantic information} of the points in question. Points on a tree should match points on a tree, for example, and not points on car. Moreover, such a natural restriction is clearly human-like - a human would generally quickly eliminate candidate regions for matching based on semantics. Employing semantic information is not only efficient but natural. It is also timely - due to the recent advances in semantic classification capabilities. This paper advances this theme by demonstrating that state of the art registration techniques, in particular ones that rely on "preservation of length under rigid motion" as an underlying matching consistency constraint, can be augmented with semantic information. Semantic identity is of course also preserved under rigid-motion, but also under wider motions present in a scene. We demonstrate that not only the potential obstacle of cost of semantic segmentation, and the potential obstacle of the unreliability of semantic segmentation; are both no impediment to achieving both speed and accuracy in fully automatic registration of large scale point clouds.
Perception Visualization: Seeing Through the Eyes of a DNN
Apr 21, 2022
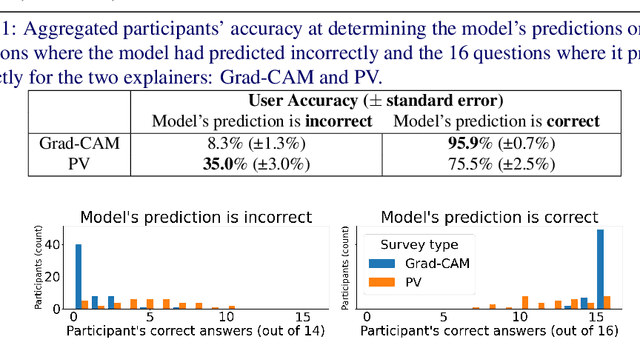

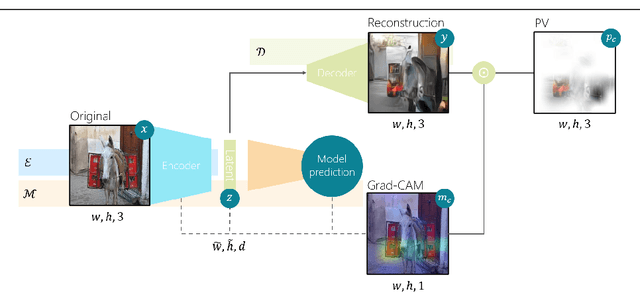
Artificial intelligence (AI) systems power the world we live in. Deep neural networks (DNNs) are able to solve tasks in an ever-expanding landscape of scenarios, but our eagerness to apply these powerful models leads us to focus on their performance and deprioritises our ability to understand them. Current research in the field of explainable AI tries to bridge this gap by developing various perturbation or gradient-based explanation techniques. For images, these techniques fail to fully capture and convey the semantic information needed to elucidate why the model makes the predictions it does. In this work, we develop a new form of explanation that is radically different in nature from current explanation methods, such as Grad-CAM. Perception visualization provides a visual representation of what the DNN perceives in the input image by depicting what visual patterns the latent representation corresponds to. Visualizations are obtained through a reconstruction model that inverts the encoded features, such that the parameters and predictions of the original models are not modified. Results of our user study demonstrate that humans can better understand and predict the system's decisions when perception visualizations are available, thus easing the debugging and deployment of deep models as trusted systems.
Thinking about GPT-3 In-Context Learning for Biomedical IE? Think Again
Mar 16, 2022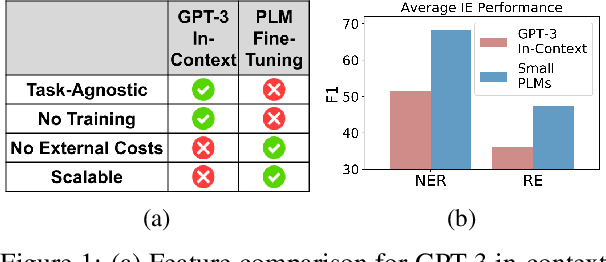
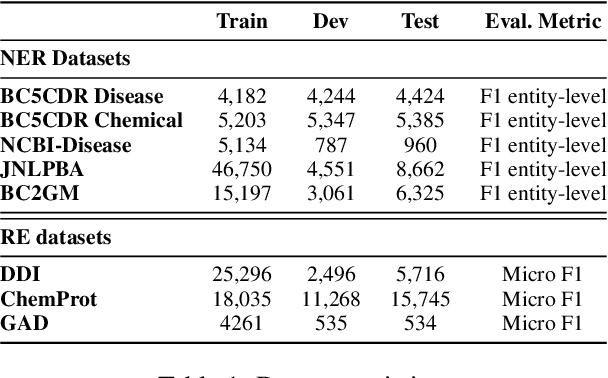

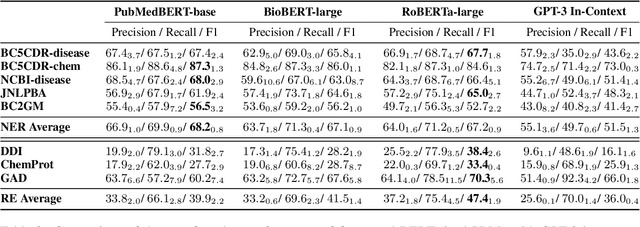
The strong few-shot in-context learning capability of large pre-trained language models (PLMs) such as GPT-3 is highly appealing for biomedical applications where data annotation is particularly costly. In this paper, we present the first systematic and comprehensive study to compare the few-shot performance of GPT-3 in-context learning with fine-tuning smaller (i.e., BERT-sized) PLMs on two highly representative biomedical information extraction tasks, named entity recognition and relation extraction. We follow the true few-shot setting to avoid overestimating models' few-shot performance by model selection over a large validation set. We also optimize GPT-3's performance with known techniques such as contextual calibration and dynamic in-context example retrieval. However, our results show that GPT-3 still significantly underperforms compared with simply fine-tuning a smaller PLM using the same small training set. Moreover, what is equally important for practical applications is that adding more labeled data would reliably yield an improvement in model performance. While that is the case when fine-tuning small PLMs, GPT-3's performance barely improves when adding more data. In-depth analyses further reveal issues of the in-context learning setting that may be detrimental to information extraction tasks in general. Given the high cost of experimenting with GPT-3, we hope our study provides guidance for biomedical researchers and practitioners towards more promising directions such as fine-tuning GPT-3 or small PLMs.
Situational Perception Guided Image Matting
Apr 21, 2022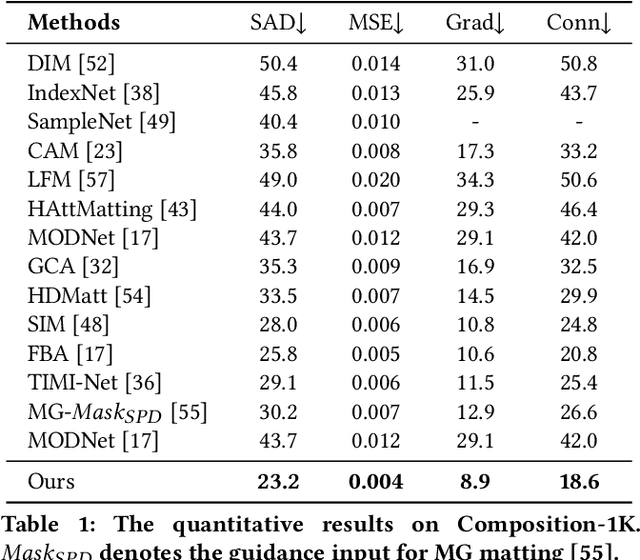
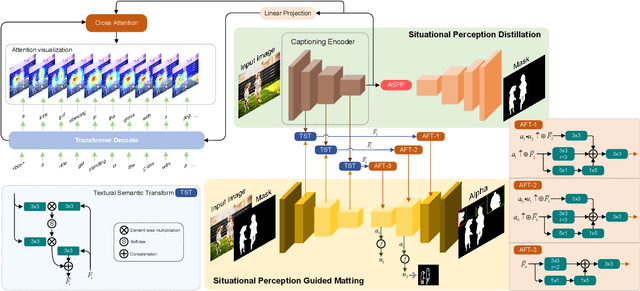
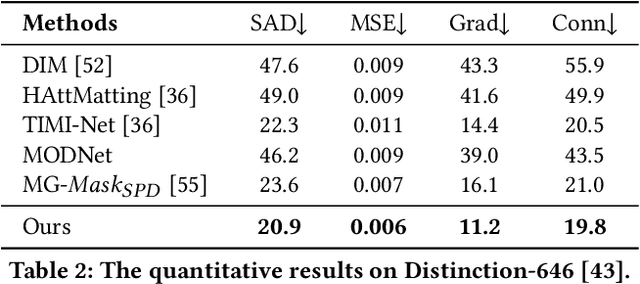
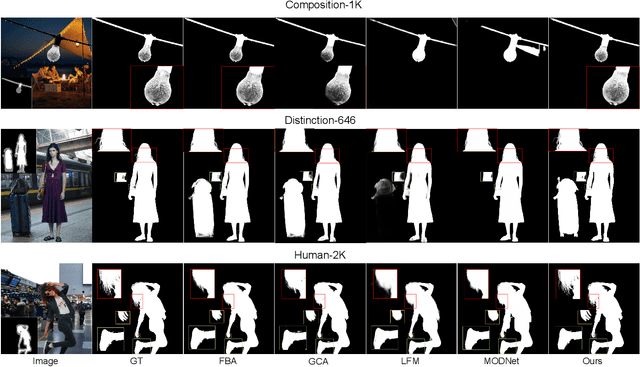
Most automatic matting methods try to separate the salient foreground from the background. However, the insufficient quantity and subjective bias of the current existing matting datasets make it difficult to fully explore the semantic association between object-to-object and object-to-environment in a given image. In this paper, we propose a Situational Perception Guided Image Matting (SPG-IM) method that mitigates subjective bias of matting annotations and captures sufficient situational perception information for better global saliency distilled from the visual-to-textual task. SPG-IM can better associate inter-objects and object-to-environment saliency, and compensate the subjective nature of image matting and its expensive annotation. We also introduce a textual Semantic Transformation (TST) module that can effectively transform and integrate the semantic feature stream to guide the visual representations. In addition, an Adaptive Focal Transformation (AFT) Refinement Network is proposed to adaptively switch multi-scale receptive fields and focal points to enhance both global and local details. Extensive experiments demonstrate the effectiveness of situational perception guidance from the visual-to-textual tasks on image matting, and our model outperforms the state-of-the-art methods. We also analyze the significance of different components in our model. The code will be released soon.
A Multi-Characteristic Learning Method with Micro-Doppler Signatures for Pedestrian Identification
Mar 23, 2022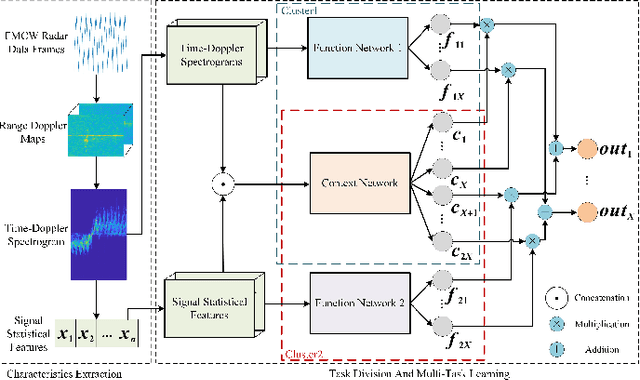
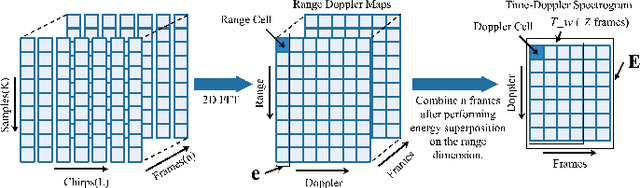
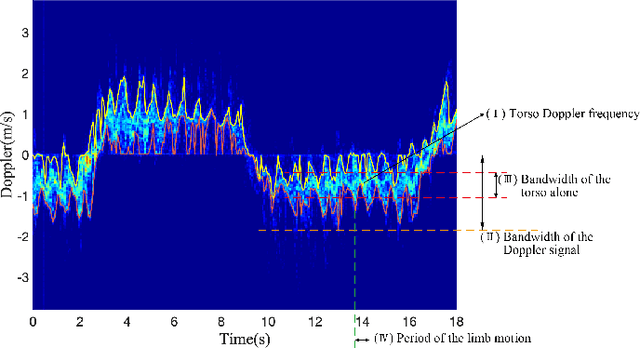
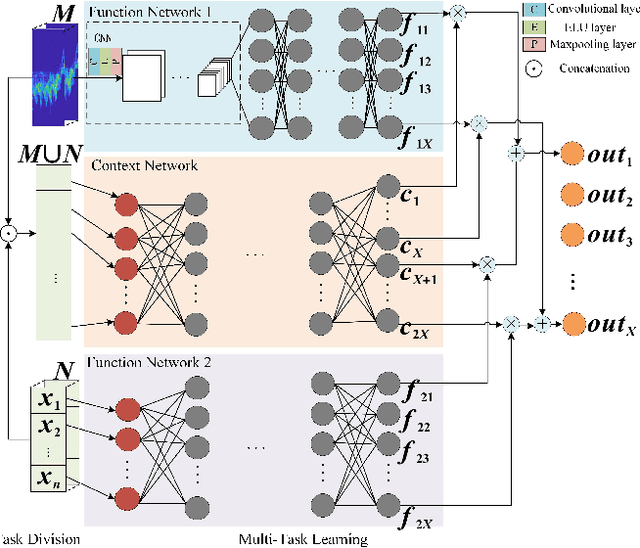
The identification of pedestrians using radar micro-Doppler signatures has become a hot topic in recent years. In this paper, we propose a multi-characteristic learning (MCL) model with clusters to jointly learn discrepant pedestrian micro-Doppler signatures and fuse the knowledge learned from each cluster into final decisions. Time-Doppler spectrogram (TDS) and signal statistical features extracted from FMCW radar, as two categories of micro-Doppler signatures, are used in MCL to learn the micro-motion information inside pedestrians' free walking patterns. The experimental results show that our model achieves a higher accuracy rate and is more stable for pedestrian identification than other studies, which make our model more practical.
Entropy-based Active Learning for Object Detection with Progressive Diversity Constraint
Apr 17, 2022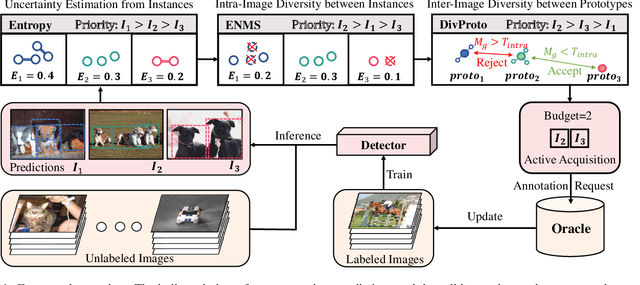
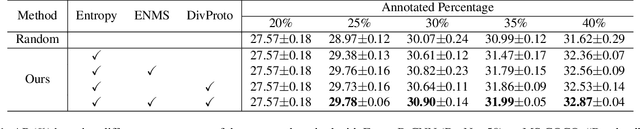
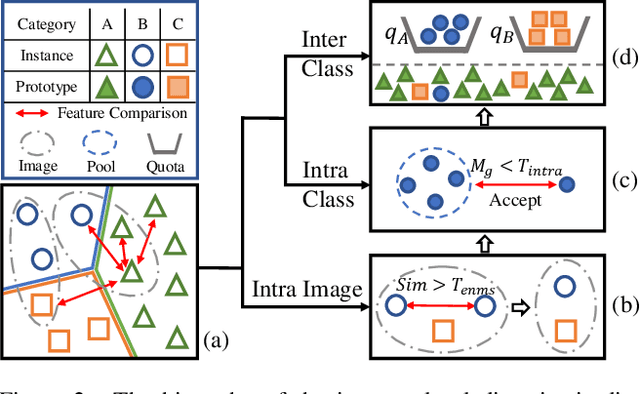
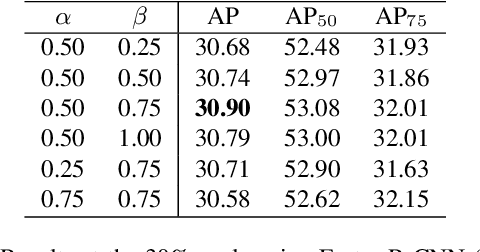
Active learning is a promising alternative to alleviate the issue of high annotation cost in the computer vision tasks by consciously selecting more informative samples to label. Active learning for object detection is more challenging and existing efforts on it are relatively rare. In this paper, we propose a novel hybrid approach to address this problem, where the instance-level uncertainty and diversity are jointly considered in a bottom-up manner. To balance the computational complexity, the proposed approach is designed as a two-stage procedure. At the first stage, an Entropy-based Non-Maximum Suppression (ENMS) is presented to estimate the uncertainty of every image, which performs NMS according to the entropy in the feature space to remove predictions with redundant information gains. At the second stage, a diverse prototype (DivProto) strategy is explored to ensure the diversity across images by progressively converting it into the intra-class and inter-class diversities of the entropy-based class-specific prototypes. Extensive experiments are conducted on MS COCO and Pascal VOC, and the proposed approach achieves state of the art results and significantly outperforms the other counterparts, highlighting its superiority.