 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MonoTrack: Shuttle trajectory reconstruction from monocular badminton video
Apr 04, 2022
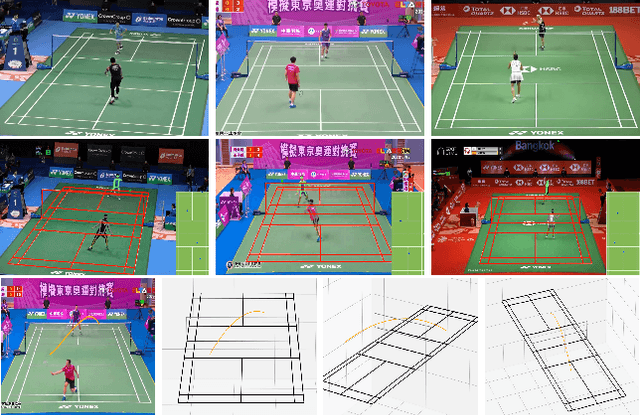
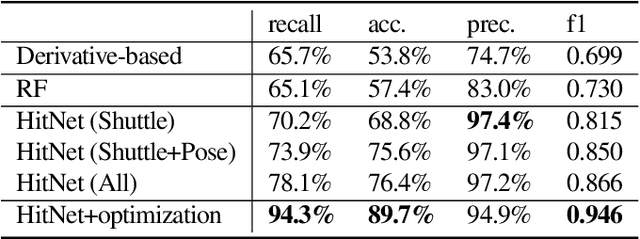
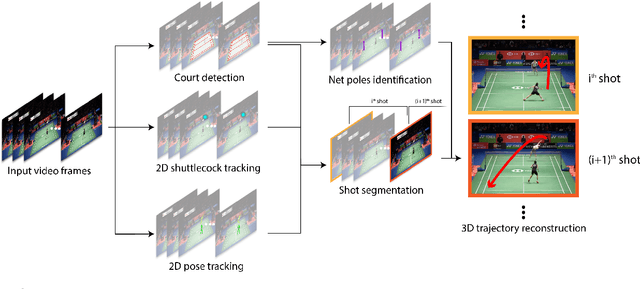

Trajectory estimation is a fundamental component of racket sport analytics, as the trajectory contains information not only about the winning and losing of each point, but also how it was won or lost. In sports such as badminton, players benefit from knowing the full 3D trajectory, as the height of shuttlecock or ball provides valuable tactical information. Unfortunately, 3D reconstruction is a notoriously hard problem, and standard trajectory estimators can only track 2D pixel coordinates. In this work, we present the first complete end-to-end system for the extraction and segmentation of 3D shuttle trajectories from monocular badminton videos. Our system integrates badminton domain knowledge such as court dimension, shot placement, physical laws of motion, along with vision-based features such as player poses and shuttle tracking. We find that significant engineering efforts and model improvements are needed to make the overall system robust, and as a by-product of our work, improve state-of-the-art results on court recognition, 2D trajectory estimation, and hit recognition.
Do Encoder Representations of Generative Dialogue Models Encode Sufficient Information about the Task ?
Jun 20, 2021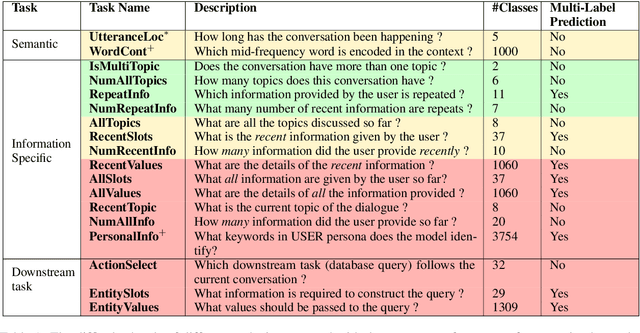
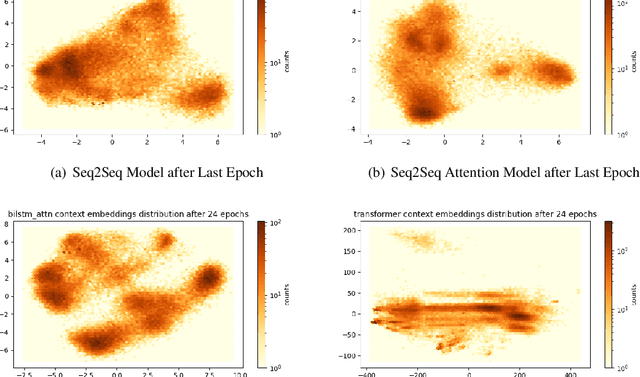
Predicting the next utterance in dialogue is contingent on encoding of users' input text to generate appropriate and relevant response in data-driven approaches. Although the semantic and syntactic quality of the language generated is evaluated, more often than not, the encoded representation of input is not evaluated. As the representation of the encoder is essential for predicting the appropriate response, evaluation of encoder representation is a challenging yet important problem. In this work, we showcase evaluating the text generated through human or automatic metrics is not sufficient to appropriately evaluate soundness of the language understanding of dialogue models and, to that end, propose a set of probe tasks to evaluate encoder representation of different language encoders commonly used in dialogue models. From experiments, we observe that some of the probe tasks are easier and some are harder for even sophisticated model architectures to learn. And, through experiments we observe that RNN based architectures have lower performance on automatic metrics on text generation than transformer model but perform better than the transformer model on the probe tasks indicating that RNNs might preserve task information better than the Transformers.
End-to-End Zero-Shot Voice Style Transfer with Location-Variable Convolutions
May 19, 2022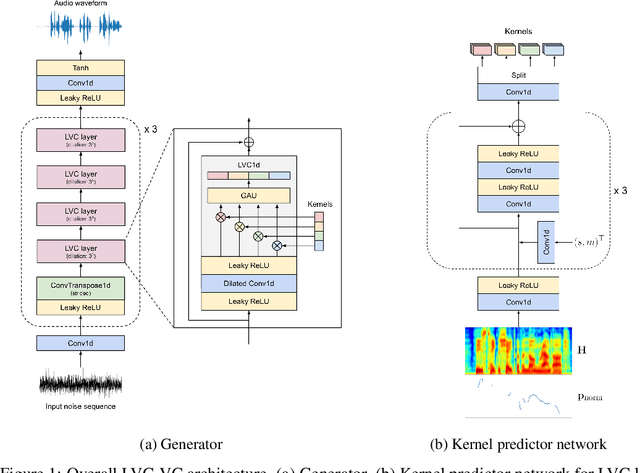
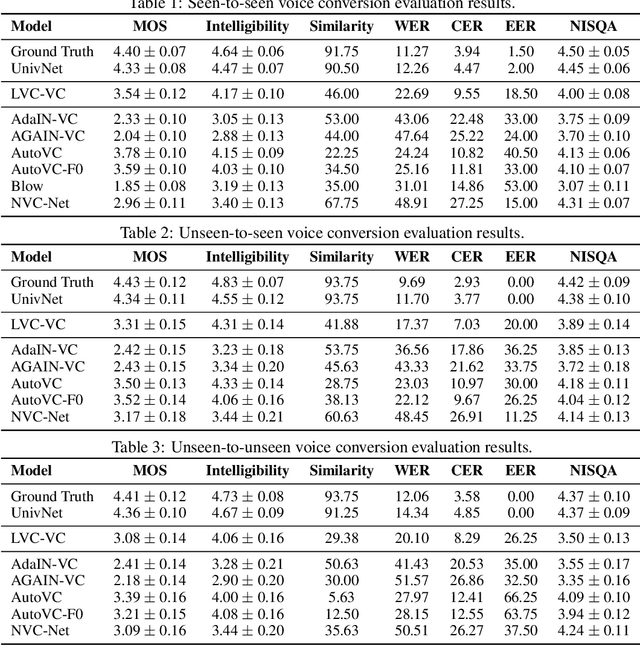

Zero-shot voice conversion is becoming an increasingly popular research direction, as it promises the ability to transform speech to match the voice style of any speaker. However, little work has been done on end-to-end methods for this task, which are appealing because they remove the need for a separate vocoder to generate audio from intermediate features. In this work, we propose Location-Variable Convolution-based Voice Conversion (LVC-VC), a model for performing end-to-end zero-shot voice conversion that is based on a neural vocoder. LVC-VC utilizes carefully designed input features that have disentangled content and speaker style information, and the vocoder-like architecture learns to combine them to simultaneously perform voice conversion while synthesizing audio. To the best of our knowledge, LVC-VC is one of the first models to be proposed that can perform zero-shot voice conversion in an end-to-end manner, and it is the first to do so using a vocoder-like neural framework. Experiments show that our model achieves competitive or better voice style transfer performance compared to several baselines while maintaining the intelligibility of transformed speech much better.
Semi-Supervised Super-Resolution
Apr 19, 2022
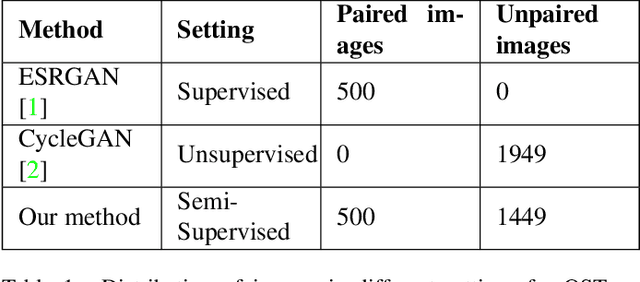
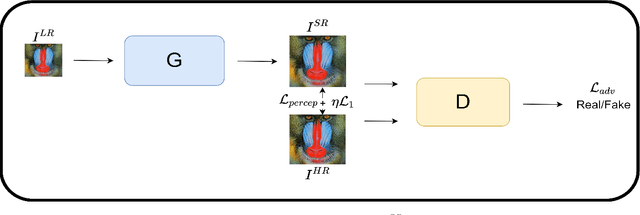
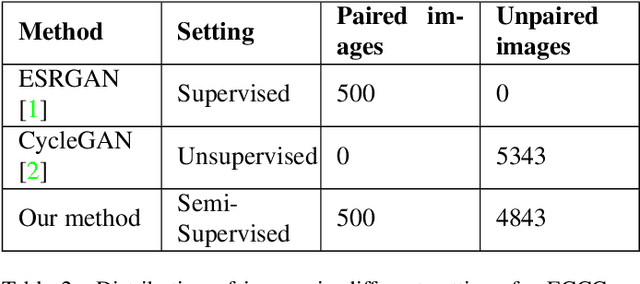
Super-Resolution is the technique to improve the quality of a low-resolution photo by boosting its plausible resolution. The computer vision community has extensively explored the area of Super-Resolution. However, previous Super-Resolution methods require vast amounts of data for training which becomes problematic in domains where very few low-resolution, high-resolution pairs might be available. One such area is statistical downscaling, where super-resolution is increasingly being used to obtain high-resolution climate information from low-resolution data. Acquiring high-resolution climate data is extremely expensive and challenging. To reduce the cost of generating high-resolution climate information, Super-Resolution algorithms should be able to train with a limited number of low-resolution, high-resolution pairs. This paper tries to solve the aforementioned problem by introducing a semi-supervised way to perform super-resolution that can generate sharp, high-resolution images with as few as 500 paired examples. The proposed semi-supervised technique can be used as a plug-and-play module with any supervised GAN-based Super-Resolution method to enhance its performance. We quantitatively and qualitatively analyze the performance of the proposed model and compare it with completely supervised methods as well as other unsupervised techniques. Comprehensive evaluations show the superiority of our method over other methods on different metrics. We also offer the applicability of our approach in statistical downscaling to obtain high-resolution climate images.
MSTRIQ: No Reference Image Quality Assessment Based on Swin Transformer with Multi-Stage Fusion
May 23, 2022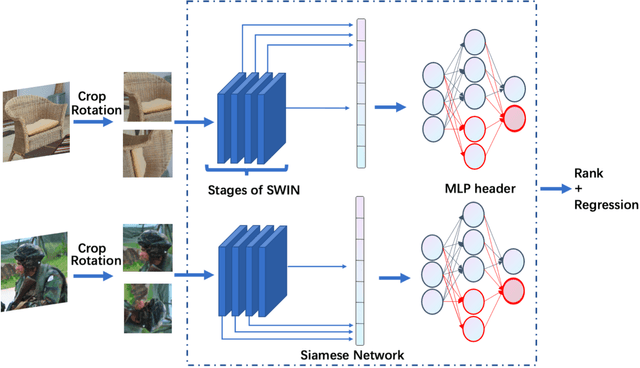
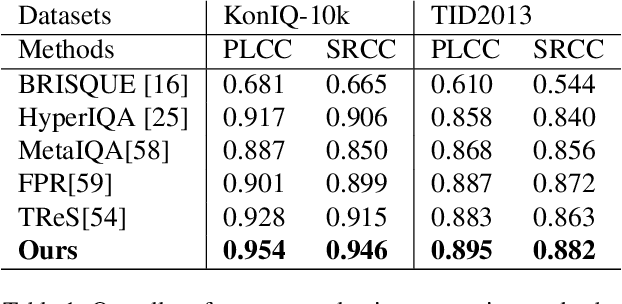
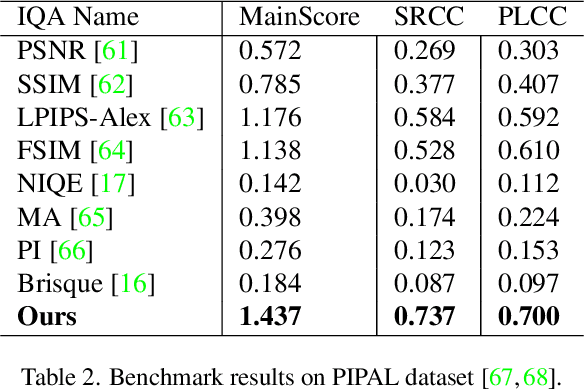
Measuring the perceptual quality of images automatically is an essential task in the area of computer vision, as degradations on image quality can exist in many processes from image acquisition, transmission to enhancing. Many Image Quality Assessment(IQA) algorithms have been designed to tackle this problem. However, it still remains un settled due to the various types of image distortions and the lack of large-scale human-rated datasets. In this paper, we propose a novel algorithm based on the Swin Transformer [31] with fused features from multiple stages, which aggregates information from both local and global features to better predict the quality. To address the issues of small-scale datasets, relative rankings of images have been taken into account together with regression loss to simultaneously optimize the model. Furthermore, effective data augmentation strategies are also used to improve the performance. In comparisons with previous works, experiments are carried out on two standard IQA datasets and a challenge dataset. The results demonstrate the effectiveness of our work. The proposed method outperforms other methods on standard datasets and ranks 2nd in the no-reference track of NTIRE 2022 Perceptual Image Quality Assessment Challenge [53]. It verifies that our method is promising in solving diverse IQA problems and thus can be used to real-word applications.
ConvMAE: Masked Convolution Meets Masked Autoencoders
May 19, 2022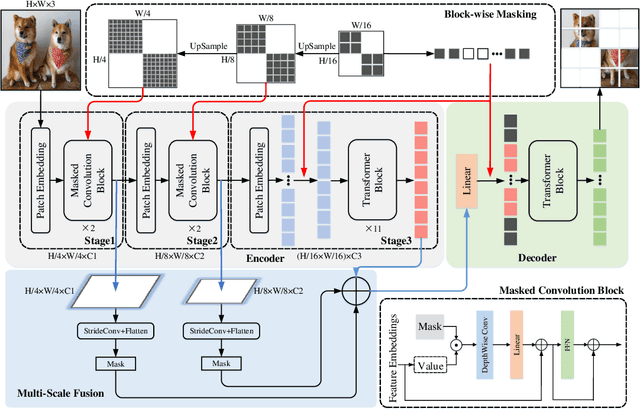
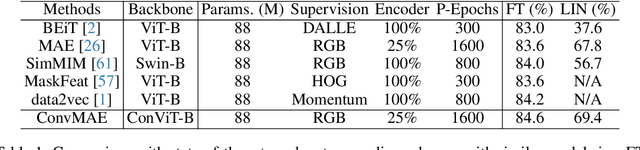
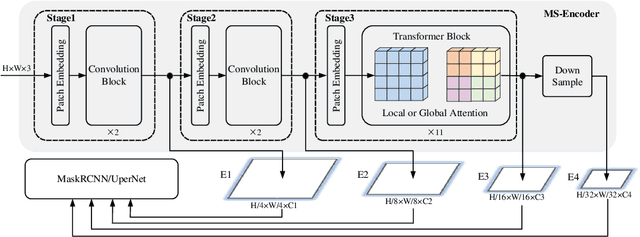
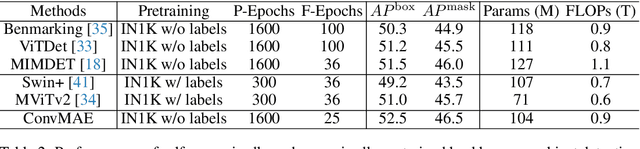
Vision Transformers (ViT) become widely-adopted architectures for various vision tasks. Masked auto-encoding for feature pretraining and multi-scale hybrid convolution-transformer architectures can further unleash the potentials of ViT, leading to state-of-the-art performances on image classification, detection and semantic segmentation. In this paper, our ConvMAE framework demonstrates that multi-scale hybrid convolution-transformer can learn more discriminative representations via the mask auto-encoding scheme. However, directly using the original masking strategy leads to the heavy computational cost and pretraining-finetuning discrepancy. To tackle the issue, we adopt the masked convolution to prevent information leakage in the convolution blocks. A simple block-wise masking strategy is proposed to ensure computational efficiency. We also propose to more directly supervise the multi-scale features of the encoder to boost multi-scale features. Based on our pretrained ConvMAE models, ConvMAE-Base improves ImageNet-1K finetuning accuracy by 1.4% compared with MAE-Base. On object detection, ConvMAE-Base finetuned for only 25 epochs surpasses MAE-Base fined-tuned for 100 epochs by 2.9% box AP and 2.2% mask AP respectively. Code and pretrained models are available at https://github.com/Alpha-VL/ConvMAE.
Certified Error Control of Candidate Set Pruning for Two-Stage Relevance Ranking
May 19, 2022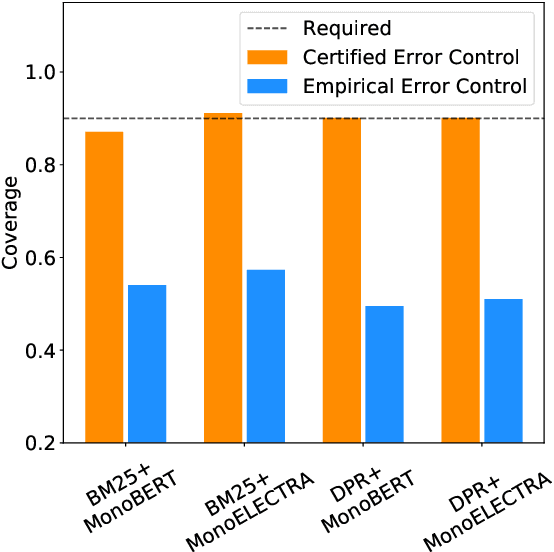

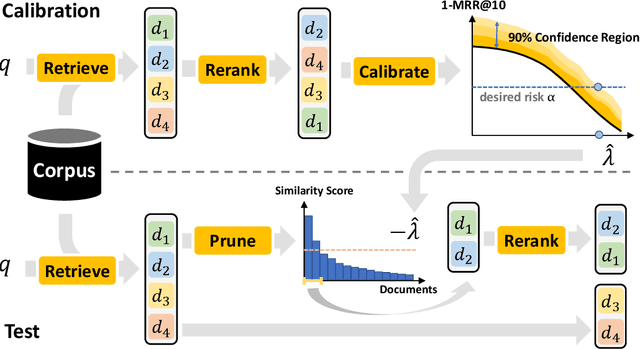
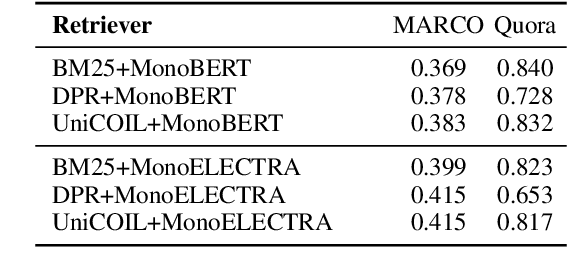
In information retrieval (IR), candidate set pruning has been commonly used to speed up two-stage relevance ranking. However, such an approach lacks accurate error control and often trades accuracy off against computational efficiency in an empirical fashion, lacking theoretical guarantees. In this paper, we propose the concept of certified error control of candidate set pruning for relevance ranking, which means that the test error after pruning is guaranteed to be controlled under a user-specified threshold with high probability. Both in-domain and out-of-domain experiments show that our method successfully prunes the first-stage retrieved candidate sets to improve the second-stage reranking speed while satisfying the pre-specified accuracy constraints in both settings. For example, on MS MARCO Passage v1, our method yields an average candidate set size of 27 out of 1,000 which increases the reranking speed by about 37 times, while the MRR@10 is greater than a pre-specified value of 0.38 with about 90% empirical coverage and the empirical baselines fail to provide such guarantee. Code and data are available at: https://github.com/alexlimh/CEC-Ranking.
Social Interpretable Tree for Pedestrian Trajectory Prediction
May 26, 2022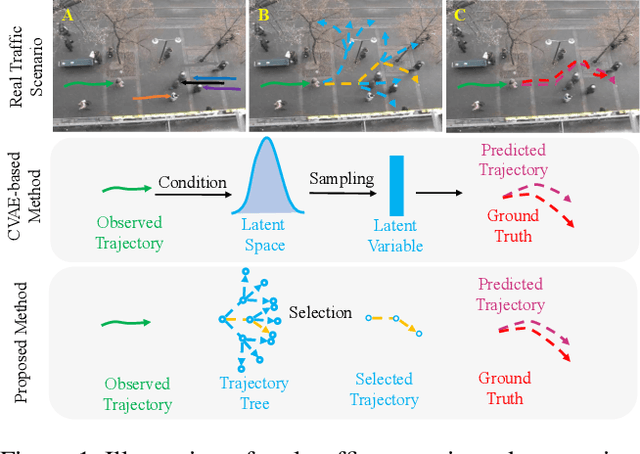
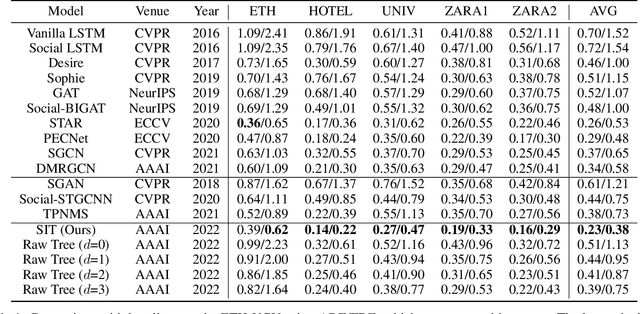
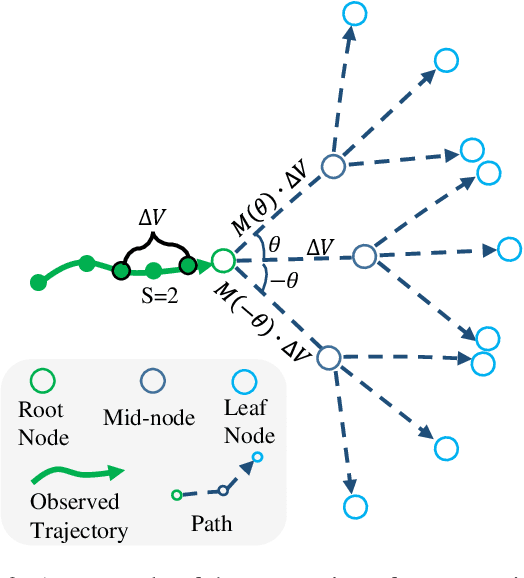
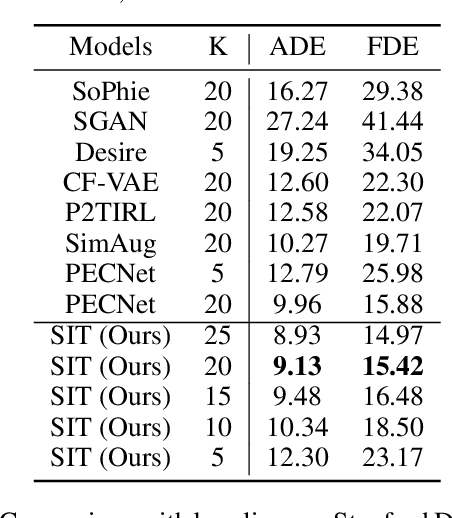
Understanding the multiple socially-acceptable future behaviors is an essential task for many vision applications. In this paper, we propose a tree-based method, termed as Social Interpretable Tree (SIT), to address this multi-modal prediction task, where a hand-crafted tree is built depending on the prior information of observed trajectory to model multiple future trajectories. Specifically, a path in the tree from the root to leaf represents an individual possible future trajectory. SIT employs a coarse-to-fine optimization strategy, in which the tree is first built by high-order velocity to balance the complexity and coverage of the tree and then optimized greedily to encourage multimodality. Finally, a teacher-forcing refining operation is used to predict the final fine trajectory. Compared with prior methods which leverage implicit latent variables to represent possible future trajectories, the path in the tree can explicitly explain the rough moving behaviors (e.g., go straight and then turn right), and thus provides better interpretability. Despite the hand-crafted tree, the experimental results on ETH-UCY and Stanford Drone datasets demonstrate that our method is capable of matching or exceeding the performance of state-of-the-art methods. Interestingly, the experiments show that the raw built tree without training outperforms many prior deep neural network based approaches. Meanwhile, our method presents sufficient flexibility in long-term prediction and different best-of-$K$ predictions.
On the Eigenvalues of Global Covariance Pooling for Fine-grained Visual Recognition
May 26, 2022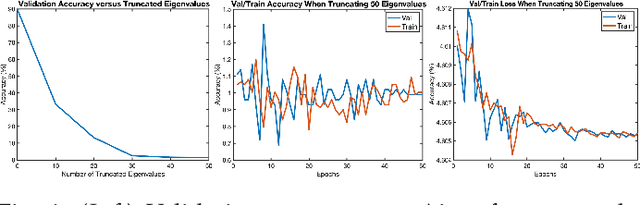

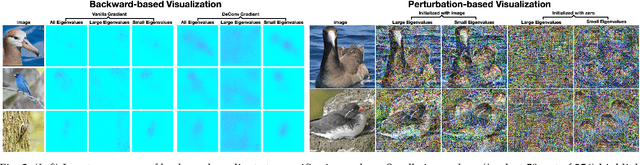
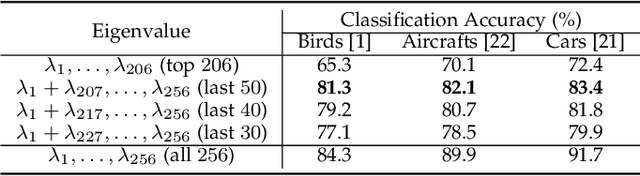
The Fine-Grained Visual Categorization (FGVC) is challenging because the subtle inter-class variations are difficult to be captured. One notable research line uses the Global Covariance Pooling (GCP) layer to learn powerful representations with second-order statistics, which can effectively model inter-class differences. In our previous conference paper, we show that truncating small eigenvalues of the GCP covariance can attain smoother gradient and improve the performance on large-scale benchmarks. However, on fine-grained datasets, truncating the small eigenvalues would make the model fail to converge. This observation contradicts the common assumption that the small eigenvalues merely correspond to the noisy and unimportant information. Consequently, ignoring them should have little influence on the performance. To diagnose this peculiar behavior, we propose two attribution methods whose visualizations demonstrate that the seemingly unimportant small eigenvalues are crucial as they are in charge of extracting the discriminative class-specific features. Inspired by this observation, we propose a network branch dedicated to magnifying the importance of small eigenvalues. Without introducing any additional parameters, this branch simply amplifies the small eigenvalues and achieves state-of-the-art performances of GCP methods on three fine-grained benchmarks. Furthermore, the performance is also competitive against other FGVC approaches on larger datasets. Code is available at \href{https://github.com/KingJamesSong/DifferentiableSVD}{https://github.com/KingJamesSong/DifferentiableSVD}.
Combining Deep Learning and Adaptive Sparse Modeling for Low-dose CT Reconstruction
May 19, 2022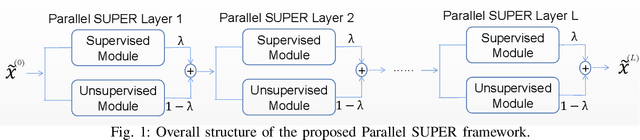
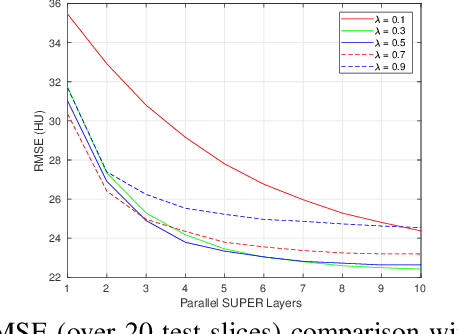
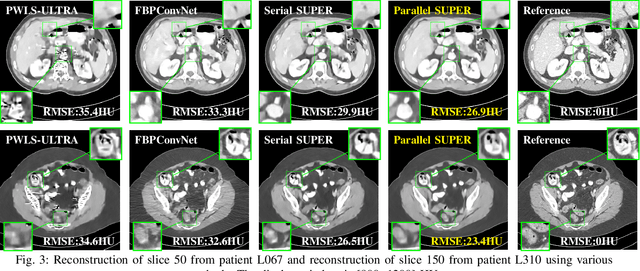
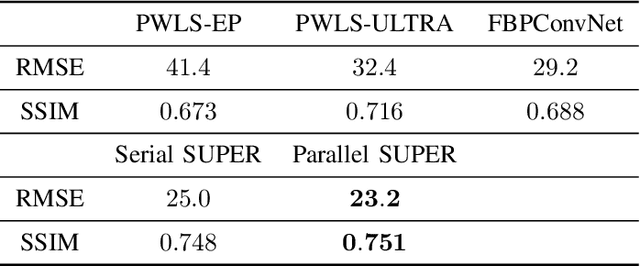
Traditional model-based image reconstruction (MBIR) methods combine forward and noise models with simple object priors. Recent application of deep learning methods for image reconstruction provides a successful data-driven approach to addressing the challenges when reconstructing images with measurement undersampling or various types of noise. In this work, we propose a hybrid supervised-unsupervised learning framework for X-ray computed tomography (CT) image reconstruction. The proposed learning formulation leverages both sparsity or unsupervised learning-based priors and neural network reconstructors to simulate a fixed-point iteration process. Each proposed trained block consists of a deterministic MBIR solver and a neural network. The information flows in parallel through these two reconstructors and is then optimally combined, and multiple such blocks are cascaded to form a reconstruction pipeline. We demonstrate the efficacy of this learned hybrid model for low-dose CT image reconstruction with limited training data, where we use the NIH AAPM Mayo Clinic Low Dose CT Grand Challenge dataset for training and testing. In our experiments, we study combinations of supervised deep network reconstructors and sparse representations-based (unsupervised) learned or analytical priors. Our results demonstrate the promising performance of the proposed framework compared to recent reconstruction methods.