 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Non-target Knowledge for Few-shot Semantic Segmentation
May 10, 2022

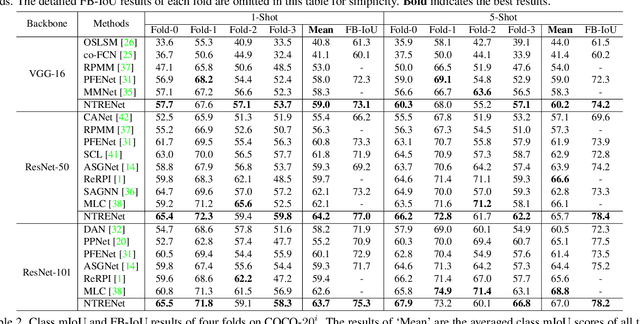
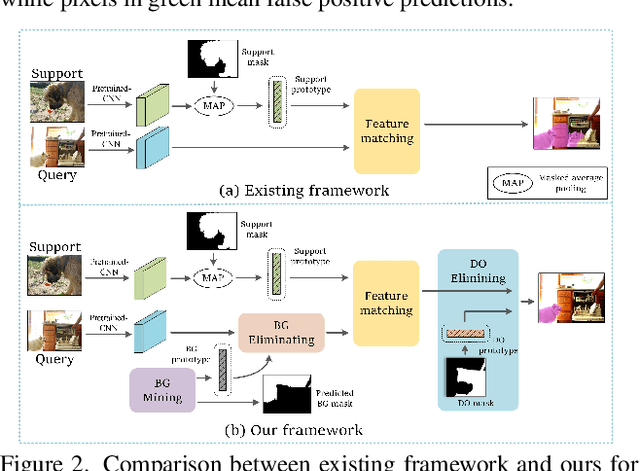
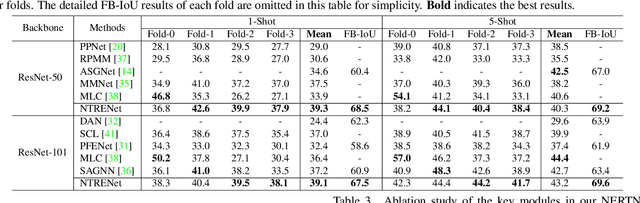
Existing studies in few-shot semantic segmentation only focus on mining the target object information, however, often are hard to tell ambiguous regions, especially in non-target regions, which include background (BG) and Distracting Objects (DOs). To alleviate this problem, we propose a novel framework, namely Non-Target Region Eliminating (NTRE) network, to explicitly mine and eliminate BG and DO regions in the query. First, a BG Mining Module (BGMM) is proposed to extract the BG region via learning a general BG prototype. To this end, we design a BG loss to supervise the learning of BGMM only using the known target object segmentation ground truth. Then, a BG Eliminating Module and a DO Eliminating Module are proposed to successively filter out the BG and DO information from the query feature, based on which we can obtain a BG and DO-free target object segmentation result. Furthermore, we propose a prototypical contrastive learning algorithm to improve the model ability of distinguishing the target object from DOs. Extensive experiments on both PASCAL-5i and COCO-20i datasets show that our approach is effective despite its simplicity.
Hausa Visual Genome: A Dataset for Multi-Modal English to Hausa Machine Translation
May 06, 2022
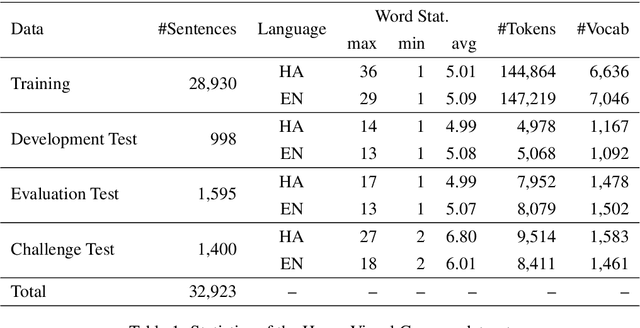
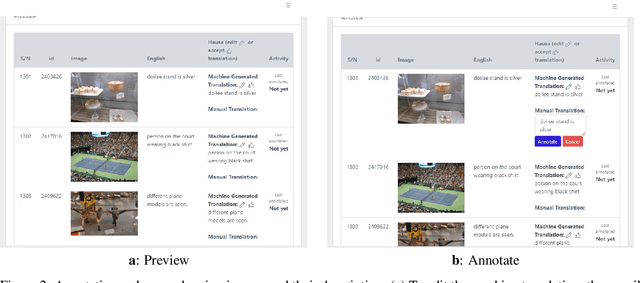

Multi-modal Machine Translation (MMT) enables the use of visual information to enhance the quality of translations. The visual information can serve as a valuable piece of context information to decrease the ambiguity of input sentences. Despite the increasing popularity of such a technique, good and sizeable datasets are scarce, limiting the full extent of their potential. Hausa, a Chadic language, is a member of the Afro-Asiatic language family. It is estimated that about 100 to 150 million people speak the language, with more than 80 million indigenous speakers. This is more than any of the other Chadic languages. Despite a large number of speakers, the Hausa language is considered low-resource in natural language processing (NLP). This is due to the absence of sufficient resources to implement most NLP tasks. While some datasets exist, they are either scarce, machine-generated, or in the religious domain. Therefore, there is a need to create training and evaluation data for implementing machine learning tasks and bridging the research gap in the language. This work presents the Hausa Visual Genome (HaVG), a dataset that contains the description of an image or a section within the image in Hausa and its equivalent in English. To prepare the dataset, we started by translating the English description of the images in the Hindi Visual Genome (HVG) into Hausa automatically. Afterward, the synthetic Hausa data was carefully post-edited considering the respective images. The dataset comprises 32,923 images and their descriptions that are divided into training, development, test, and challenge test set. The Hausa Visual Genome is the first dataset of its kind and can be used for Hausa-English machine translation, multi-modal research, and image description, among various other natural language processing and generation tasks.
Spatial Cross-Attention Improves Self-Supervised Visual Representation Learning
Jun 07, 2022
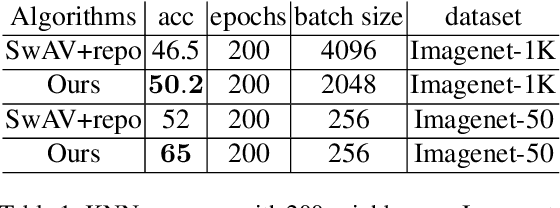
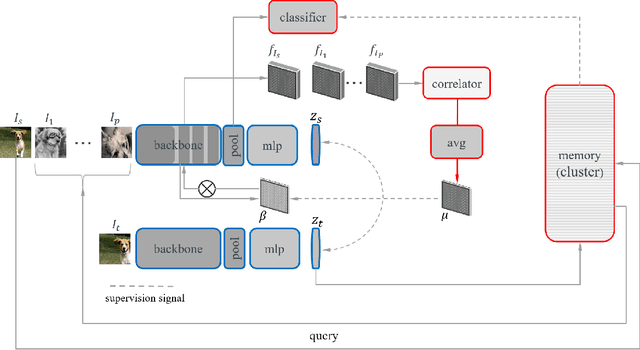
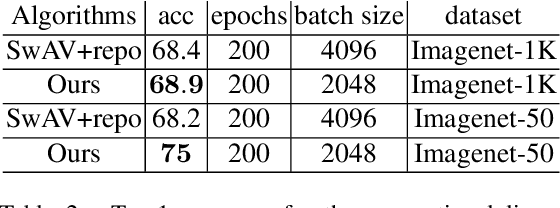
Unsupervised representation learning methods like SwAV are proved to be effective in learning visual semantics of a target dataset. The main idea behind these methods is that different views of a same image represent the same semantics. In this paper, we further introduce an add-on module to facilitate the injection of the knowledge accounting for spatial cross correlations among the samples. This in turn results in distilling intra-class information including feature level locations and cross similarities between same-class instances. The proposed add-on can be added to existing methods such as the SwAV. We can later remove the add-on module for inference without any modification of the learned weights. Through an extensive set of empirical evaluations, we verify that our method yields an improved performance in detecting the class activation maps, top-1 classification accuracy, and down-stream tasks such as object detection, with different configuration settings.
Scaling-up Generalized Planning as Heuristic Search with Landmarks
May 10, 2022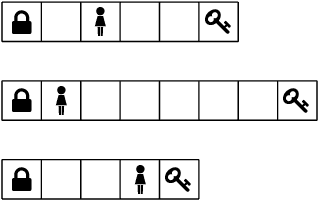
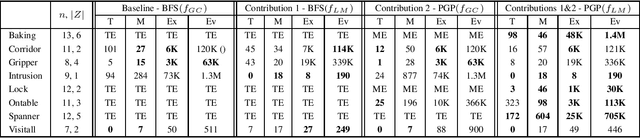
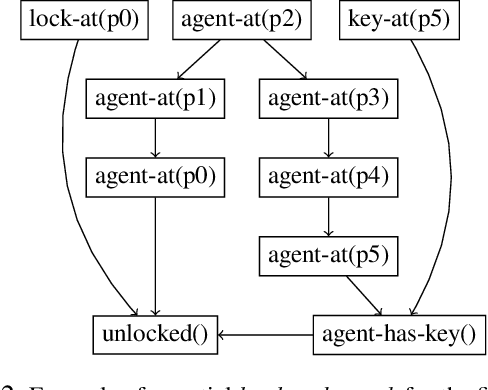
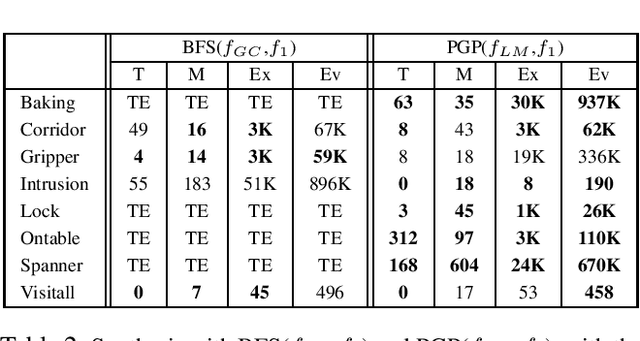
Landmarks are one of the most effective search heuristics for classical planning, but largely ignored in generalized planning. Generalized planning (GP) is usually addressed as a combinatorial search in a given space of algorithmic solutions, where candidate solutions are evaluated w.r.t.~the instances they solve. This type of solution evaluation ignores any sub-goal information that is not explicit in the representation of the planning instances, causing plateaus in the space of candidate generalized plans. Furthermore, node expansion in GP is a run-time bottleneck since it requires evaluating every child node over the entire batch of classical planning instances in a GP problem. In this paper we define a landmark counting heuristic for GP (that considers sub-goal information that is not explicitly represented in the planning instances), and a novel heuristic search algorithm for GP (that we call PGP) and that progressively processes subsets of the planning instances of a GP problem. Our two orthogonal contributions are analyzed in an ablation study, showing that both improve the state-of-the-art in GP as heuristic search, and that both benefit from each other when used in combination.
Multi-LexSum: Real-World Summaries of Civil Rights Lawsuits at Multiple Granularities
Jun 23, 2022
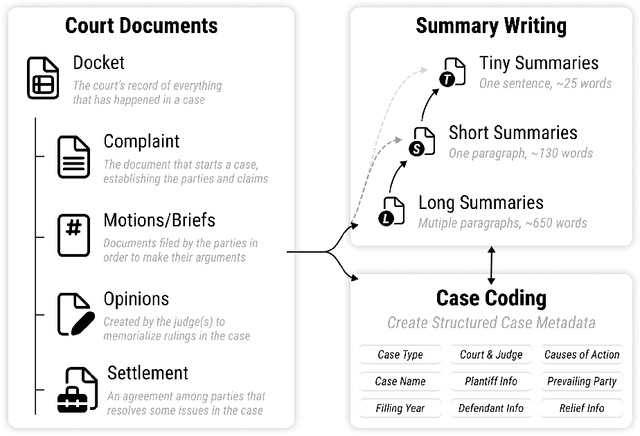


With the advent of large language models, methods for abstractive summarization have made great strides, creating potential for use in applications to aid knowledge workers processing unwieldy document collections. One such setting is the Civil Rights Litigation Clearinghouse (CRLC) (https://clearinghouse.net),which posts information about large-scale civil rights lawsuits, serving lawyers, scholars, and the general public. Today, summarization in the CRLC requires extensive training of lawyers and law students who spend hours per case understanding multiple relevant documents in order to produce high-quality summaries of key events and outcomes. Motivated by this ongoing real-world summarization effort, we introduce Multi-LexSum, a collection of 9,280 expert-authored summaries drawn from ongoing CRLC writing. Multi-LexSum presents a challenging multi-document summarization task given the length of the source documents, often exceeding two hundred pages per case. Furthermore, Multi-LexSum is distinct from other datasets in its multiple target summaries, each at a different granularity (ranging from one-sentence "extreme" summaries to multi-paragraph narrations of over five hundred words). We present extensive analysis demonstrating that despite the high-quality summaries in the training data (adhering to strict content and style guidelines), state-of-the-art summarization models perform poorly on this task. We release Multi-LexSum for further research in summarization methods as well as to facilitate development of applications to assist in the CRLC's mission at https://multilexsum.github.io.
Approximate Vanishing Ideal Computations at Scale
Jul 04, 2022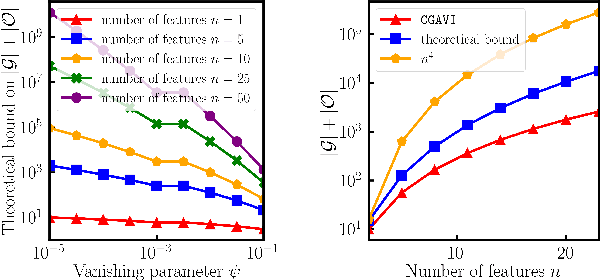

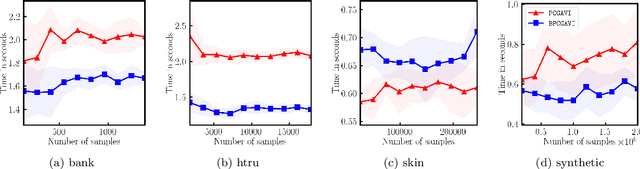

The approximate vanishing ideal of a set of points $X = \{\mathbf{x}_1, \ldots, \mathbf{x}_m\}\subseteq [0,1]^n$ is the set of polynomials that approximately evaluate to $0$ over all points $\mathbf{x} \in X$ and admits an efficient representation by a finite set of polynomials called generators. Algorithms that construct this set of generators are extensively studied but ultimately find little practical application because their computational complexities are thought to be superlinear in the number of samples $m$. In this paper, we focus on scaling up the Oracle Approximate Vanishing Ideal algorithm (OAVI), one of the most powerful of these methods. We prove that the computational complexity of OAVI is not superlinear but linear in the number of samples $m$ and polynomial in the number of features $n$, making OAVI an attractive preprocessing technique for large-scale machine learning. To further accelerate OAVI's training time, we propose two changes: First, as the name suggests, OAVI makes repeated oracle calls to convex solvers throughout its execution. By replacing the Pairwise Conditional Gradients algorithm, one of the standard solvers used in OAVI, with the faster Blended Pairwise Conditional Gradients algorithm, we illustrate how OAVI directly benefits from advancements in the study of convex solvers. Second, we propose Inverse Hessian Boosting (IHB): IHB exploits the fact that OAVI repeatedly solves quadratic convex optimization problems that differ only by very little and whose solutions can be written in closed form using inverse Hessian information. By efficiently updating the inverse of the Hessian matrix, the convex optimization problems can be solved almost instantly, accelerating OAVI's training time by up to multiple orders of magnitude. We complement our theoretical analysis with extensive numerical experiments on data sets whose sample numbers are in the millions.
FedBC: Calibrating Global and Local Models via Federated Learning Beyond Consensus
Jun 26, 2022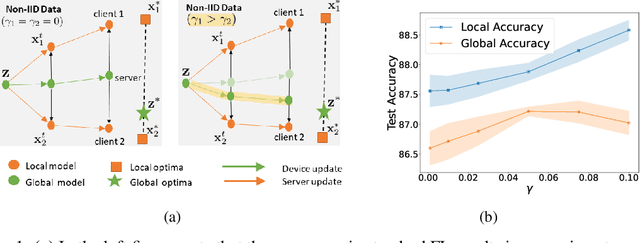
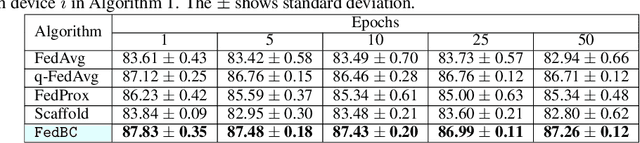
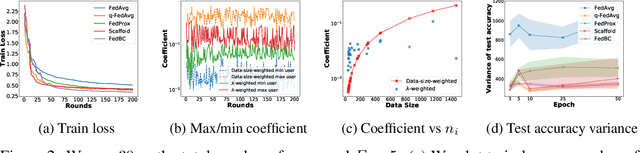
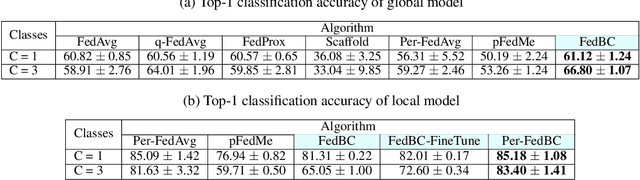
In federated learning (FL), the objective of collaboratively learning a global model through aggregation of model updates across devices tends to oppose the goal of personalization via local information. In this work, we calibrate this tradeoff in a quantitative manner through a multi-criterion optimization-based framework, which we cast as a constrained program: the objective for a device is its local objective, which it seeks to minimize while satisfying nonlinear constraints that quantify the proximity between the local and the global model. By considering the Lagrangian relaxation of this problem, we develop an algorithm that allows each node to minimize its local component of Lagrangian through queries to a first-order gradient oracle. Then, the server executes Lagrange multiplier ascent steps followed by a Lagrange multiplier-weighted averaging step. We call this instantiation of the primal-dual method Federated Learning Beyond Consensus ($\texttt{FedBC}$). Theoretically, we establish that $\texttt{FedBC}$ converges to a first-order stationary point at rates that matches the state of the art, up to an additional error term that depends on the tolerance parameter that arises due to the proximity constraints. Overall, the analysis is a novel characterization of primal-dual methods applied to non-convex saddle point problems with nonlinear constraints. Finally, we demonstrate that $\texttt{FedBC}$ balances the global and local model test accuracy metrics across a suite of datasets (Synthetic, MNIST, CIFAR-10, Shakespeare), achieving competitive performance with the state of the art.
Guidelines and a Corpus for Extracting Biographical Events
Jun 07, 2022
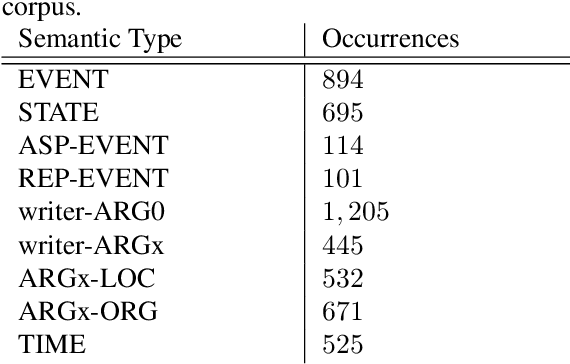
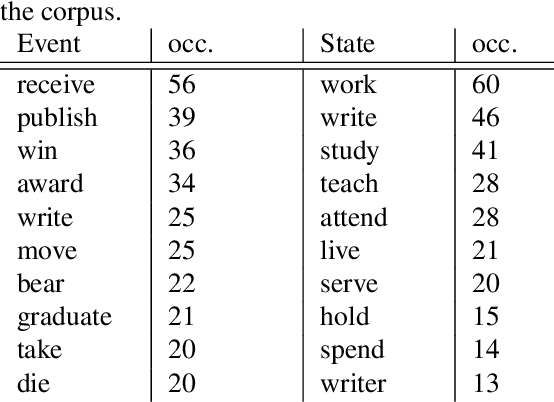
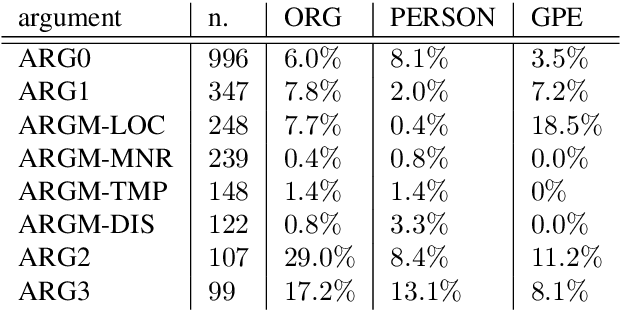
Despite biographies are widely spread within the Semantic Web, resources and approaches to automatically extract biographical events are limited. Such limitation reduces the amount of structured, machine-readable biographical information, especially about people belonging to underrepresented groups. Our work challenges this limitation by providing a set of guidelines for the semantic annotation of life events. The guidelines are designed to be interoperable with existing ISO-standards for semantic annotation: ISO-TimeML (ISO-24617-1), and SemAF (ISO-24617-4). Guidelines were tested through an annotation task of Wikipedia biographies of underrepresented writers, namely authors born in non-Western countries, migrants, or belonging to ethnic minorities. 1,000 sentences were annotated by 4 annotators with an average Inter-Annotator Agreement of 0.825. The resulting corpus was mapped on OntoNotes. Such mapping allowed to to expand our corpus, showing that already existing resources may be exploited for the biographical event extraction task.
Fixed-point iterations for several dissimilarity measure barycenters in the Gaussian case
May 10, 2022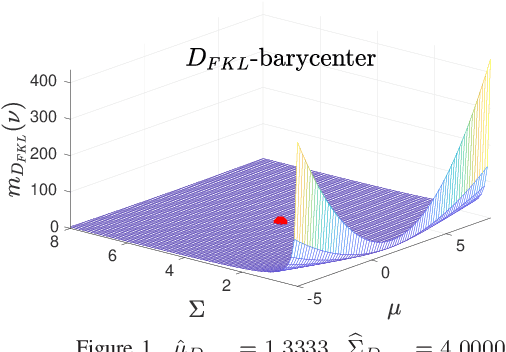
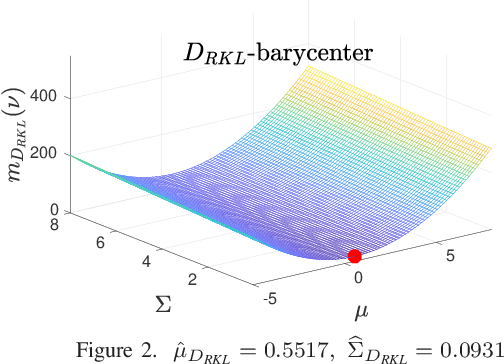
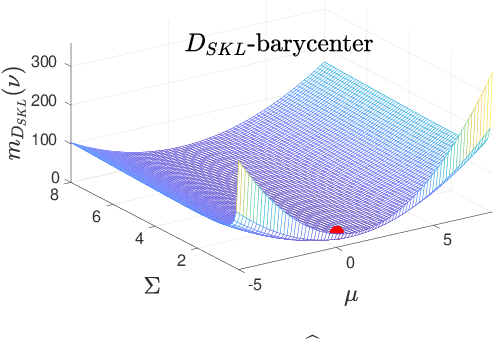
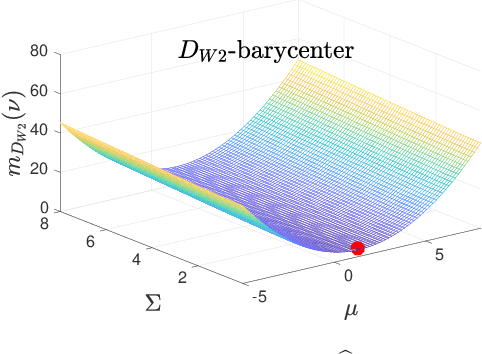
In target tracking and sensor fusion contexts it is not unusual to deal with a large number of Gaussian densities that encode the available information (multiple hypotheses), as in applications where many sensors, affected by clutter or multimodal noise, take measurements on the same scene. In such cases reduction procedures must be implemented, with the purpose of limiting the computational load. In some situations it is required to fuse all available information into a single hypothesis, and this is usually done by computing the barycenter of the set. However, such computation strongly depends on the chosen dissimilarity measure, and most often it must be performed making use of numerical methods, since in very few cases the barycenter can be computed analytically. Some issues, like the constraint on the covariance, that must be symmetric and positive definite, make it hard the numerical computation of the barycenter of a set of Gaussians. In this work, Fixed-Point Iterations (FPI) are presented for the computation of barycenters according to several dissimilarity measures, making up a useful toolbox for fusion/reduction of Gaussian sets in applications where specific dissimilarity measures are required.
Using dependency parsing for few-shot learning in distributional semantics
May 12, 2022
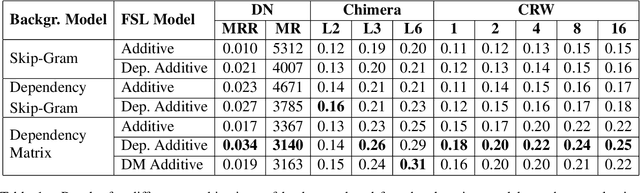
In this work, we explore the novel idea of employing dependency parsing information in the context of few-shot learning, the task of learning the meaning of a rare word based on a limited amount of context sentences. Firstly, we use dependency-based word embedding models as background spaces for few-shot learning. Secondly, we introduce two few-shot learning methods which enhance the additive baseline model by using dependencies.