 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKAM-CoT: Knowledge Augmented Multimodal Chain-of-Thoughts Reasoning
Jan 23, 2024



Large Language Models (LLMs) have demonstrated impressive performance in natural language processing tasks by leveraging chain of thought (CoT) that enables step-by-step thinking. Extending LLMs with multimodal capabilities is the recent interest, but incurs computational cost and requires substantial hardware resources. To address these challenges, we propose KAM-CoT a framework that integrates CoT reasoning, Knowledge Graphs (KGs), and multiple modalities for a comprehensive understanding of multimodal tasks. KAM-CoT adopts a two-stage training process with KG grounding to generate effective rationales and answers. By incorporating external knowledge from KGs during reasoning, the model gains a deeper contextual understanding reducing hallucinations and enhancing the quality of answers. This knowledge-augmented CoT reasoning empowers the model to handle questions requiring external context, providing more informed answers. Experimental findings show KAM-CoT outperforms the state-of-the-art methods. On the ScienceQA dataset, we achieve an average accuracy of 93.87%, surpassing GPT-3.5 (75.17%) by 18% and GPT-4 (83.99%) by 10%. Remarkably, KAM-CoT achieves these results with only 280M trainable parameters at a time, demonstrating its cost-efficiency and effectiveness.
Silo NLP's Participation at WAT2022
Aug 02, 2022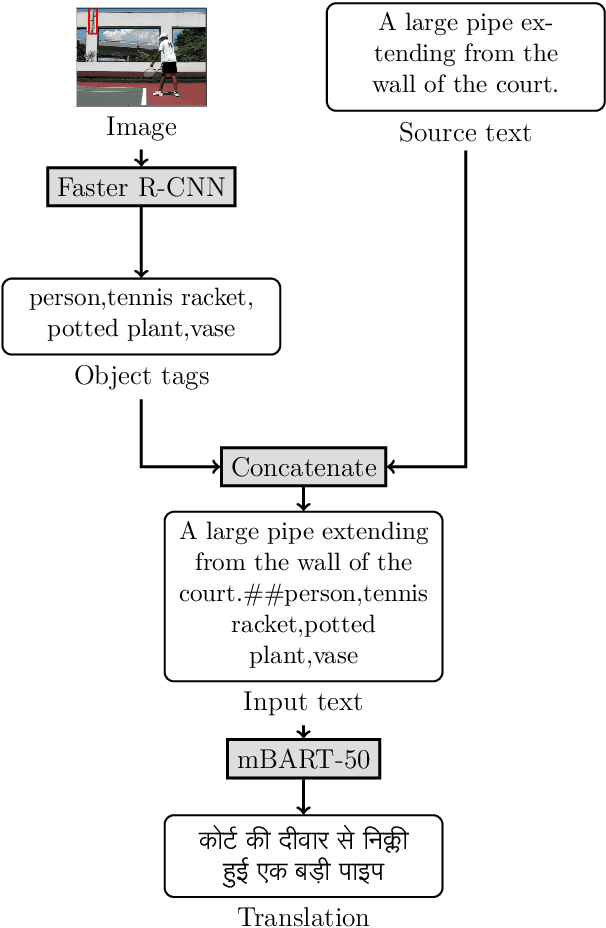
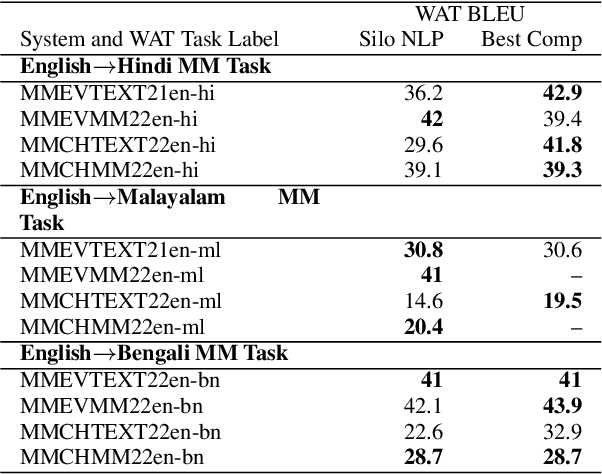

This paper provides the system description of "Silo NLP's" submission to the Workshop on Asian Translation (WAT2022). We have participated in the Indic Multimodal tasks (English->Hindi, English->Malayalam, and English->Bengali Multimodal Translation). For text-only translation, we trained Transformers from scratch and fine-tuned mBART-50 models. For multimodal translation, we used the same mBART architecture and extracted object tags from the images to use as visual features concatenated with the text sequence. Our submission tops many tasks including English->Hindi multimodal translation (evaluation test), English->Malayalam text-only and multimodal translation (evaluation test), English->Bengali multimodal translation (challenge test), and English->Bengali text-only translation (evaluation test).
Hausa Visual Genome: A Dataset for Multi-Modal English to Hausa Machine Translation
May 06, 2022
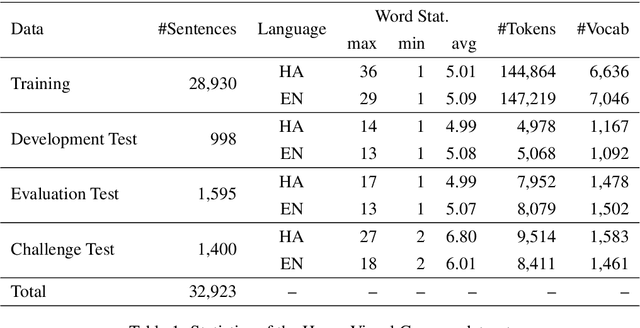
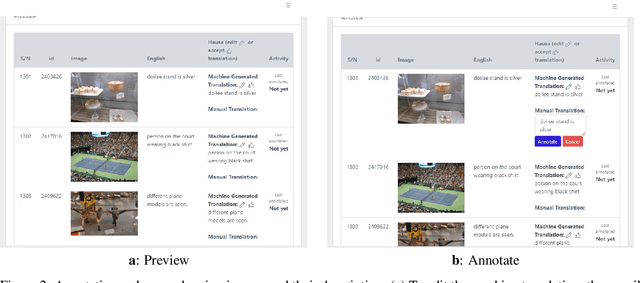

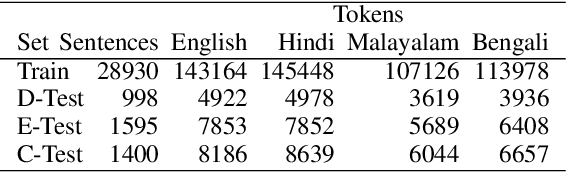
Multi-modal Machine Translation (MMT) enables the use of visual information to enhance the quality of translations. The visual information can serve as a valuable piece of context information to decrease the ambiguity of input sentences. Despite the increasing popularity of such a technique, good and sizeable datasets are scarce, limiting the full extent of their potential. Hausa, a Chadic language, is a member of the Afro-Asiatic language family. It is estimated that about 100 to 150 million people speak the language, with more than 80 million indigenous speakers. This is more than any of the other Chadic languages. Despite a large number of speakers, the Hausa language is considered low-resource in natural language processing (NLP). This is due to the absence of sufficient resources to implement most NLP tasks. While some datasets exist, they are either scarce, machine-generated, or in the religious domain. Therefore, there is a need to create training and evaluation data for implementing machine learning tasks and bridging the research gap in the language. This work presents the Hausa Visual Genome (HaVG), a dataset that contains the description of an image or a section within the image in Hausa and its equivalent in English. To prepare the dataset, we started by translating the English description of the images in the Hindi Visual Genome (HVG) into Hausa automatically. Afterward, the synthetic Hausa data was carefully post-edited considering the respective images. The dataset comprises 32,923 images and their descriptions that are divided into training, development, test, and challenge test set. The Hausa Visual Genome is the first dataset of its kind and can be used for Hausa-English machine translation, multi-modal research, and image description, among various other natural language processing and generation tasks.