 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTailNLG: A Multilingual Benchmark Addressing Verbalization of Long-Tail Entities
Mar 29, 2026The automatic verbalization of structured knowledge is a key task for making knowledge graphs accessible to non-expert users and supporting retrieval-augmented generation systems. Although recent advances in Data-to-Text generation have improved multilingual coverage, little attention has been paid to potential biases in the verbalization of rare entities, frequently known as long-tail entities. In this work, we present the first systematic study of long-tail entities in Data-to-Text generation. We introduce TailNLG, a new multilingual benchmark in English, Italian, and Spanish, built from Wikidata and covering entities with varying levels of popularity. We evaluate three different families of large language models in zero-shot settings and compare their performance on rare versus common entities, as well as against the established WebNLG benchmark. Our results reveal a consistent bias against long-tail entities: embedding-based scores are lower, and model uncertainty is higher for rare entities. We further show that the impact of long-tail entities varies across models and languages, and that existing evaluation metrics do not consistently capture these differences, highlighting the need for more reliable evaluation frameworks.
Conspiracy Frame: a Semiotically-Driven Approach for Conspiracy Theories Detection
Mar 22, 2026Conspiracy theories are anti-authoritarian narratives that lead to social conflict, impacting how people perceive political information. To help in understanding this issue, we introduce the Conspiracy Frame: a fine-grained semantic representation of conspiratorial narratives derived from frame-semantics and semiotics, which spawned the Conspiracy Frames (Con.Fra.) dataset: a corpus of Telegram messages annotated at span-level. The Conspiracy Frame and Con.Fra. dataset contribute to the implementation of a more generalizable understanding and recognition of conspiracy theories. We observe the ability of LLMs to recognize this phenomenon in-domain and out-of-domain, investigating the role that frames may have in supporting this task. Results show that, while the injection of frames in an in-context approach does not lead to clear increase of performance, it has potential; the mapping of annotated spans with FrameNet shows abstract semantic patterns (e.g., `Kinship', `Ingest\_substance') that potentially pave the way for a more semantically- and semiotically-aware detection of conspiratorial narratives.
Exploring Values in Museum Artifacts in the SPICE project: a Preliminary Study
Nov 13, 2023


This document describes the rationale, the implementation and a preliminary evaluation of a semantic reasoning tool developed in the EU H2020 SPICE project to enhance the diversity of perspectives experienced by museum visitors. The tool, called DEGARI 2.0 for values, relies on the commonsense reasoning framework TCL, and exploits an ontological model formalizingthe Haidt's theory of moral values to associate museum items with combined values and emotions. Within a museum exhibition, this tool can suggest cultural items that are associated not only with the values of already experienced or preferred objects, but also with novel items with different value stances, opening the visit experience to more inclusive interpretations of cultural content. The system has been preliminarily tested, in the context of the SPICE project, on the collection of the Hecht Museum of Haifa.
The World Literature Knowledge Graph
Jul 31, 2023



Digital media have enabled the access to unprecedented literary knowledge. Authors, readers, and scholars are now able to discover and share an increasing amount of information about books and their authors. However, these sources of knowledge are fragmented and do not adequately represent non-Western writers and their works. In this paper we present The World Literature Knowledge Graph, a semantic resource containing 194,346 writers and 965,210 works, specifically designed for exploring facts about literary works and authors from different parts of the world. The knowledge graph integrates information about the reception of literary works gathered from 3 different communities of readers, aligned according to a single semantic model. The resource is accessible through an online visualization platform, which can be found at the following URL: https://literaturegraph.di.unito.it/. This platform has been rigorously tested and validated by $3$ distinct categories of experts who have found it to be highly beneficial for their respective work domains. These categories include teachers, researchers in the humanities, and professionals in the publishing industry. The feedback received from these experts confirms that they can effectively utilize the platform to enhance their work processes and achieve valuable outcomes.
Wikibio: a Semantic Resource for the Intersectional Analysis of Biographical Events
Jun 15, 2023Biographical event detection is a relevant task for the exploration and comparison of the ways in which people's lives are told and represented. In this sense, it may support several applications in digital humanities and in works aimed at exploring bias about minoritized groups. Despite that, there are no corpora and models specifically designed for this task. In this paper we fill this gap by presenting a new corpus annotated for biographical event detection. The corpus, which includes 20 Wikipedia biographies, was compared with five existing corpora to train a model for the biographical event detection task. The model was able to detect all mentions of the target-entity in a biography with an F-score of 0.808 and the entity-related events with an F-score of 0.859. Finally, the model was used for performing an analysis of biases about women and non-Western people in Wikipedia biographies.
Preliminary results of a therapeutic lab for promoting autonomies in autistic children
May 04, 2023This extended abtract describes the preliminary qualitative results coming from a therapeutic laboratory focused on the use of the Pepper robot to promote autonomies and functional acquisitions in highly functioning (Asperger) children with autism. The field lab, ideated and led by a multidisciplinary team, involved 4 children, aged 11-13, who attended the laboratory sessions once a week for four months.
The URW-KG: a Resource for Tackling the Underrepresentation of non-Western Writers
Dec 21, 2022



Digital media have enabled the access to unprecedented literary knowledge. Authors, readers, and scholars are now able to discover and share an increasing amount of information about books and their authors. Notwithstanding, digital archives are still unbalanced: writers from non-Western countries are less represented, and such a condition leads to the perpetration of old forms of discrimination. In this paper, we present the Under-Represented Writers Knowledge Graph (URW-KG), a resource designed to explore and possibly amend this lack of representation by gathering and mapping information about works and authors from Wikidata and three other sources: Open Library, Goodreads, and Google Books. The experiments based on KG embeddings showed that the integrated information encoded in the graph allows scholars and users to be more easily exposed to non-Western literary works and authors with respect to Wikidata alone. This opens to the development of fairer and effective tools for author discovery and exploration.
Guidelines and a Corpus for Extracting Biographical Events
Jun 07, 2022
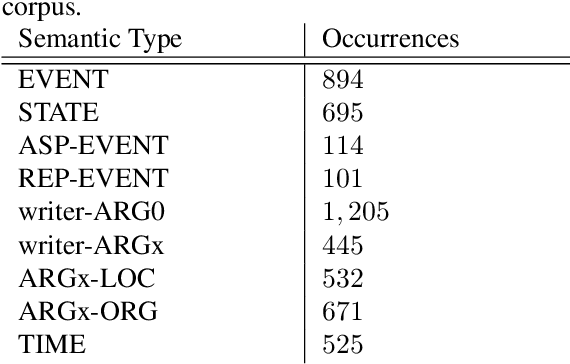
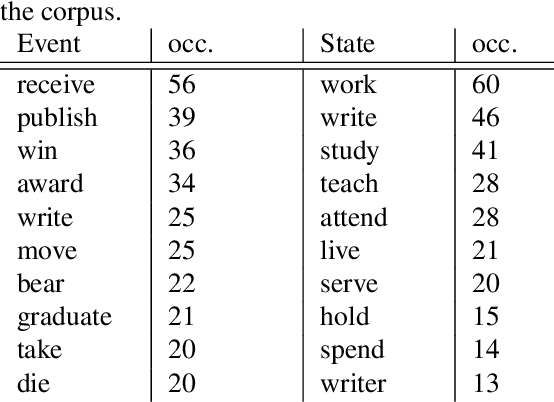
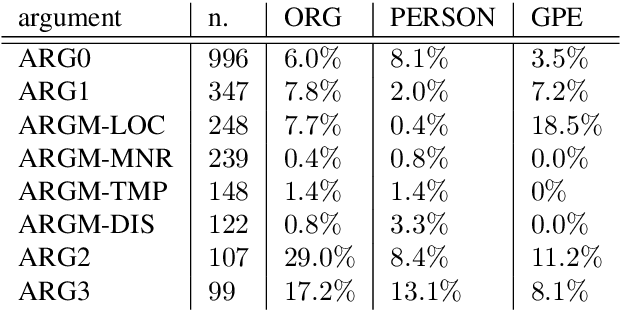
Despite biographies are widely spread within the Semantic Web, resources and approaches to automatically extract biographical events are limited. Such limitation reduces the amount of structured, machine-readable biographical information, especially about people belonging to underrepresented groups. Our work challenges this limitation by providing a set of guidelines for the semantic annotation of life events. The guidelines are designed to be interoperable with existing ISO-standards for semantic annotation: ISO-TimeML (ISO-24617-1), and SemAF (ISO-24617-4). Guidelines were tested through an annotation task of Wikipedia biographies of underrepresented writers, namely authors born in non-Western countries, migrants, or belonging to ethnic minorities. 1,000 sentences were annotated by 4 annotators with an average Inter-Annotator Agreement of 0.825. The resulting corpus was mapped on OntoNotes. Such mapping allowed to to expand our corpus, showing that already existing resources may be exploited for the biographical event extraction task.
APPReddit: a Corpus of Reddit Posts Annotated for Appraisal
May 31, 2022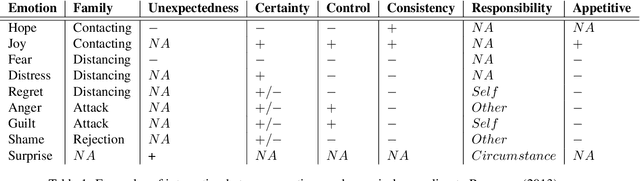
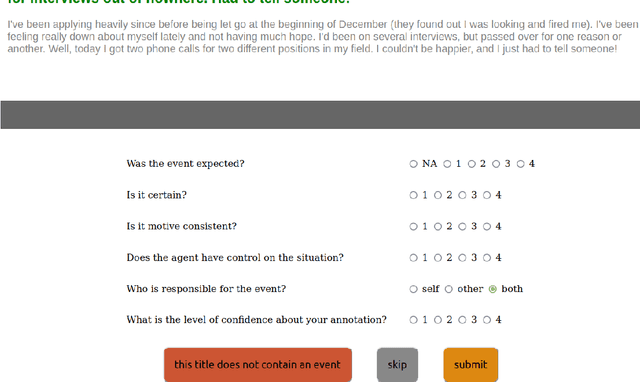

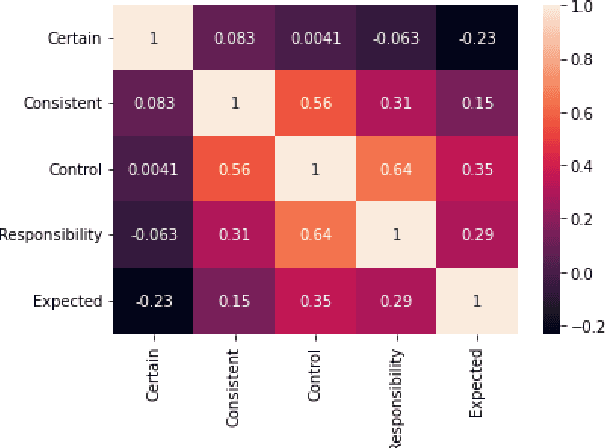
Despite the large number of computational resources for emotion recognition, there is a lack of data sets relying on appraisal models. According to Appraisal theories, emotions are the outcome of a multi-dimensional evaluation of events. In this paper, we present APPReddit, the first corpus of non-experimental data annotated according to this theory. After describing its development, we compare our resource with enISEAR, a corpus of events created in an experimental setting and annotated for appraisal. Results show that the two corpora can be mapped notwithstanding different typologies of data and annotations schemes. A SVM model trained on APPReddit predicts four appraisal dimensions without significant loss. Merging both corpora in a single training set increases the prediction of 3 out of 4 dimensions. Such findings pave the way to a better performing classification model for appraisal prediction.
Autistic Children's Mental Model of an Humanoid Robot
Mar 14, 2022This position paper introduces the results of an initial card sorting experiment based on the reactions and questions of a group of children with autism working with a humanoid robot in a therapeutic laboratory on autonomy.