 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2026 Task 9: Detecting Multilingual, Multicultural and Multievent Online Polarization
Apr 08, 2026We present SemEval-2026 Task 9, a shared task on online polarization detection, covering 22 languages and comprising over 110K annotated instances. Each data instance is multi-labeled with the presence of polarization, polarization type, and polarization manifestation. Participants were asked to predict labels in three sub-tasks: (1) detecting the presence of polarization, (2) identifying the type of polarization, and (3) recognizing the polarization manifestation. The three tasks attracted over 1,000 participants worldwide and more than 10k submission on Codabench. We received final submissions from 67 teams and 73 system description papers. We report the baseline results and analyze the performance of the best-performing systems, highlighting the most common approaches and the most effective methods across different subtasks and languages. The dataset of this task is publicly available.
Building pre-train LLM Dataset for the INDIC Languages: a case study on Hindi
Jul 13, 2024



Large language models (LLMs) demonstrated transformative capabilities in many applications that require automatically generating responses based on human instruction. However, the major challenge for building LLMs, particularly in Indic languages, is the availability of high-quality data for building foundation LLMs. In this paper, we are proposing a large pre-train dataset in Hindi useful for the Indic language Hindi. We have collected the data span across several domains including major dialects in Hindi. The dataset contains 1.28 billion Hindi tokens. We have explained our pipeline including data collection, pre-processing, and availability for LLM pre-training. The proposed approach can be easily extended to other Indic and low-resource languages and will be available freely for LLM pre-training and LLM research purposes.
Towards a More Inclusive AI: Progress and Perspectives in Large Language Model Training for the Sámi Language
May 09, 2024



S\'ami, an indigenous language group comprising multiple languages, faces digital marginalization due to the limited availability of data and sophisticated language models designed for its linguistic intricacies. This work focuses on increasing technological participation for the S\'ami language. We draw the attention of the ML community towards the language modeling problem of Ultra Low Resource (ULR) languages. ULR languages are those for which the amount of available textual resources is very low, and the speaker count for them is also very low. ULRLs are also not supported by mainstream Large Language Models (LLMs) like ChatGPT, due to which gathering artificial training data for them becomes even more challenging. Mainstream AI foundational model development has given less attention to this category of languages. Generally, these languages have very few speakers, making it hard to find them. However, it is important to develop foundational models for these ULR languages to promote inclusion and the tangible abilities and impact of LLMs. To this end, we have compiled the available S\'ami language resources from the web to create a clean dataset for training language models. In order to study the behavior of modern LLM models with ULR languages (S\'ami), we have experimented with different kinds of LLMs, mainly at the order of $\sim$ seven billion parameters. We have also explored the effect of multilingual LLM training for ULRLs. We found that the decoder-only models under a sequential multilingual training scenario perform better than joint multilingual training, whereas multilingual training with high semantic overlap, in general, performs better than training from scratch.This is the first study on the S\'ami language for adapting non-statistical language models that use the latest developments in the field of natural language processing (NLP).
Building a Llama2-finetuned LLM for Odia Language Utilizing Domain Knowledge Instruction Set
Dec 19, 2023Building LLMs for languages other than English is in great demand due to the unavailability and performance of multilingual LLMs, such as understanding the local context. The problem is critical for low-resource languages due to the need for instruction sets. In a multilingual country like India, there is a need for LLMs supporting Indic languages to provide generative AI and LLM-based technologies and services to its citizens. This paper presents our approach of i) generating a large Odia instruction set, including domain knowledge data suitable for LLM fine-tuning, and ii) building a Llama2-finetuned model tailored for enhanced performance in the Odia domain. The proposed work will help researchers build an instruction set and LLM, particularly for Indic languages. We will release the model and instruction set for the public for research and noncommercial purposes.
HaVQA: A Dataset for Visual Question Answering and Multimodal Research in Hausa Language
May 28, 2023



This paper presents HaVQA, the first multimodal dataset for visual question-answering (VQA) tasks in the Hausa language. The dataset was created by manually translating 6,022 English question-answer pairs, which are associated with 1,555 unique images from the Visual Genome dataset. As a result, the dataset provides 12,044 gold standard English-Hausa parallel sentences that were translated in a fashion that guarantees their semantic match with the corresponding visual information. We conducted several baseline experiments on the dataset, including visual question answering, visual question elicitation, text-only and multimodal machine translation.
Machine Translation by Projecting Text into the Same Phonetic-Orthographic Space Using a Common Encoding
May 21, 2023The use of subword embedding has proved to be a major innovation in Neural Machine Translation (NMT). It helps NMT to learn better context vectors for Low Resource Languages (LRLs) so as to predict the target words by better modelling the morphologies of the two languages and also the morphosyntax transfer. Even so, their performance for translation in Indian language to Indian language scenario is still not as good as for resource-rich languages. One reason for this is the relative morphological richness of Indian languages, while another is that most of them fall into the extremely low resource or zero-shot categories. Since most major Indian languages use Indic or Brahmi origin scripts, the text written in them is highly phonetic in nature and phonetically similar in terms of abstract letters and their arrangements. We use these characteristics of Indian languages and their scripts to propose an approach based on common multilingual Latin-based encodings (WX notation) that take advantage of language similarity while addressing the morphological complexity issue in NMT. These multilingual Latin-based encodings in NMT, together with Byte Pair Embedding (BPE) allow us to better exploit their phonetic and orthographic as well as lexical similarities to improve the translation quality by projecting different but similar languages on the same orthographic-phonetic character space. We verify the proposed approach by demonstrating experiments on similar language pairs (Gujarati-Hindi, Marathi-Hindi, Nepali-Hindi, Maithili-Hindi, Punjabi-Hindi, and Urdu-Hindi) under low resource conditions. The proposed approach shows an improvement in a majority of cases, in one case as much as ~10 BLEU points compared to baseline techniques for similar language pairs. We also get up to ~1 BLEU points improvement on distant and zero-shot language pairs.
Silo NLP's Participation at WAT2022
Aug 02, 2022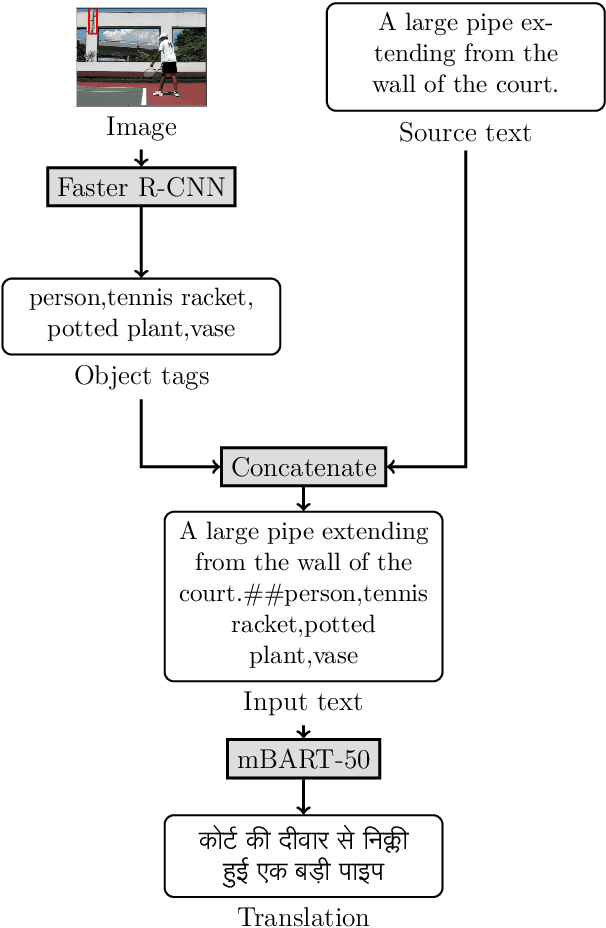
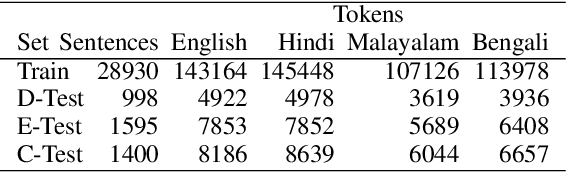
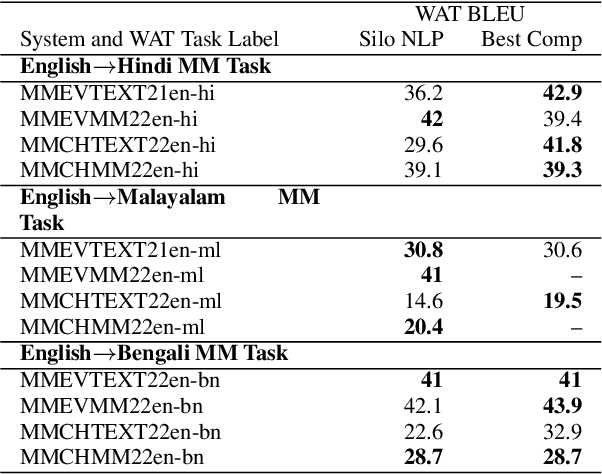

This paper provides the system description of "Silo NLP's" submission to the Workshop on Asian Translation (WAT2022). We have participated in the Indic Multimodal tasks (English->Hindi, English->Malayalam, and English->Bengali Multimodal Translation). For text-only translation, we trained Transformers from scratch and fine-tuned mBART-50 models. For multimodal translation, we used the same mBART architecture and extracted object tags from the images to use as visual features concatenated with the text sequence. Our submission tops many tasks including English->Hindi multimodal translation (evaluation test), English->Malayalam text-only and multimodal translation (evaluation test), English->Bengali multimodal translation (challenge test), and English->Bengali text-only translation (evaluation test).
Universal Dependency Treebank for Odia Language
May 24, 2022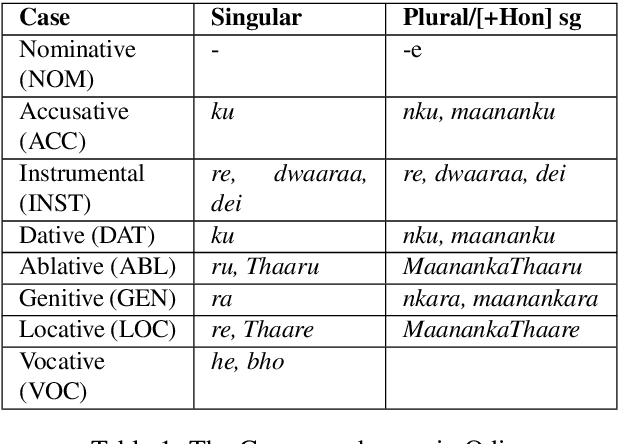
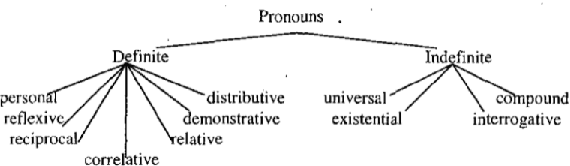
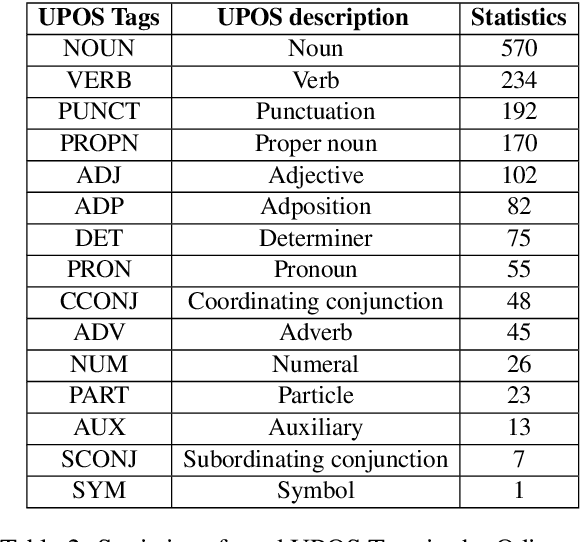
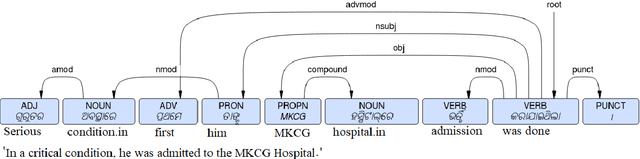
This paper presents the first publicly available treebank of Odia, a morphologically rich low resource Indian language. The treebank contains approx. 1082 tokens (100 sentences) in Odia selected from "Samantar", the largest available parallel corpora collection for Indic languages. All the selected sentences are manually annotated following the ``Universal Dependency (UD)" guidelines. The morphological analysis of the Odia treebank was performed using machine learning techniques. The Odia annotated treebank will enrich the Odia language resource and will help in building language technology tools for cross-lingual learning and typological research. We also build a preliminary Odia parser using a machine learning approach. The accuracy of the parser is 86.6% Tokenization, 64.1% UPOS, 63.78% XPOS, 42.04% UAS and 21.34% LAS. Finally, the paper briefly discusses the linguistic analysis of the Odia UD treebank.
Hausa Visual Genome: A Dataset for Multi-Modal English to Hausa Machine Translation
May 06, 2022
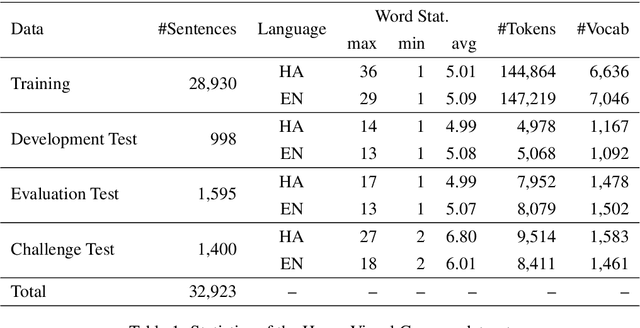
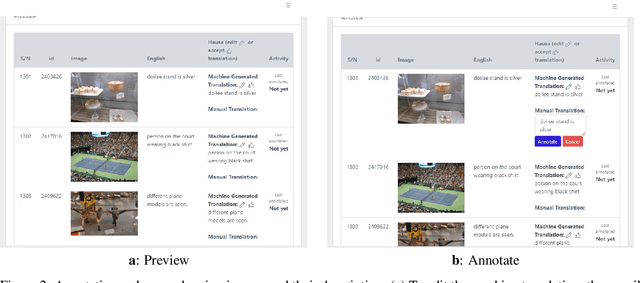

Multi-modal Machine Translation (MMT) enables the use of visual information to enhance the quality of translations. The visual information can serve as a valuable piece of context information to decrease the ambiguity of input sentences. Despite the increasing popularity of such a technique, good and sizeable datasets are scarce, limiting the full extent of their potential. Hausa, a Chadic language, is a member of the Afro-Asiatic language family. It is estimated that about 100 to 150 million people speak the language, with more than 80 million indigenous speakers. This is more than any of the other Chadic languages. Despite a large number of speakers, the Hausa language is considered low-resource in natural language processing (NLP). This is due to the absence of sufficient resources to implement most NLP tasks. While some datasets exist, they are either scarce, machine-generated, or in the religious domain. Therefore, there is a need to create training and evaluation data for implementing machine learning tasks and bridging the research gap in the language. This work presents the Hausa Visual Genome (HaVG), a dataset that contains the description of an image or a section within the image in Hausa and its equivalent in English. To prepare the dataset, we started by translating the English description of the images in the Hindi Visual Genome (HVG) into Hausa automatically. Afterward, the synthetic Hausa data was carefully post-edited considering the respective images. The dataset comprises 32,923 images and their descriptions that are divided into training, development, test, and challenge test set. The Hausa Visual Genome is the first dataset of its kind and can be used for Hausa-English machine translation, multi-modal research, and image description, among various other natural language processing and generation tasks.
Hindi Visual Genome: A Dataset for Multimodal English-to-Hindi Machine Translation
Jul 21, 2019
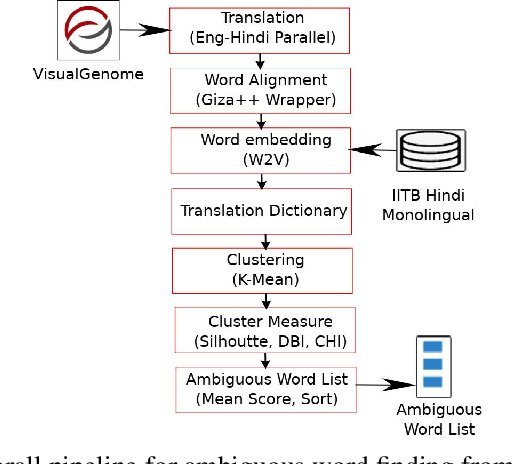
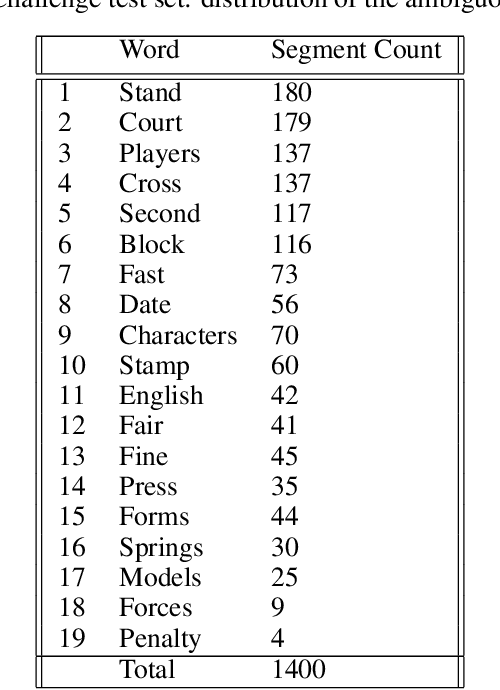

Visual Genome is a dataset connecting structured image information with English language. We present ``Hindi Visual Genome'', a multimodal dataset consisting of text and images suitable for English-Hindi multimodal machine translation task and multimodal research. We have selected short English segments (captions) from Visual Genome along with associated images and automatically translated them to Hindi with manual post-editing which took the associated images into account. We prepared a set of 31525 segments, accompanied by a challenge test set of 1400 segments. This challenge test set was created by searching for (particularly) ambiguous English words based on the embedding similarity and manually selecting those where the image helps to resolve the ambiguity. Our dataset is the first for multimodal English-Hindi machine translation, freely available for non-commercial research purposes. Our Hindi version of Visual Genome also allows to create Hindi image labelers or other practical tools. Hindi Visual Genome also serves in Workshop on Asian Translation (WAT) 2019 Multi-Modal Translation Task.