 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Image Colorization using U-Net with Skip Connections and Fusion Layer on Landscape Images
May 25, 2022
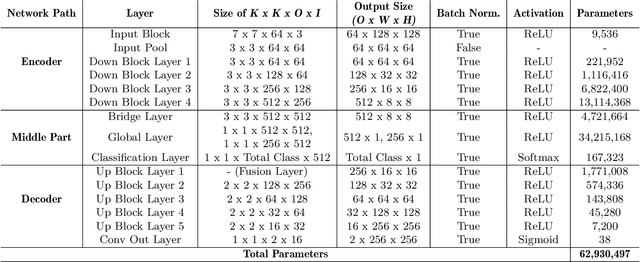
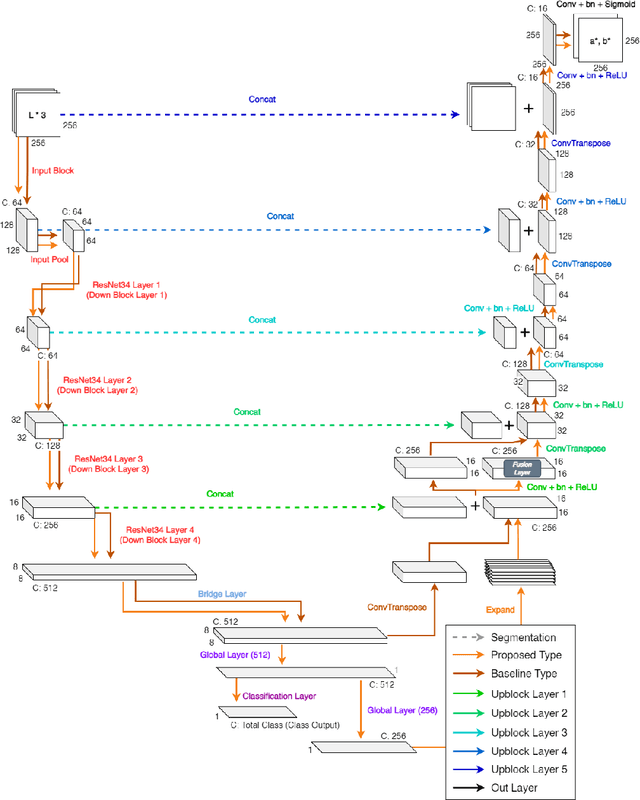
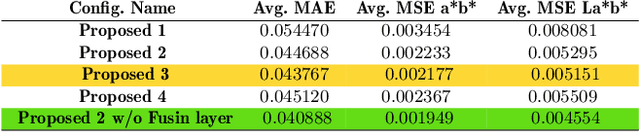

We present a novel technique to automatically colorize grayscale images that combine the U-Net model and Fusion Layer features. This approach allows the model to learn the colorization of images from pre-trained U-Net. Moreover, the Fusion layer is applied to merge local information results dependent on small image patches with global priors of an entire image on each class, forming visually more compelling colorization results. Finally, we validate our approach with a user study evaluation and compare it against state-of-the-art, resulting in improvements.
Encoding NetFlows for State-Machine Learning
Jul 08, 2022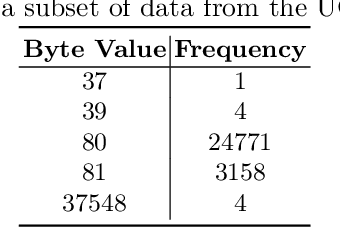
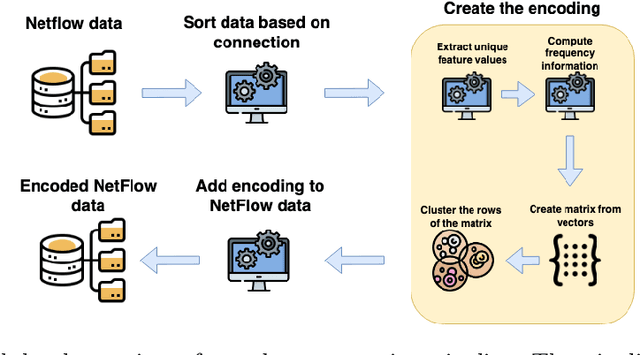
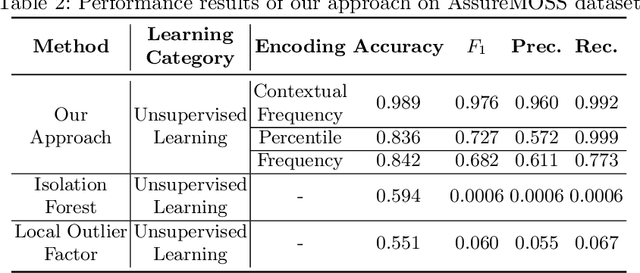
NetFlow data is a well-known network log format used by many network analysts and researchers. The advantages of using this format compared to pcap are that it contains fewer data, is less privacy intrusive, and is easier to collect and process. However, having less data does mean that this format might not be able to capture important network behaviour as all information is summarised into statistics. Much research aims to overcome this disadvantage through the use of machine learning, for instance, to detect attacks within a network. Many approaches can be used to pre-process the NetFlow data before it is used to train the machine learning algorithms. However, many of these approaches simply apply existing methods to the data, not considering the specific properties of network data. We argue that for data originating from software systems, such as NetFlow or software logs, similarities in frequency and contexts of feature values are more important than similarities in the value itself. In this work, we, therefore, propose an encoding algorithm that directly takes the frequency and the context of the feature values into account when the data is being processed. Different types of network behaviours can be clustered using this encoding, thus aiding the process of detecting anomalies within the network. From windows of these clusters obtained from monitoring a clean system, we learn state machine behavioural models for anomaly detection. These models are very well-suited to modelling the cyclic and repetitive patterns present in NetFlow data. We evaluate our encoding on a new dataset that we created for detecting problems in Kubernetes clusters and on two well-known public NetFlow datasets. The obtained performance results of the state machine models are comparable to existing works that use many more features and require both clean and infected data as training input.
Codified audio language modeling learns useful representations for music information retrieval
Jul 12, 2021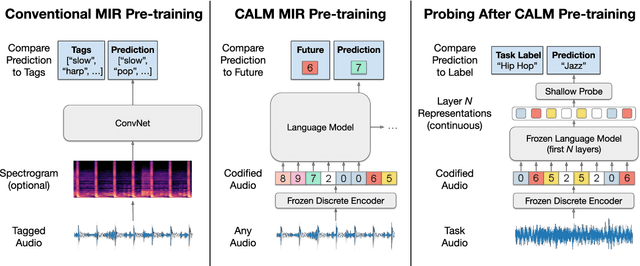
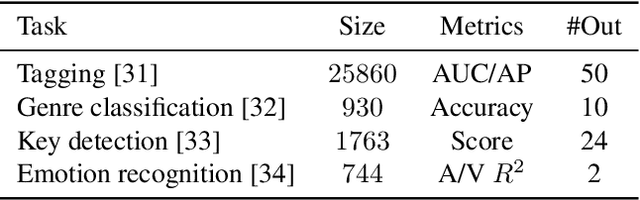
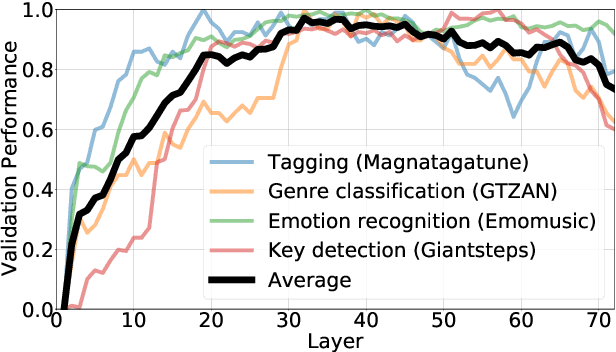

We demonstrate that language models pre-trained on codified (discretely-encoded) music audio learn representations that are useful for downstream MIR tasks. Specifically, we explore representations from Jukebox (Dhariwal et al. 2020): a music generation system containing a language model trained on codified audio from 1M songs. To determine if Jukebox's representations contain useful information for MIR, we use them as input features to train shallow models on several MIR tasks. Relative to representations from conventional MIR models which are pre-trained on tagging, we find that using representations from Jukebox as input features yields 30% stronger performance on average across four MIR tasks: tagging, genre classification, emotion recognition, and key detection. For key detection, we observe that representations from Jukebox are considerably stronger than those from models pre-trained on tagging, suggesting that pre-training via codified audio language modeling may address blind spots in conventional approaches. We interpret the strength of Jukebox's representations as evidence that modeling audio instead of tags provides richer representations for MIR.
TranSpeech: Speech-to-Speech Translation With Bilateral Perturbation
May 25, 2022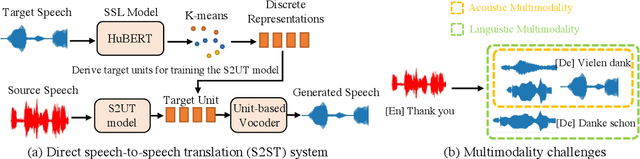
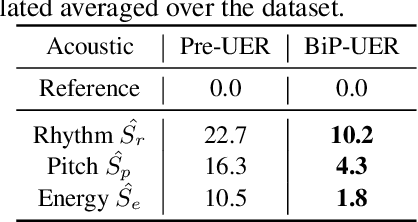
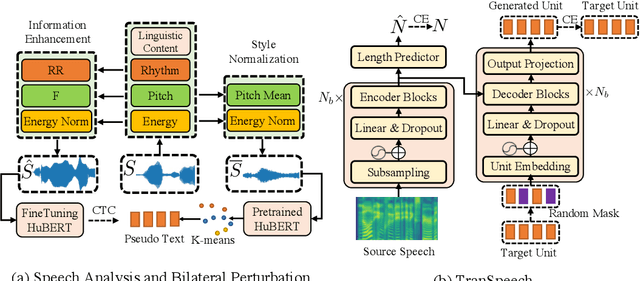
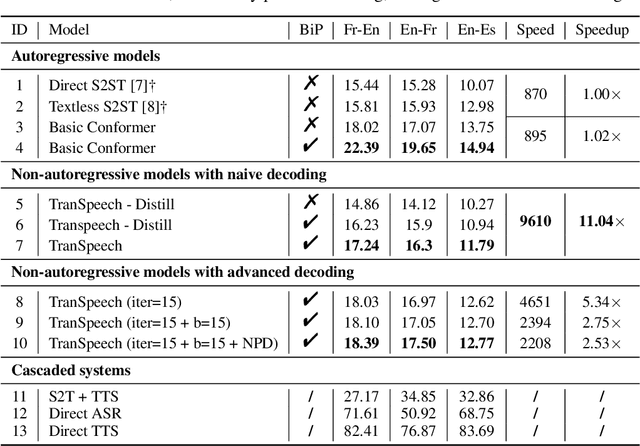
Direct speech-to-speech translation (S2ST) systems leverage recent progress in speech representation learning, where a sequence of discrete representations (units) derived in a self-supervised manner, are predicted from the model and passed to a vocoder for speech synthesis, still facing the following challenges: 1) Acoustic multimodality: the discrete units derived from speech with same content could be indeterministic due to the acoustic property (e.g., rhythm, pitch, and energy), which causes deterioration of translation accuracy; 2) high latency: current S2ST systems utilize autoregressive models which predict each unit conditioned on the sequence previously generated, failing to take full advantage of parallelism. In this work, we propose TranSpeech, a speech-to-speech translation model with bilateral perturbation. To alleviate the acoustic multimodal problem, we propose bilateral perturbation, which consists of the style normalization and information enhancement stages, to learn only the linguistic information from speech samples and generate more deterministic representations. With reduced multimodality, we step forward and become the first to establish a non-autoregressive S2ST technique, which repeatedly masks and predicts unit choices and produces high-accuracy results in just a few cycles. Experimental results on three language pairs demonstrate the state-of-the-art results by up to 2.5 BLEU points over the best publicly-available textless S2ST baseline. Moreover, TranSpeech shows a significant improvement in inference latency, enabling speedup up to 21.4x than autoregressive technique. Audio samples are available at \url{https://TranSpeech.github.io/}
Importance of Different Temporal Modulations of Speech: A Tale of Two Perspectives
Mar 31, 2022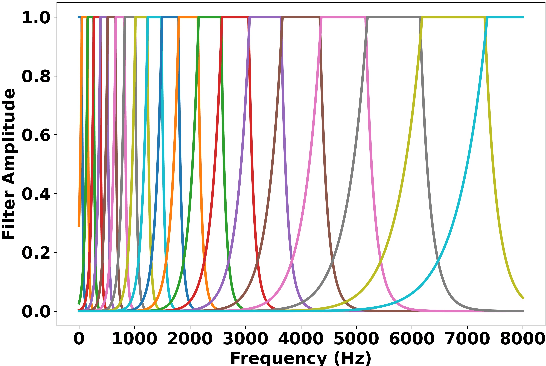

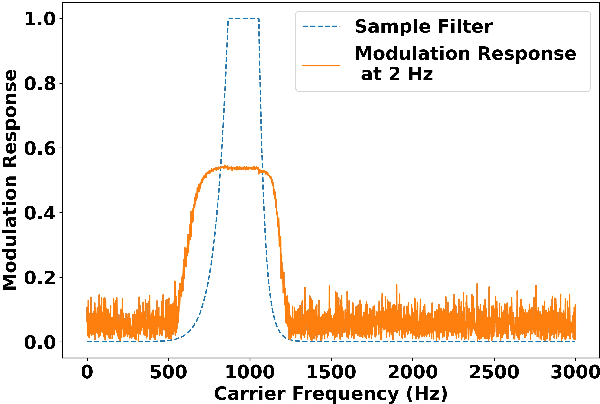
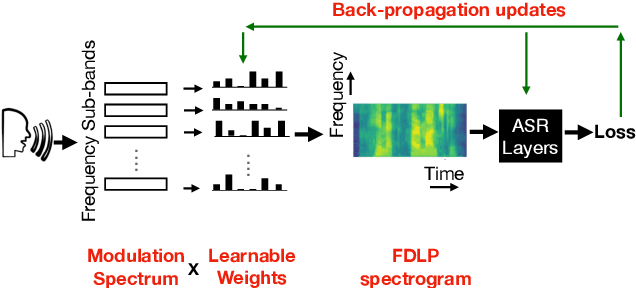
How important are different temporal speech modulations for speech recognition? We answer this question from two complementary perspectives. Firstly, we quantify the amount of phonetic information in the modulation spectrum of speech by computing the mutual information between temporal modulations with frame-wise phoneme labels. Looking from another perspective, we ask - which speech modulations does an Automatic Speech Recognition (ASR) system prefer for its operation. Data-driven weights are learnt over the modulation spectrum and optimized for an end-to-end ASR task. Both methods unanimously agree that speech information is mostly contained in slow modulation. Maximum mutual information occurs around 3-6 Hz which also happens to be the range of modulations most preferred by the ASR. In addition, we show that incorporation of this knowledge into ASRs significantly reduces its dependency on the amount of training data.
Collaboration-Aware Graph Convolutional Networks for Recommendation Systems
Jul 03, 2022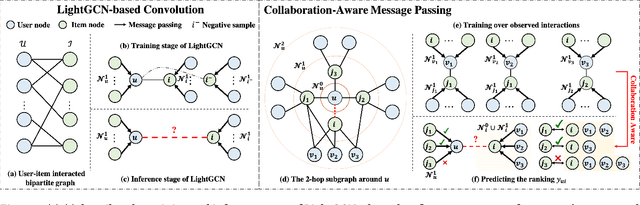
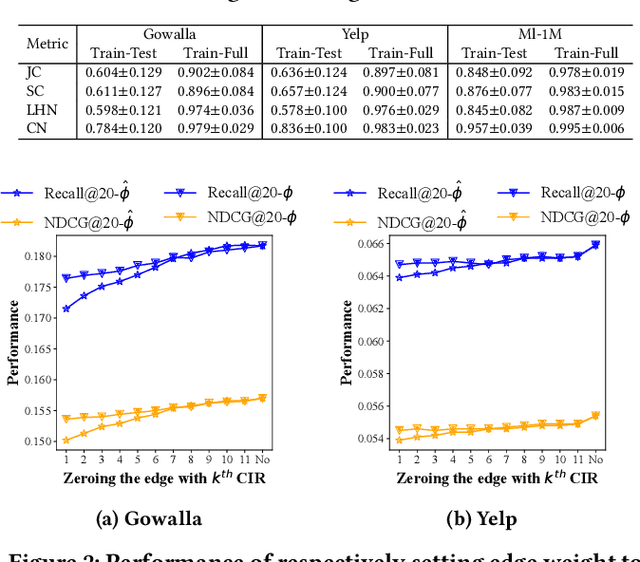
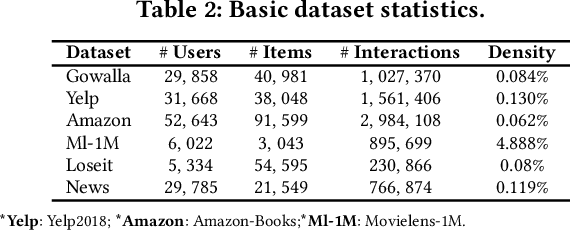
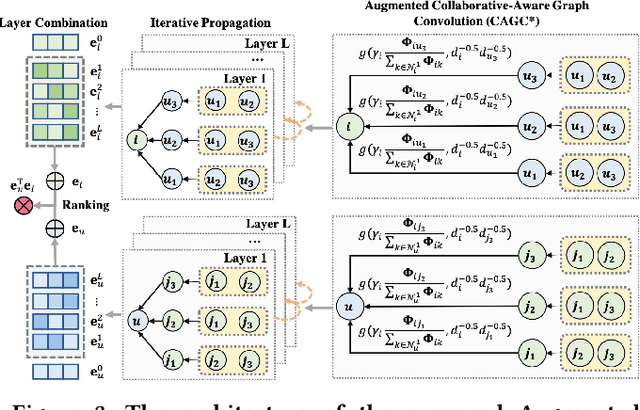
By virtue of the message-passing that implicitly injects collaborative effect into the embedding process, Graph Neural Networks (GNNs) have been successfully adopted in recommendation systems. Nevertheless, most of existing message-passing mechanisms in recommendation are directly inherited from GNNs without any recommendation-tailored modification. Although some efforts have been made towards simplifying GNNs to improve the performance/efficiency of recommendation, no study has comprehensively scrutinized how message-passing captures collaborative effect and whether the captured effect would benefit the prediction of user preferences over items. Therefore, in this work we aim to demystify the collaborative effect captured by message-passing in GNNs and develop new insights towards customizing message-passing for recommendation. First, we theoretically analyze how message-passing captures and leverages the collaborative effect in predicting user preferences. Then, to determine whether the captured collaborative effect would benefit the prediction of user preferences, we propose a recommendation-oriented topological metric, Common Interacted Ratio (CIR), which measures the level of interaction between a specific neighbor of a node with the rest of its neighborhood set. Inspired by our theoretical and empirical analysis, we propose a recommendation-tailored GNN, Augmented Collaboration-Aware Graph Convolutional Network (CAGCN*), that extends upon the LightGCN framework and is able to selectively pass information of neighbors based on their CIR via the Collaboration-Aware Graph Convolution. Experimental results on six benchmark datasets show that CAGCN* outperforms the most representative GNN-based recommendation model, LightGCN, by 9% in Recall@20 and also achieves more than 79% speedup. Our code is publicly available at https://github.com/YuWVandy/CAGCN.
Open vs Closed-ended questions in attitudinal surveys -- comparing, combining, and interpreting using natural language processing
May 03, 2022
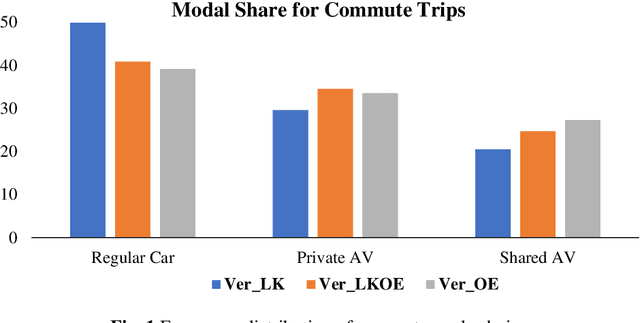
To improve the traveling experience, researchers have been analyzing the role of attitudes in travel behavior modeling. Although most researchers use closed-ended surveys, the appropriate method to measure attitudes is debatable. Topic Modeling could significantly reduce the time to extract information from open-ended responses and eliminate subjective bias, thereby alleviating analyst concerns. Our research uses Topic Modeling to extract information from open-ended questions and compare its performance with closed-ended responses. Furthermore, some respondents might prefer answering questions using their preferred questionnaire type. So, we propose a modeling framework that allows respondents to use their preferred questionnaire type to answer the survey and enable analysts to use the modeling frameworks of their choice to predict behavior. We demonstrate this using a dataset collected from the USA that measures the intention to use Autonomous Vehicles for commute trips. Respondents were presented with alternative questionnaire versions (open- and closed- ended). Since our objective was also to compare the performance of alternative questionnaire versions, the survey was designed to eliminate influences resulting from statements, behavioral framework, and the choice experiment. Results indicate the suitability of using Topic Modeling to extract information from open-ended responses; however, the models estimated using the closed-ended questions perform better compared to them. Besides, the proposed model performs better compared to the models used currently. Furthermore, our proposed framework will allow respondents to choose the questionnaire type to answer, which could be particularly beneficial to them when using voice-based surveys.
Self-Constrained Inference Optimization on Structural Groups for Human Pose Estimation
Jul 06, 2022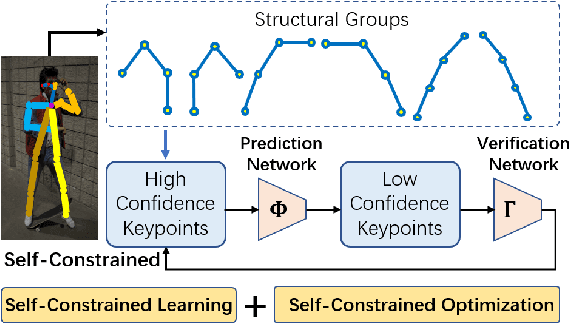
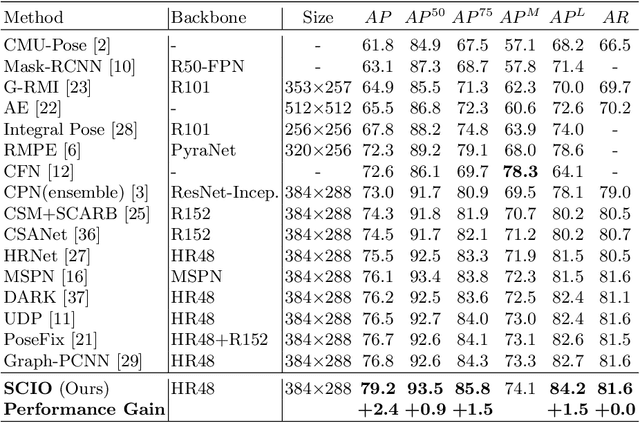
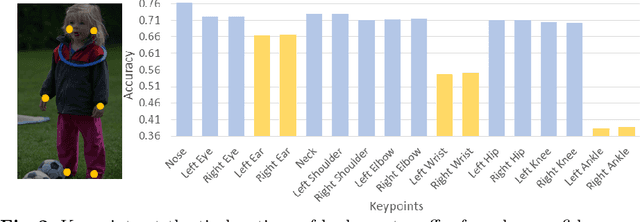
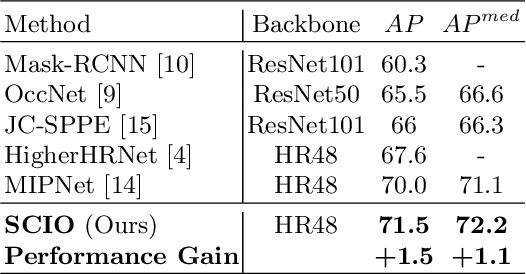
We observe that human poses exhibit strong group-wise structural correlation and spatial coupling between keypoints due to the biological constraints of different body parts. This group-wise structural correlation can be explored to improve the accuracy and robustness of human pose estimation. In this work, we develop a self-constrained prediction-verification network to characterize and learn the structural correlation between keypoints during training. During the inference stage, the feedback information from the verification network allows us to perform further optimization of pose prediction, which significantly improves the performance of human pose estimation. Specifically, we partition the keypoints into groups according to the biological structure of human body. Within each group, the keypoints are further partitioned into two subsets, high-confidence base keypoints and low-confidence terminal keypoints. We develop a self-constrained prediction-verification network to perform forward and backward predictions between these keypoint subsets. One fundamental challenge in pose estimation, as well as in generic prediction tasks, is that there is no mechanism for us to verify if the obtained pose estimation or prediction results are accurate or not, since the ground truth is not available. Once successfully learned, the verification network serves as an accuracy verification module for the forward pose prediction. During the inference stage, it can be used to guide the local optimization of the pose estimation results of low-confidence keypoints with the self-constrained loss on high-confidence keypoints as the objective function. Our extensive experimental results on benchmark MS COCO and CrowdPose datasets demonstrate that the proposed method can significantly improve the pose estimation results.
Hyperspectral image reconstruction for spectral camera based on ghost imaging via sparsity constraints using V-DUnet
Jun 28, 2022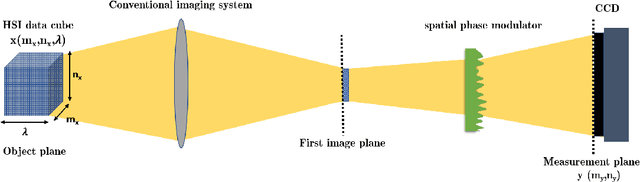
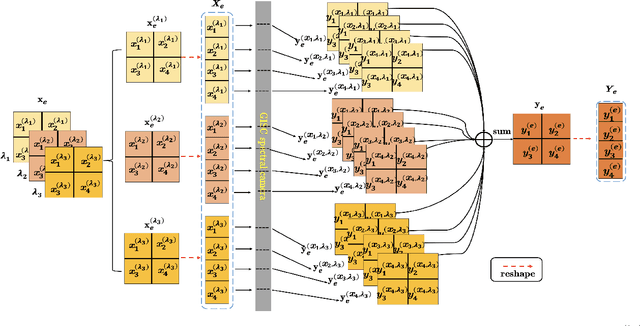
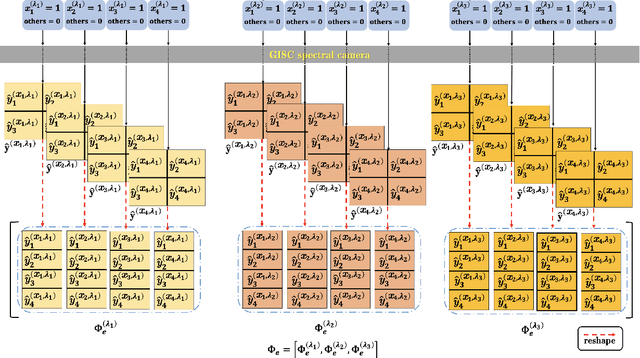
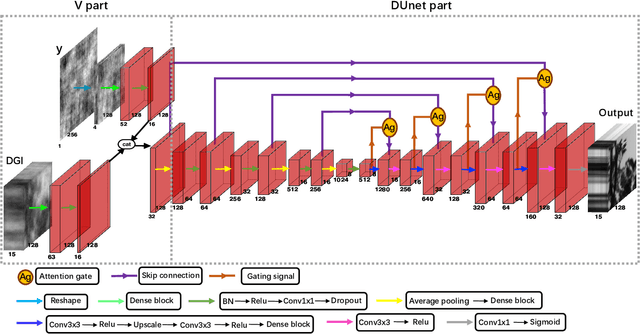
Spectral camera based on ghost imaging via sparsity constraints (GISC spectral camera) obtains three-dimensional (3D) hyperspectral information with two-dimensional (2D) compressive measurements in a single shot, which has attracted much attention in recent years. However, its imaging quality and real-time performance of reconstruction still need to be further improved. Recently, deep learning has shown great potential in improving the reconstruction quality and reconstruction speed for computational imaging. When applying deep learning into GISC spectral camera, there are several challenges need to be solved: 1) how to deal with the large amount of 3D hyperspectral data, 2) how to reduce the influence caused by the uncertainty of the random reference measurements, 3) how to improve the reconstructed image quality as far as possible. In this paper, we present an end-to-end V-DUnet for the reconstruction of 3D hyperspectral data in GISC spectral camera. To reduce the influence caused by the uncertainty of the measurement matrix and enhance the reconstructed image quality, both differential ghost imaging results and the detected measurements are sent into the network's inputs. Compared with compressive sensing algorithm, such as PICHCS and TwIST, it not only significantly improves the imaging quality with high noise immunity, but also speeds up the reconstruction time by more than two orders of magnitude.
Distilling Inter-Class Distance for Semantic Segmentation
May 07, 2022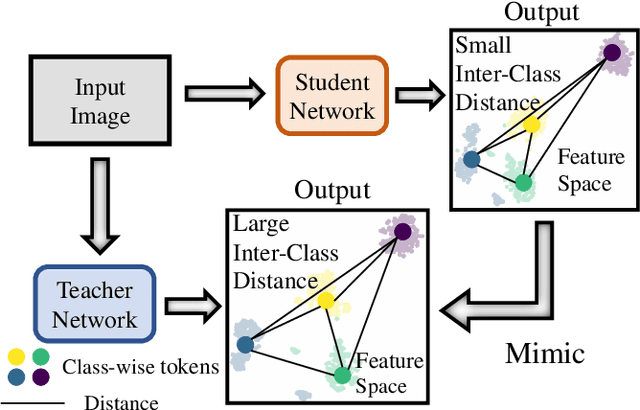
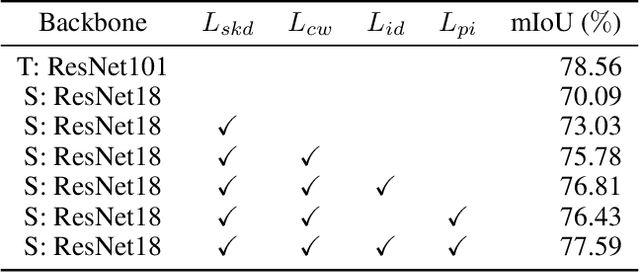
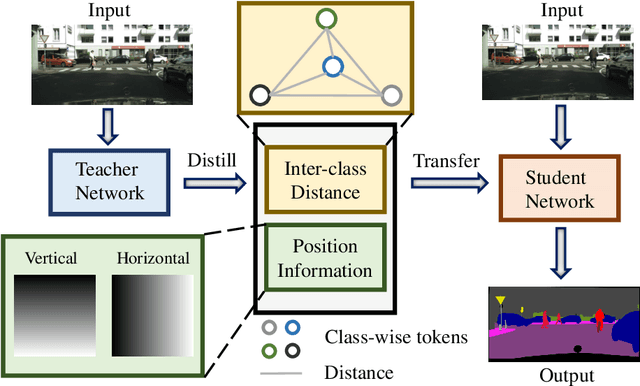
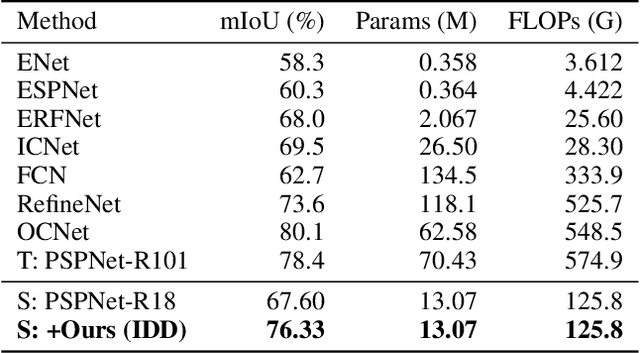
Knowledge distillation is widely adopted in semantic segmentation to reduce the computation cost.The previous knowledge distillation methods for semantic segmentation focus on pixel-wise feature alignment and intra-class feature variation distillation, neglecting to transfer the knowledge of the inter-class distance in the feature space, which is important for semantic segmentation. To address this issue, we propose an Inter-class Distance Distillation (IDD) method to transfer the inter-class distance in the feature space from the teacher network to the student network. Furthermore, semantic segmentation is a position-dependent task,thus we exploit a position information distillation module to help the student network encode more position information. Extensive experiments on three popular datasets: Cityscapes, Pascal VOC and ADE20K show that our method is helpful to improve the accuracy of semantic segmentation models and achieves the state-of-the-art performance. E.g. it boosts the benchmark model("PSPNet+ResNet18") by 7.50% in accuracy on the Cityscapes dataset.