 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Toward an ImageNet Library of Functions for Global Optimization Benchmarking
Jun 27, 2022
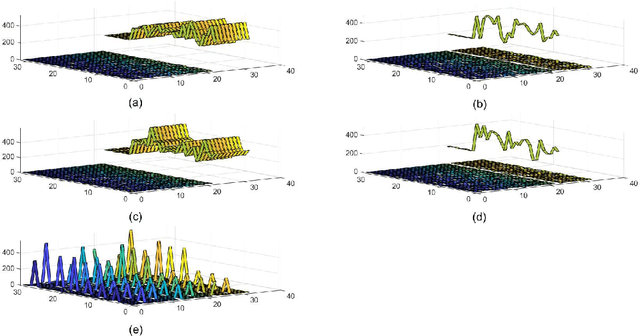
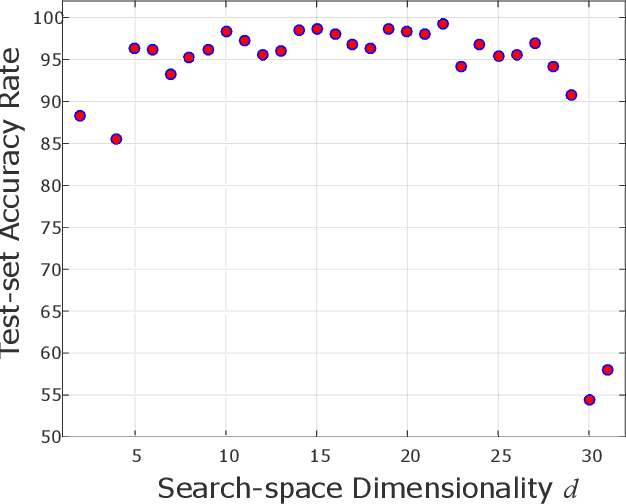
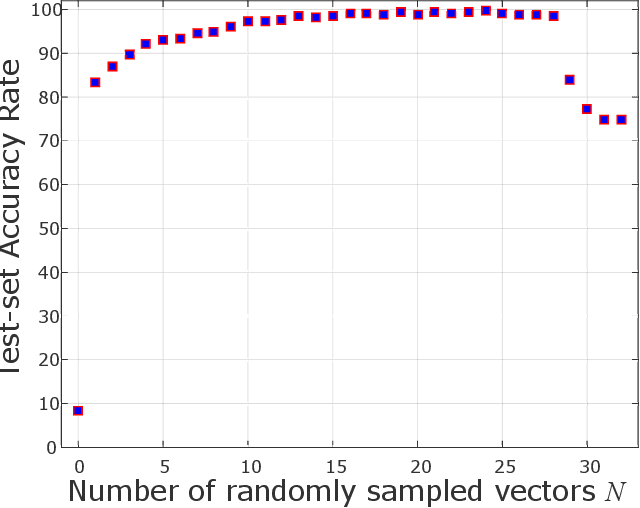
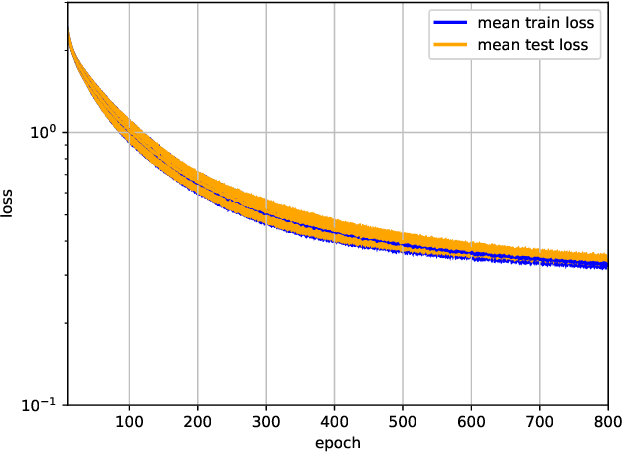
Knowledge of search-landscape features of BlackBox Optimization (BBO) problems offers valuable information in light of the Algorithm Selection and/or Configuration problems. Exploratory Landscape Analysis (ELA) models have gained success in identifying predefined human-derived features and in facilitating portfolio selectors to address those challenges. Unlike ELA approaches, the current study proposes to transform the identification problem into an image recognition problem, with a potential to detect conception-free, machine-driven landscape features. To this end, we introduce the notion of Landscape Images, which enables us to generate imagery instances per a benchmark function, and then target the classification challenge over a diverse generalized dataset of functions. We address it as a supervised multi-class image recognition problem and apply basic artificial neural network models to solve it. The efficacy of our approach is numerically validated on the noise free BBOB and IOHprofiler benchmarking suites. This evident successful learning is another step toward automated feature extraction and local structure deduction of BBO problems. By using this definition of landscape images, and by capitalizing on existing capabilities of image recognition algorithms, we foresee the construction of an ImageNet-like library of functions for training generalized detectors that rely on machine-driven features.
Language model compression with weighted low-rank factorization
Jun 30, 2022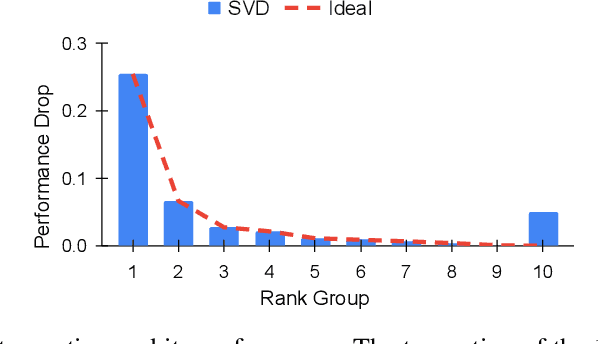
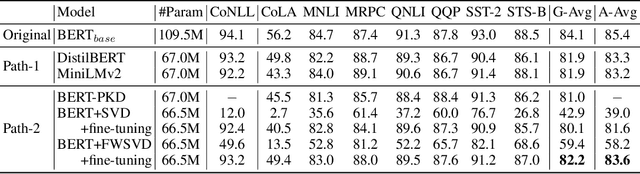


Factorizing a large matrix into small matrices is a popular strategy for model compression. Singular value decomposition (SVD) plays a vital role in this compression strategy, approximating a learned matrix with fewer parameters. However, SVD minimizes the squared error toward reconstructing the original matrix without gauging the importance of the parameters, potentially giving a larger reconstruction error for those who affect the task accuracy more. In other words, the optimization objective of SVD is not aligned with the trained model's task accuracy. We analyze this previously unexplored problem, make observations, and address it by introducing Fisher information to weigh the importance of parameters affecting the model prediction. This idea leads to our method: Fisher-Weighted SVD (FWSVD). Although the factorized matrices from our approach do not result in smaller reconstruction errors, we find that our resulting task accuracy is much closer to the original model's performance. We perform analysis with the transformer-based language models, showing our weighted SVD largely alleviates the mismatched optimization objectives and can maintain model performance with a higher compression rate. Our method can directly compress a task-specific model while achieving better performance than other compact model strategies requiring expensive model pre-training. Moreover, the evaluation of compressing an already compact model shows our method can further reduce 9% to 30% parameters with an insignificant impact on task accuracy.
Integrated Sensing and Communication with Reconfigurable Intelligent Surfaces: Opportunities, Applications, and Future Directions
Jun 17, 2022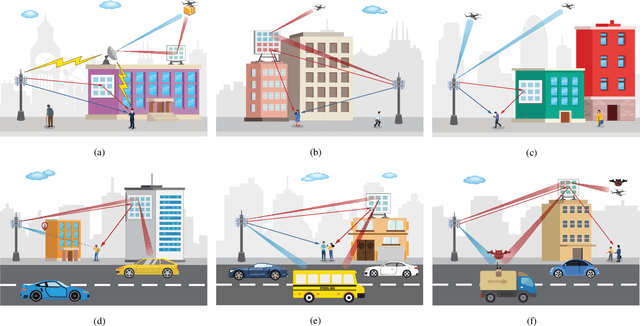
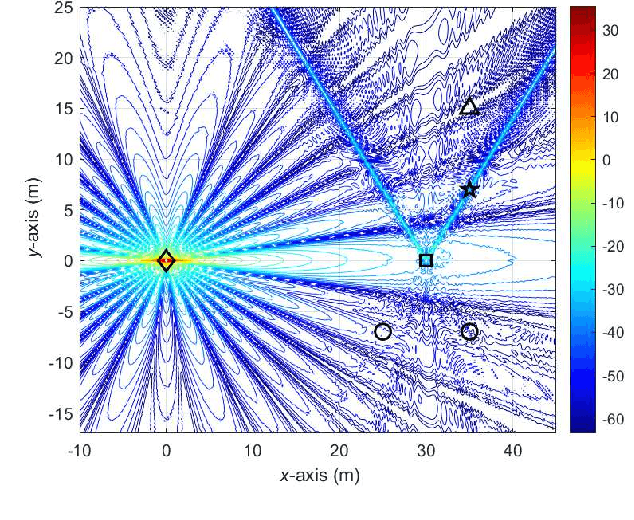
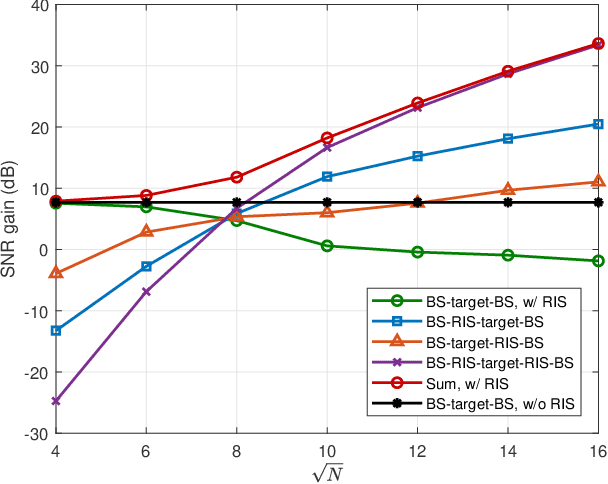
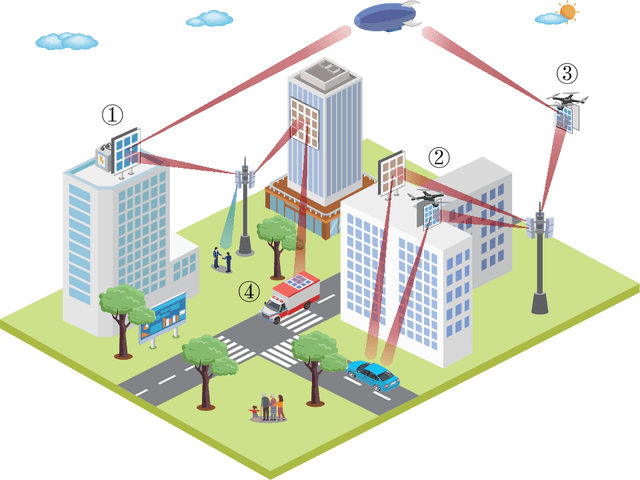
Integrated sensing and communication (ISAC) is emerging as a key enabler to address the growing spectrum congestion problem and satisfy increasing demands for ubiquitous sensing and communication. By sharing various resources and information, ISAC achieves much higher spectral, energy, hardware, and economic efficiencies. Concurrently, reconfigurable intelligent surface (RIS) technology has been deemed as a promising approach due to its capability of intelligently manipulating the wireless propagation environment in an energy and hardware efficient manner. In this article, we analyze the potential of deploying RIS to improve communication and sensing performance in ISAC systems. We first describe the fundamentals of RIS and its applications in traditional communication and sensing systems, then introduce the principles of ISAC and overview existing explorations on RIS-assisted ISAC, followed by one case study to verify the advantages of deploying RIS in ISAC systems. Finally, open challenges and research directions are discussed to stimulate this line of research and pave the way for practical applications.
Zeroth-Order Topological Insights into Iterative Magnitude Pruning
Jun 17, 2022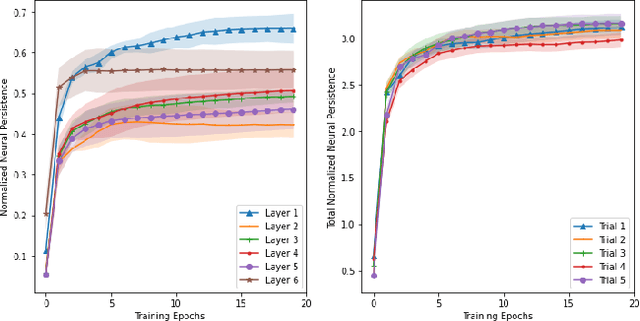
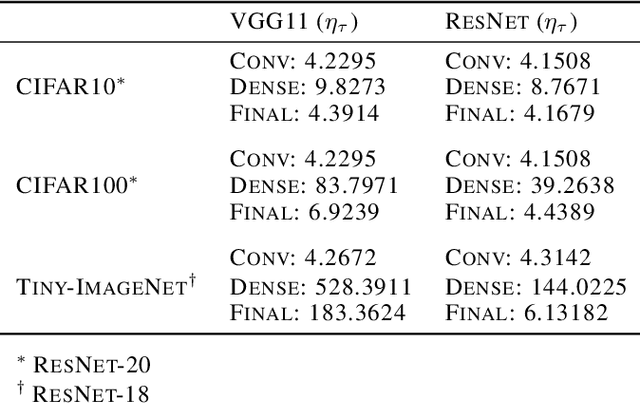
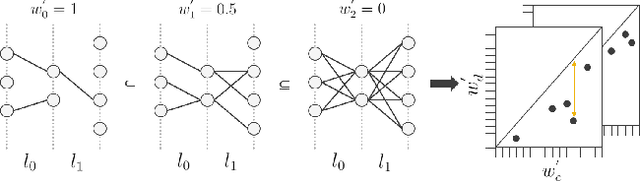
Modern-day neural networks are famously large, yet also highly redundant and compressible; there exist numerous pruning strategies in the deep learning literature that yield over 90% sparser sub-networks of fully-trained, dense architectures while still maintaining their original accuracies. Amongst these many methods though -- thanks to its conceptual simplicity, ease of implementation, and efficacy -- Iterative Magnitude Pruning (IMP) dominates in practice and is the de facto baseline to beat in the pruning community. However, theoretical explanations as to why a simplistic method such as IMP works at all are few and limited. In this work, we leverage the notion of persistent homology to gain insights into the workings of IMP and show that it inherently encourages retention of those weights which preserve topological information in a trained network. Subsequently, we also provide bounds on how much different networks can be pruned while perfectly preserving their zeroth order topological features, and present a modified version of IMP to do the same.
The Harvard USPTO Patent Dataset: A Large-Scale, Well-Structured, and Multi-Purpose Corpus of Patent Applications
Jul 08, 2022


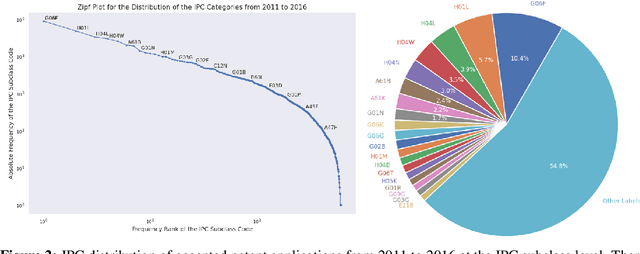
Innovation is a major driver of economic and social development, and information about many kinds of innovation is embedded in semi-structured data from patents and patent applications. Although the impact and novelty of innovations expressed in patent data are difficult to measure through traditional means, ML offers a promising set of techniques for evaluating novelty, summarizing contributions, and embedding semantics. In this paper, we introduce the Harvard USPTO Patent Dataset (HUPD), a large-scale, well-structured, and multi-purpose corpus of English-language patent applications filed to the United States Patent and Trademark Office (USPTO) between 2004 and 2018. With more than 4.5 million patent documents, HUPD is two to three times larger than comparable corpora. Unlike previously proposed patent datasets in NLP, HUPD contains the inventor-submitted versions of patent applications--not the final versions of granted patents--thereby allowing us to study patentability at the time of filing using NLP methods for the first time. It is also novel in its inclusion of rich structured metadata alongside the text of patent filings: By providing each application's metadata along with all of its text fields, the dataset enables researchers to perform new sets of NLP tasks that leverage variation in structured covariates. As a case study on the types of research HUPD makes possible, we introduce a new task to the NLP community--namely, binary classification of patent decisions. We additionally show the structured metadata provided in the dataset enables us to conduct explicit studies of concept shifts for this task. Finally, we demonstrate how HUPD can be used for three additional tasks: multi-class classification of patent subject areas, language modeling, and summarization.
A Numerical Reasoning Question Answering System with Fine-grained Retriever and the Ensemble of Multiple Generators for FinQA
Jun 17, 2022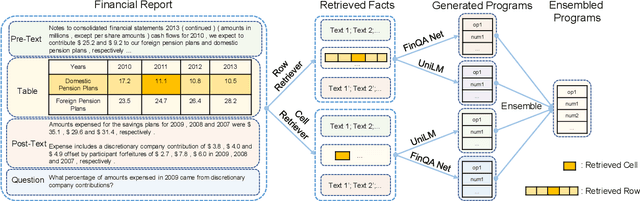
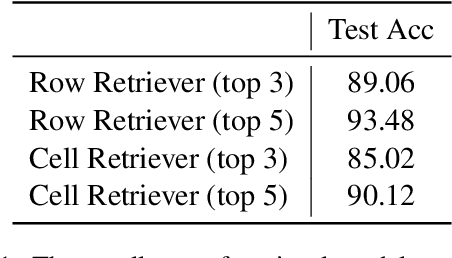
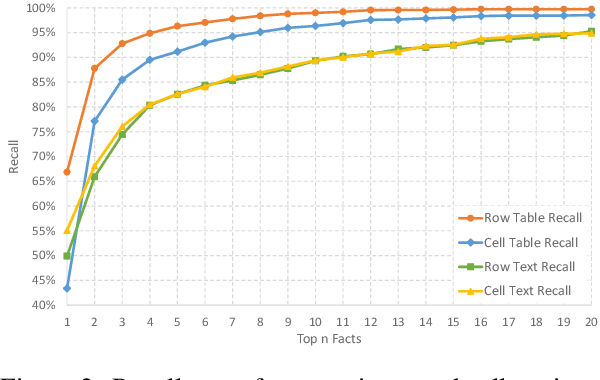
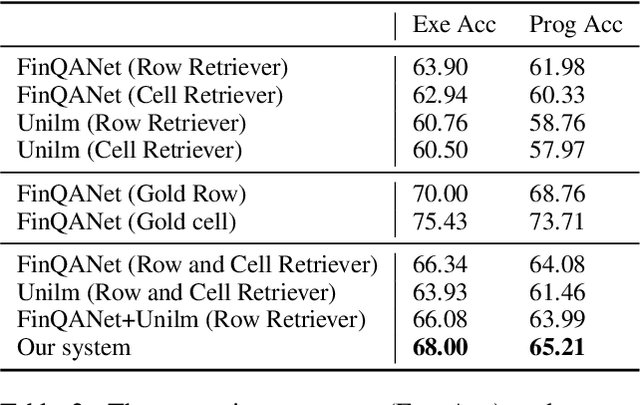
The numerical reasoning in the financial domain -- performing quantitative analysis and summarizing the information from financial reports -- can greatly increase business efficiency and reduce costs of billions of dollars. Here, we propose a numerical reasoning question answering system to answer numerical reasoning questions among financial text and table data sources, consisting of a retriever module, a generator module, and an ensemble module. Specifically, in the retriever module, in addition to retrieving the whole row data, we innovatively design a cell retriever that retrieves the gold cells to avoid bringing unrelated and similar cells in the same row to the inputs of the generator module. In the generator module, we utilize multiple generators to produce programs, which are operation steps to answer the question. Finally, in the ensemble module, we integrate multiple programs to choose the best program as the output of our system. In the final private test set in FinQA Competition, our system obtains 69.79 execution accuracy.
SynWMD: Syntax-aware Word Mover's Distance for Sentence Similarity Evaluation
Jun 20, 2022
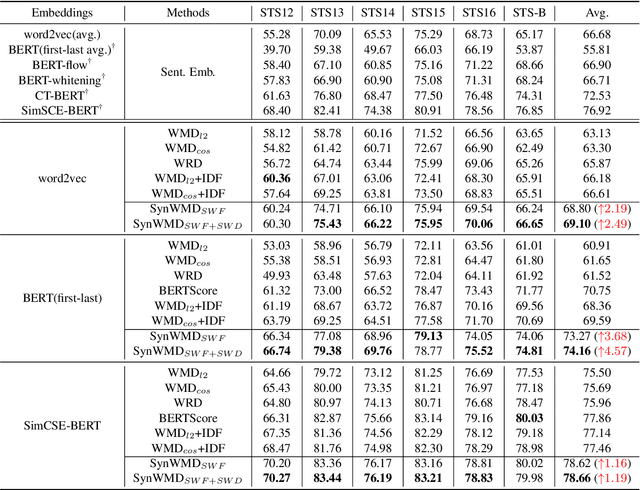
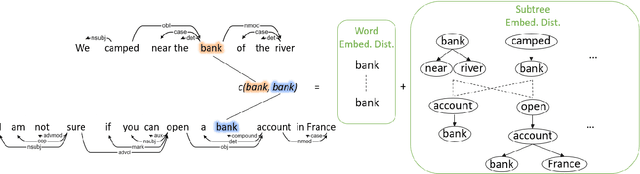
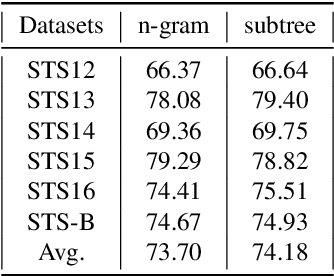
Word Mover's Distance (WMD) computes the distance between words and models text similarity with the moving cost between words in two text sequences. Yet, it does not offer good performance in sentence similarity evaluation since it does not incorporate word importance and fails to take inherent contextual and structural information in a sentence into account. An improved WMD method using the syntactic parse tree, called Syntax-aware Word Mover's Distance (SynWMD), is proposed to address these two shortcomings in this work. First, a weighted graph is built upon the word co-occurrence statistics extracted from the syntactic parse trees of sentences. The importance of each word is inferred from graph connectivities. Second, the local syntactic parsing structure of words is considered in computing the distance between words. To demonstrate the effectiveness of the proposed SynWMD, we conduct experiments on 6 textual semantic similarity (STS) datasets and 4 sentence classification datasets. Experimental results show that SynWMD achieves state-of-the-art performance on STS tasks. It also outperforms other WMD-based methods on sentence classification tasks.
Variational Autoencoder Assisted Neural Network Likelihood RSRP Prediction Model
Jun 27, 2022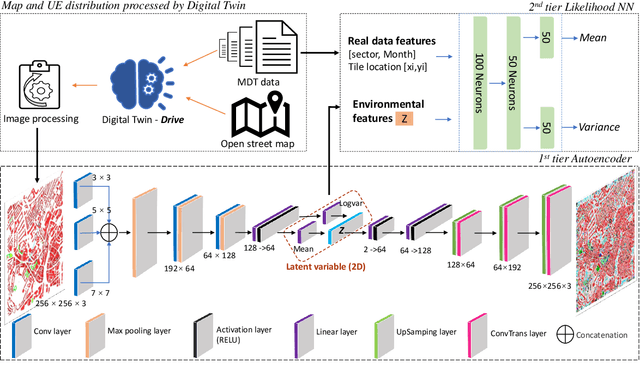
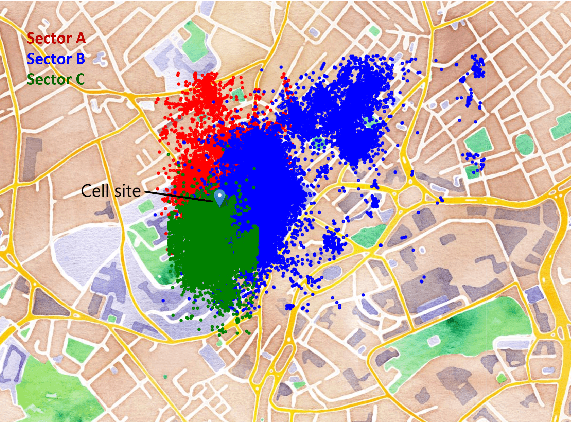
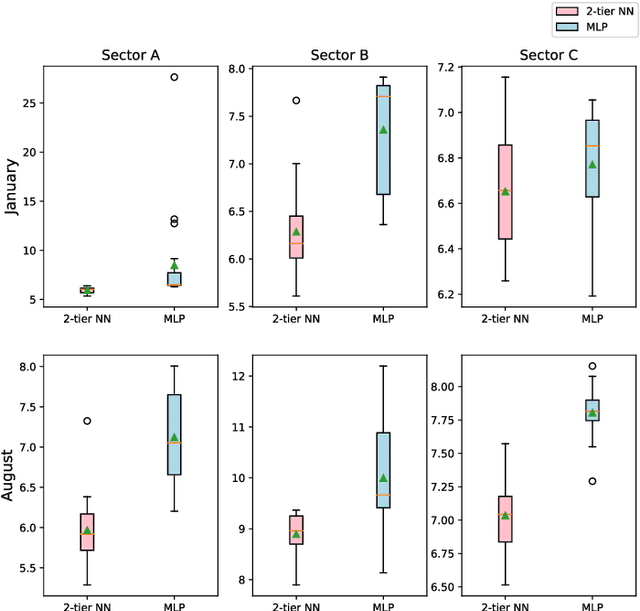
Measuring customer experience on mobile data is of utmost importance for global mobile operators. The reference signal received power (RSRP) is one of the important indicators for current mobile network management, evaluation and monitoring. Radio data gathered through the minimization of drive test (MDT), a 3GPP standard technique, is commonly used for radio network analysis. Collecting MDT data in different geographical areas is inefficient and constrained by the terrain conditions and user presence, hence is not an adequate technique for dynamic radio environments. In this paper, we study a generative model for RSRP prediction, exploiting MDT data and a digital twin (DT), and propose a data-driven, two-tier neural network (NN) model. In the first tier, environmental information related to user equipment (UE), base stations (BS) and network key performance indicators (KPI) are extracted through a variational autoencoder (VAE). The second tier is designed as a likelihood model. Here, the environmental features and real MDT data features are adopted, formulating an integrated training process. On validation, our proposed model that uses real-world data demonstrates an accuracy improvement of about 20% or more compared with the empirical model and about 10% when compared with a fully connected prediction network.
A Comprehensive 3-D Framework for Automatic Quantification of Late Gadolinium Enhanced Cardiac Magnetic Resonance Images
May 21, 2022
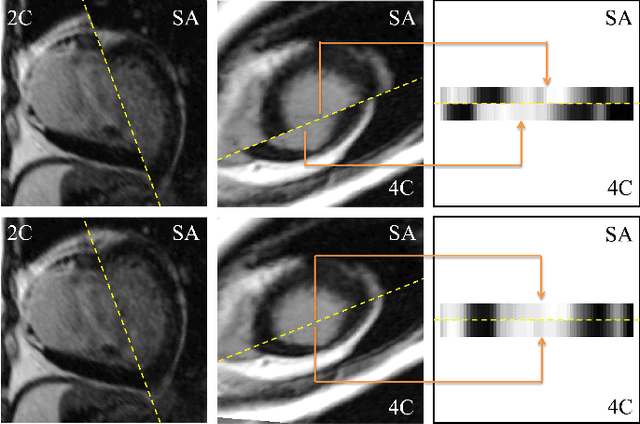
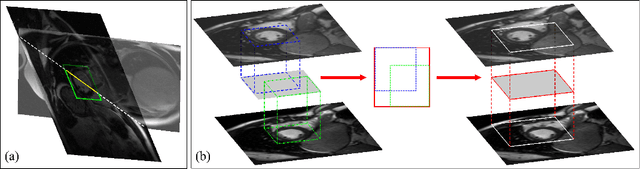
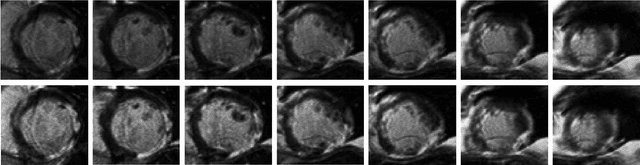
Late gadolinium enhanced (LGE) cardiac magnetic resonance (CMR) can directly visualize nonviable myocardium with hyperenhanced intensities with respect to normal myocardium. For heart attack patients, it is crucial to facilitate the decision of appropriate therapy by analyzing and quantifying their LGE CMR images. To achieve accurate quantification, LGE CMR images need to be processed in two steps: segmentation of the myocardium followed by classification of infarcts within the segmented myocardium. However, automatic segmentation is difficult usually due to the intensity heterogeneity of the myocardium and intensity similarity between the infarcts and blood pool. Besides, the slices of an LGE CMR dataset often suffer from spatial and intensity distortions, causing further difficulties in segmentation and classification. In this paper, we present a comprehensive 3-D framework for automatic quantification of LGE CMR images. In this framework, myocardium is segmented with a novel method that deforms coupled endocardial and epicardial meshes and combines information in both short- and long-axis slices, while infarcts are classified with a graph-cut algorithm incorporating intensity and spatial information. Moreover, both spatial and intensity distortions are effectively corrected with specially designed countermeasures. Experiments with 20 sets of real patient data show visually good segmentation and classification results that are quantitatively in strong agreement with those manually obtained by experts.
Adaptive Decoding Mechanisms for UAV-enabled Double-Uplink Coordinated NOMA
Jun 27, 2022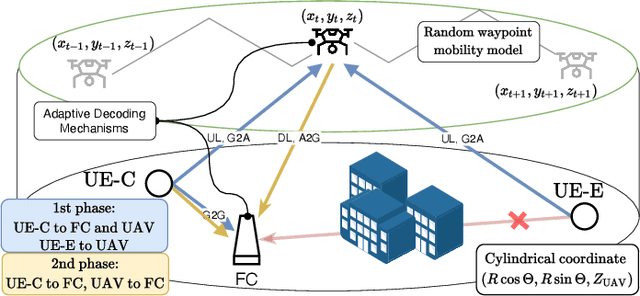
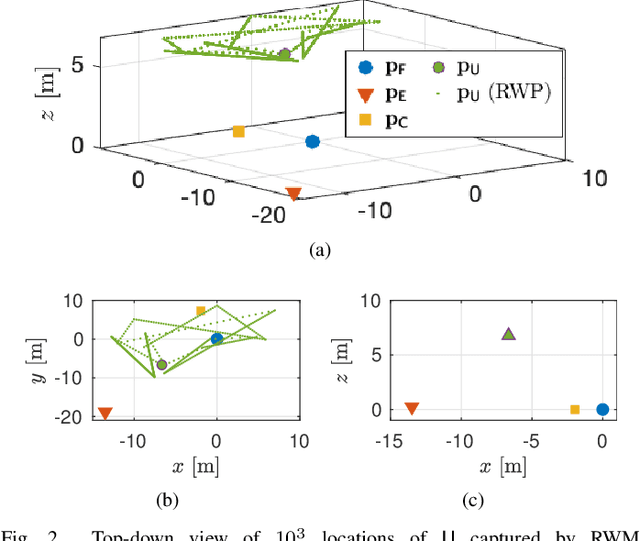
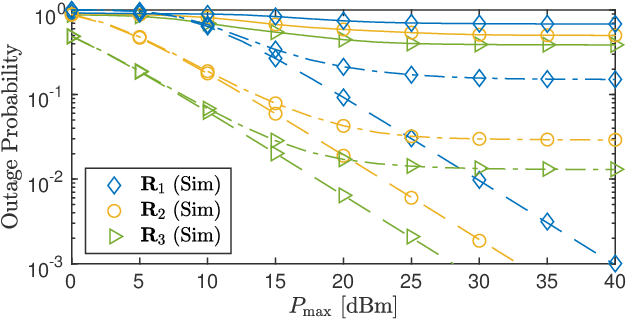
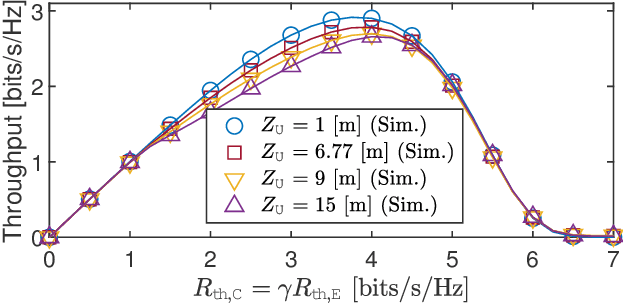
In this paper, we propose a novel adaptive decoding mechanism (ADM) for the unmanned aerial vehicle (UAV)-enabled uplink (UL) non-orthogonal multiple access (NOMA) communications. Specifically, considering a harsh UAV environment where ground-to-ground links are regularly unavailable, the proposed ADM overcomes the challenging problem of conventional UL-NOMA systems whose performance is sensitive to the transmitter's statistical channel state information and the receiver's decoding order. To evaluate the performance of the ADM, we derive closed-form expressions for the system outage probability (OP) and throughput. In the performance analysis, we provide novel expressions for practical air-to-ground and ground-to-air channels while taking into account the practical implementation of imperfect successive interference cancellation (SIC) in UL-NOMA. These results have not been previously reported in the technical literature. Moreover, the obtained expression can be adopted to characterize the OP of various systems under a Mixture of Gamma (MG) distribution-based fading channels. Next, we propose a sub-optimal Gradient Descent-based algorithm to obtain the power allocation coefficients that result in maximum throughput with respect to each location on UAV's trajectory, which follows a random waypoint mobility model for UAVs. Numerical solutions show that the ADM significantly improves the performance of UAV-enabled UL-NOMA, particularly in mobile environments.