 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AI Enlightens Wireless Communication: A Transformer Backbone for CSI Feedback
Jun 16, 2022
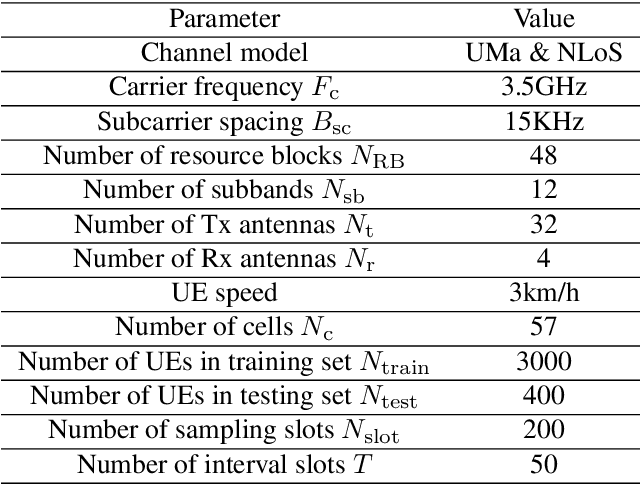

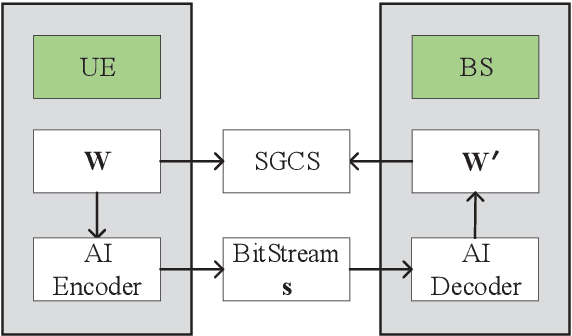
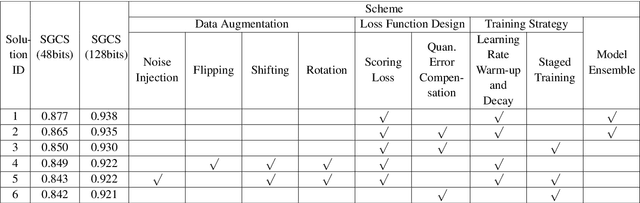
This paper is based on the background of the 2nd Wireless Communication Artificial Intelligence (AI) Competition (WAIC) which is hosted by IMT-2020(5G) Promotion Group 5G+AIWork Group, where the framework of the eigenvector-based channel state information (CSI) feedback problem is firstly provided. Then a basic Transformer backbone for CSI feedback referred to EVCsiNet-T is proposed. Moreover, a series of potential enhancements for deep learning based (DL-based) CSI feedback including i) data augmentation, ii) loss function design, iii) training strategy, and iv) model ensemble are introduced. The experimental results involving the comparison between EVCsiNet-T and traditional codebook methods over different channels are further provided, which show the advanced performance and a promising prospect of Transformer on DL-based CSI feedback problem.
AvatarCap: Animatable Avatar Conditioned Monocular Human Volumetric Capture
Jul 05, 2022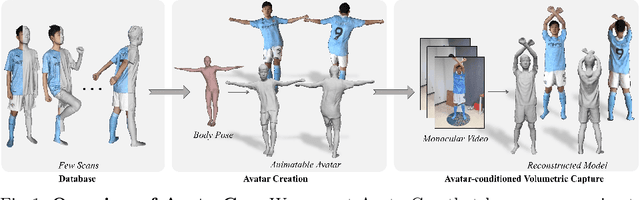

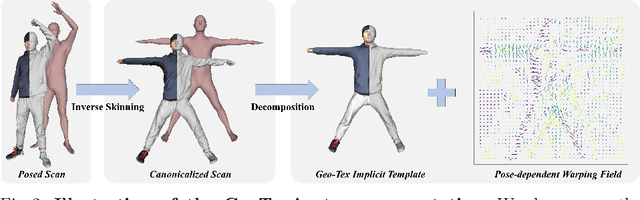

To address the ill-posed problem caused by partial observations in monocular human volumetric capture, we present AvatarCap, a novel framework that introduces animatable avatars into the capture pipeline for high-fidelity reconstruction in both visible and invisible regions. Our method firstly creates an animatable avatar for the subject from a small number (~20) of 3D scans as a prior. Then given a monocular RGB video of this subject, our method integrates information from both the image observation and the avatar prior, and accordingly recon-structs high-fidelity 3D textured models with dynamic details regardless of the visibility. To learn an effective avatar for volumetric capture from only few samples, we propose GeoTexAvatar, which leverages both geometry and texture supervisions to constrain the pose-dependent dynamics in a decomposed implicit manner. An avatar-conditioned volumetric capture method that involves a canonical normal fusion and a reconstruction network is further proposed to integrate both image observations and avatar dynamics for high-fidelity reconstruction in both observed and invisible regions. Overall, our method enables monocular human volumetric capture with detailed and pose-dependent dynamics, and the experiments show that our method outperforms state of the art. Code is available at https://github.com/lizhe00/AvatarCap.
Individually Conditional Individual Mutual Information Bound on Generalization Error
Dec 17, 2020
We propose a new information-theoretic bound on generalization error based on a combination of the error decomposition technique of Bu et al. and the conditional mutual information (CMI) construction of Steinke and Zakynthinou. In a previous work, Haghifam et al. proposed a different bound combining the two aforementioned techniques, which we refer to as the conditional individual mutual information (CIMI) bound. However, in a simple Gaussian setting, both the CMI and the CIMI bounds are order-wise worse than that by Bu et al.. This observation motivated us to propose the new bound, which overcomes this issue by reducing the conditioning terms in the conditional mutual information. In the process of establishing this bound, a conditional decoupling lemma is established, which also leads to a meaningful dichotomy and comparison among these information-theoretic bounds.
Evaluating Understanding on Conceptual Abstraction Benchmarks
Jun 28, 2022

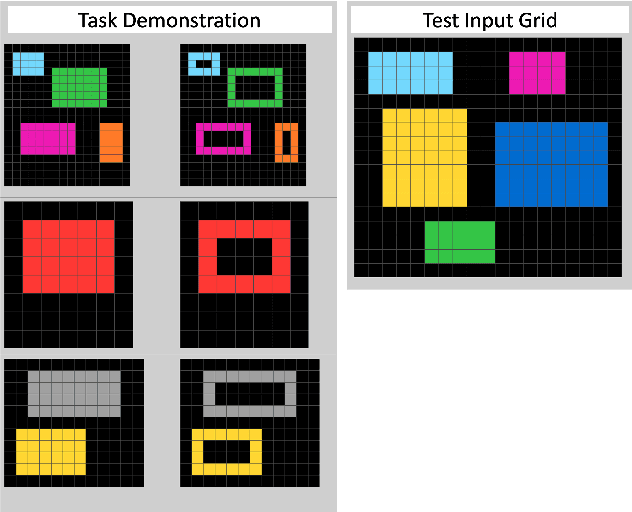

A long-held objective in AI is to build systems that understand concepts in a humanlike way. Setting aside the difficulty of building such a system, even trying to evaluate one is a challenge, due to present-day AI's relative opacity and its proclivity for finding shortcut solutions. This is exacerbated by humans' tendency to anthropomorphize, assuming that a system that can recognize one instance of a concept must also understand other instances, as a human would. In this paper, we argue that understanding a concept requires the ability to use it in varied contexts. Accordingly, we propose systematic evaluations centered around concepts, by probing a system's ability to use a given concept in many different instantiations. We present case studies of such an evaluations on two domains -- RAVEN (inspired by Raven's Progressive Matrices) and the Abstraction and Reasoning Corpus (ARC) -- that have been used to develop and assess abstraction abilities in AI systems. Our concept-based approach to evaluation reveals information about AI systems that conventional test sets would have left hidden.
CoVA: Exploiting Compressed-Domain Analysis to Accelerate Video Analytics
Jul 02, 2022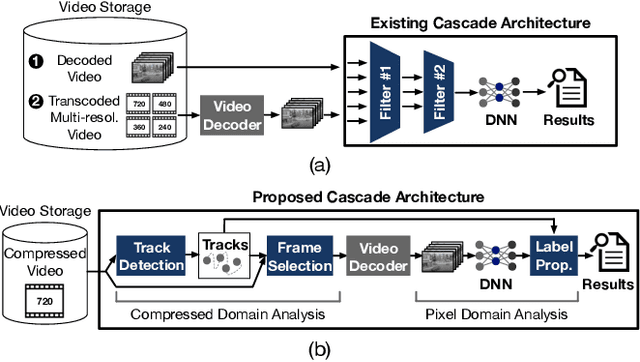
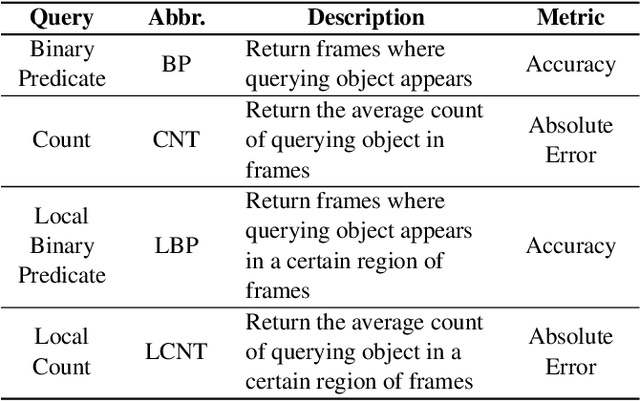
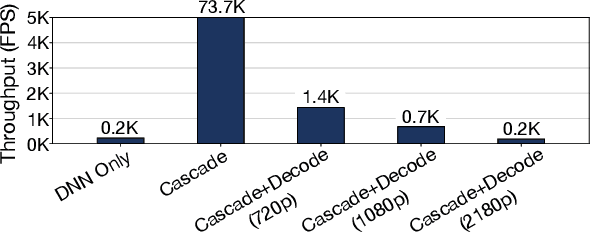

Modern retrospective analytics systems leverage cascade architecture to mitigate bottleneck for computing deep neural networks (DNNs). However, the existing cascades suffer two limitations: (1) decoding bottleneck is either neglected or circumvented, paying significant compute and storage cost for pre-processing; and (2) the systems are specialized for temporal queries and lack spatial query support. This paper presents CoVA, a novel cascade architecture that splits the cascade computation between compressed domain and pixel domain to address the decoding bottleneck, supporting both temporal and spatial queries. CoVA cascades analysis into three major stages where the first two stages are performed in compressed domain while the last one in pixel domain. First, CoVA detects occurrences of moving objects (called blobs) over a set of compressed frames (called tracks). Then, using the track results, CoVA prudently selects a minimal set of frames to obtain the label information and only decode them to compute the full DNNs, alleviating the decoding bottleneck. Lastly, CoVA associates tracks with labels to produce the final analysis results on which users can process both temporal and spatial queries. Our experiments demonstrate that CoVA offers 4.8x throughput improvement over modern cascade systems, while imposing modest accuracy loss.
Relating the fundamental frequency of speech with EEG using a dilated convolutional network
Jul 05, 2022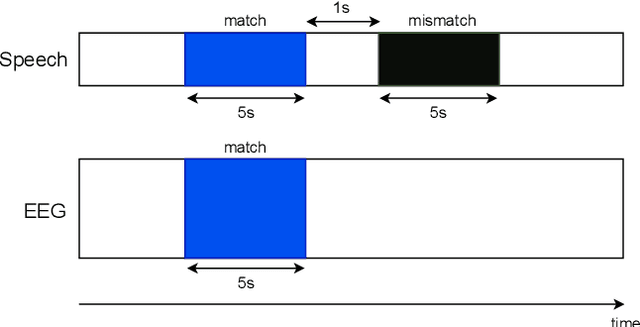
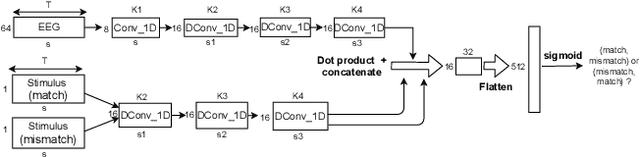
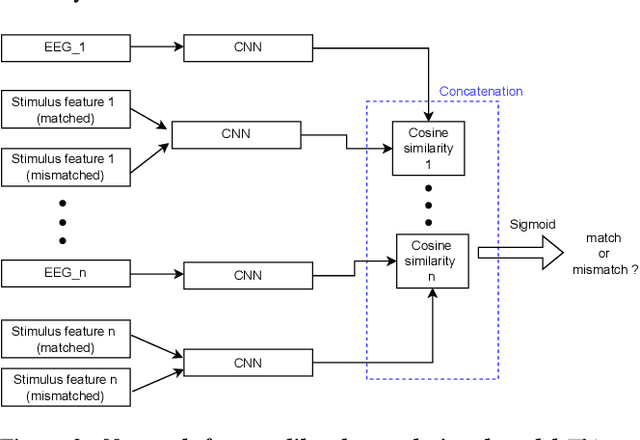
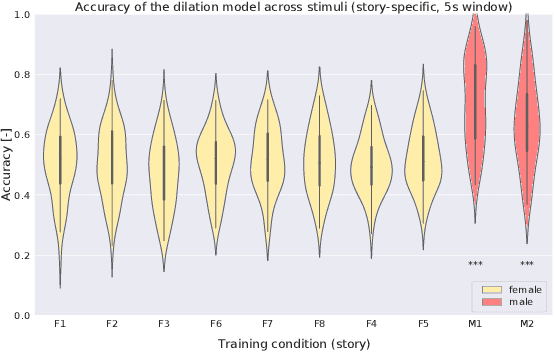
To investigate how speech is processed in the brain, we can model the relation between features of a natural speech signal and the corresponding recorded electroencephalogram (EEG). Usually, linear models are used in regression tasks. Either EEG is predicted, or speech is reconstructed, and the correlation between predicted and actual signal is used to measure the brain's decoding ability. However, given the nonlinear nature of the brain, the modeling ability of linear models is limited. Recent studies introduced nonlinear models to relate the speech envelope to EEG. We set out to include other features of speech that are not coded in the envelope, notably the fundamental frequency of the voice (f0). F0 is a higher-frequency feature primarily coded at the brainstem to midbrain level. We present a dilated-convolutional model to provide evidence of neural tracking of the f0. We show that a combination of f0 and the speech envelope improves the performance of a state-of-the-art envelope-based model. This suggests the dilated-convolutional model can extract non-redundant information from both f0 and the envelope. We also show the ability of the dilated-convolutional model to generalize to subjects not included during training. This latter finding will accelerate f0-based hearing diagnosis.
Bayes Classification using an approximation to the Joint Probability Distribution of the Attributes
May 29, 2022
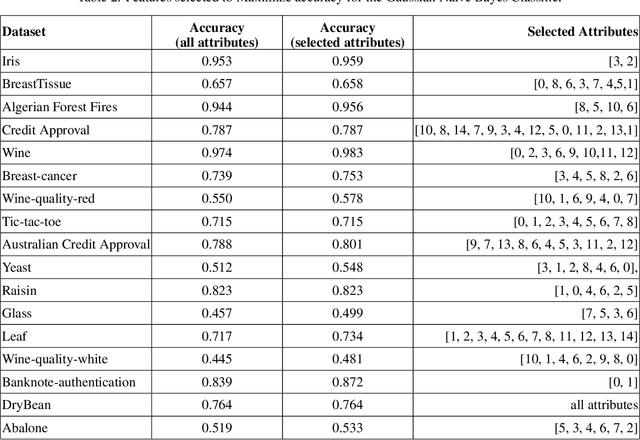
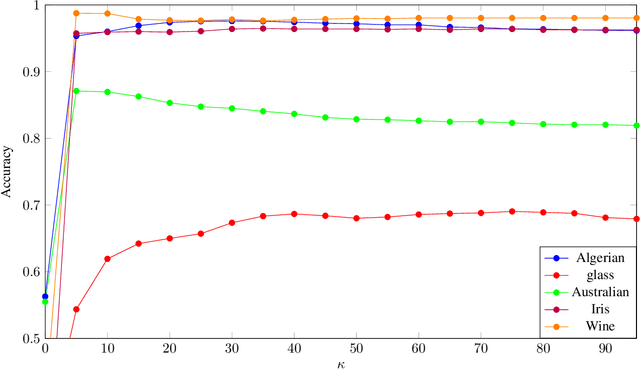
The Naive-Bayes classifier is widely used due to its simplicity, speed and accuracy. However this approach fails when, for at least one attribute value in a test sample, there are no corresponding training samples with that attribute value. This is known as the zero frequency problem and is typically addressed using Laplace Smoothing. However, Laplace Smoothing does not take into account the statistical characteristics of the neighbourhood of the attribute values of the test sample. Gaussian Naive Bayes addresses this but the resulting Gaussian model is formed from global information. We instead propose an approach that estimates conditional probabilities using information in the neighbourhood of the test sample. In this case we no longer need to make the assumption of independence of attribute values and hence consider the joint probability distribution conditioned on the given class which means our approach (unlike the Gaussian and Laplace approaches) takes into consideration dependencies among the attribute values. We illustrate the performance of the proposed approach on a wide range of datasets taken from the University of California at Irvine (UCI) Machine Learning Repository. We also include results for the $k$-NN classifier and demonstrate that the proposed approach is simple, robust and outperforms standard approaches.
How to Steer Your Adversary: Targeted and Efficient Model Stealing Defenses with Gradient Redirection
Jun 28, 2022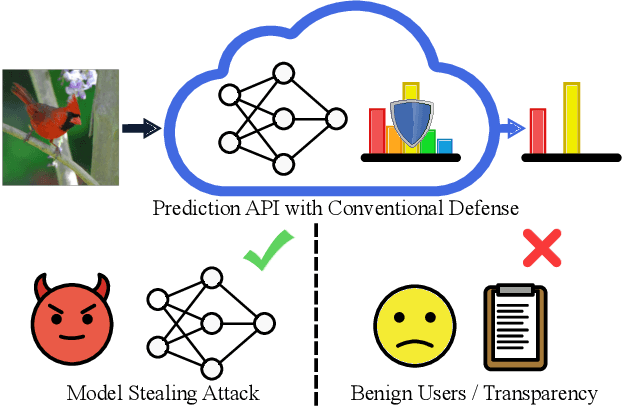
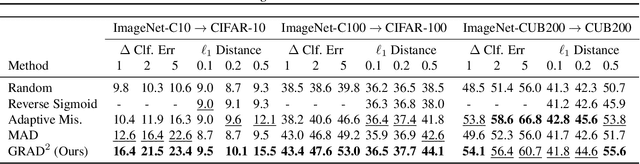
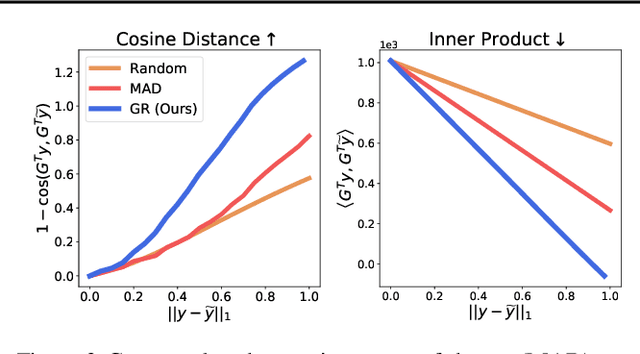
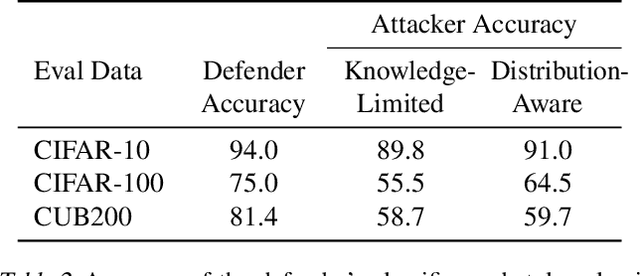
Model stealing attacks present a dilemma for public machine learning APIs. To protect financial investments, companies may be forced to withhold important information about their models that could facilitate theft, including uncertainty estimates and prediction explanations. This compromise is harmful not only to users but also to external transparency. Model stealing defenses seek to resolve this dilemma by making models harder to steal while preserving utility for benign users. However, existing defenses have poor performance in practice, either requiring enormous computational overheads or severe utility trade-offs. To meet these challenges, we present a new approach to model stealing defenses called gradient redirection. At the core of our approach is a provably optimal, efficient algorithm for steering an adversary's training updates in a targeted manner. Combined with improvements to surrogate networks and a novel coordinated defense strategy, our gradient redirection defense, called GRAD${}^2$, achieves small utility trade-offs and low computational overhead, outperforming the best prior defenses. Moreover, we demonstrate how gradient redirection enables reprogramming the adversary with arbitrary behavior, which we hope will foster work on new avenues of defense.
Entity Linking in Tabular Data Needs the Right Attention
Jul 05, 2022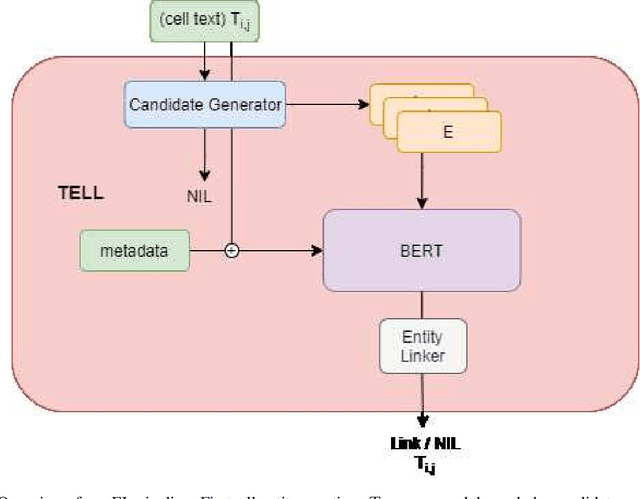
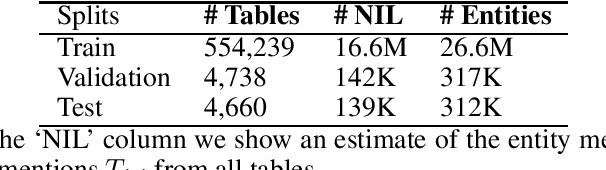
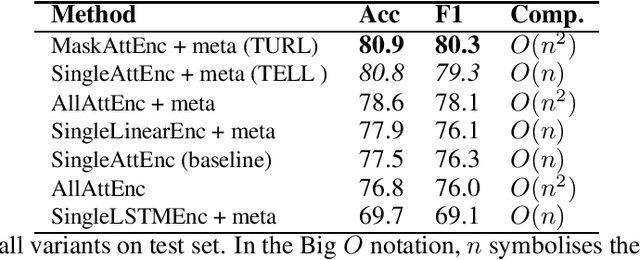
Understanding the semantic meaning of tabular data requires Entity Linking (EL), in order to associate each cell value to a real-world entity in a Knowledge Base (KB). In this work, we focus on end-to-end solutions for EL on tabular data that do not rely on fact lookup in the target KB. Tabular data contains heterogeneous and sparse context, including column headers, cell values and table captions. We experiment with various models to generate a vector representation for each cell value to be linked. Our results show that it is critical to apply an attention mechanism as well as an attention mask, so that the model can only attend to the most relevant context and avoid information dilution. The most relevant context includes: same-row cells, same-column cells, headers and caption. Computational complexity, however, grows quadratically with the size of tabular data for such a complex model. We achieve constant memory usage by introducing a Tabular Entity Linking Lite model (TELL ) that generates vector representation for a cell based only on its value, the table headers and the table caption. TELL achieves 80.8% accuracy on Wikipedia tables, which is only 0.1% lower than the state-of-the-art model with quadratic memory usage.
Spatial-Temporal Frequency Forgery Clue for Video Forgery Detection in VIS and NIR Scenario
Jul 05, 2022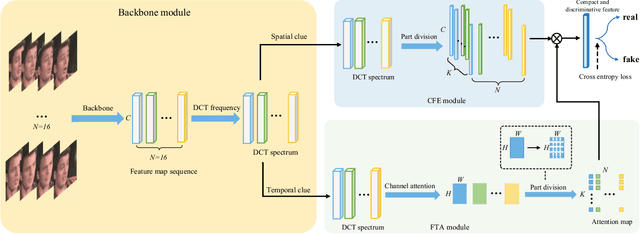
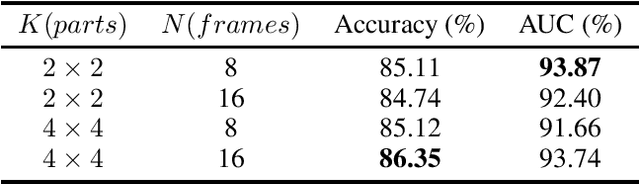
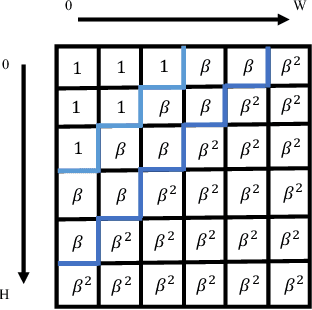
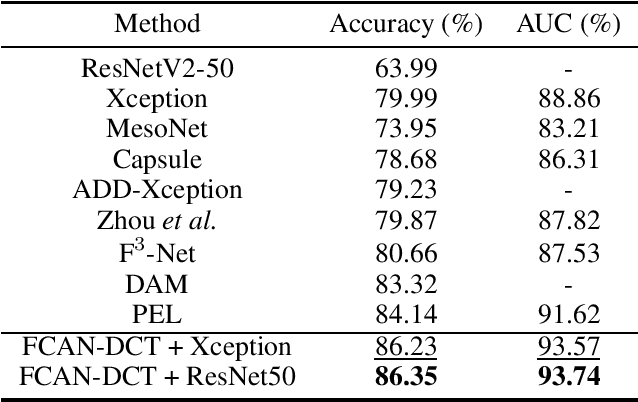
In recent years, with the rapid development of face editing and generation, more and more fake videos are circulating on social media, which has caused extreme public concerns. Existing face forgery detection methods based on frequency domain find that the GAN forged images have obvious grid-like visual artifacts in the frequency spectrum compared to the real images. But for synthesized videos, these methods only confine to single frame and pay little attention to the most discriminative part and temporal frequency clue among different frames. To take full advantage of the rich information in video sequences, this paper performs video forgery detection on both spatial and temporal frequency domains and proposes a Discrete Cosine Transform-based Forgery Clue Augmentation Network (FCAN-DCT) to achieve a more comprehensive spatial-temporal feature representation. FCAN-DCT consists of a backbone network and two branches: Compact Feature Extraction (CFE) module and Frequency Temporal Attention (FTA) module. We conduct thorough experimental assessments on two visible light (VIS) based datasets WildDeepfake and Celeb-DF (v2), and our self-built video forgery dataset DeepfakeNIR, which is the first video forgery dataset on near-infrared modality. The experimental results demonstrate the effectiveness of our method on detecting forgery videos in both VIS and NIR scenarios.