 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACFormer: Mitigating Non-linearity with Auto Convolutional Encoder for Time Series Forecasting
Jan 28, 2026Time series forecasting (TSF) faces challenges in modeling complex intra-channel temporal dependencies and inter-channel correlations. Although recent research has highlighted the efficiency of linear architectures in capturing global trends, these models often struggle with non-linear signals. To address this gap, we conducted a systematic receptive field analysis of convolutional neural network (CNN) TSF models. We introduce the "individual receptive field" to uncover granular structural dependencies, revealing that convolutional layers act as feature extractors that mirror channel-wise attention while exhibiting superior robustness to non-linear fluctuations. Based on these insights, we propose ACFormer, an architecture designed to reconcile the efficiency of linear projections with the non-linear feature-extraction power of convolutions. ACFormer captures fine-grained information through a shared compression module, preserves temporal locality via gated attention, and reconstructs variable-specific temporal patterns using an independent patch expansion layer. Extensive experiments on multiple benchmark datasets demonstrate that ACFormer consistently achieves state-of-the-art performance, effectively mitigating the inherent drawbacks of linear models in capturing high-frequency components.
FEATHer: Fourier-Efficient Adaptive Temporal Hierarchy Forecaster for Time-Series Forecasting
Jan 16, 2026Time-series forecasting is fundamental in industrial domains like manufacturing and smart factories. As systems evolve toward automation, models must operate on edge devices (e.g., PLCs, microcontrollers) with strict constraints on latency and memory, limiting parameters to a few thousand. Conventional deep architectures are often impractical here. We propose the Fourier-Efficient Adaptive Temporal Hierarchy Forecaster (FEATHer) for accurate long-term forecasting under severe limits. FEATHer introduces: (i) ultra-lightweight multiscale decomposition into frequency pathways; (ii) a shared Dense Temporal Kernel using projection-depthwise convolution-projection without recurrence or attention; (iii) frequency-aware branch gating that adaptively fuses representations based on spectral characteristics; and (iv) a Sparse Period Kernel reconstructing outputs via period-wise downsampling to capture seasonality. FEATHer maintains a compact architecture (as few as 400 parameters) while outperforming baselines. Across eight benchmarks, it achieves the best ranking, recording 60 first-place results with an average rank of 2.05. These results demonstrate that reliable long-range forecasting is achievable on constrained edge hardware, offering a practical direction for industrial real-time inference.
Cultural Rights and the Rights to Development in the Age of AI: Implications for Global Human Rights Governance
Dec 15, 2025Cultural rights and the right to development are essential norms within the wider framework of international human rights law. However, recent technological advances in artificial intelligence (AI) and adjacent digital frontier technologies pose significant challenges to the protection and realization of these rights. This owes to the increasing influence of AI systems on the creation and depiction of cultural content, affect the use and distribution of the intellectual property of individuals and communities, and influence cultural participation and expression worldwide. In addition, the growing influence of AI thus risks exacerbating preexisting economic, social and digital divides and reinforcing inequities for marginalized communities. This dynamic challenges the existing interplay between cultural rights and the right to development, and raises questions about the integration of cultural and developmental considerations into emerging AI governance frameworks. To address these challenges, the paper examines the impact of AI on both categories of rights. Conceptually, it analyzes the epistemic and normative limitations of AI with respect to cultural and developmental assumptions embedded in algorithmic design and deployment, but also individual and structural impacts of AI on both rights. On this basis, the paper identifies gaps and tensions in existing AI governance frameworks with respect to cultural rights and the right to development. By situating cultural rights and the right to development within the broader landscape of AI and human rights, this paper contributes to the academic discourse on AI ethics, legal frameworks, and international human rights law. Finally, it outlines avenues for future research and policy development based on existing conversations in global AI governance.
From Prediction to Application: Language Model-based Code Knowledge Tracing with Domain Adaptive Pre-Training and Automatic Feedback System with Pedagogical Prompting for Comprehensive Programming Education
Aug 31, 2024



Knowledge Tracing (KT) is a critical component in online learning, but traditional approaches face limitations in interpretability and cross-domain adaptability. This paper introduces Language Model-based Code Knowledge Tracing (CodeLKT), an innovative application of Language model-based Knowledge Tracing (LKT) to programming education. CodeLKT leverages pre-trained language models to process learning data, demonstrating superior performance over existing KT and Code KT models. We explore Domain Adaptive Pre-Training (DAPT) and Task Adaptive Pre-Training (TAPT), showing enhanced performance in the coding domain and investigating cross-domain transfer between mathematics and coding. Additionally, we present an theoretically-informed integrated system combining CodeLKT with large language models to generate personalized, in-depth feedback to support students' programming learning. This work advances the field of Code Knowledge Tracing by expanding the knowledge base with language model-based approach and offering practical implications for programming education through data-informed feedback.
DLFormer: Enhancing Explainability in Multivariate Time Series Forecasting using Distributed Lag Embedding
Aug 29, 2024



. Most real-world variables are multivariate time series influenced by past values and explanatory factors. Consequently, predicting these time series data using artificial intelligence is ongoing. In particular, in fields such as healthcare and finance, where reliability is crucial, having understandable explanations for predictions is essential. However, achieving a balance between high prediction accuracy and intuitive explainability has proven challenging. Although attention-based models have limitations in representing the individual influences of each variable, these models can influence the temporal dependencies in time series prediction and the magnitude of the influence of individual variables. To address this issue, this study introduced DLFormer, an attention-based architecture integrated with distributed lag embedding, to temporally embed individual variables and capture their temporal influence. Through validation against various real-world datasets, DLFormer showcased superior performance improvements compared to existing attention-based high-performance models. Furthermore, comparing the relationships between variables enhanced the reliability of explainability.
Language Model Can Do Knowledge Tracing: Simple but Effective Method to Integrate Language Model and Knowledge Tracing Task
Jun 05, 2024Knowledge Tracing (KT) is a critical task in online learning for modeling student knowledge over time. Despite the success of deep learning-based KT models, which rely on sequences of numbers as data, most existing approaches fail to leverage the rich semantic information in the text of questions and concepts. This paper proposes Language model-based Knowledge Tracing (LKT), a novel framework that integrates pre-trained language models (PLMs) with KT methods. By leveraging the power of language models to capture semantic representations, LKT effectively incorporates textual information and significantly outperforms previous KT models on large benchmark datasets. Moreover, we demonstrate that LKT can effectively address the cold-start problem in KT by leveraging the semantic knowledge captured by PLMs. Interpretability of LKT is enhanced compared to traditional KT models due to its use of text-rich data. We conducted the local interpretable model-agnostic explanation technique and analysis of attention scores to interpret the model performance further. Our work highlights the potential of integrating PLMs with KT and paves the way for future research in KT domain.
NaturalInversion: Data-Free Image Synthesis Improving Real-World Consistency
Jun 29, 2023



We introduce NaturalInversion, a novel model inversion-based method to synthesize images that agrees well with the original data distribution without using real data. In NaturalInversion, we propose: (1) a Feature Transfer Pyramid which uses enhanced image prior of the original data by combining the multi-scale feature maps extracted from the pre-trained classifier, (2) a one-to-one approach generative model where only one batch of images are synthesized by one generator to bring the non-linearity to optimization and to ease the overall optimizing process, (3) learnable Adaptive Channel Scaling parameters which are end-to-end trained to scale the output image channel to utilize the original image prior further. With our NaturalInversion, we synthesize images from classifiers trained on CIFAR-10/100 and show that our images are more consistent with original data distribution than prior works by visualization and additional analysis. Furthermore, our synthesized images outperform prior works on various applications such as knowledge distillation and pruning, demonstrating the effectiveness of our proposed method.
* Published at AAAI 2022
CRU: A Novel Neural Architecture for Improving the Predictive Performance of Time-Series Data
Nov 30, 2022The time-series forecasting (TSF) problem is a traditional problem in the field of artificial intelligence. Models such as Recurrent Neural Network (RNN), Long Short Term Memory (LSTM), and GRU (Gate Recurrent Units) have contributed to improving the predictive accuracy of TSF. Furthermore, model structures have been proposed to combine time-series decomposition methods, such as seasonal-trend decomposition using Loess (STL) to ensure improved predictive accuracy. However, because this approach is learned in an independent model for each component, it cannot learn the relationships between time-series components. In this study, we propose a new neural architecture called a correlation recurrent unit (CRU) that can perform time series decomposition within a neural cell and learn correlations (autocorrelation and correlation) between each decomposition component. The proposed neural architecture was evaluated through comparative experiments with previous studies using five univariate time-series datasets and four multivariate time-series data. The results showed that long- and short-term predictive performance was improved by more than 10%. The experimental results show that the proposed CRU is an excellent method for TSF problems compared to other neural architectures.
CoVA: Exploiting Compressed-Domain Analysis to Accelerate Video Analytics
Jul 02, 2022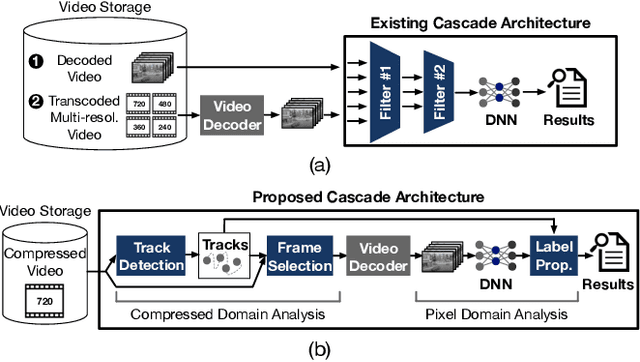
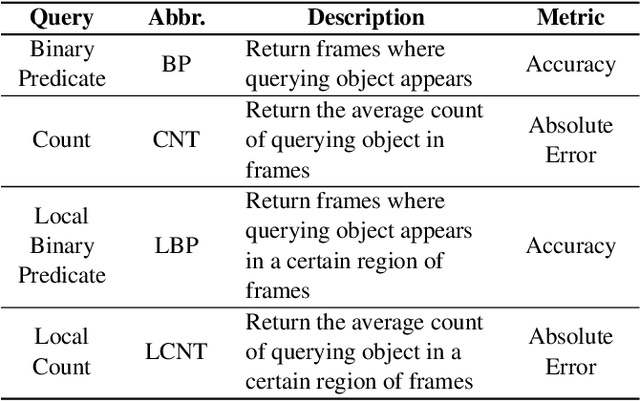
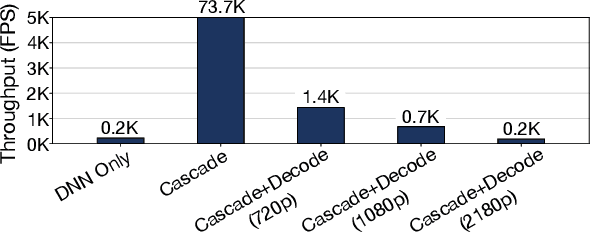

Modern retrospective analytics systems leverage cascade architecture to mitigate bottleneck for computing deep neural networks (DNNs). However, the existing cascades suffer two limitations: (1) decoding bottleneck is either neglected or circumvented, paying significant compute and storage cost for pre-processing; and (2) the systems are specialized for temporal queries and lack spatial query support. This paper presents CoVA, a novel cascade architecture that splits the cascade computation between compressed domain and pixel domain to address the decoding bottleneck, supporting both temporal and spatial queries. CoVA cascades analysis into three major stages where the first two stages are performed in compressed domain while the last one in pixel domain. First, CoVA detects occurrences of moving objects (called blobs) over a set of compressed frames (called tracks). Then, using the track results, CoVA prudently selects a minimal set of frames to obtain the label information and only decode them to compute the full DNNs, alleviating the decoding bottleneck. Lastly, CoVA associates tracks with labels to produce the final analysis results on which users can process both temporal and spatial queries. Our experiments demonstrate that CoVA offers 4.8x throughput improvement over modern cascade systems, while imposing modest accuracy loss.