 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CE-FPN: Enhancing Channel Information for Object Detection
Mar 19, 2021
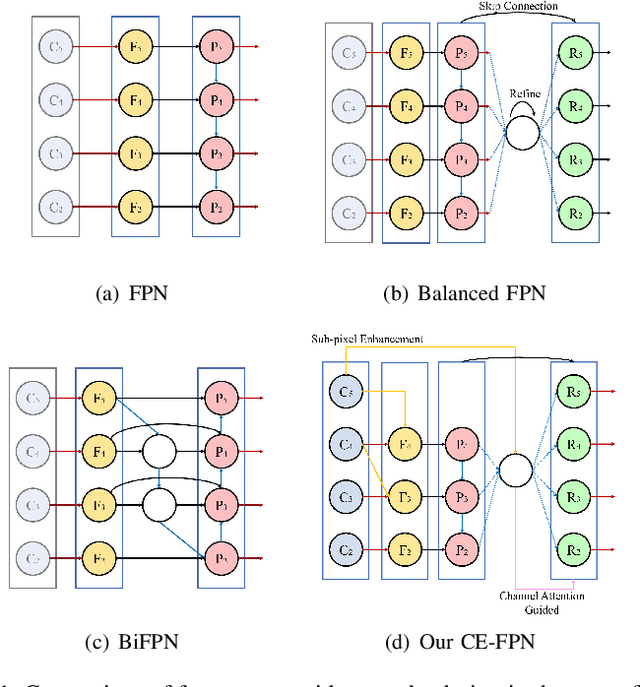
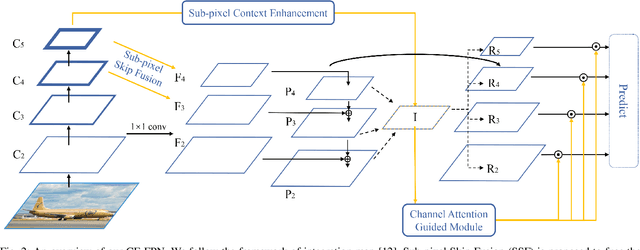
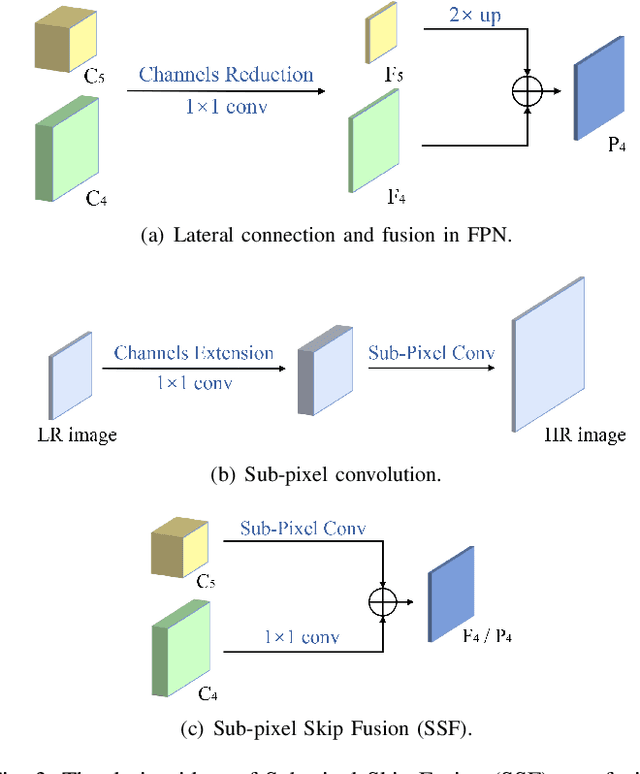
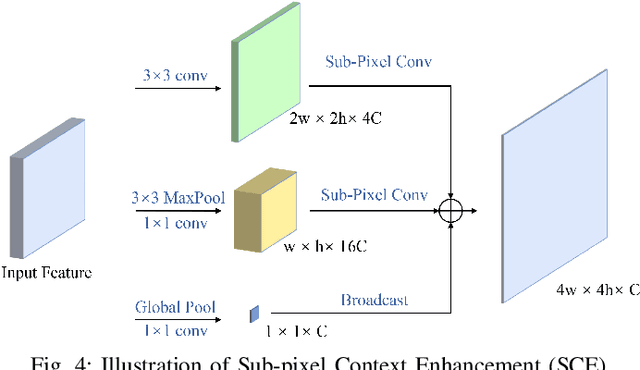
Feature pyramid network (FPN) has been an effective framework to extract multi-scale features in object detection. However, current FPN-based methods mostly suffer from the intrinsic flaw of channel reduction, which brings about the loss of semantical information. And the miscellaneous fused feature maps may cause serious aliasing effects. In this paper, we present a novel channel enhancement feature pyramid network (CE-FPN) with three simple yet effective modules to alleviate these problems. Specifically, inspired by sub-pixel convolution, we propose a sub-pixel skip fusion method to perform both channel enhancement and upsampling. Instead of the original 1x1 convolution and linear upsampling, it mitigates the information loss due to channel reduction. Then we propose a sub-pixel context enhancement module for extracting more feature representations, which is superior to other context methods due to the utilization of rich channel information by sub-pixel convolution. Furthermore, a channel attention guided module is introduced to optimize the final integrated features on each level, which alleviates the aliasing effect only with a few computational burdens. Our experiments show that CE-FPN achieves competitive performance compared to state-of-the-art FPN-based detectors on MS COCO benchmark.
Grounding Visual Representations with Texts for Domain Generalization
Jul 21, 2022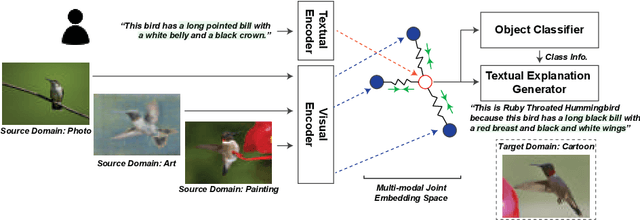
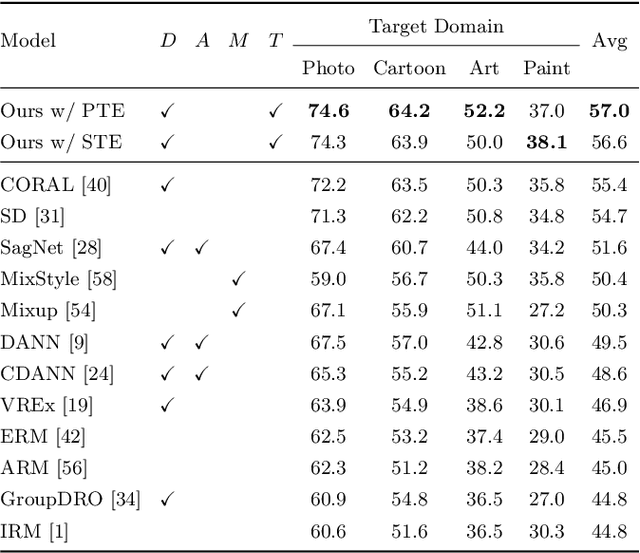
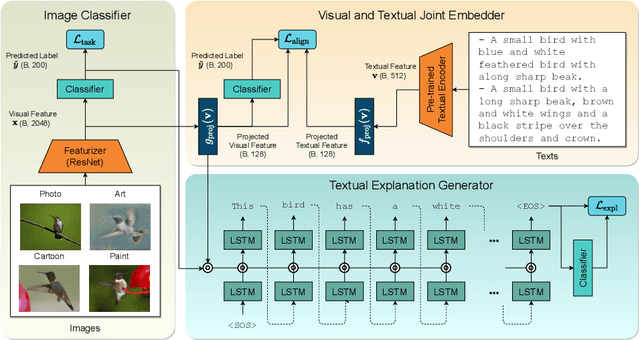
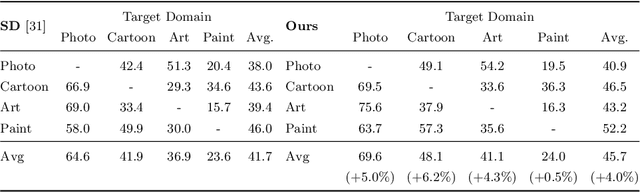
Reducing the representational discrepancy between source and target domains is a key component to maximize the model generalization. In this work, we advocate for leveraging natural language supervision for the domain generalization task. We introduce two modules to ground visual representations with texts containing typical reasoning of humans: (1) Visual and Textual Joint Embedder and (2) Textual Explanation Generator. The former learns the image-text joint embedding space where we can ground high-level class-discriminative information into the model. The latter leverages an explainable model and generates explanations justifying the rationale behind its decision. To the best of our knowledge, this is the first work to leverage the vision-and-language cross-modality approach for the domain generalization task. Our experiments with a newly created CUB-DG benchmark dataset demonstrate that cross-modality supervision can be successfully used to ground domain-invariant visual representations and improve the model generalization. Furthermore, in the large-scale DomainBed benchmark, our proposed method achieves state-of-the-art results and ranks 1st in average performance for five multi-domain datasets. The dataset and codes are available at https://github.com/mswzeus/GVRT.
FuseFormer: Fusing Fine-Grained Information in Transformers for Video Inpainting
Sep 07, 2021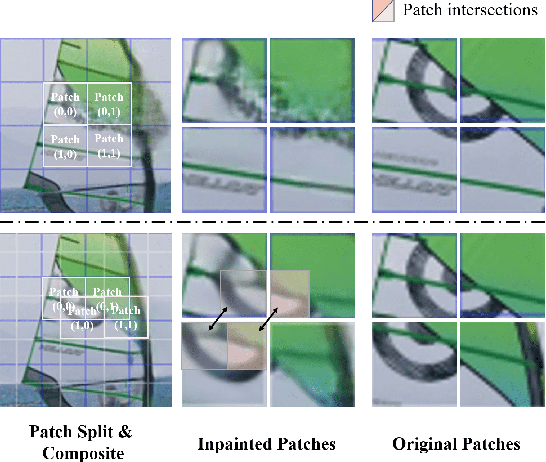
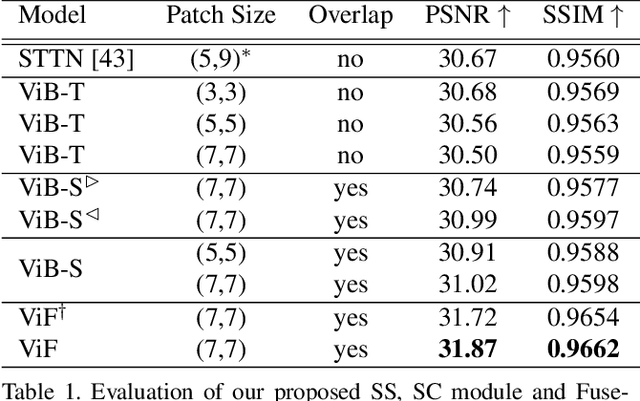
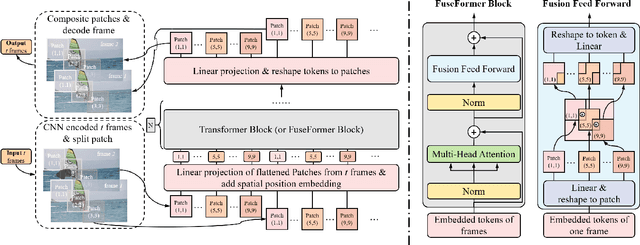
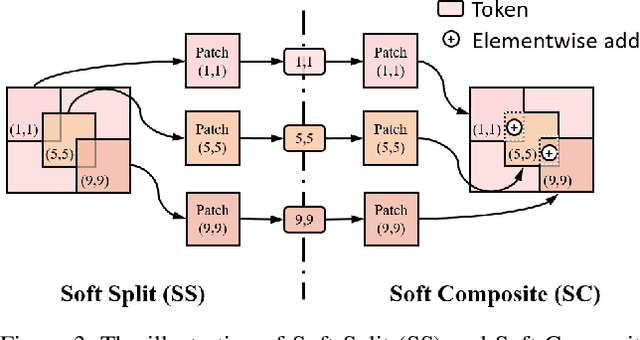
Transformer, as a strong and flexible architecture for modelling long-range relations, has been widely explored in vision tasks. However, when used in video inpainting that requires fine-grained representation, existed method still suffers from yielding blurry edges in detail due to the hard patch splitting. Here we aim to tackle this problem by proposing FuseFormer, a Transformer model designed for video inpainting via fine-grained feature fusion based on novel Soft Split and Soft Composition operations. The soft split divides feature map into many patches with given overlapping interval. On the contrary, the soft composition operates by stitching different patches into a whole feature map where pixels in overlapping regions are summed up. These two modules are first used in tokenization before Transformer layers and de-tokenization after Transformer layers, for effective mapping between tokens and features. Therefore, sub-patch level information interaction is enabled for more effective feature propagation between neighboring patches, resulting in synthesizing vivid content for hole regions in videos. Moreover, in FuseFormer, we elaborately insert the soft composition and soft split into the feed-forward network, enabling the 1D linear layers to have the capability of modelling 2D structure. And, the sub-patch level feature fusion ability is further enhanced. In both quantitative and qualitative evaluations, our proposed FuseFormer surpasses state-of-the-art methods. We also conduct detailed analysis to examine its superiority.
Better Neural Machine Translation by Extracting Linguistic Information from BERT
Apr 07, 2021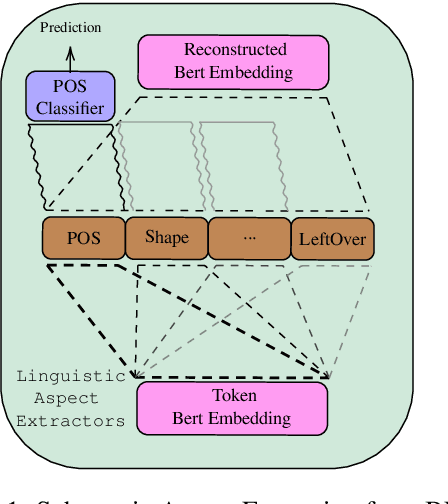

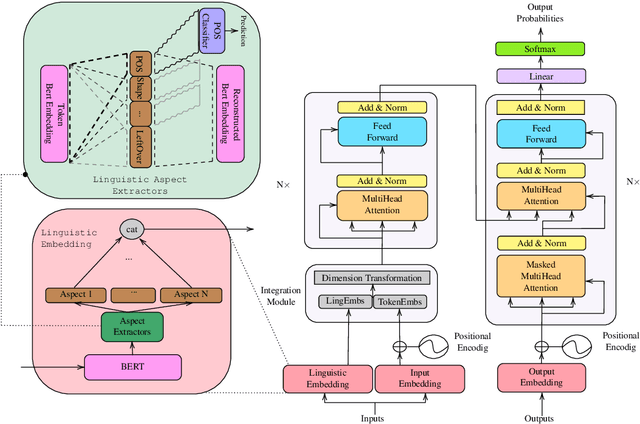
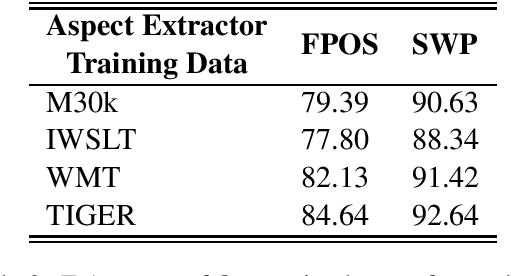
Adding linguistic information (syntax or semantics) to neural machine translation (NMT) has mostly focused on using point estimates from pre-trained models. Directly using the capacity of massive pre-trained contextual word embedding models such as BERT (Devlin et al., 2019) has been marginally useful in NMT because effective fine-tuning is difficult to obtain for NMT without making training brittle and unreliable. We augment NMT by extracting dense fine-tuned vector-based linguistic information from BERT instead of using point estimates. Experimental results show that our method of incorporating linguistic information helps NMT to generalize better in a variety of training contexts and is no more difficult to train than conventional Transformer-based NMT.
OSFormer: One-Stage Camouflaged Instance Segmentation with Transformers
Jul 05, 2022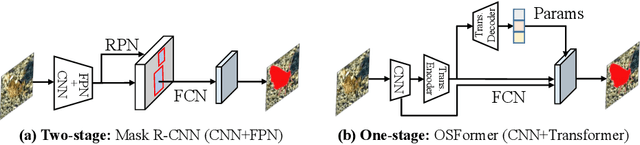
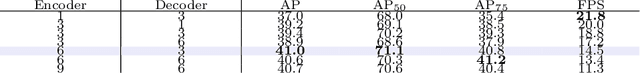

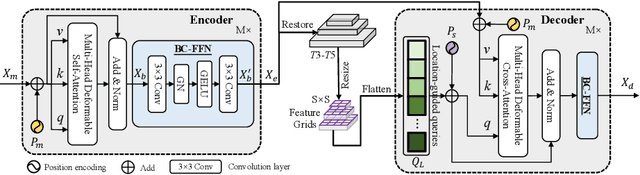
We present OSFormer, the first one-stage transformer framework for camouflaged instance segmentation (CIS). OSFormer is based on two key designs. First, we design a location-sensing transformer (LST) to obtain the location label and instance-aware parameters by introducing the location-guided queries and the blend-convolution feedforward network. Second, we develop a coarse-to-fine fusion (CFF) to merge diverse context information from the LST encoder and CNN backbone. Coupling these two components enables OSFormer to efficiently blend local features and long-range context dependencies for predicting camouflaged instances. Compared with two-stage frameworks, our OSFormer reaches 41% AP and achieves good convergence efficiency without requiring enormous training data, i.e., only 3,040 samples under 60 epochs. Code link: https://github.com/PJLallen/OSFormer.
Troll Tweet Detection Using Contextualized Word Representations
Jul 17, 2022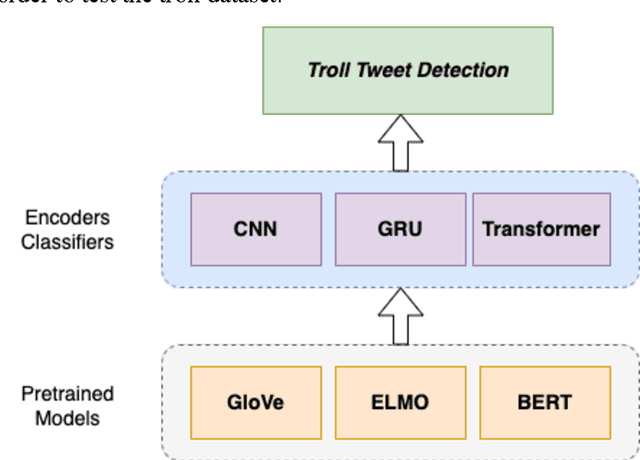
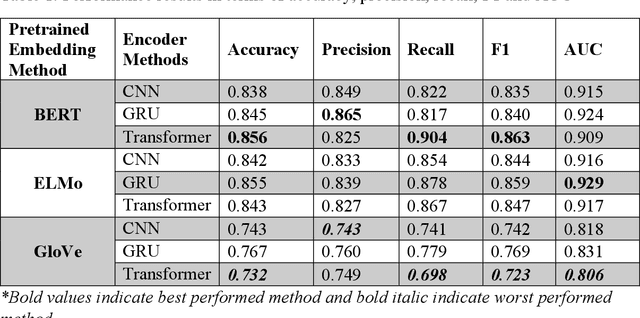

In recent years, many troll accounts have emerged to manipulate social media opinion. Detecting and eradicating trolling is a critical issue for social-networking platforms because businesses, abusers, and nation-state-sponsored troll farms use false and automated accounts. NLP techniques are used to extract data from social networking text, such as Twitter tweets. In many text processing applications, word embedding representation methods, such as BERT, have performed better than prior NLP techniques, offering novel breaks to precisely comprehend and categorize social-networking information for various tasks. This paper implements and compares nine deep learning-based troll tweet detection architectures, with three models for each BERT, ELMo, and GloVe word embedding model. Precision, recall, F1 score, AUC, and classification accuracy are used to evaluate each architecture. From the experimental results, most architectures using BERT models improved troll tweet detection. A customized ELMo-based architecture with a GRU classifier has the highest AUC for detecting troll messages. The proposed architectures can be used by various social-based systems to detect troll messages in the future.
Towards quantifying information flows: relative entropy in deep neural networks and the renormalization group
Jul 14, 2021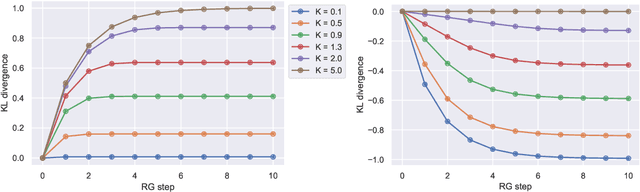
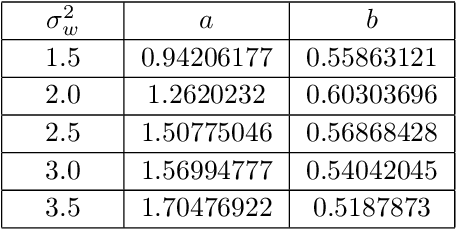
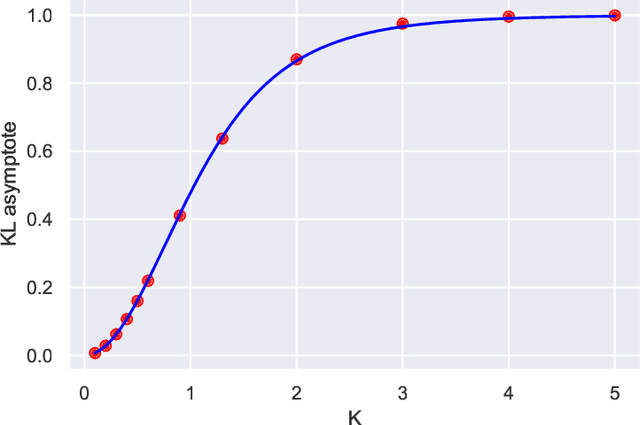
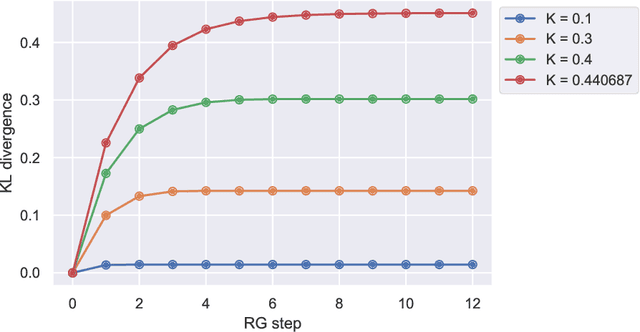
We investigate the analogy between the renormalization group (RG) and deep neural networks, wherein subsequent layers of neurons are analogous to successive steps along the RG. In particular, we quantify the flow of information by explicitly computing the relative entropy or Kullback-Leibler divergence in both the one- and two-dimensional Ising models under decimation RG, as well as in a feedforward neural network as a function of depth. We observe qualitatively identical behavior characterized by the monotonic increase to a parameter-dependent asymptotic value. On the quantum field theory side, the monotonic increase confirms the connection between the relative entropy and the c-theorem. For the neural networks, the asymptotic behavior may have implications for various information maximization methods in machine learning, as well as for disentangling compactness and generalizability. Furthermore, while both the two-dimensional Ising model and the random neural networks we consider exhibit non-trivial critical points, the relative entropy appears insensitive to the phase structure of either system. In this sense, more refined probes are required in order to fully elucidate the flow of information in these models.
Robust Scene Inference under Noise-Blur Dual Corruptions
Jul 24, 2022
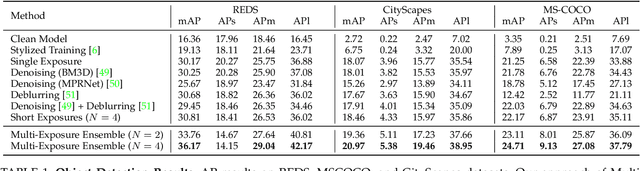
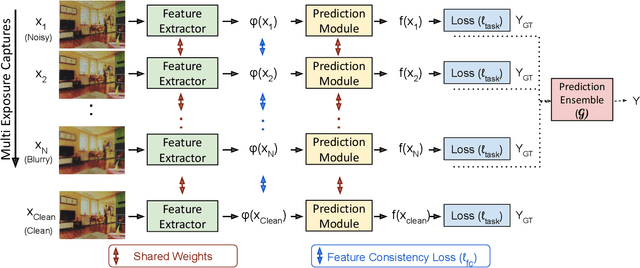
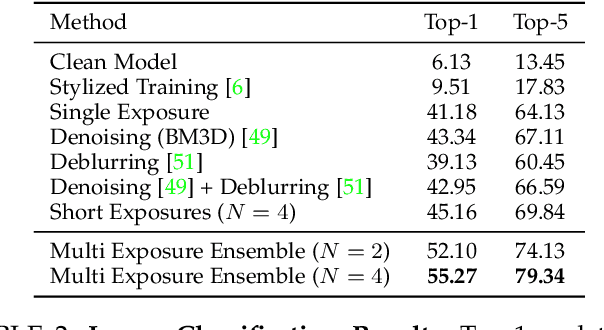
Scene inference under low-light is a challenging problem due to severe noise in the captured images. One way to reduce noise is to use longer exposure during the capture. However, in the presence of motion (scene or camera motion), longer exposures lead to motion blur, resulting in loss of image information. This creates a trade-off between these two kinds of image degradations: motion blur (due to long exposure) vs. noise (due to short exposure), also referred as a dual image corruption pair in this paper. With the rise of cameras capable of capturing multiple exposures of the same scene simultaneously, it is possible to overcome this trade-off. Our key observation is that although the amount and nature of degradation varies for these different image captures, the semantic content remains the same across all images. To this end, we propose a method to leverage these multi exposure captures for robust inference under low-light and motion. Our method builds on a feature consistency loss to encourage similar results from these individual captures, and uses the ensemble of their final predictions for robust visual recognition. We demonstrate the effectiveness of our approach on simulated images as well as real captures with multiple exposures, and across the tasks of object detection and image classification.
FEJ-VIRO: A Consistent First-Estimate Jacobian Visual-Inertial-Ranging Odometry
Jul 17, 2022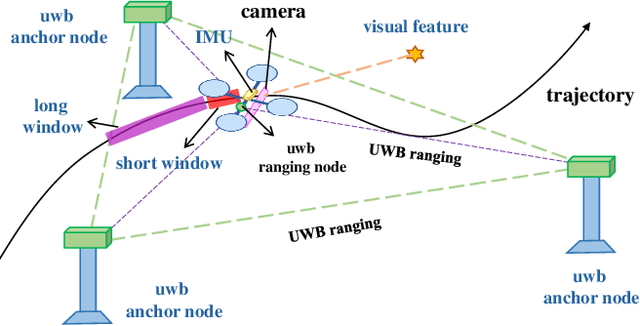
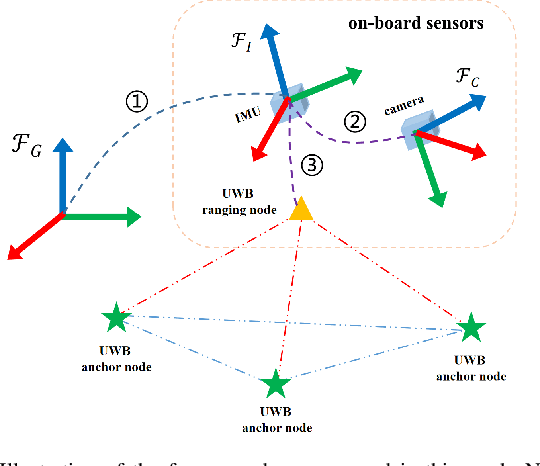
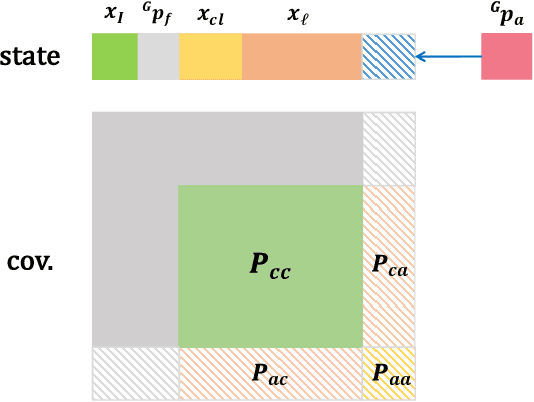
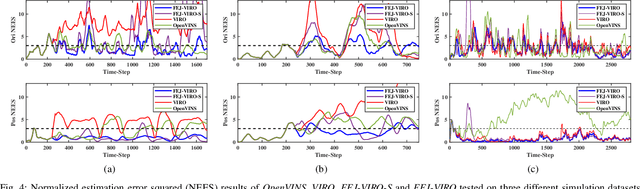
In recent years, Visual-Inertial Odometry (VIO) has achieved many significant progresses. However, VIO methods suffer from localization drift over long trajectories. In this paper, we propose a First-Estimates Jacobian Visual-Inertial-Ranging Odometry (FEJ-VIRO) to reduce the localization drifts of VIO by incorporating ultra-wideband (UWB) ranging measurements into the VIO framework \textit{consistently}. Considering that the initial positions of UWB anchors are usually unavailable, we propose a long-short window structure to initialize the UWB anchors' positions as well as the covariance for state augmentation. After initialization, the FEJ-VIRO estimates the UWB anchors' positions simultaneously along with the robot poses. We further analyze the observability of the visual-inertial-ranging estimators and proved that there are \textit{four} unobservable directions in the ideal case, while one of them vanishes in the actual case due to the gain of spurious information. Based on these analyses, we leverage the FEJ technique to enforce the unobservable directions, hence reducing inconsistency of the estimator. Finally, we validate our analysis and evaluate the proposed FEJ-VIRO with both simulation and real-world experiments.
Normalized Feature Distillation for Semantic Segmentation
Jul 12, 2022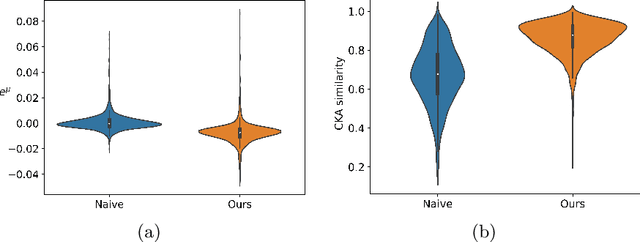
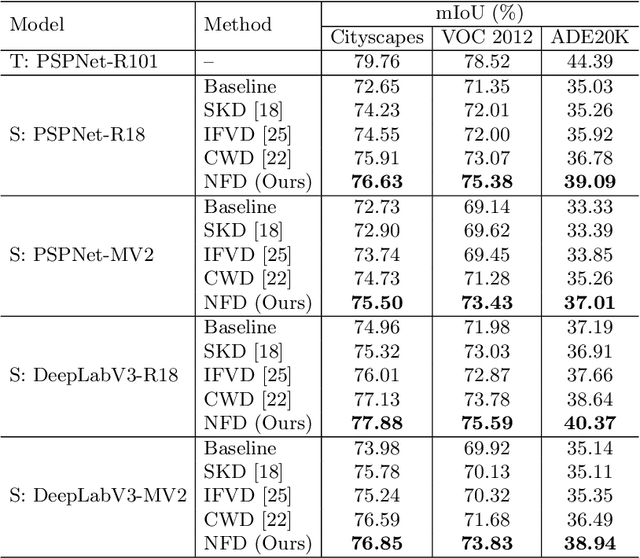
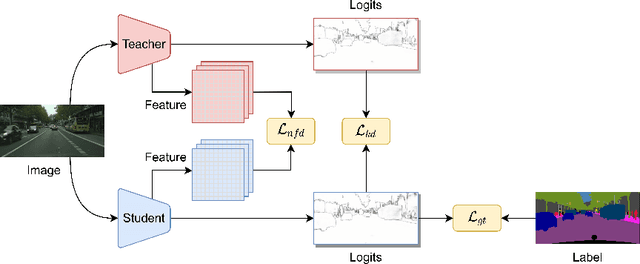
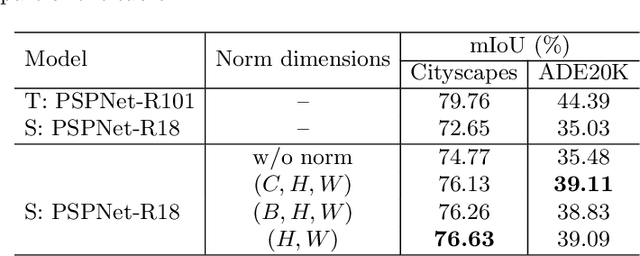
As a promising approach in model compression, knowledge distillation improves the performance of a compact model by transferring the knowledge from a cumbersome one. The kind of knowledge used to guide the training of the student is important. Previous distillation methods in semantic segmentation strive to extract various forms of knowledge from the features, which involve elaborate manual design relying on prior information and have limited performance gains. In this paper, we propose a simple yet effective feature distillation method called normalized feature distillation (NFD), aiming to enable effective distillation with the original features without the need to manually design new forms of knowledge. The key idea is to prevent the student from focusing on imitating the magnitude of the teacher's feature response by normalization. Our method achieves state-of-the-art distillation results for semantic segmentation on Cityscapes, VOC 2012, and ADE20K datasets. Code will be available.