 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On Integrating Prior Knowledge into Gaussian Processes for Prognostic Health Monitoring
Jun 17, 2022

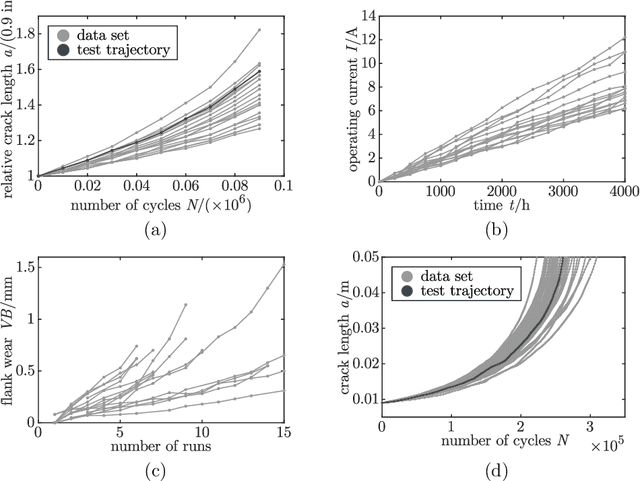

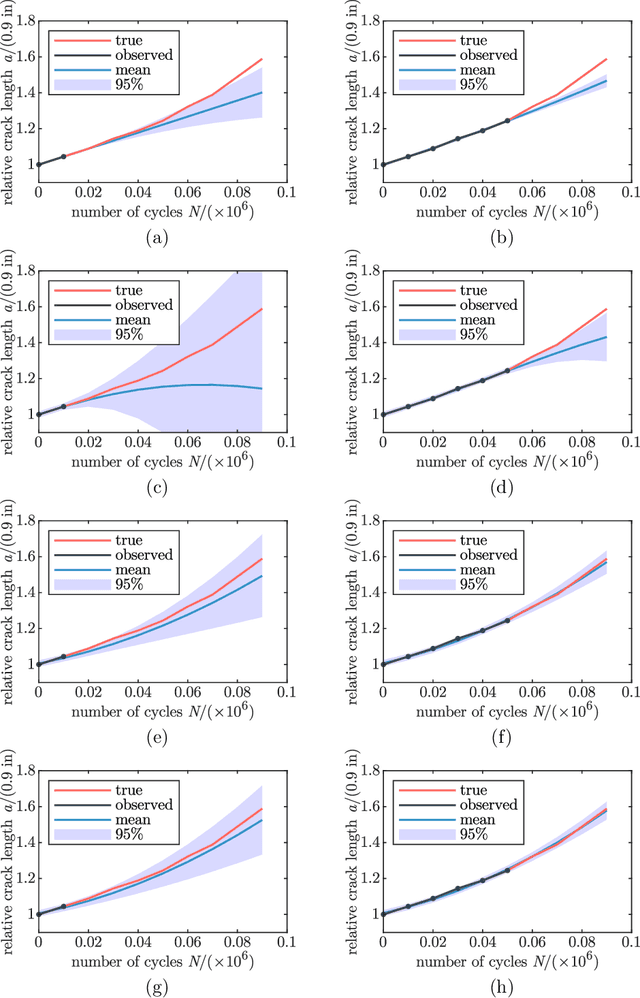
Gaussian process regression is a powerful method for predicting states based on given data. It has been successfully applied for probabilistic predictions of structural systems to quantify, for example, the crack growth in mechanical structures. Typically, predefined mean and covariance functions are employed to construct the Gaussian process model. Then, the model is updated using current data during operation while prior information based on previous data is ignored. However, predefined mean and covariance functions without prior information reduce the potential of Gaussian processes. This paper proposes a method to improve the predictive capabilities of Gaussian processes. We integrate prior knowledge by deriving the mean and covariance functions from previous data. More specifically, we first approximate previous data by a weighted sum of basis functions and then derive the mean and covariance functions directly from the estimated weight coefficients. Basis functions may be either estimated or derived from problem-specific governing equations to incorporate physical information. The applicability and effectiveness of this approach are demonstrated for fatigue crack growth, laser degradation, and milling machine wear data. We show that well-chosen mean and covariance functions, like those based on previous data, significantly increase look-ahead time and accuracy. Using physical basis functions further improves accuracy. In addition, computation effort for training is significantly reduced.
Robust and Secure Resource Allocation for ISAC Systems: A Novel Optimization Framework for Variable-Length Snapshots
Jun 27, 2022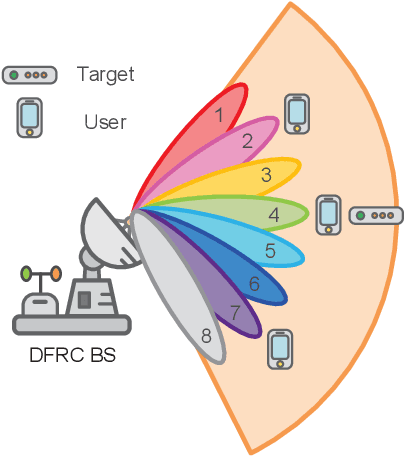
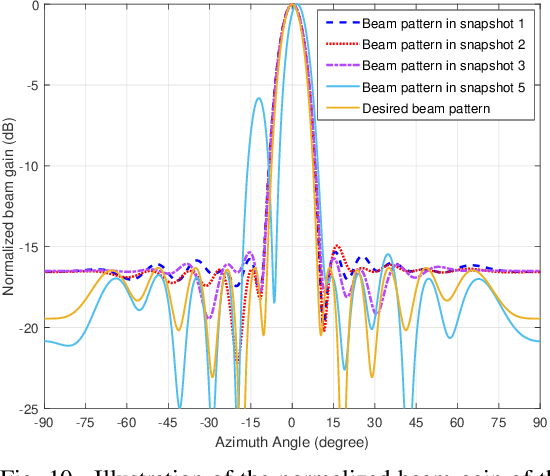
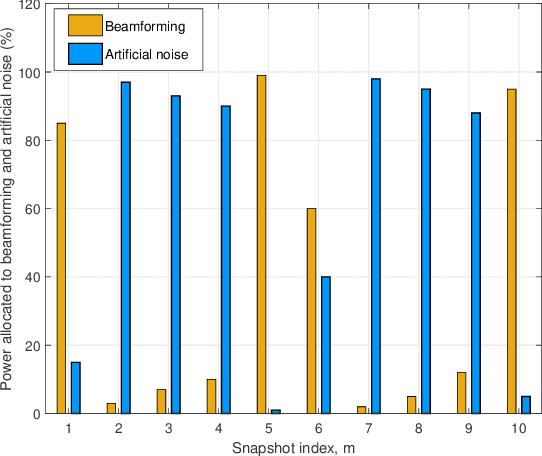
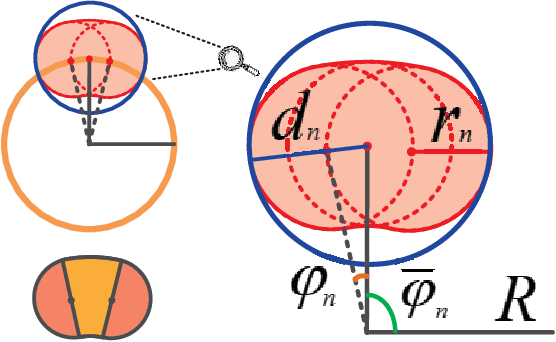
In this paper, we investigate the robust resource allocation design for secure communication in an integrated sensing and communication (ISAC) system. A multi-antenna dual-functional radar-communication (DFRC) base station (BS) serves multiple single-antenna legitimate users and senses for targets simultaneously, where already identified targets are treated as potential single-antenna eavesdroppers. The DFRC BS scans a sector with a sequence of dedicated beams, and the ISAC system takes a snapshot of the environment during the transmission of each beam. Based on the sensing information, the DFRC BS can acquire the channel state information (CSI) of the potential eavesdroppers. Different from existing works that focused on the resource allocation design for a single snapshot, in this paper, we propose a novel optimization framework that jointly optimizes the communication and sensing resources over a sequence of snapshots with adjustable durations. To this end, we jointly optimize the duration of each snapshot, the beamforming vector, and the covariance matrix of the AN for maximization of the system sum secrecy rate over a sequence of snapshots while guaranteeing a minimum required average achievable rate and a maximum information leakage constraint for each legitimate user. The resource allocation algorithm design is formulated as a non-convex optimization problem, where we account for the imperfect CSI of both the legitimate users and the potential eavesdroppers. To make the problem tractable, we derive a bound for the uncertainty region of the potential eavesdroppers' small-scale fading based on a safe approximation, which facilitates the development of a block coordinate descent-based iterative algorithm for obtaining an efficient suboptimal solution.
SIXO: Smoothing Inference with Twisted Objectives
Jun 20, 2022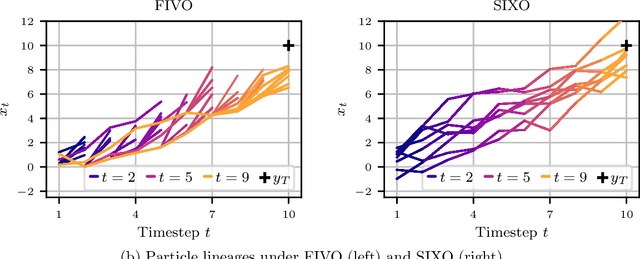

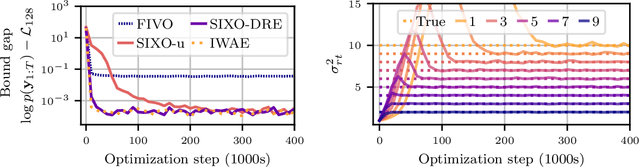
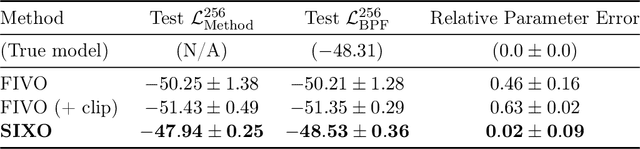
Sequential Monte Carlo (SMC) is an inference algorithm for state space models that approximates the posterior by sampling from a sequence of target distributions. The target distributions are often chosen to be the filtering distributions, but these ignore information from future observations, leading to practical and theoretical limitations in inference and model learning. We introduce SIXO, a method that instead learns targets that approximate the smoothing distributions, incorporating information from all observations. The key idea is to use density ratio estimation to fit functions that warp the filtering distributions into the smoothing distributions. We then use SMC with these learned targets to define a variational objective for model and proposal learning. SIXO yields provably tighter log marginal lower bounds and offers significantly more accurate posterior inferences and parameter estimates in a variety of domains.
Incorporating Customer Reviews in Size and Fit Recommendation systems for Fashion E-Commerce
Aug 11, 2022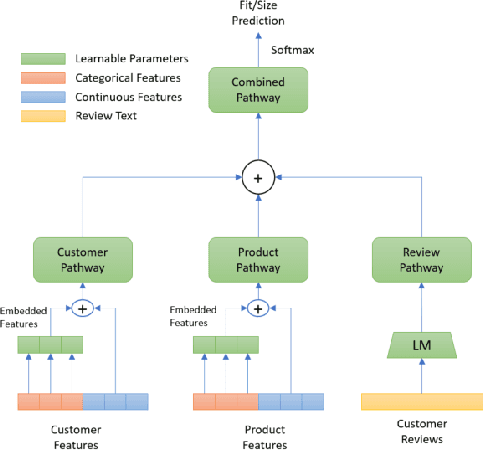


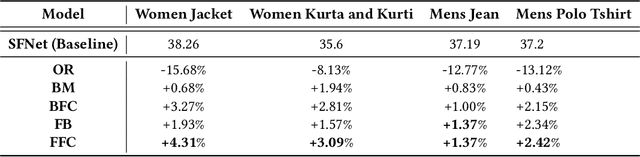
With the huge growth in e-commerce domain, product recommendations have become an increasing field of interest amongst e-commerce companies. One of the more difficult tasks in product recommendations is size and fit predictions. There are a lot of size related returns and refunds in e-fashion domain which causes inconvenience to the customers as well as costs the company. Thus having a good size and fit recommendation system, which can predict the correct sizes for the customers will not only reduce size related returns and refunds but also improve customer experience. Early works in this field used traditional machine learning approaches to estimate customer and product sizes from purchase history. These methods suffered from cold start problem due to huge sparsity in the customer-product data. More recently, people have used deep learning to address this problem by embedding customer and product features. But none of them incorporates valuable customer feedback present on product pages along with the customer and product features. We propose a novel approach which can use information from customer reviews along with customer and product features for size and fit predictions. We demonstrate the effectiveness of our approach compared to using just product and customer features on 4 datasets. Our method shows an improvement of 1.37% - 4.31% in F1 (macro) score over the baseline across the 4 different datasets.
Effective Few-Shot Named Entity Linking by Meta-Learning
Jul 12, 2022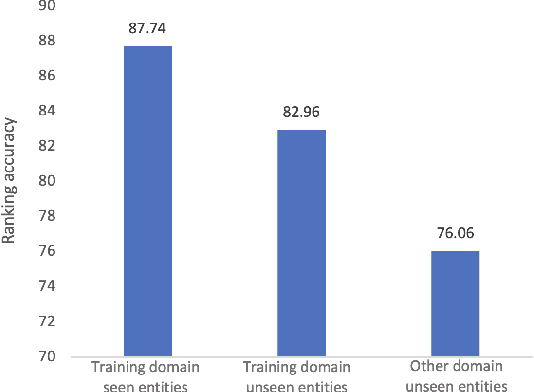
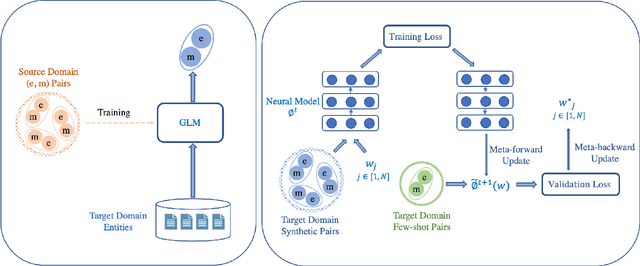
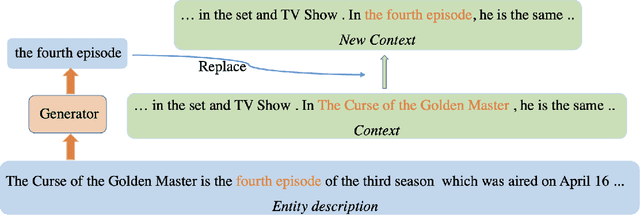
Entity linking aims to link ambiguous mentions to their corresponding entities in a knowledge base, which is significant and fundamental for various downstream applications, e.g., knowledge base completion, question answering, and information extraction. While great efforts have been devoted to this task, most of these studies follow the assumption that large-scale labeled data is available. However, when the labeled data is insufficient for specific domains due to labor-intensive annotation work, the performance of existing algorithms will suffer an intolerable decline. In this paper, we endeavor to solve the problem of few-shot entity linking, which only requires a minimal amount of in-domain labeled data and is more practical in real situations. Specifically, we firstly propose a novel weak supervision strategy to generate non-trivial synthetic entity-mention pairs based on mention rewriting. Since the quality of the synthetic data has a critical impact on effective model training, we further design a meta-learning mechanism to assign different weights to each synthetic entity-mention pair automatically. Through this way, we can profoundly exploit rich and precious semantic information to derive a well-trained entity linking model under the few-shot setting. The experiments on real-world datasets show that the proposed method can extensively improve the state-of-the-art few-shot entity linking model and achieve impressive performance when only a small amount of labeled data is available. Moreover, we also demonstrate the outstanding ability of the model's transferability.
Enhancing Dynamic Mode Decomposition Workflow with In-Situ Visualization and Data Compression
Aug 16, 2022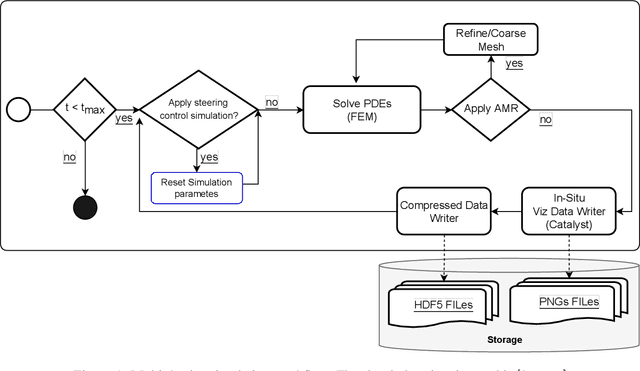

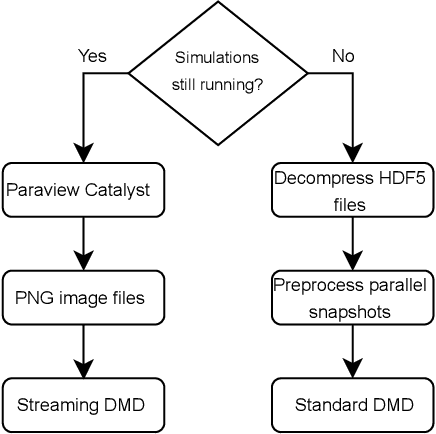
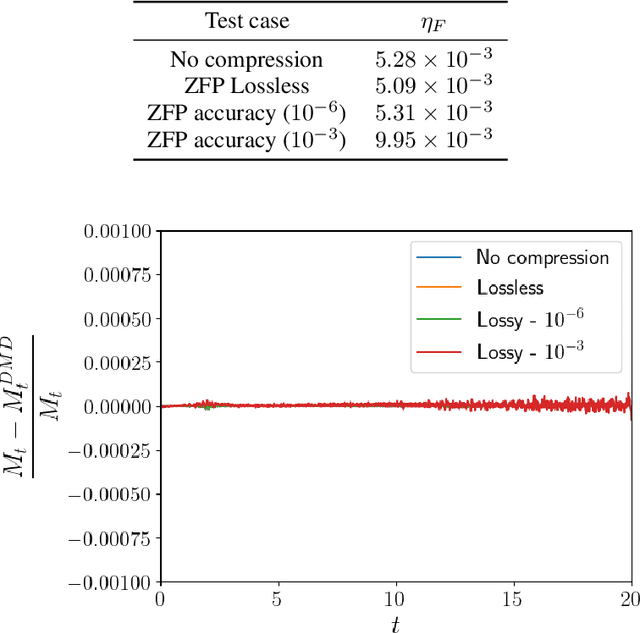
Modern computational science and engineering applications are being improved by the advances in scientific machine learning. Data-driven methods such as Dynamic Mode Decomposition (DMD) can extract coherent structures from spatio-temporal data generated from dynamical systems and infer different scenarios for said systems. The spatio-temporal data comes as snapshots containing spatial information for each time instant. In modern engineering applications, the generation of high-dimensional snapshots can be time and/or resource-demanding. In the present study, we consider two strategies for enhancing DMD workflow in large numerical simulations: (i) snapshots compression to relieve disk pressure; (ii) the use of in situ visualization images to reconstruct the dynamics (or part of) in runtime. We evaluate our approaches with two 3D fluid dynamics simulations and consider DMD to reconstruct the solutions. Results reveal that snapshot compression considerably reduces the required disk space. We have observed that lossy compression reduces storage by almost $50\%$ with low relative errors in the signal reconstructions and other quantities of interest. We also extend our analysis to data generated on-the-fly, using in-situ visualization tools to generate image files of our state vectors during runtime. On large simulations, the generation of snapshots may be slow enough to use batch algorithms for inference. Streaming DMD takes advantage of the incremental SVD algorithm and updates the modes with the arrival of each new snapshot. We use streaming DMD to reconstruct the dynamics from in-situ generated images. We show that this process is efficient, and the reconstructed dynamics are accurate.
Perfusion imaging in deep prostate cancer detection from mp-MRI: can we take advantage of it?
Jul 06, 2022

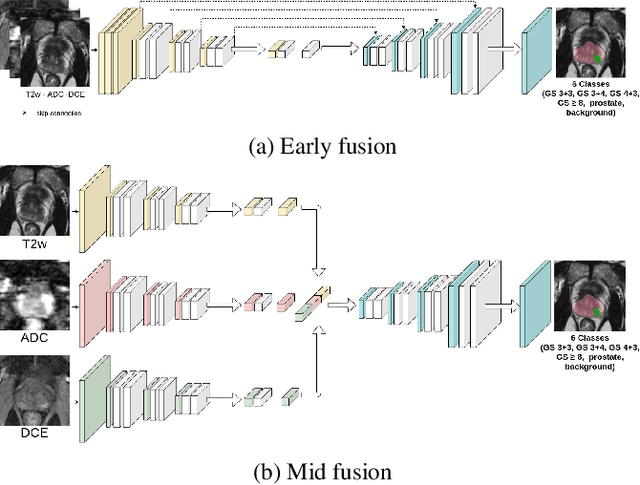
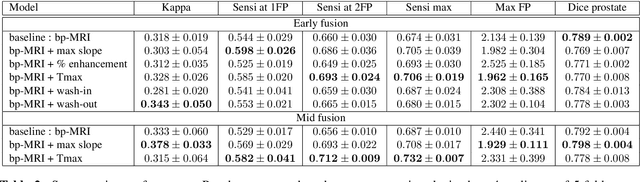
To our knowledge, all deep computer-aided detection and diagnosis (CAD) systems for prostate cancer (PCa) detection consider bi-parametric magnetic resonance imaging (bp-MRI) only, including T2w and ADC sequences while excluding the 4D perfusion sequence,which is however part of standard clinical protocols for this diagnostic task. In this paper, we question strategies to integrate information from perfusion imaging in deep neural architectures. To do so, we evaluate several ways to encode the perfusion information in a U-Net like architecture, also considering early versus mid fusion strategies. We compare performance of multiparametric MRI (mp-MRI) models with the baseline bp-MRI model based on a private dataset of 219 mp-MRI exams. Perfusion maps derived from dynamic contrast enhanced MR exams are shown to positively impact segmentation and grading performance of PCa lesions, especially the 3D MR volume corresponding to the maximum slope of the wash-in curve as well as Tmax perfusion maps. The latter mp-MRI models indeed outperform the bp-MRI one whatever the fusion strategy, with Cohen's kappa score of 0.318$\pm$0.019 for the bp-MRI model and 0.378 $\pm$ 0.033 for the model including the maximum slope with a mid fusion strategy, also achieving competitive Cohen's kappa score compared to state of the art.
Resilient Active Information Acquisition with Teams of Robots
Mar 17, 2021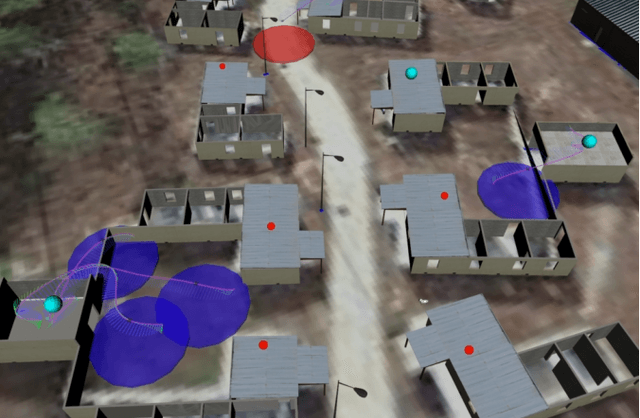
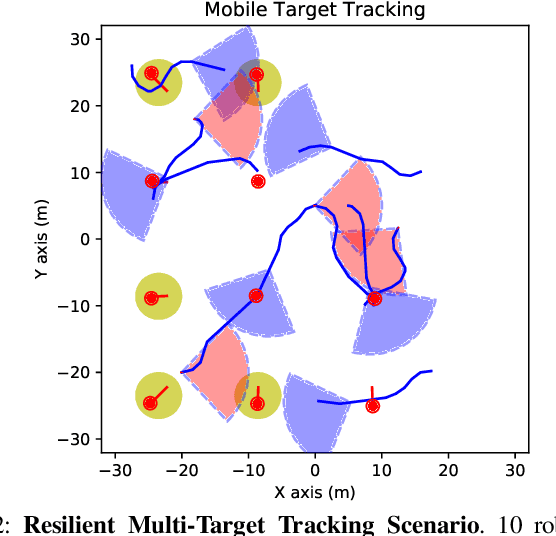
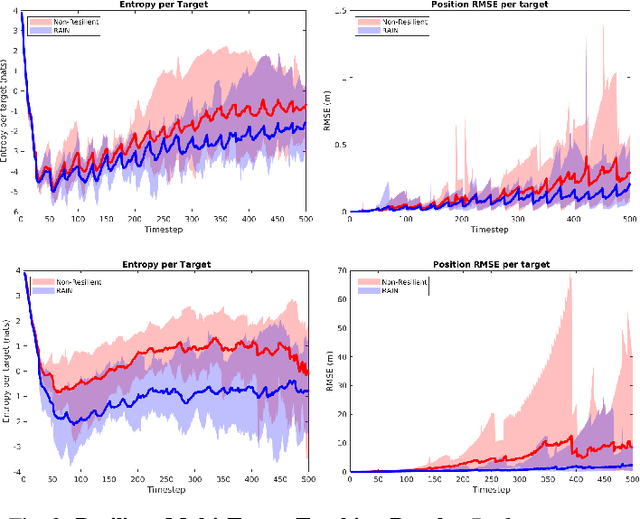
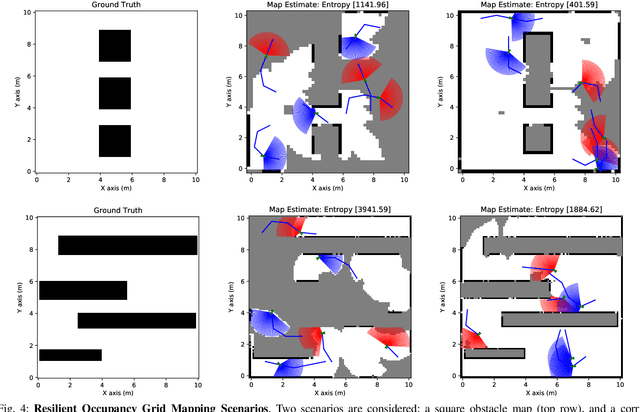
Emerging applications of collaborative autonomy, such as Multi-Target Tracking, Unknown Map Exploration, and Persistent Surveillance, require robots plan paths to navigate an environment while maximizing the information collected via on-board sensors. In this paper, we consider such information acquisition tasks but in adversarial environments, where attacks may temporarily disable the robots' sensors. We propose the first receding horizon algorithm, aiming for robust and adaptive multi-robot planning against any number of attacks, which we call Resilient Active Information acquisitioN (RAIN). RAIN calls, in an online fashion, a Robust Trajectory Planning (RTP) subroutine which plans attack-robust control inputs over a look-ahead planning horizon. We quantify RTP's performance by bounding its suboptimality. We base our theoretical analysis on notions of curvature introduced in combinatorial optimization. We evaluate RAIN in three information acquisition scenarios: Multi-Target Tracking, Occupancy Grid Mapping, and Persistent Surveillance. The scenarios are simulated in C++ and a Unity-based simulator. In all simulations, RAIN runs in real-time, and exhibits superior performance against a state-of-the-art baseline information acquisition algorithm, even in the presence of a high number of attacks. We also demonstrate RAIN's robustness and effectiveness against varying models of attacks (worst-case and random), as well as, varying replanning rates.
Improving Robustness and Accuracy via Relative Information Encoding in 3D Human Pose Estimation
Jul 29, 2021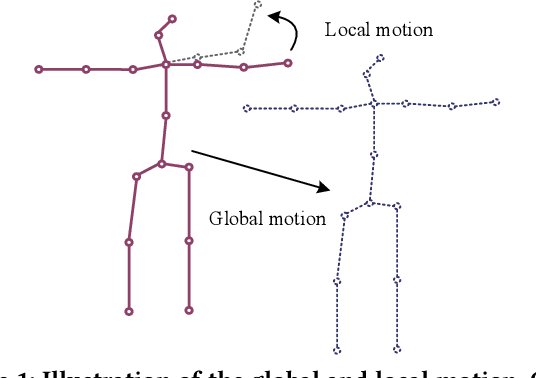
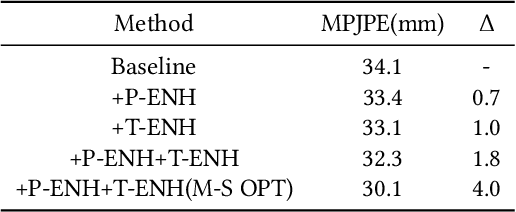
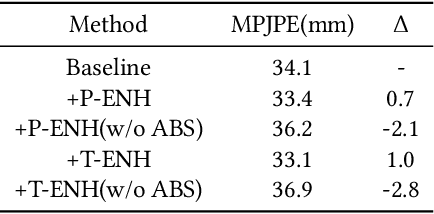
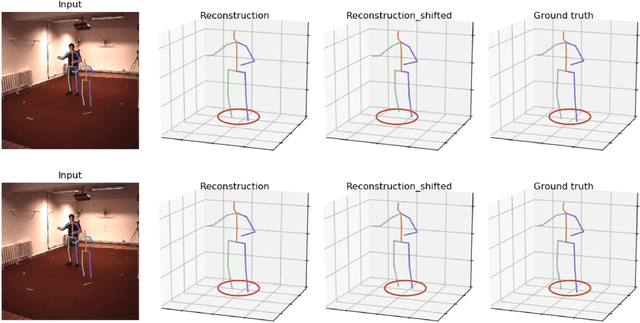
Most of the existing 3D human pose estimation approaches mainly focus on predicting 3D positional relationships between the root joint and other human joints (local motion) instead of the overall trajectory of the human body (global motion). Despite the great progress achieved by these approaches, they are not robust to global motion, and lack the ability to accurately predict local motion with a small movement range. To alleviate these two problems, we propose a relative information encoding method that yields positional and temporal enhanced representations. Firstly, we encode positional information by utilizing relative coordinates of 2D poses to enhance the consistency between the input and output distribution. The same posture with different absolute 2D positions can be mapped to a common representation. It is beneficial to resist the interference of global motion on the prediction results. Second, we encode temporal information by establishing the connection between the current pose and other poses of the same person within a period of time. More attention will be paid to the movement changes before and after the current pose, resulting in better prediction performance on local motion with a small movement range. The ablation studies validate the effectiveness of the proposed relative information encoding method. Besides, we introduce a multi-stage optimization method to the whole framework to further exploit the positional and temporal enhanced representations. Our method outperforms state-of-the-art methods on two public datasets. Code is available at https://github.com/paTRICK-swk/Pose3D-RIE.
MSP-Former: Multi-Scale Projection Transformer for Single Image Desnowing
Jul 17, 2022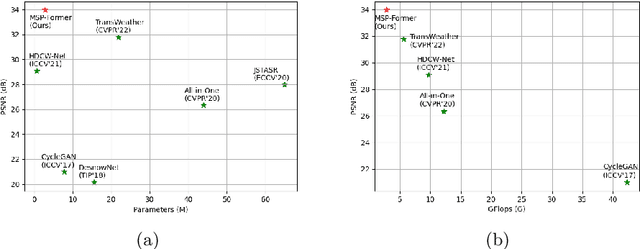
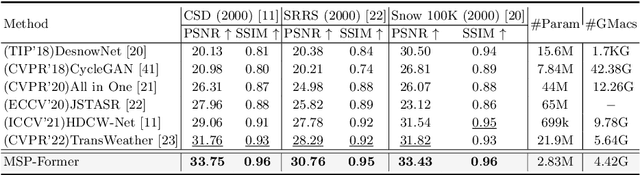

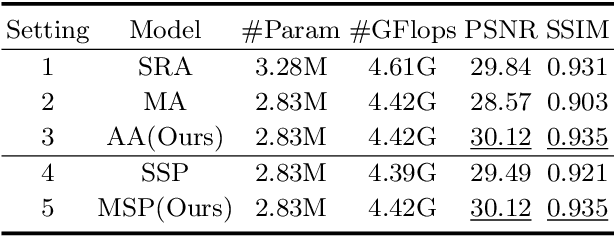
Image restoration of snow scenes in severe weather is a difficult task. Snow images have complex degradations and are cluttered over clean images, changing the distribution of clean images. The previous methods based on CNNs are challenging to remove perfectly in restoring snow scenes due to their local inductive biases' lack of a specific global modeling ability. In this paper, we apply the vision transformer to the task of snow removal from a single image. Specifically, we propose a parallel network architecture split along the channel, performing local feature refinement and global information modeling separately. We utilize a channel shuffle operation to combine their respective strengths to enhance network performance. Second, we propose the MSP module, which utilizes multi-scale avgpool to aggregate information of different sizes and simultaneously performs multi-scale projection self-attention on multi-head self-attention to improve the representation ability of the model under different scale degradations. Finally, we design a lightweight and simple local capture module, which can refine the local capture capability of the model. In the experimental part, we conduct extensive experiments to demonstrate the superiority of our method. We compared the previous snow removal methods on three snow scene datasets. The experimental results show that our method surpasses the state-of-the-art methods with fewer parameters and computation. We achieve substantial growth by 1.99dB and SSIM 0.03 on the CSD test dataset. On the SRRS and Snow100K datasets, we also increased PSNR by 2.47dB and 1.62dB compared with the Transweather approach and improved by 0.03 in SSIM. In the visual comparison section, our MSP-Former also achieves better visual effects than existing methods, proving the usability of our method.