 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On Feature Learning in the Presence of Spurious Correlations
Oct 20, 2022
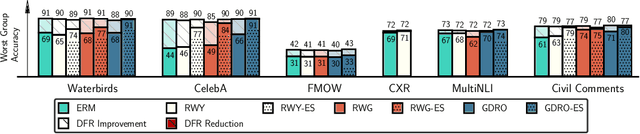
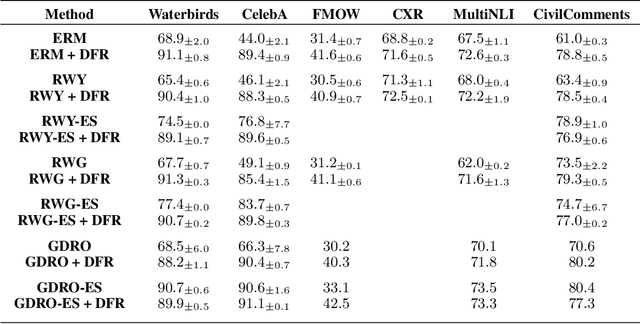
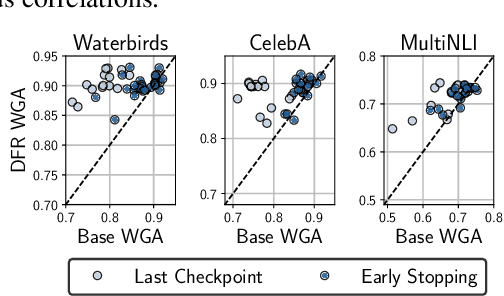
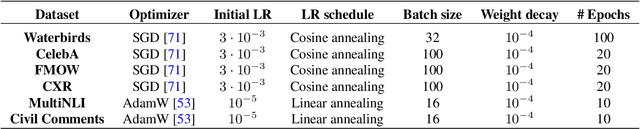
Deep classifiers are known to rely on spurious features $\unicode{x2013}$ patterns which are correlated with the target on the training data but not inherently relevant to the learning problem, such as the image backgrounds when classifying the foregrounds. In this paper we evaluate the amount of information about the core (non-spurious) features that can be decoded from the representations learned by standard empirical risk minimization (ERM) and specialized group robustness training. Following recent work on Deep Feature Reweighting (DFR), we evaluate the feature representations by re-training the last layer of the model on a held-out set where the spurious correlation is broken. On multiple vision and NLP problems, we show that the features learned by simple ERM are highly competitive with the features learned by specialized group robustness methods targeted at reducing the effect of spurious correlations. Moreover, we show that the quality of learned feature representations is greatly affected by the design decisions beyond the training method, such as the model architecture and pre-training strategy. On the other hand, we find that strong regularization is not necessary for learning high quality feature representations. Finally, using insights from our analysis, we significantly improve upon the best results reported in the literature on the popular Waterbirds, CelebA hair color prediction and WILDS-FMOW problems, achieving 97%, 92% and 50% worst-group accuracies, respectively.
Being Automated or Not? Risk Identification of Occupations with Graph Neural Networks
Sep 06, 2022
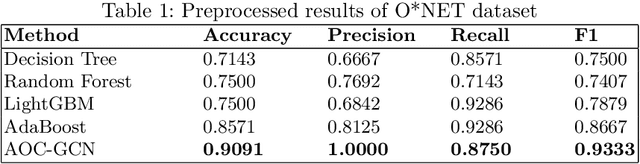
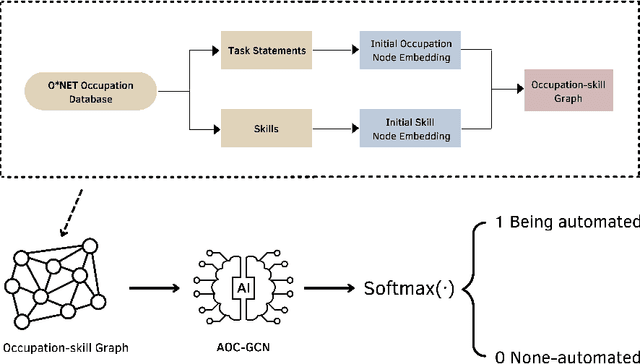

The rapid advances in automation technologies, such as artificial intelligence (AI) and robotics, pose an increasing risk of automation for occupations, with a likely significant impact on the labour market. Recent social-economic studies suggest that nearly 50\% of occupations are at high risk of being automated in the next decade. However, the lack of granular data and empirically informed models have limited the accuracy of these studies and made it challenging to predict which jobs will be automated. In this paper, we study the automation risk of occupations by performing a classification task between automated and non-automated occupations. The available information is 910 occupations' task statements, skills and interactions categorised by Standard Occupational Classification (SOC). To fully utilize this information, we propose a graph-based semi-supervised classification method named \textbf{A}utomated \textbf{O}ccupation \textbf{C}lassification based on \textbf{G}raph \textbf{C}onvolutional \textbf{N}etworks (\textbf{AOC-GCN}) to identify the automated risk for occupations. This model integrates a heterogeneous graph to capture occupations' local and global contexts. The results show that our proposed method outperforms the baseline models by considering the information of both internal features of occupations and their external interactions. This study could help policymakers identify potential automated occupations and support individuals' decision-making before entering the job market.
Don't Lose Yourself! Empathetic Response Generation via Explicit Self-Other Awareness
Oct 08, 2022
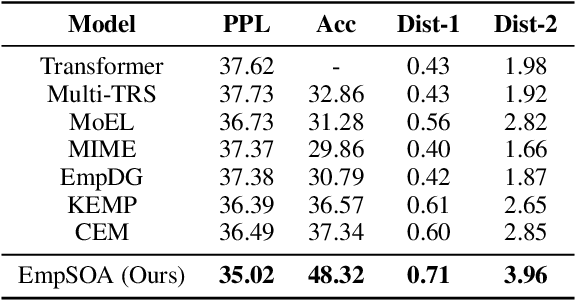
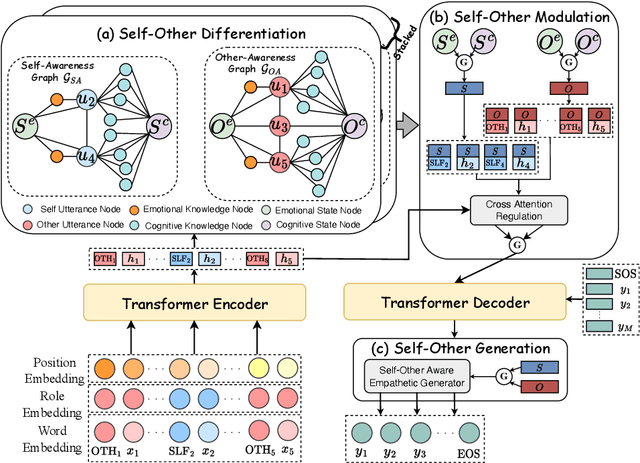
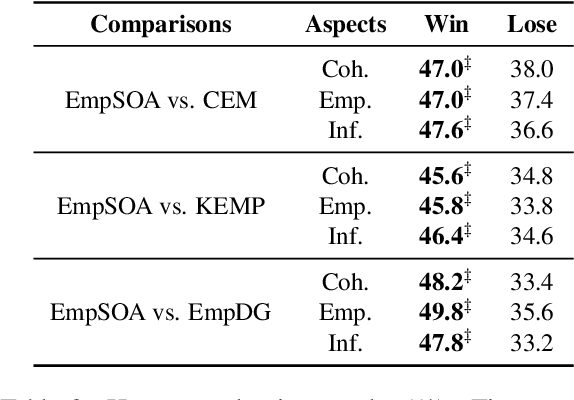
As a critical step to achieve human-like chatbots, empathetic response generation has attained increasing interests. Previous attempts are incomplete and not sufficient enough to elicit empathy because they only focus on the initial aspect of empathy to automatically mimic the feelings and thoughts of the user via other-awareness. However, they ignore to maintain and take the own views of the system into account, which is a crucial process to achieve the empathy called self-other awareness. To this end, we propose to generate Empathetic response with explicit Self-Other Awareness (EmpSOA). Specifically, three stages, self-other differentiation, self-other modulation and self-other generation, are devised to clearly maintain, regulate and inject the self-other aware information into the process of empathetic response generation. Both automatic and human evaluations on the benchmark dataset demonstrate the superiority of EmpSOA to generate more empathetic responses.
AI Explainability and Governance in Smart Energy Systems: A Review
Oct 24, 2022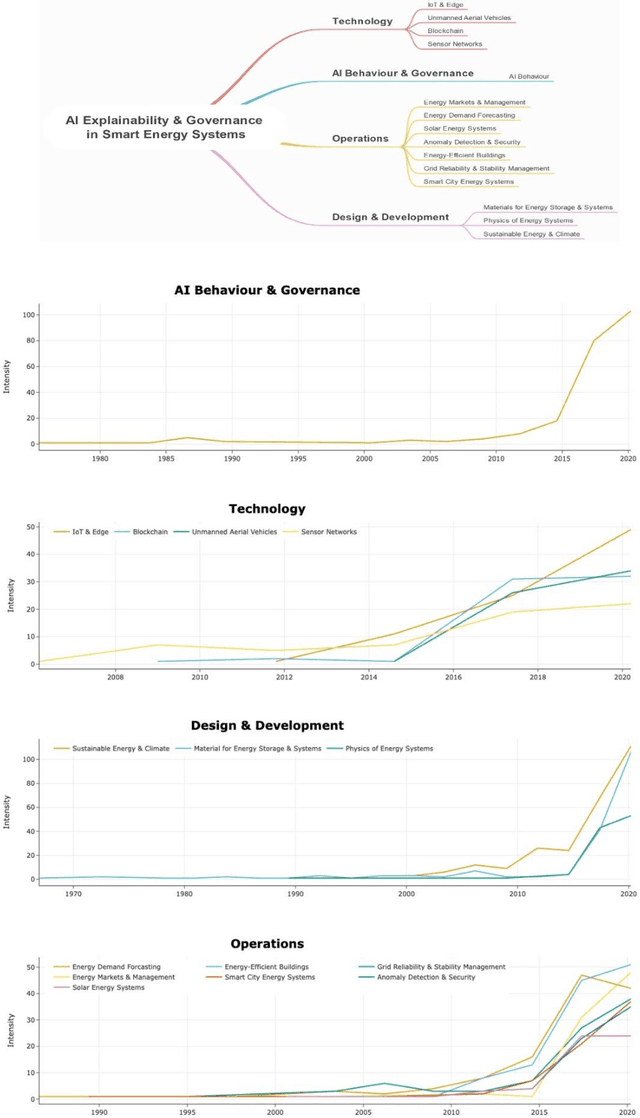
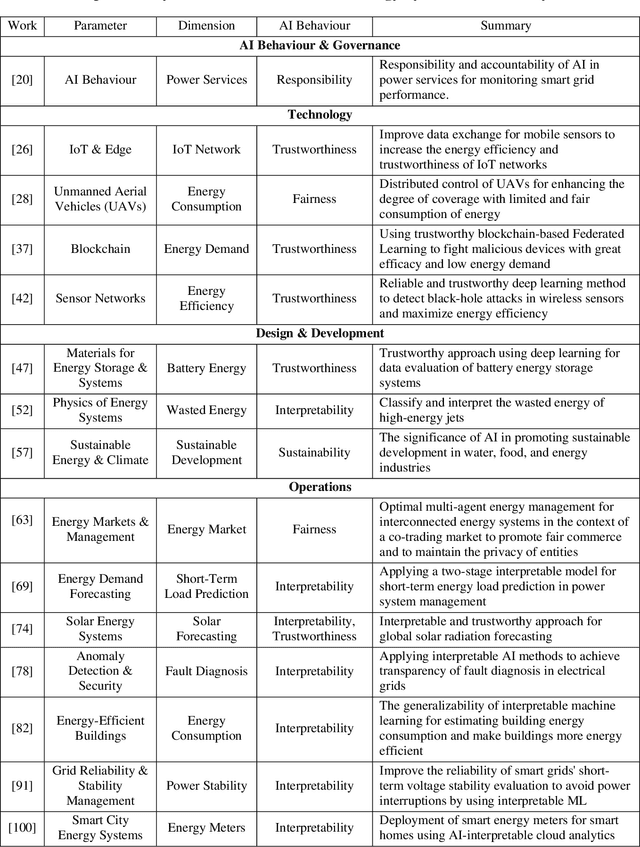
Traditional electrical power grids have long suffered from operational unreliability, instability, inflexibility, and inefficiency. Smart grids (or smart energy systems) continue to transform the energy sector with emerging technologies, renewable energy sources, and other trends. Artificial intelligence (AI) is being applied to smart energy systems to process massive and complex data in this sector and make smart and timely decisions. However, the lack of explainability and governability of AI is a major concern for stakeholders hindering a fast uptake of AI in the energy sector. This paper provides a review of AI explainability and governance in smart energy systems. We collect 3,568 relevant papers from the Scopus database, automatically discover 15 parameters or themes for AI governance in energy and elaborate the research landscape by reviewing over 100 papers and providing temporal progressions of the research. The methodology for discovering parameters or themes is based on "deep journalism", our data-driven deep learning-based big data analytics approach to automatically discover and analyse cross-sectional multi-perspective information to enable better decision-making and develop better instruments for governance. The findings show that research on AI explainability in energy systems is segmented and narrowly focussed on a few AI traits and energy system problems. This paper deepens our knowledge of AI governance in energy and is expected to help governments, industry, academics, energy prosumers, and other stakeholders to understand the landscape of AI in the energy sector, leading to better design, operations, utilisation, and risk management of energy systems.
UDoc-GAN: Unpaired Document Illumination Correction with Background Light Prior
Oct 15, 2022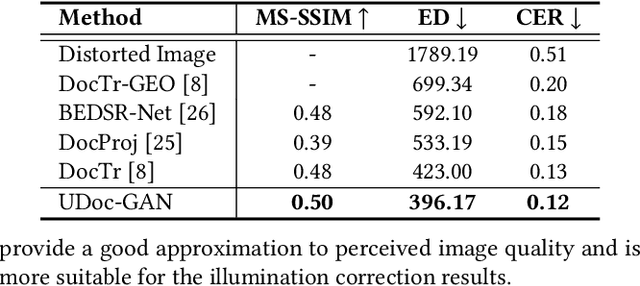
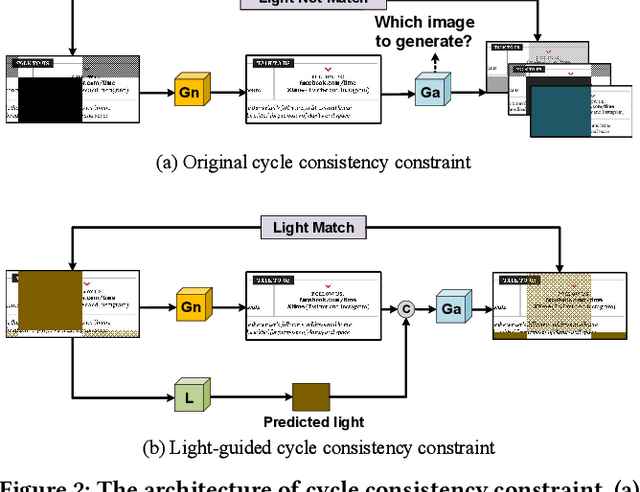
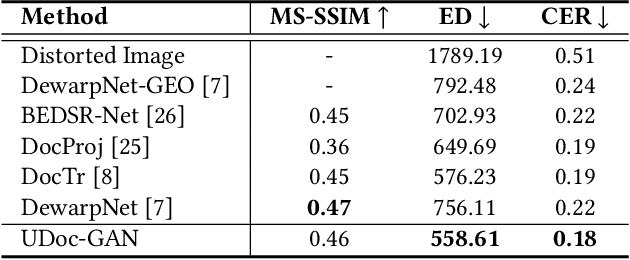
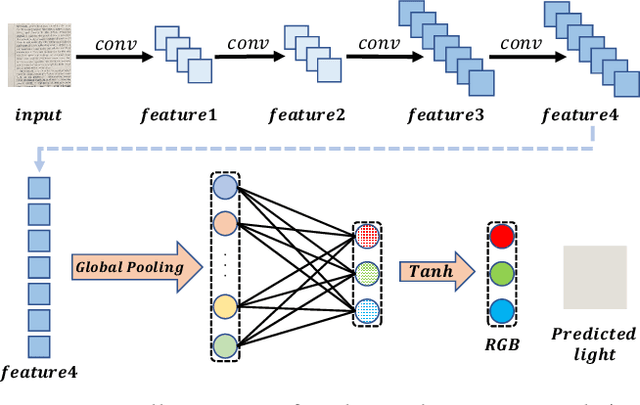
Document images captured by mobile devices are usually degraded by uncontrollable illumination, which hampers the clarity of document content. Recently, a series of research efforts have been devoted to correcting the uneven document illumination. However, existing methods rarely consider the use of ambient light information, and usually rely on paired samples including degraded and the corrected ground-truth images which are not always accessible. To this end, we propose UDoc-GAN, the first framework to address the problem of document illumination correction under the unpaired setting. Specifically, we first predict the ambient light features of the document. Then, according to the characteristics of different level of ambient lights, we re-formulate the cycle consistency constraint to learn the underlying relationship between normal and abnormal illumination domains. To prove the effectiveness of our approach, we conduct extensive experiments on DocProj dataset under the unpaired setting. Compared with the state-of-the-art approaches, our method demonstrates promising performance in terms of character error rate (CER) and edit distance (ED), together with better qualitative results for textual detail preservation. The source code is now publicly available at https://github.com/harrytea/UDoc-GAN.
Revisiting the Roles of "Text" in Text Games
Oct 15, 2022
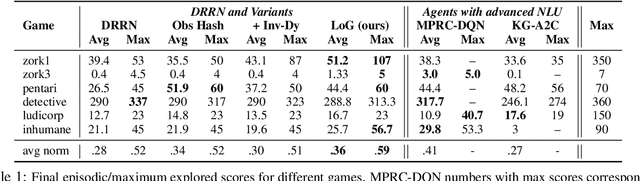
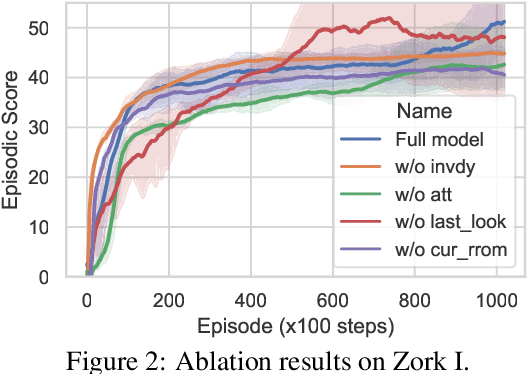
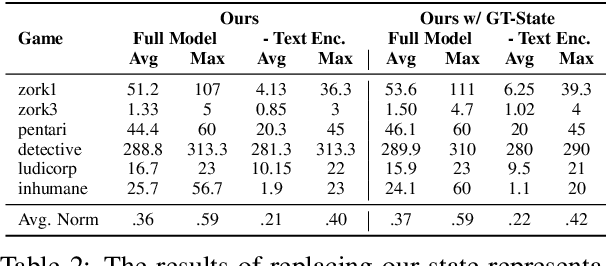
Text games present opportunities for natural language understanding (NLU) methods to tackle reinforcement learning (RL) challenges. However, recent work has questioned the necessity of NLU by showing random text hashes could perform decently. In this paper, we pursue a fine-grained investigation into the roles of text in the face of different RL challenges, and reconcile that semantic and non-semantic language representations could be complementary rather than contrasting. Concretely, we propose a simple scheme to extract relevant contextual information into an approximate state hash as extra input for an RNN-based text agent. Such a lightweight plug-in achieves competitive performance with state-of-the-art text agents using advanced NLU techniques such as knowledge graph and passage retrieval, suggesting non-NLU methods might suffice to tackle the challenge of partial observability. However, if we remove RNN encoders and use approximate or even ground-truth state hash alone, the model performs miserably, which confirms the importance of semantic function approximation to tackle the challenge of combinatorially large observation and action spaces. Our findings and analysis provide new insights for designing better text game task setups and agents.
Classification of Web Phishing Kits for early detection by platform providers
Oct 15, 2022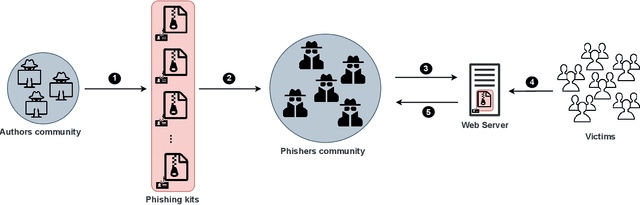
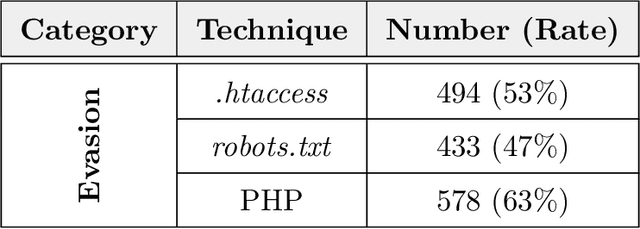

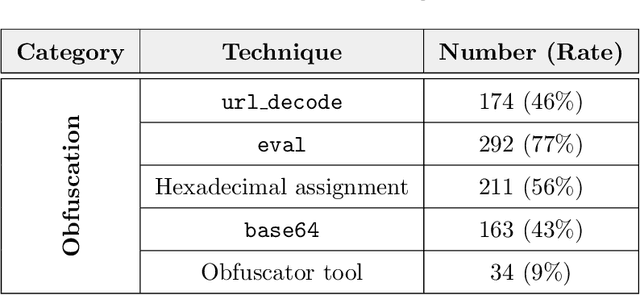
Phishing kits are tools that dark side experts provide to the community of criminal phishers to facilitate the construction of malicious Web sites. As these kits evolve in sophistication, providers of Web-based services need to keep pace with continuous complexity. We present an original classification of a corpus of over 2000 recent phishing kits according to their adopted evasion and obfuscation functions. We carry out an initial deterministic analysis of the source code of the kits to extract the most discriminant features and information about their principal authors. We then integrate this initial classification through supervised machine learning models. Thanks to the ground-truth achieved in the first step, we can demonstrate whether and which machine learning models are able to suitably classify even the kits adopting novel evasion and obfuscation techniques that were unseen during the training phase. We compare different algorithms and evaluate their robustness in the realistic case in which only a small number of phishing kits are available for training. This paper represents an initial but important step to support Web service providers and analysts in improving early detection mechanisms and intelligence operations for the phishing kits that might be installed on their platforms.
Evolving Neural Networks with Optimal Balance between Information Flow and Connections Cost
Feb 16, 2022
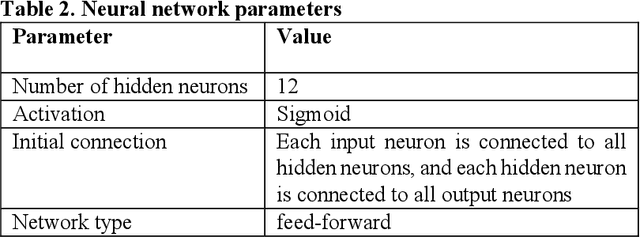
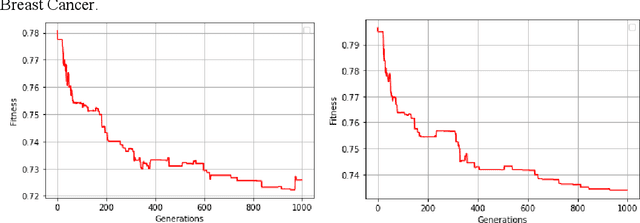
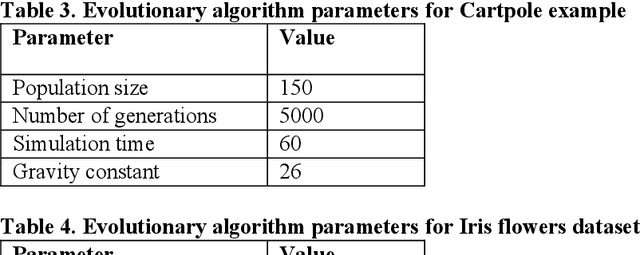
Evolving Neural Networks (NNs) has recently seen an increasing interest as an alternative path that might be more successful. It has many advantages compared to other approaches, such as learning the architecture of the NNs. However, the extremely large search space and the existence of many complex interacting parts still represent a major obstacle. Many criteria were recently investigated to help guide the algorithm and to cut down the large search space. Recently there has been growing research bringing insights from network science to improve the design of NNs. In this paper, we investigate evolving NNs architectures that have one of the most fundamental characteristics of real-world networks, namely the optimal balance between connections cost and information flow. The performance of different metrics that represent this balance is evaluated and the improvement in the accuracy of putting more selection pressure toward this balance is demonstrated on three datasets.
Deep Molecular Representation Learning via Fusing Physical and Chemical Information
Nov 28, 2021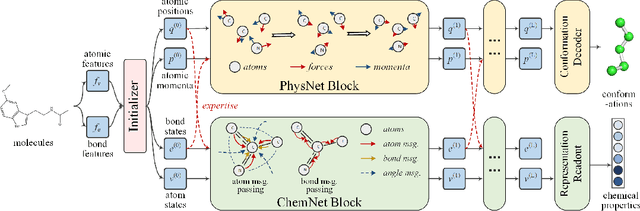
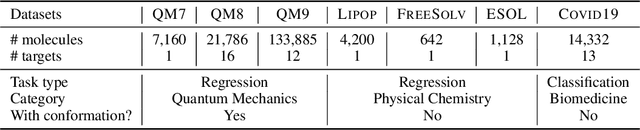
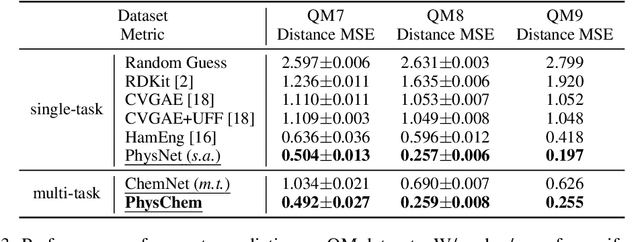
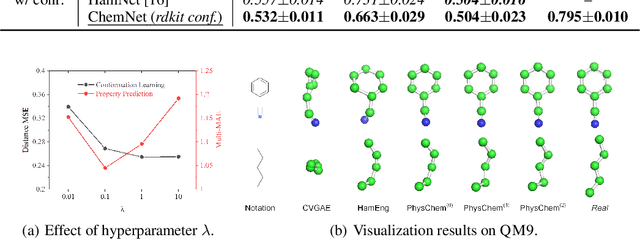
Molecular representation learning is the first yet vital step in combining deep learning and molecular science. To push the boundaries of molecular representation learning, we present PhysChem, a novel neural architecture that learns molecular representations via fusing physical and chemical information of molecules. PhysChem is composed of a physicist network (PhysNet) and a chemist network (ChemNet). PhysNet is a neural physical engine that learns molecular conformations through simulating molecular dynamics with parameterized forces; ChemNet implements geometry-aware deep message-passing to learn chemical / biomedical properties of molecules. Two networks specialize in their own tasks and cooperate by providing expertise to each other. By fusing physical and chemical information, PhysChem achieved state-of-the-art performances on MoleculeNet, a standard molecular machine learning benchmark. The effectiveness of PhysChem was further corroborated on cutting-edge datasets of SARS-CoV-2.
Word to Sentence Visual Semantic Similarity for Caption Generation: Lessons Learned
Sep 26, 2022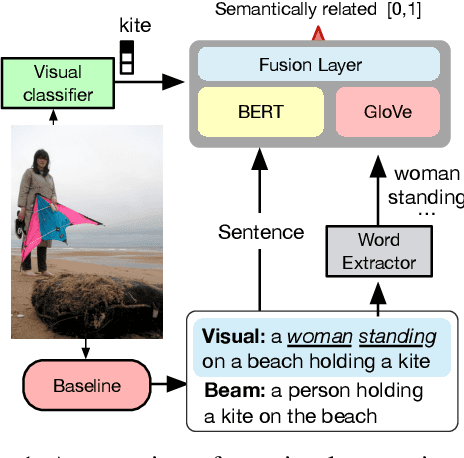
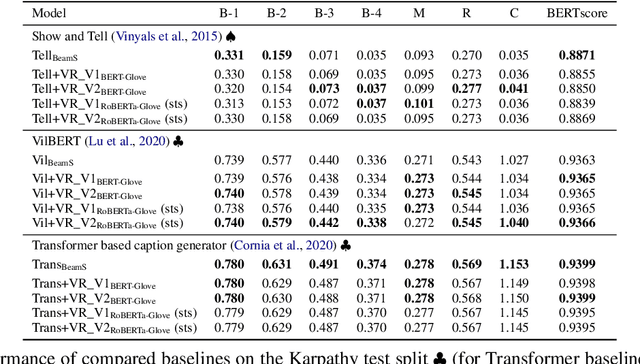
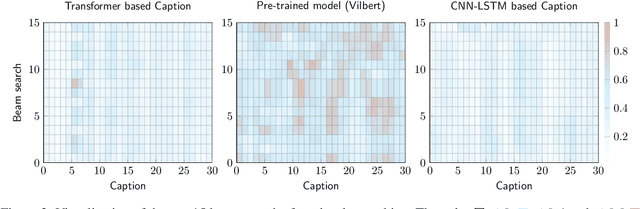
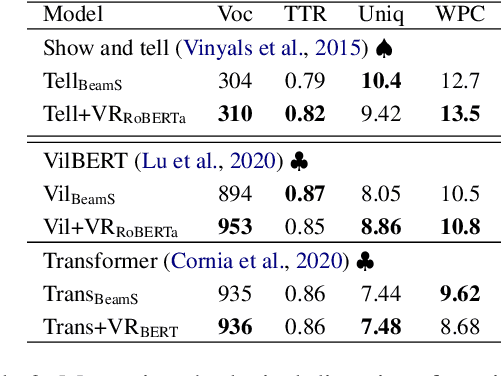
This paper focuses on enhancing the captions generated by image-caption generation systems. We propose an approach for improving caption generation systems by choosing the most closely related output to the image rather than the most likely output produced by the model. Our model revises the language generation output beam search from a visual context perspective. We employ a visual semantic measure in a word and sentence level manner to match the proper caption to the related information in the image. The proposed approach can be applied to any caption system as a post-processing based method.