 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLeAN: Continual Learning Adaptive Normalization in Dynamic Environments
Mar 18, 2026Artificial intelligence systems predominantly rely on static data distributions, making them ineffective in dynamic real-world environments, such as cybersecurity, autonomous transportation, or finance, where data shifts frequently. Continual learning offers a potential solution by enabling models to learn from sequential data while retaining prior knowledge. However, a critical and underexplored issue in this domain is data normalization. Conventional normalization methods, such as min-max scaling, presuppose access to the entire dataset, which is incongruent with the sequential nature of continual learning. In this paper we introduce Continual Learning Adaptive Normalization (CLeAN), a novel adaptive normalization technique designed for continual learning in tabular data. CLeAN involves the estimation of global feature scales using learnable parameters that are updated via an Exponential Moving Average (EMA) module, enabling the model to adapt to evolving data distributions. Through comprehensive evaluations on two datasets and various continual learning strategies, including Resevoir Experience Replay, A-GEM, and EwC we demonstrate that CLeAN not only improves model performance on new data but also mitigates catastrophic forgetting. The findings underscore the importance of adaptive normalization in enhancing the stability and effectiveness of tabular data, offering a novel perspective on the use of normalization to preserve knowledge in dynamic learning environments.
Evaluating Adversarial Attacks on Federated Learning for Temperature Forecasting
Dec 16, 2025Deep learning and federated learning (FL) are becoming powerful partners for next-generation weather forecasting. Deep learning enables high-resolution spatiotemporal forecasts that can surpass traditional numerical models, while FL allows institutions in different locations to collaboratively train models without sharing raw data, addressing efficiency and security concerns. While FL has shown promise across heterogeneous regions, its distributed nature introduces new vulnerabilities. In particular, data poisoning attacks, in which compromised clients inject manipulated training data, can degrade performance or introduce systematic biases. These threats are amplified by spatial dependencies in meteorological data, allowing localized perturbations to influence broader regions through global model aggregation. In this study, we investigate how adversarial clients distort federated surface temperature forecasts trained on the Copernicus European Regional ReAnalysis (CERRA) dataset. We simulate geographically distributed clients and evaluate patch-based and global biasing attacks on regional temperature forecasts. Our results show that even a small fraction of poisoned clients can mislead predictions across large, spatially connected areas. A global temperature bias attack from a single compromised client shifts predictions by up to -1.7 K, while coordinated patch attacks more than triple the mean squared error and produce persistent regional anomalies exceeding +3.5 K. Finally, we assess trimmed mean aggregation as a defense mechanism, showing that it successfully defends against global bias attacks (2-13% degradation) but fails against patch attacks (281-603% amplification), exposing limitations of outlier-based defenses for spatially correlated data.
Classification of Web Phishing Kits for early detection by platform providers
Oct 15, 2022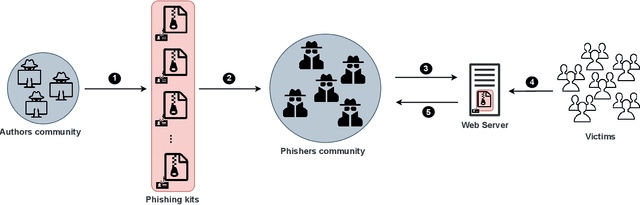
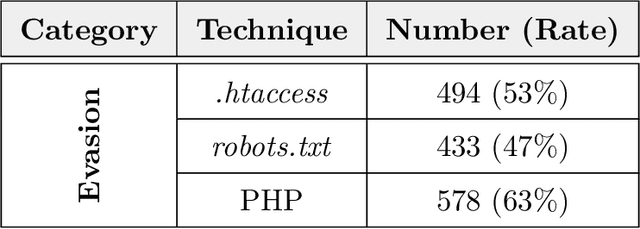

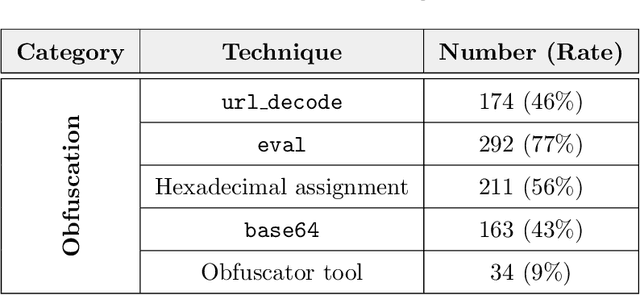
Phishing kits are tools that dark side experts provide to the community of criminal phishers to facilitate the construction of malicious Web sites. As these kits evolve in sophistication, providers of Web-based services need to keep pace with continuous complexity. We present an original classification of a corpus of over 2000 recent phishing kits according to their adopted evasion and obfuscation functions. We carry out an initial deterministic analysis of the source code of the kits to extract the most discriminant features and information about their principal authors. We then integrate this initial classification through supervised machine learning models. Thanks to the ground-truth achieved in the first step, we can demonstrate whether and which machine learning models are able to suitably classify even the kits adopting novel evasion and obfuscation techniques that were unseen during the training phase. We compare different algorithms and evaluate their robustness in the realistic case in which only a small number of phishing kits are available for training. This paper represents an initial but important step to support Web service providers and analysts in improving early detection mechanisms and intelligence operations for the phishing kits that might be installed on their platforms.
Hardening Random Forest Cyber Detectors Against Adversarial Attacks
Dec 09, 2019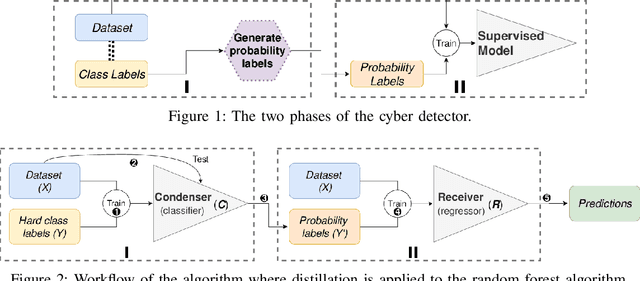
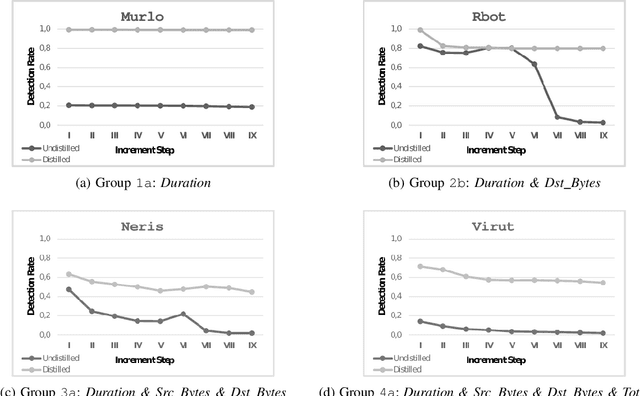
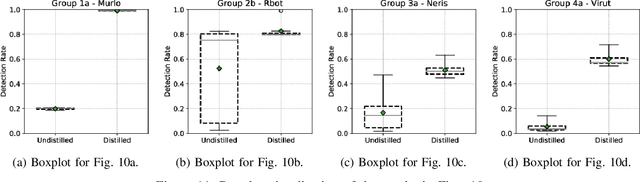
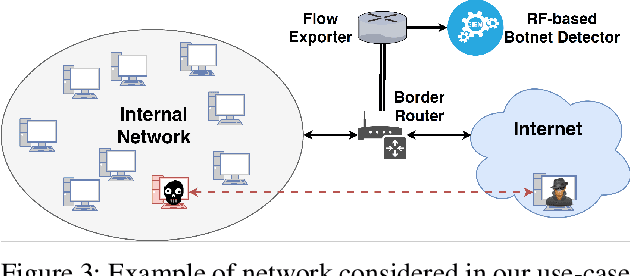
Machine learning algorithms are effective in several applications, but they are not as much successful when applied to intrusion detection in cyber security. Due to the high sensitivity to their training data, cyber detectors based on machine learning are vulnerable to targeted adversarial attacks that involve the perturbation of initial samples. Existing defenses assume unrealistic scenarios; their results are underwhelming in non-adversarial settings; or they can be applied only to machine learning algorithms that perform poorly for cyber security. We present an original methodology for countering adversarial perturbations targeting intrusion detection systems based on random forests. As a practical application, we integrate the proposed defense method in a cyber detector analyzing network traffic. The experimental results on millions of labelled network flows show that the new detector has a twofold value: it outperforms state-of-the-art detectors that are subject to adversarial attacks; it exhibits robust results both in adversarial and non-adversarial scenarios.