 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic Review on Reinforcement Learning in the Field of Fintech
Apr 29, 2023Applications of Reinforcement Learning in the Finance Technology (Fintech) have acquired a lot of admiration lately. Undoubtedly Reinforcement Learning, through its vast competence and proficiency, has aided remarkable results in the field of Fintech. The objective of this systematic survey is to perform an exploratory study on a correlation between reinforcement learning and Fintech to highlight the prediction accuracy, complexity, scalability, risks, profitability and performance. Major uses of reinforcement learning in finance or Fintech include portfolio optimization, credit risk reduction, investment capital management, profit maximization, effective recommendation systems, and better price setting strategies. Several studies have addressed the actual contribution of reinforcement learning to the performance of financial institutions. The latest studies included in this survey are publications from 2018 onward. The survey is conducted using PRISMA technique which focuses on the reporting of reviews and is based on a checklist and four-phase flow diagram. The conducted survey indicates that the performance of RL-based strategies in Fintech fields proves to perform considerably better than other state-of-the-art algorithms. The present work discusses the use of reinforcement learning algorithms in diverse decision-making challenges in Fintech and concludes that the organizations dealing with finance can benefit greatly from Robo-advising, smart order channelling, market making, hedging and options pricing, portfolio optimization, and optimal execution.
Multi-generational labour markets: data-driven discovery of multi-perspective system parameters using machine learning
Feb 20, 2023Economic issues, such as inflation, energy costs, taxes, and interest rates, are a constant presence in our daily lives and have been exacerbated by global events such as pandemics, environmental disasters, and wars. A sustained history of financial crises reveals significant weaknesses and vulnerabilities in the foundations of modern economies. Another significant issue currently is people quitting their jobs in large numbers. Moreover, many organizations have a diverse workforce comprising multiple generations posing new challenges. Transformative approaches in economics and labour markets are needed to protect our societies, economies, and planet. In this work, we use big data and machine learning methods to discover multi-perspective parameters for multi-generational labour markets. The parameters for the academic perspective are discovered using 35,000 article abstracts from the Web of Science for the period 1958-2022 and for the professionals' perspective using 57,000 LinkedIn posts from 2022. We discover a total of 28 parameters and categorised them into 5 macro-parameters, Learning & Skills, Employment Sectors, Consumer Industries, Learning & Employment Issues, and Generations-specific Issues. A complete machine learning software tool is developed for data-driven parameter discovery. A variety of quantitative and visualisation methods are applied and multiple taxonomies are extracted to explore multi-generational labour markets. A knowledge structure and literature review of multi-generational labour markets using over 100 research articles is provided. It is expected that this work will enhance the theory and practice of AI-based methods for knowledge discovery and system parameter discovery to develop autonomous capabilities and systems and promote novel approaches to labour economics and markets, leading to the development of sustainable societies and economies.
AI Explainability and Governance in Smart Energy Systems: A Review
Oct 24, 2022Traditional electrical power grids have long suffered from operational unreliability, instability, inflexibility, and inefficiency. Smart grids (or smart energy systems) continue to transform the energy sector with emerging technologies, renewable energy sources, and other trends. Artificial intelligence (AI) is being applied to smart energy systems to process massive and complex data in this sector and make smart and timely decisions. However, the lack of explainability and governability of AI is a major concern for stakeholders hindering a fast uptake of AI in the energy sector. This paper provides a review of AI explainability and governance in smart energy systems. We collect 3,568 relevant papers from the Scopus database, automatically discover 15 parameters or themes for AI governance in energy and elaborate the research landscape by reviewing over 100 papers and providing temporal progressions of the research. The methodology for discovering parameters or themes is based on "deep journalism", our data-driven deep learning-based big data analytics approach to automatically discover and analyse cross-sectional multi-perspective information to enable better decision-making and develop better instruments for governance. The findings show that research on AI explainability in energy systems is segmented and narrowly focussed on a few AI traits and energy system problems. This paper deepens our knowledge of AI governance in energy and is expected to help governments, industry, academics, energy prosumers, and other stakeholders to understand the landscape of AI in the energy sector, leading to better design, operations, utilisation, and risk management of energy systems.
Potrika: Raw and Balanced Newspaper Datasets in the Bangla Language with Eight Topics and Five Attributes
Oct 17, 2022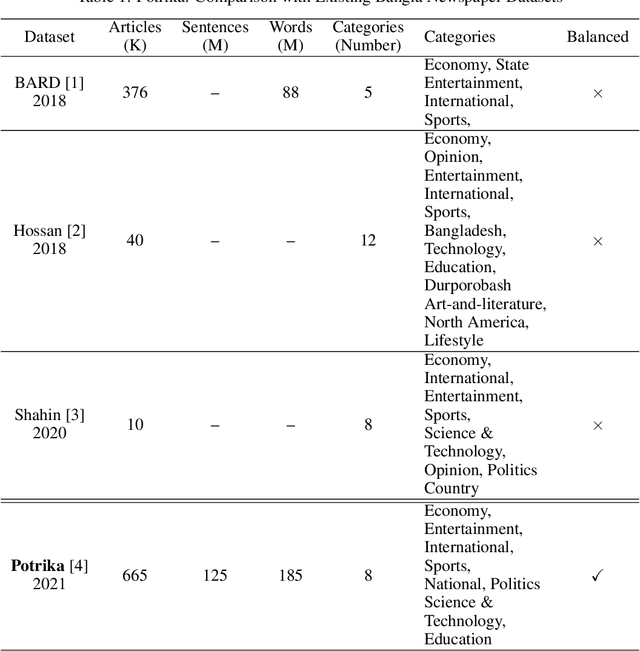
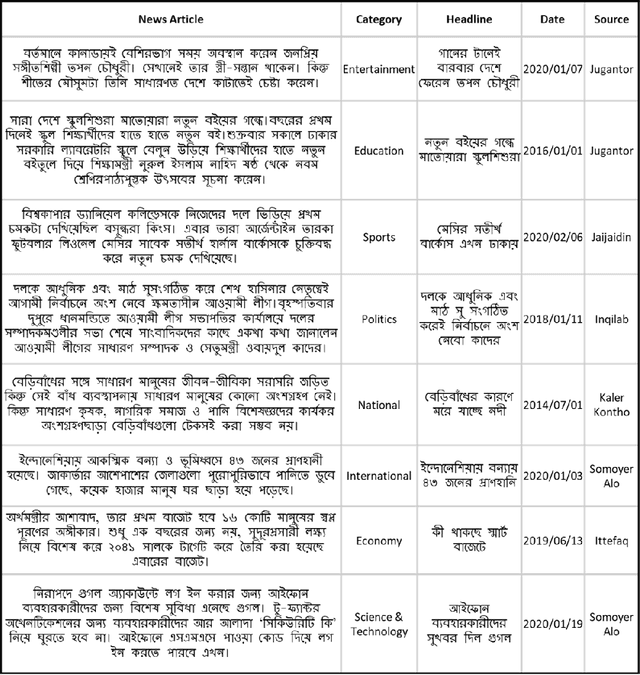
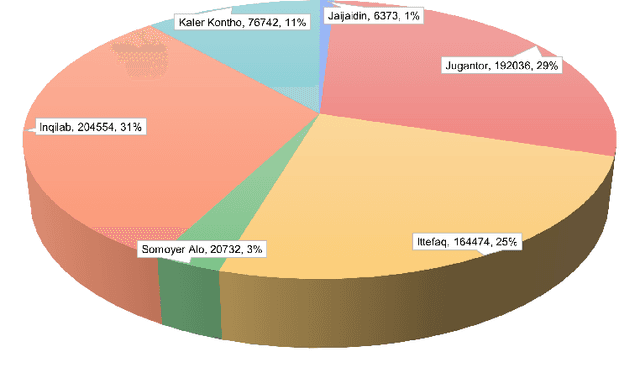
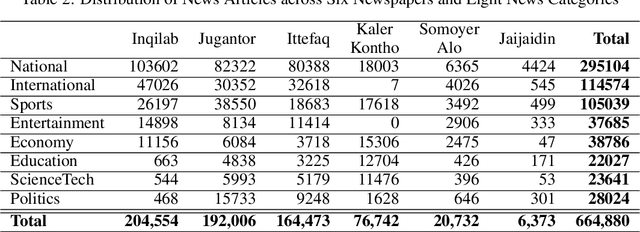
Knowledge is central to human and scientific developments. Natural Language Processing (NLP) allows automated analysis and creation of knowledge. Data is a crucial NLP and machine learning ingredient. The scarcity of open datasets is a well-known problem in machine and deep learning research. This is very much the case for textual NLP datasets in English and other major world languages. For the Bangla language, the situation is even more challenging and the number of large datasets for NLP research is practically nil. We hereby present Potrika, a large single-label Bangla news article textual dataset curated for NLP research from six popular online news portals in Bangladesh (Jugantor, Jaijaidin, Ittefaq, Kaler Kontho, Inqilab, and Somoyer Alo) for the period 2014-2020. The articles are classified into eight distinct categories (National, Sports, International, Entertainment, Economy, Education, Politics, and Science \& Technology) providing five attributes (News Article, Category, Headline, Publication Date, and Newspaper Source). The raw dataset contains 185.51 million words and 12.57 million sentences contained in 664,880 news articles. Moreover, using NLP augmentation techniques, we create from the raw (unbalanced) dataset another (balanced) dataset comprising 320,000 news articles with 40,000 articles in each of the eight news categories. Potrika contains both the datasets (raw and balanced) to suit a wide range of NLP research. By far, to the best of our knowledge, Potrika is the largest and the most extensive dataset for news classification.