 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FAMIE: A Fast Active Learning Framework for Multilingual Information Extraction
Feb 16, 2022
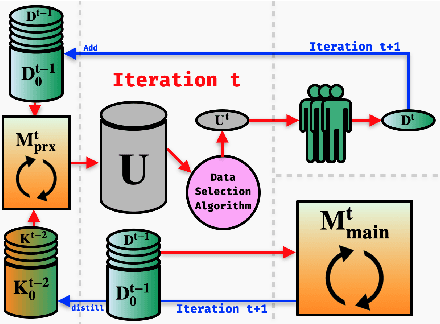

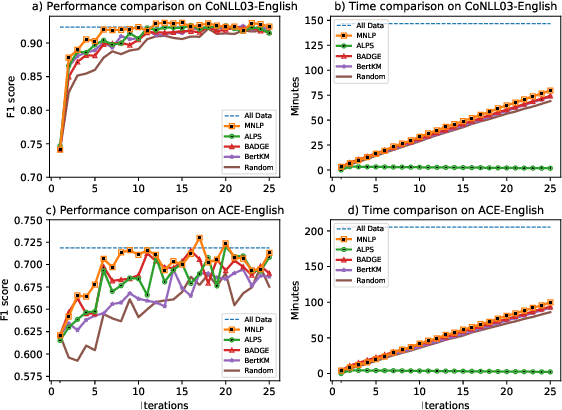

This paper presents FAMIE, a comprehensive and efficient active learning (AL) toolkit for multilingual information extraction. FAMIE is designed to address a fundamental problem in existing AL frameworks where annotators need to wait for a long time between annotation batches due to the time-consuming nature of model training and data selection at each AL iteration. This hinders the engagement, productivity, and efficiency of annotators. Based on the idea of using a small proxy network for fast data selection, we introduce a novel knowledge distillation mechanism to synchronize the proxy network with the main large model (i.e., BERT-based) to ensure the appropriateness of the selected annotation examples for the main model. Our AL framework can support multiple languages. The experiments demonstrate the advantages of FAMIE in terms of competitive performance and time efficiency for sequence labeling with AL. We publicly release our code (\url{https://github.com/nlp-uoregon/famie}) and demo website (\url{http://nlp.uoregon.edu:9000/}). A demo video for FAMIE is provided at: \url{https://youtu.be/I2i8n_jAyrY}.
ViLPAct: A Benchmark for Compositional Generalization on Multimodal Human Activities
Oct 11, 2022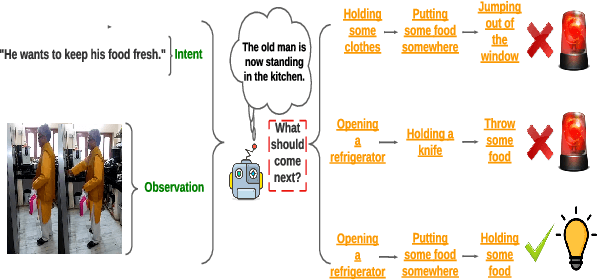
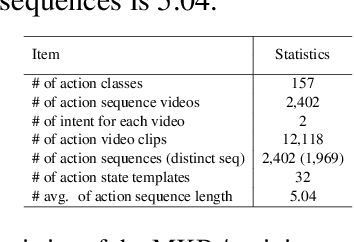
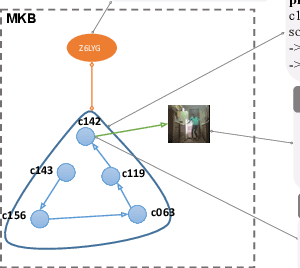

We introduce ViLPAct, a novel vision-language benchmark for human activity planning. It is designed for a task where embodied AI agents can reason and forecast future actions of humans based on video clips about their initial activities and intents in text. The dataset consists of 2.9k videos from \charades extended with intents via crowdsourcing, a multi-choice question test set, and four strong baselines. One of the baselines implements a neurosymbolic approach based on a multi-modal knowledge base (MKB), while the other ones are deep generative models adapted from recent state-of-the-art (SOTA) methods. According to our extensive experiments, the key challenges are compositional generalization and effective use of information from both modalities.
Broad-persistent Advice for Interactive Reinforcement Learning Scenarios
Oct 11, 2022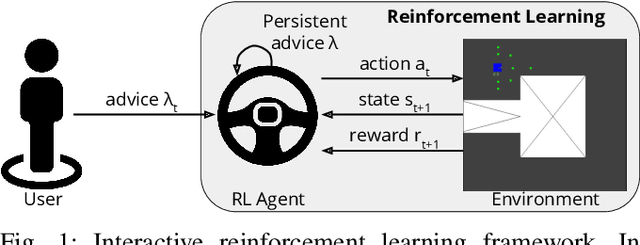
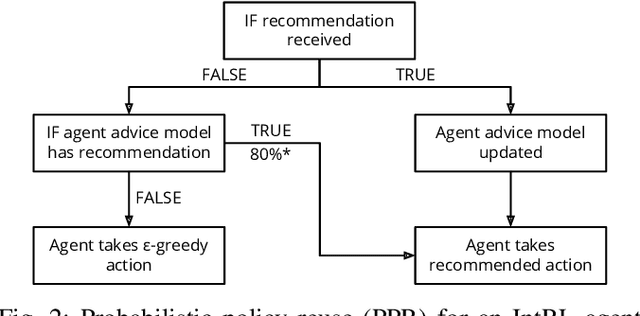
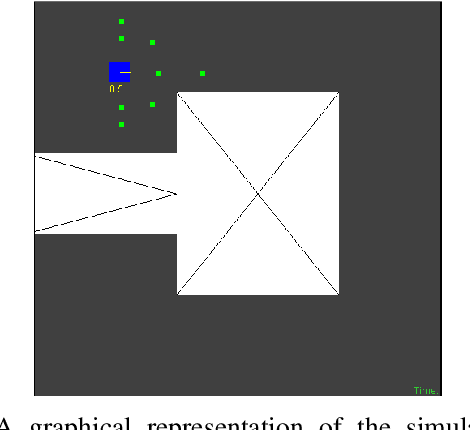

The use of interactive advice in reinforcement learning scenarios allows for speeding up the learning process for autonomous agents. Current interactive reinforcement learning research has been limited to real-time interactions that offer relevant user advice to the current state only. Moreover, the information provided by each interaction is not retained and instead discarded by the agent after a single use. In this paper, we present a method for retaining and reusing provided knowledge, allowing trainers to give general advice relevant to more than just the current state. Results obtained show that the use of broad-persistent advice substantially improves the performance of the agent while reducing the number of interactions required for the trainer.
Habitat-Matterport 3D Semantics Dataset
Oct 11, 2022
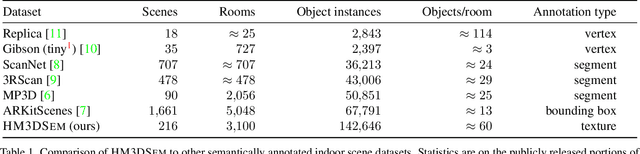

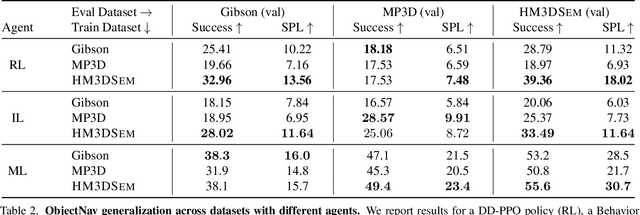
We present the Habitat-Matterport 3D Semantics (HM3DSEM) dataset. HM3DSEM is the largest dataset of 3D real-world spaces with densely annotated semantics that is currently available to the academic community. It consists of 142,646 object instance annotations across 216 3D spaces and 3,100 rooms within those spaces. The scale, quality, and diversity of object annotations far exceed those of datasets from prior work. A key difference setting apart HM3DSEM from other datasets is the use of texture information to annotate pixel-accurate object boundaries. We demonstrate the effectiveness of HM3DSEM dataset for the Object Goal Navigation task using different methods. Policies trained using HM3DSEM perform comparable or better than those trained on prior datasets.
EditEval: An Instruction-Based Benchmark for Text Improvements
Sep 27, 2022
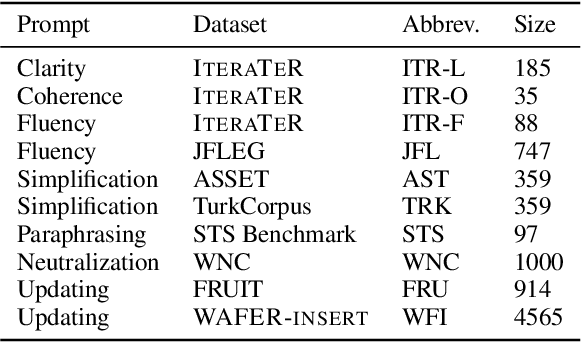
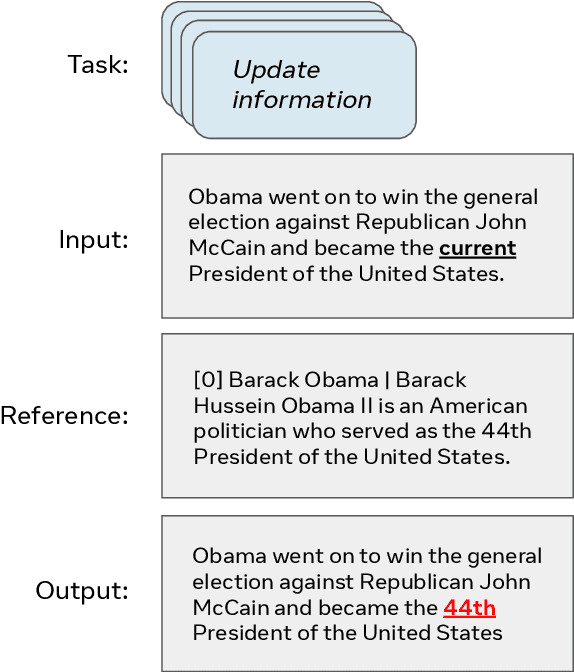
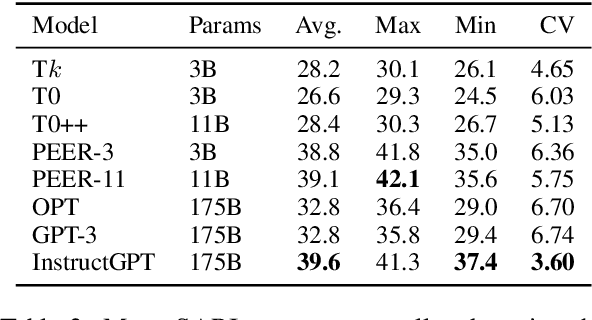
Evaluation of text generation to date has primarily focused on content created sequentially, rather than improvements on a piece of text. Writing, however, is naturally an iterative and incremental process that requires expertise in different modular skills such as fixing outdated information or making the style more consistent. Even so, comprehensive evaluation of a model's capacity to perform these skills and the ability to edit remains sparse. This work presents EditEval: An instruction-based, benchmark and evaluation suite that leverages high-quality existing and new datasets for automatic evaluation of editing capabilities such as making text more cohesive and paraphrasing. We evaluate several pre-trained models, which shows that InstructGPT and PEER perform the best, but that most baselines fall below the supervised SOTA, particularly when neutralizing and updating information. Our analysis also shows that commonly used metrics for editing tasks do not always correlate well, and that optimization for prompts with the highest performance does not necessarily entail the strongest robustness to different models. Through the release of this benchmark and a publicly available leaderboard challenge, we hope to unlock future research in developing models capable of iterative and more controllable editing.
Dual-Modality Haptic Feedback Improves Dexterous Task Execution with Virtual EMG-Controlled Gripper
Sep 30, 2022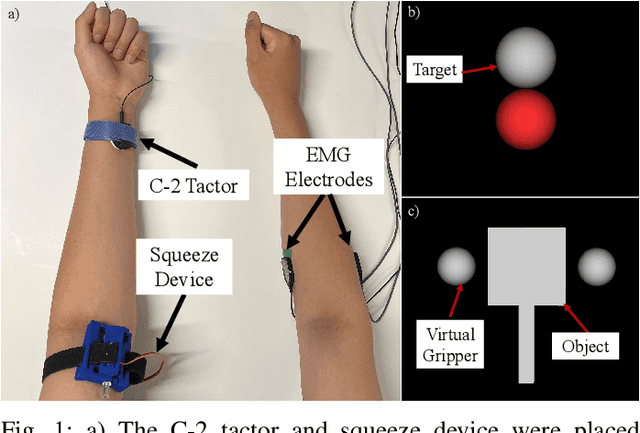
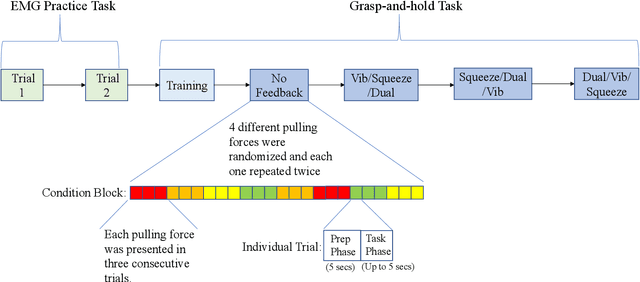
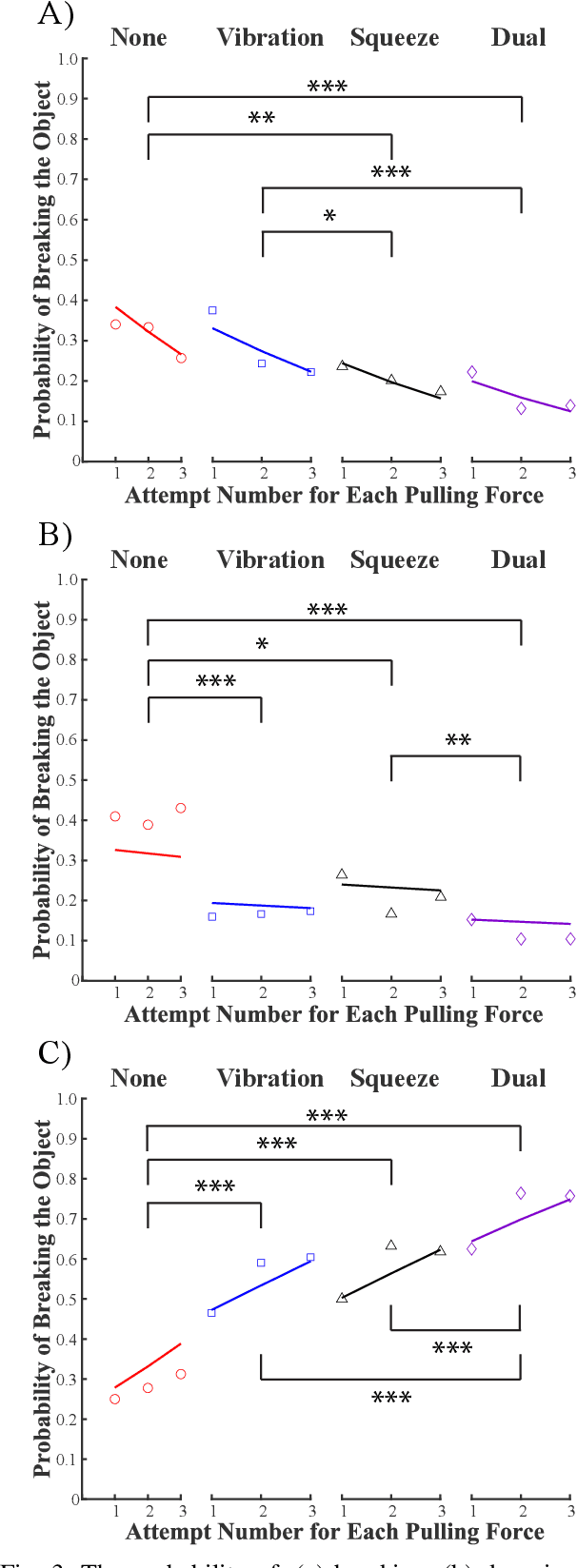
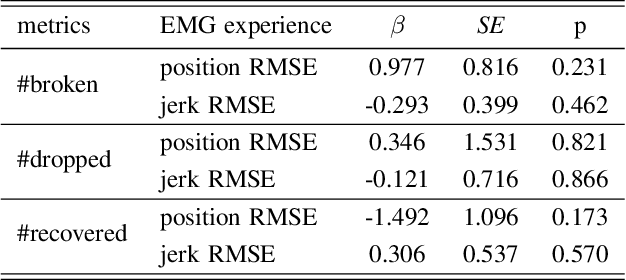
Upper-extremity amputees who use myoelectric prostheses currently lack the haptic sensory information needed to perform dexterous activities of daily living. While considerable research has focused on restoring this haptic information, these approaches often rely on single-modality feedback schemes which are necessary but insufficient for the feedforward and feedback control strategies employed by the central nervous system. Multi-modality feedback approaches have been gaining attention in several application domains, however, the utility for myoelectric prosthesis use remains unclear. In this study, we investigated the utility of dual-modality haptic feedback in a virtual EMG-controlled grasp-and-hold task with a brittle object and variable load force. We recruited N=20 non-amputee participants to perform the task in four conditions: no feedback, vibration feedback of incipient slip, squeezing feedback of grip force, and dual (vibration + squeezing) feedback of incipient slip and grip force. Results suggest that receiving any feedback is better than receiving none, however, dual-modality feedback is far superior to either single-modality feedback approach in terms of preventing the object from breaking or dropping, even after it started slipping. Control with dual-modality feedback was also seen as more intuitive than with either of the single-modality feedback approaches.
Posterior Covariance Information Criterion
Jun 25, 2021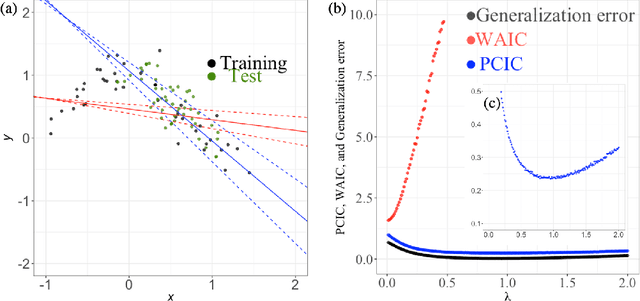
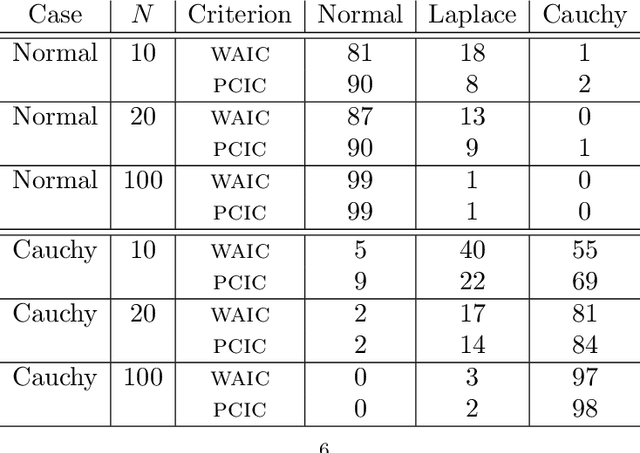
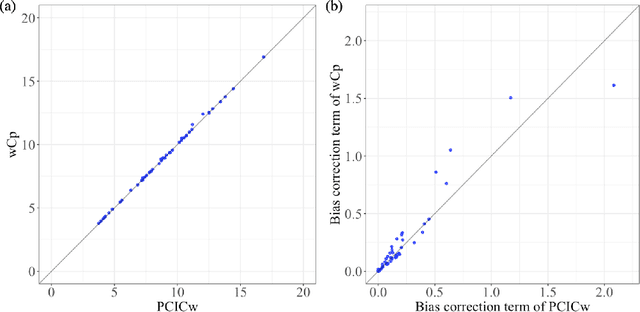
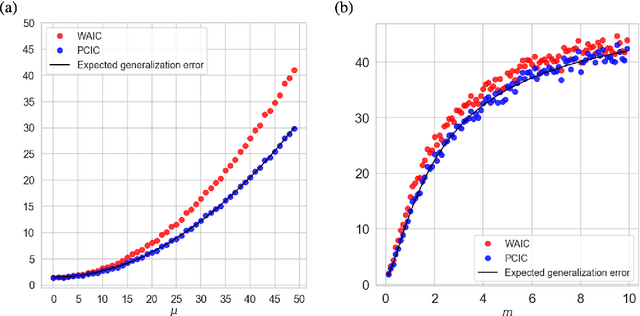
We introduce an information criterion, PCIC, for predictive evaluation based on quasi-posterior distributions. It is regarded as a natural generalization of widely applicable information criterion (WAIC) and can be computed via a single Markov Chain Monte Carlo run. PCIC is useful in a variety of predictive settings that are not well dealt with in WAIC, including weighted likelihood inference and quasi-Bayesian prediction.
Spatio-temporal motion correction and iterative reconstruction of in-utero fetal fMRI
Sep 17, 2022Resting-state functional Magnetic Resonance Imaging (fMRI) is a powerful imaging technique for studying functional development of the brain in utero. However, unpredictable and excessive movement of fetuses have limited its clinical applicability. Previous studies have focused primarily on the accurate estimation of the motion parameters employing a single step 3D interpolation at each individual time frame to recover a motion-free 4D fMRI image. Using only information from a 3D spatial neighborhood neglects the temporal structure of fMRI and useful information from neighboring timepoints. Here, we propose a novel technique based on four dimensional iterative reconstruction of the motion scattered fMRI slices. Quantitative evaluation of the proposed method on a cohort of real clinical fetal fMRI data indicates improvement of reconstruction quality compared to the conventional 3D interpolation approaches.
2T-UNET: A Two-Tower UNet with Depth Clues for Robust Stereo Depth Estimation
Oct 27, 2022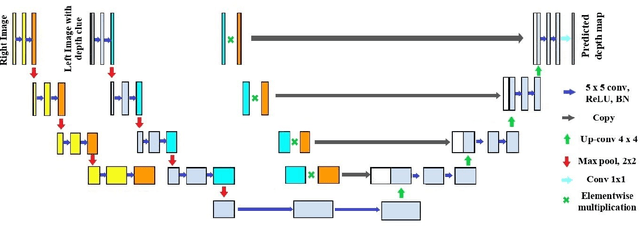
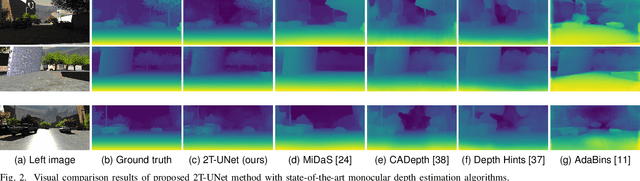
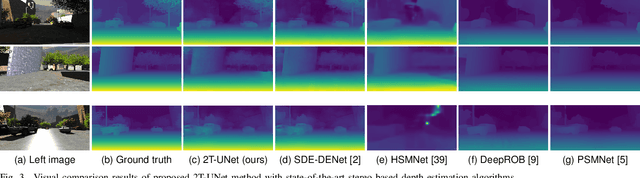

Stereo correspondence matching is an essential part of the multi-step stereo depth estimation process. This paper revisits the depth estimation problem, avoiding the explicit stereo matching step using a simple two-tower convolutional neural network. The proposed algorithm is entitled as 2T-UNet. The idea behind 2T-UNet is to replace cost volume construction with twin convolution towers. These towers have an allowance for different weights between them. Additionally, the input for twin encoders in 2T-UNet are different compared to the existing stereo methods. Generally, a stereo network takes a right and left image pair as input to determine the scene geometry. However, in the 2T-UNet model, the right stereo image is taken as one input and the left stereo image along with its monocular depth clue information, is taken as the other input. Depth clues provide complementary suggestions that help enhance the quality of predicted scene geometry. The 2T-UNet surpasses state-of-the-art monocular and stereo depth estimation methods on the challenging Scene flow dataset, both quantitatively and qualitatively. The architecture performs incredibly well on complex natural scenes, highlighting its usefulness for various real-time applications. Pretrained weights and code will be made readily available.
Modeling Inter-Dependence Between Time and Mark in Multivariate Temporal Point Processes
Oct 27, 2022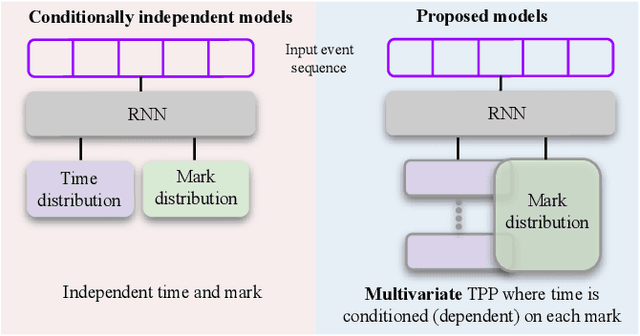

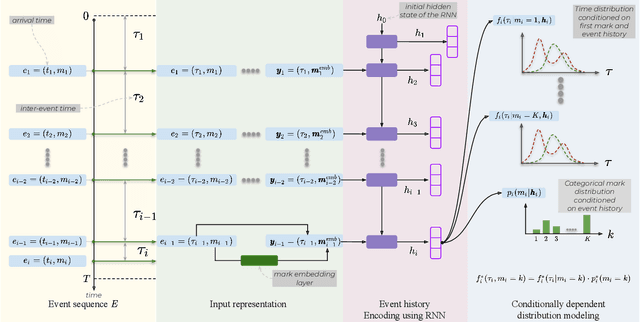
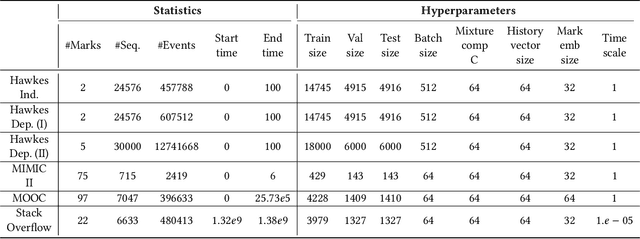
Temporal Point Processes (TPP) are probabilistic generative frameworks. They model discrete event sequences localized in continuous time. Generally, real-life events reveal descriptive information, known as marks. Marked TPPs model time and marks of the event together for practical relevance. Conditioned on past events, marked TPPs aim to learn the joint distribution of the time and the mark of the next event. For simplicity, conditionally independent TPP models assume time and marks are independent given event history. They factorize the conditional joint distribution of time and mark into the product of individual conditional distributions. This structural limitation in the design of TPP models hurt the predictive performance on entangled time and mark interactions. In this work, we model the conditional inter-dependence of time and mark to overcome the limitations of conditionally independent models. We construct a multivariate TPP conditioning the time distribution on the current event mark in addition to past events. Besides the conventional intensity-based models for conditional joint distribution, we also draw on flexible intensity-free TPP models from the literature. The proposed TPP models outperform conditionally independent and dependent models in standard prediction tasks. Our experimentation on various datasets with multiple evaluation metrics highlights the merit of the proposed approach.