 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflective Teacher: Semi-Supervised Multimodal 3D Object Detection in Bird's-Eye-View via Uncertainty Measure
Dec 05, 2024Applying pseudo labeling techniques has been found to be advantageous in semi-supervised 3D object detection (SSOD) in Bird's-Eye-View (BEV) for autonomous driving, particularly where labeled data is limited. In the literature, Exponential Moving Average (EMA) has been used for adjustments of the weights of teacher network by the student network. However, the same induces catastrophic forgetting in the teacher network. In this work, we address this issue by introducing a novel concept of Reflective Teacher where the student is trained by both labeled and pseudo labeled data while its knowledge is progressively passed to the teacher through a regularizer to ensure retention of previous knowledge. Additionally, we propose Geometry Aware BEV Fusion (GA-BEVFusion) for efficient alignment of multi-modal BEV features, thus reducing the disparity between the modalities - camera and LiDAR. This helps to map the precise geometric information embedded among LiDAR points reliably with the spatial priors for extraction of semantic information from camera images. Our experiments on the nuScenes and Waymo datasets demonstrate: 1) improved performance over state-of-the-art methods in both fully supervised and semi-supervised settings; 2) Reflective Teacher achieves equivalent performance with only 25% and 22% of labeled data for nuScenes and Waymo datasets respectively, in contrast to other fully supervised methods that utilize the full labeled dataset.
GANESH: Generalizable NeRF for Lensless Imaging
Nov 07, 2024



Lensless imaging offers a significant opportunity to develop ultra-compact cameras by removing the conventional bulky lens system. However, without a focusing element, the sensor's output is no longer a direct image but a complex multiplexed scene representation. Traditional methods have attempted to address this challenge by employing learnable inversions and refinement models, but these methods are primarily designed for 2D reconstruction and do not generalize well to 3D reconstruction. We introduce GANESH, a novel framework designed to enable simultaneous refinement and novel view synthesis from multi-view lensless images. Unlike existing methods that require scene-specific training, our approach supports on-the-fly inference without retraining on each scene. Moreover, our framework allows us to tune our model to specific scenes, enhancing the rendering and refinement quality. To facilitate research in this area, we also present the first multi-view lensless dataset, LenslessScenes. Extensive experiments demonstrate that our method outperforms current approaches in reconstruction accuracy and refinement quality. Code and video results are available at https://rakesh-123-cryp.github.io/Rakesh.github.io/
2T-UNET: A Two-Tower UNet with Depth Clues for Robust Stereo Depth Estimation
Oct 27, 2022



Stereo correspondence matching is an essential part of the multi-step stereo depth estimation process. This paper revisits the depth estimation problem, avoiding the explicit stereo matching step using a simple two-tower convolutional neural network. The proposed algorithm is entitled as 2T-UNet. The idea behind 2T-UNet is to replace cost volume construction with twin convolution towers. These towers have an allowance for different weights between them. Additionally, the input for twin encoders in 2T-UNet are different compared to the existing stereo methods. Generally, a stereo network takes a right and left image pair as input to determine the scene geometry. However, in the 2T-UNet model, the right stereo image is taken as one input and the left stereo image along with its monocular depth clue information, is taken as the other input. Depth clues provide complementary suggestions that help enhance the quality of predicted scene geometry. The 2T-UNet surpasses state-of-the-art monocular and stereo depth estimation methods on the challenging Scene flow dataset, both quantitatively and qualitatively. The architecture performs incredibly well on complex natural scenes, highlighting its usefulness for various real-time applications. Pretrained weights and code will be made readily available.
A High Resolution Multi-exposure Stereoscopic Image & Video Database of Natural Scenes
Jun 22, 2022


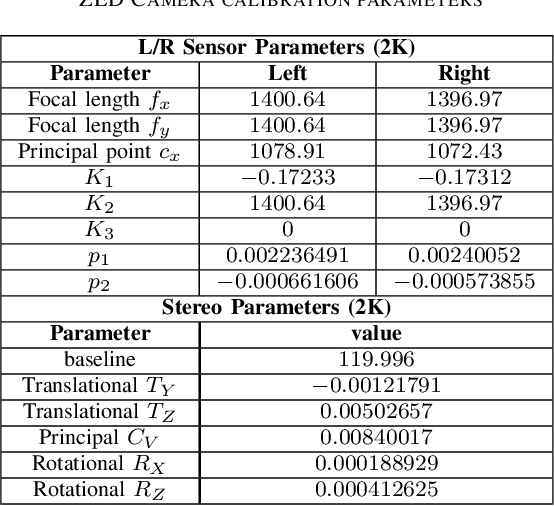
Immersive displays such as VR headsets, AR glasses, Multiview displays, Free point televisions have emerged as a new class of display technologies in recent years, offering a better visual experience and viewer engagement as compared to conventional displays. With the evolution of 3D video and display technologies, the consumer market for High Dynamic Range (HDR) cameras and displays is quickly growing. The lack of appropriate experimental data is a critical hindrance for the development of primary research efforts in the field of 3D HDR video technology. Also, the unavailability of sufficient real world multi-exposure experimental dataset is a major bottleneck for HDR imaging research, thereby limiting the quality of experience (QoE) for the viewers. In this paper, we introduce a diversified stereoscopic multi-exposure dataset captured within the campus of Indian Institute of Technology Madras, which is home to a diverse flora and fauna. The dataset is captured using ZED stereoscopic camera and provides intricate scenes of outdoor locations such as gardens, roadside views, festival venues, buildings and indoor locations such as academic and residential areas. The proposed dataset accommodates wide depth range, complex depth structure, complicate object movement, illumination variations, rich color dynamics, texture discrepancy in addition to significant randomness introduced by moving camera and background motion. The proposed dataset is made publicly available to the research community. Furthermore, the procedure for capturing, aligning and calibrating multi-exposure stereo videos and images is described in detail. Finally, we have discussed the progress, challenges, potential use cases and future research opportunities with respect to HDR imaging, depth estimation, consistent tone mapping and 3D HDR coding.
MEStereo-Du2CNN: A Novel Dual Channel CNN for Learning Robust Depth Estimates from Multi-exposure Stereo Images for HDR 3D Applications
Jun 21, 2022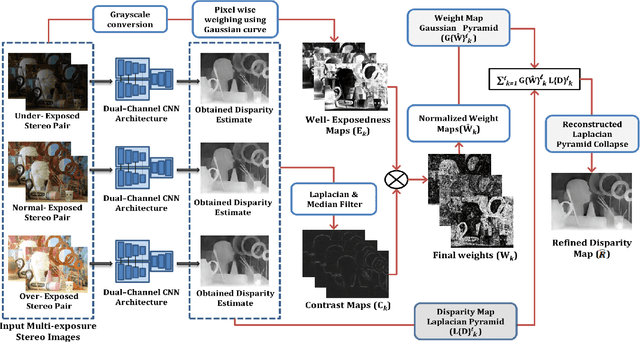
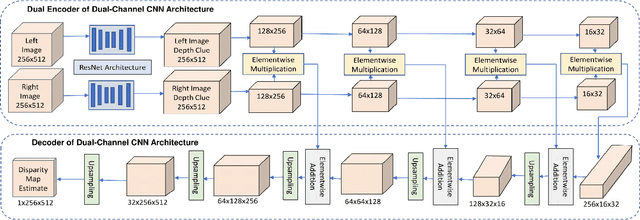
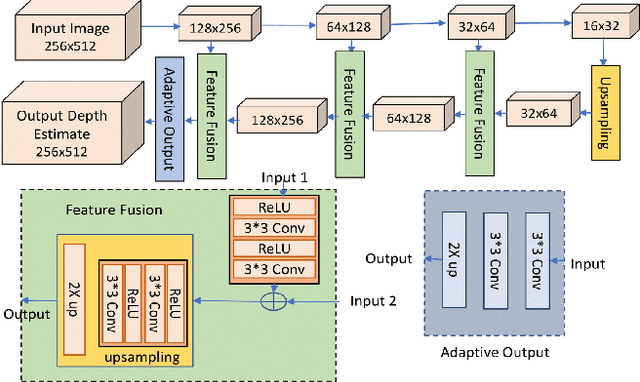

Display technologies have evolved over the years. It is critical to develop practical HDR capturing, processing, and display solutions to bring 3D technologies to the next level. Depth estimation of multi-exposure stereo image sequences is an essential task in the development of cost-effective 3D HDR video content. In this paper, we develop a novel deep architecture for multi-exposure stereo depth estimation. The proposed architecture has two novel components. First, the stereo matching technique used in traditional stereo depth estimation is revamped. For the stereo depth estimation component of our architecture, a mono-to-stereo transfer learning approach is deployed. The proposed formulation circumvents the cost volume construction requirement, which is replaced by a ResNet based dual-encoder single-decoder CNN with different weights for feature fusion. EfficientNet based blocks are used to learn the disparity. Secondly, we combine disparity maps obtained from the stereo images at different exposure levels using a robust disparity feature fusion approach. The disparity maps obtained at different exposures are merged using weight maps calculated for different quality measures. The final predicted disparity map obtained is more robust and retains best features that preserve the depth discontinuities. The proposed CNN offers flexibility to train using standard dynamic range stereo data or with multi-exposure low dynamic range stereo sequences. In terms of performance, the proposed model surpasses state-of-the-art monocular and stereo depth estimation methods, both quantitatively and qualitatively, on challenging Scene flow and differently exposed Middlebury stereo datasets. The architecture performs exceedingly well on complex natural scenes, demonstrating its usefulness for diverse 3D HDR applications.