 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Trade-off between reconstruction loss and feature alignment for domain generalization
Oct 26, 2022

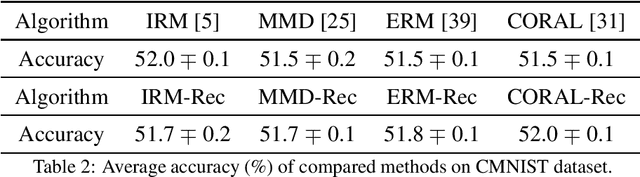
Domain generalization (DG) is a branch of transfer learning that aims to train the learning models on several seen domains and subsequently apply these pre-trained models to other unseen (unknown but related) domains. To deal with challenging settings in DG where both data and label of the unseen domain are not available at training time, the most common approach is to design the classifiers based on the domain-invariant representation features, i.e., the latent representations that are unchanged and transferable between domains. Contrary to popular belief, we show that designing classifiers based on invariant representation features alone is necessary but insufficient in DG. Our analysis indicates the necessity of imposing a constraint on the reconstruction loss induced by representation functions to preserve most of the relevant information about the label in the latent space. More importantly, we point out the trade-off between minimizing the reconstruction loss and achieving domain alignment in DG. Our theoretical results motivate a new DG framework that jointly optimizes the reconstruction loss and the domain discrepancy. Both theoretical and numerical results are provided to justify our approach.
* 13 pages, 2 tables
Learning on Large-scale Text-attributed Graphs via Variational Inference
Oct 26, 2022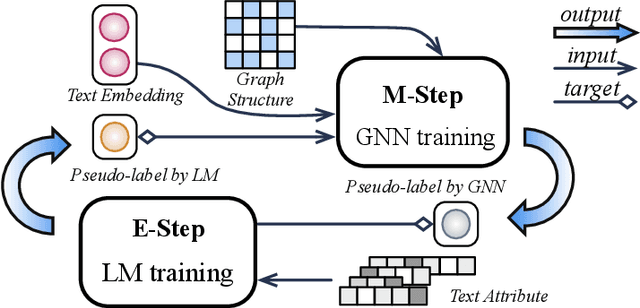

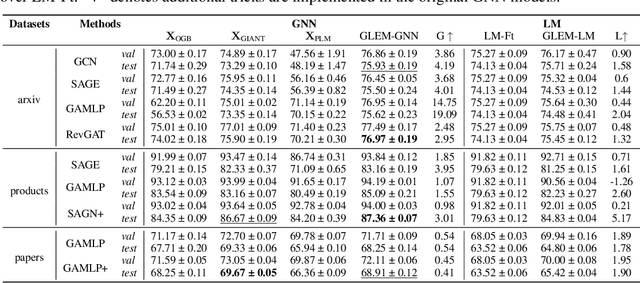
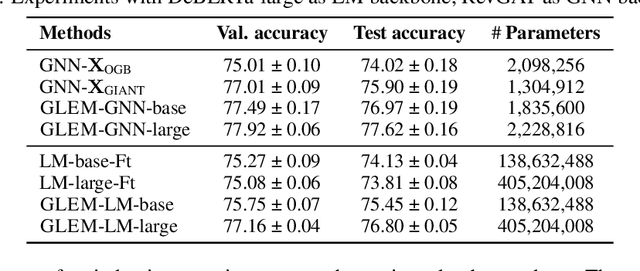
This paper studies learning on text-attributed graphs (TAGs), where each node is associated with a text description. An ideal solution for such a problem would be integrating both the text and graph structure information with large language models and graph neural networks (GNNs). However, the problem becomes very challenging when graphs are large due to the high computational complexity brought by large language models and training GNNs on big graphs. In this paper, we propose an efficient and effective solution to learning on large text-attributed graphs by fusing graph structure and language learning with a variational Expectation-Maximization (EM) framework, called GLEM. Instead of simultaneously training large language models and GNNs on big graphs, GLEM proposes to alternatively update the two modules in the E-step and M-step. Such a procedure allows to separately train the two modules but at the same time allows the two modules to interact and mutually enhance each other. Extensive experiments on multiple data sets demonstrate the efficiency and effectiveness of the proposed approach.
Hybrid HMM Decoder For Convolutional Codes By Joint Trellis-Like Structure and Channel Prior
Oct 26, 2022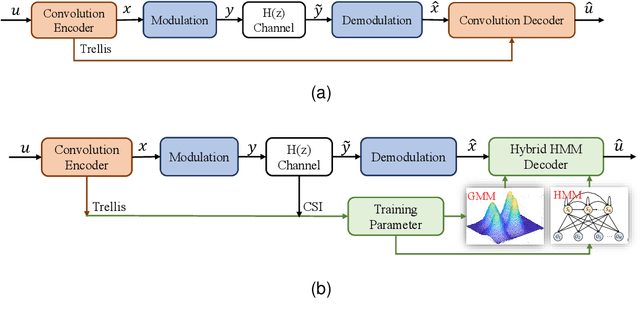
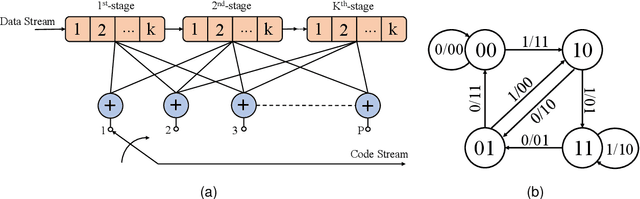
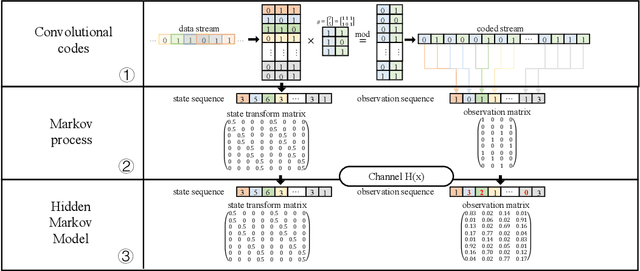
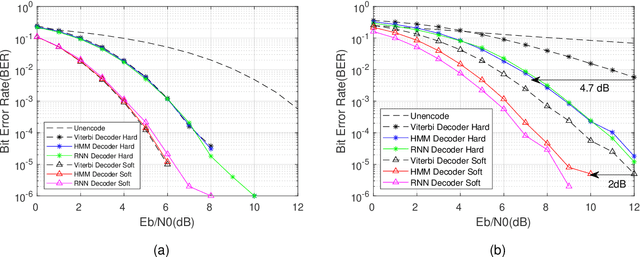
The anti-interference capability of wireless links is a physical layer problem for edge computing. Although convolutional codes have inherent error correction potential due to the redundancy introduced in the data, the performance of the convolutional code is drastically degraded due to multipath effects on the channel. In this paper, we propose the use of a Hidden Markov Model (HMM) for the reconstruction of convolutional codes and decoding by the Viterbi algorithm. Furthermore, to implement soft-decision decoding, the observation of HMM is replaced by Gaussian mixture models (GMM). Our method provides superior error correction potential than the standard method because the model parameters contain channel state information (CSI). We evaluated the performance of the method compared to standard Viterbi decoding by numerical simulation. In the multipath channel, the hybrid HMM decoder can achieve a performance gain of 4.7 dB and 2 dB when using hard-decision and soft-decision decoding, respectively. The HMM decoder also achieves significant performance gains for the RSC code, suggesting that the method could be extended to turbo codes.
Discourse-Aware Emotion Cause Extraction in Conversations
Oct 26, 2022
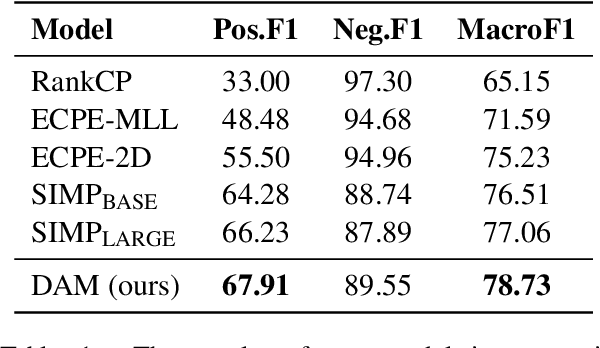
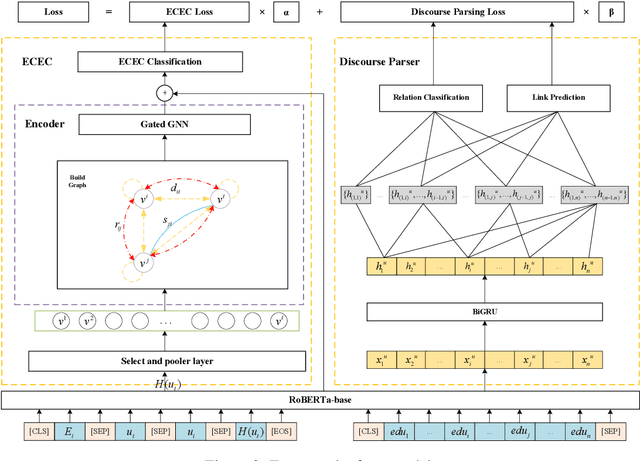
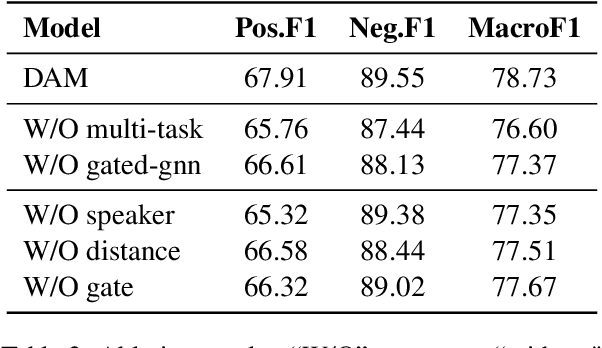
Emotion Cause Extraction in Conversations (ECEC) aims to extract the utterances which contain the emotional cause in conversations. Most prior research focuses on modelling conversational contexts with sequential encoding, ignoring the informative interactions between utterances and conversational-specific features for ECEC. In this paper, we investigate the importance of discourse structures in handling utterance interactions and conversationspecific features for ECEC. To this end, we propose a discourse-aware model (DAM) for this task. Concretely, we jointly model ECEC with discourse parsing using a multi-task learning (MTL) framework and explicitly encode discourse structures via gated graph neural network (gated GNN), integrating rich utterance interaction information to our model. In addition, we use gated GNN to further enhance our ECEC model with conversation-specific features. Results on the benchmark corpus show that DAM outperform the state-of-theart (SOTA) systems in the literature. This suggests that the discourse structure may contain a potential link between emotional utterances and their corresponding cause expressions. It also verifies the effectiveness of conversationalspecific features. The codes of this paper will be available on GitHub.
LiDAR-guided object search and detection in Subterranean Environments
Oct 26, 2022
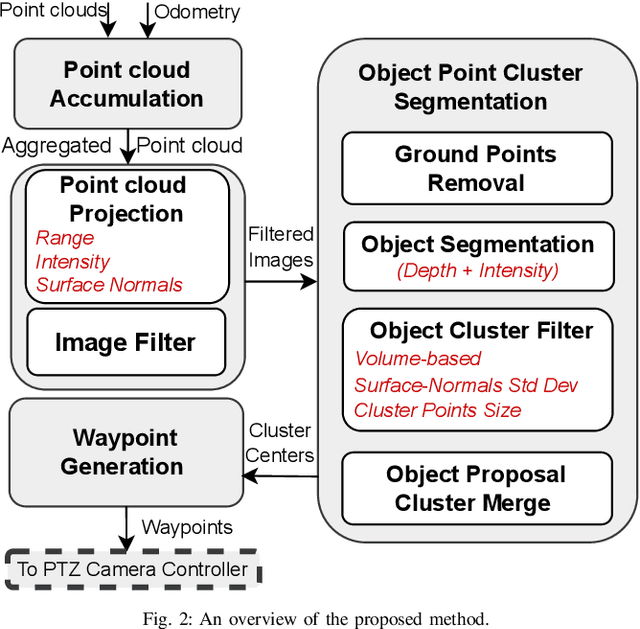

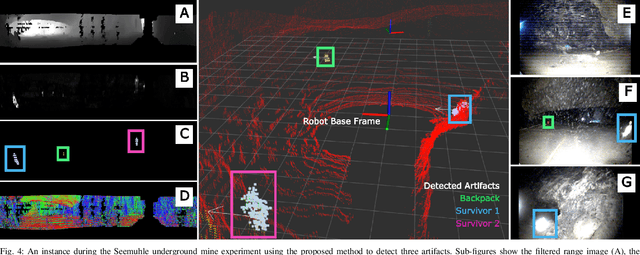
Detecting objects of interest, such as human survivors, safety equipment, and structure access points, is critical to any search-and-rescue operation. Robots deployed for such time-sensitive efforts rely on their onboard sensors to perform their designated tasks. However, as disaster response operations are predominantly conducted under perceptually degraded conditions, commonly utilized sensors such as visual cameras and LiDARs suffer in terms of performance degradation. In response, this work presents a method that utilizes the complementary nature of vision and depth sensors to leverage multi-modal information to aid object detection at longer distances. In particular, depth and intensity values from sparse LiDAR returns are used to generate proposals for objects present in the environment. These proposals are then utilized by a Pan-Tilt-Zoom (PTZ) camera system to perform a directed search by adjusting its pose and zoom level for performing object detection and classification in difficult environments. The proposed work has been thoroughly verified using an ANYmal quadruped robot in underground settings and on datasets collected during the DARPA Subterranean Challenge finals.
Two-stage dimensional emotion recognition by fusing predictions of acoustic and text networks using SVM
Oct 26, 2022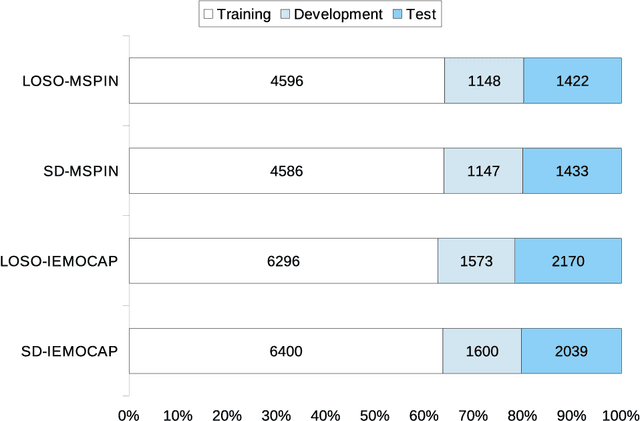

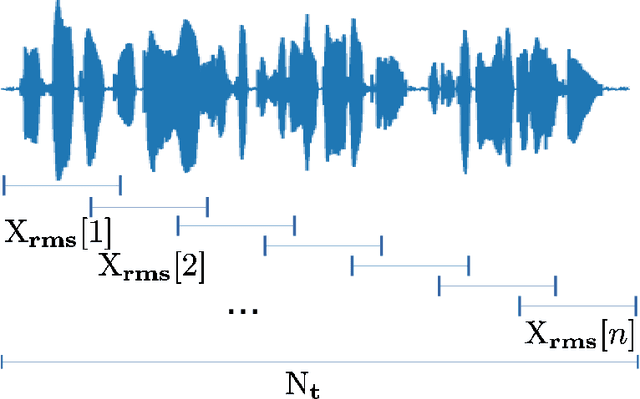
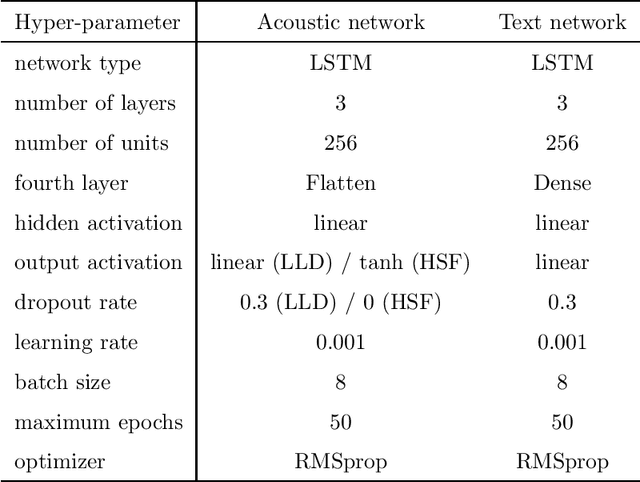
Automatic speech emotion recognition (SER) by a computer is a critical component for more natural human-machine interaction. As in human-human interaction, the capability to perceive emotion correctly is essential to take further steps in a particular situation. One issue in SER is whether it is necessary to combine acoustic features with other data such as facial expressions, text, and motion capture. This research proposes to combine acoustic and text information by applying a late-fusion approach consisting of two steps. First, acoustic and text features are trained separately in deep learning systems. Second, the prediction results from the deep learning systems are fed into a support vector machine (SVM) to predict the final regression score. Furthermore, the task in this research is dimensional emotion modeling because it can enable a deeper analysis of affective states. Experimental results show that this two-stage, late-fusion approach, obtains higher performance than that of any one-stage processing, with a linear correlation from one-stage to two-stage processing. This late-fusion approach improves previous early fusion results measured in concordance correlation coefficients score.
* Published in Speech Communications
Breaking Time Invariance: Assorted-Time Normalization for RNNs
Sep 28, 2022
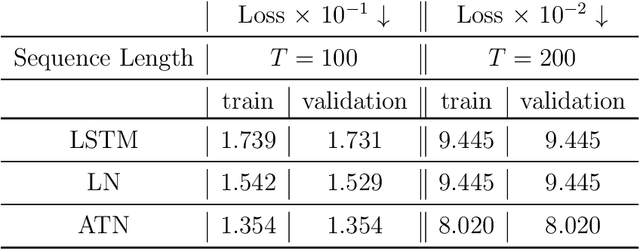
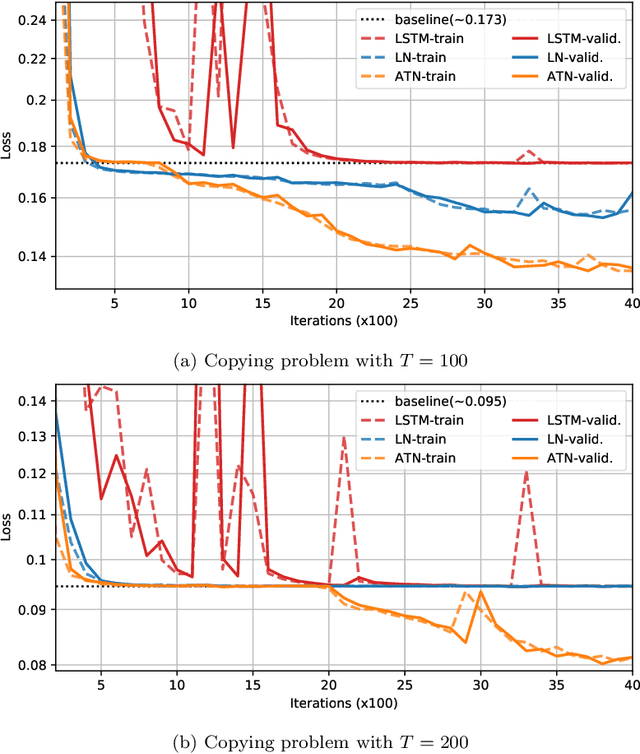
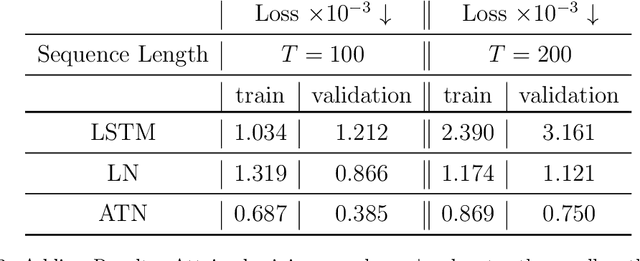
Methods such as Layer Normalization (LN) and Batch Normalization (BN) have proven to be effective in improving the training of Recurrent Neural Networks (RNNs). However, existing methods normalize using only the instantaneous information at one particular time step, and the result of the normalization is a preactivation state with a time-independent distribution. This implementation fails to account for certain temporal differences inherent in the inputs and the architecture of RNNs. Since these networks share weights across time steps, it may also be desirable to account for the connections between time steps in the normalization scheme. In this paper, we propose a normalization method called Assorted-Time Normalization (ATN), which preserves information from multiple consecutive time steps and normalizes using them. This setup allows us to introduce longer time dependencies into the traditional normalization methods without introducing any new trainable parameters. We present theoretical derivations for the gradient propagation and prove the weight scaling invariance property. Our experiments applying ATN to LN demonstrate consistent improvement on various tasks, such as Adding, Copying, and Denoise Problems and Language Modeling Problems.
Blockchain-Based Decentralized Knowledge Marketplace Using Active Inference
Oct 04, 2022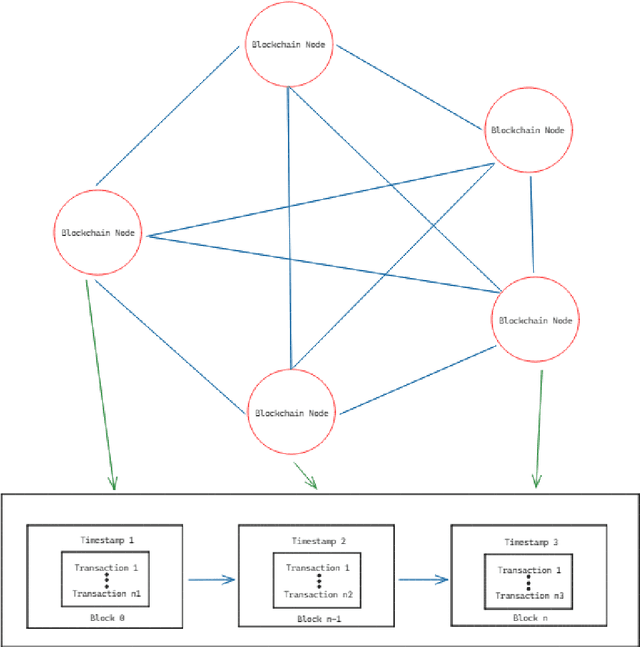
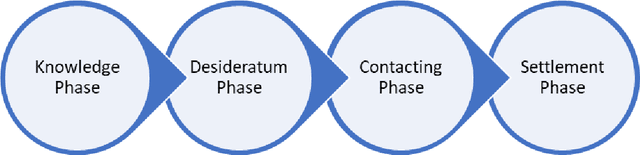
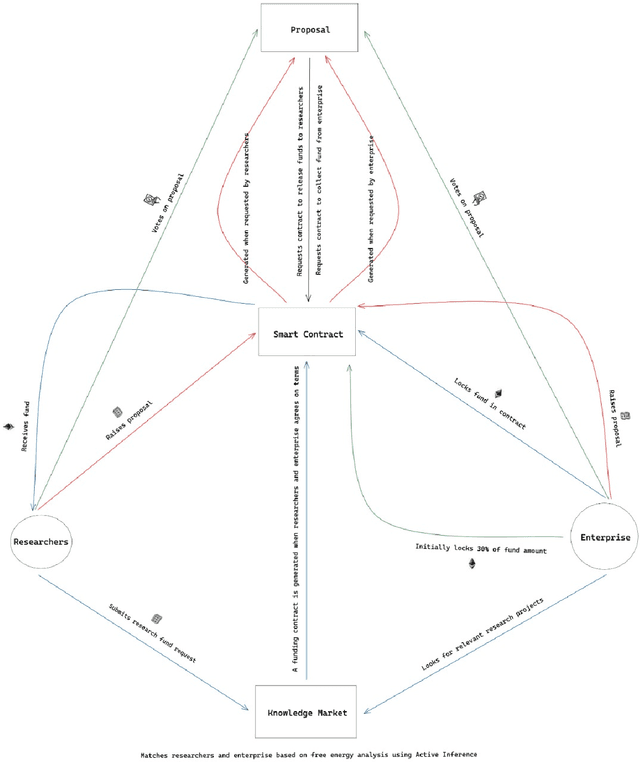
A knowledge market can be described as a type of market where there is a consistent supply of data to satisfy the demand for information and is responsible for the mapping of potential problem solvers with the entities which need these solutions. It is possible to define them as value-exchange systems in which the dynamic features of the creation and exchange of intellectual assets serve as the fundamental drivers of the frequency, nature, and outcomes of interactions among various stakeholders. Furthermore, the provision of financial backing for research is an essential component in the process of developing a knowledge market that is capable of enduring over time, and it is also an essential driver of the progression of scientific investigation. This paper underlines flaws associated with the conventional knowledge-based market, including but not limited to excessive financing concentration, ineffective information exchange, a lack of security, mapping of entities, etc. The authors present a decentralized framework for the knowledge marketplace incorporating technologies such as blockchain, active inference, zero-knowledge proof, etc. The proposed decentralized framework provides not only an efficient mapping mechanism to map entities in the marketplace but also a more secure and controlled way to share knowledge and services among various stakeholders.
DialogUSR: Complex Dialogue Utterance Splitting and Reformulation for Multiple Intent Detection
Oct 20, 2022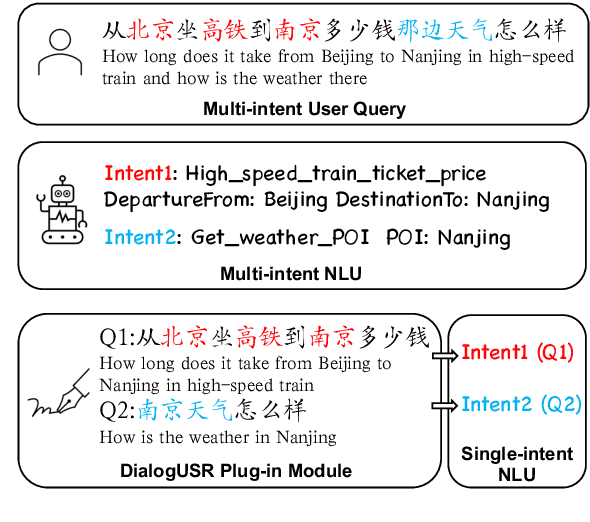
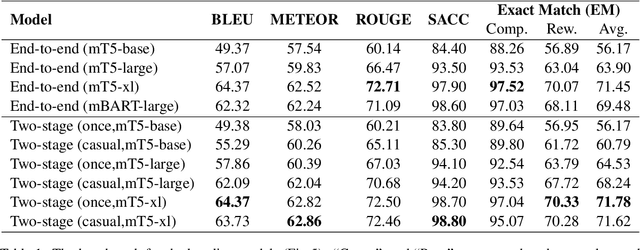

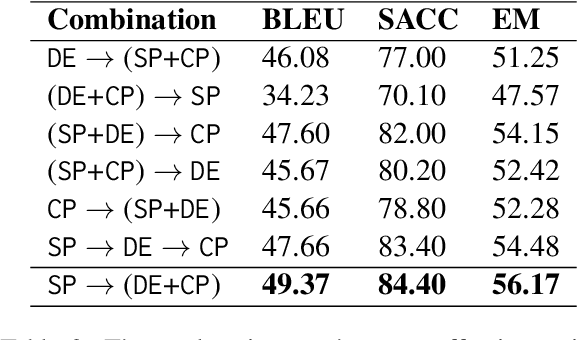
While interacting with chatbots, users may elicit multiple intents in a single dialogue utterance. Instead of training a dedicated multi-intent detection model, we propose DialogUSR, a dialogue utterance splitting and reformulation task that first splits multi-intent user query into several single-intent sub-queries and then recovers all the coreferred and omitted information in the sub-queries. DialogUSR can serve as a plug-in and domain-agnostic module that empowers the multi-intent detection for the deployed chatbots with minimal efforts. We collect a high-quality naturally occurring dataset that covers 23 domains with a multi-step crowd-souring procedure. To benchmark the proposed dataset, we propose multiple action-based generative models that involve end-to-end and two-stage training, and conduct in-depth analyses on the pros and cons of the proposed baselines.
Convolutional Learning on Multigraphs
Sep 23, 2022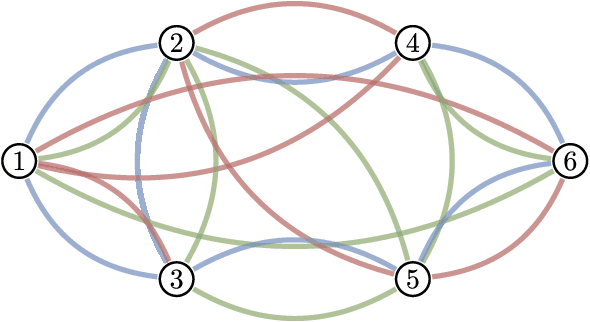
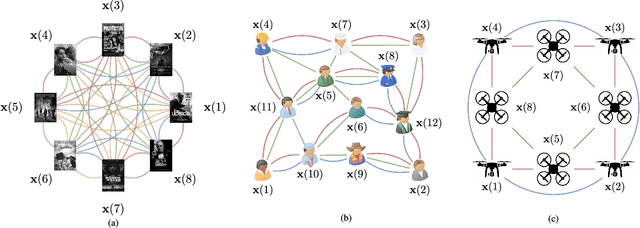

Graph convolutional learning has led to many exciting discoveries in diverse areas. However, in some applications, traditional graphs are insufficient to capture the structure and intricacies of the data. In such scenarios, multigraphs arise naturally as discrete structures in which complex dynamics can be embedded. In this paper, we develop convolutional information processing on multigraphs and introduce convolutional multigraph neural networks (MGNNs). To capture the complex dynamics of information diffusion within and across each of the multigraph's classes of edges, we formalize a convolutional signal processing model, defining the notions of signals, filtering, and frequency representations on multigraphs. Leveraging this model, we develop a multigraph learning architecture, including a sampling procedure to reduce computational complexity. The introduced architecture is applied towards optimal wireless resource allocation and a hate speech localization task, offering improved performance over traditional graph neural networks.