 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI/ML for mobile networks: Current status in Rel. 19 and challenges ahead
Mar 15, 2026The transformative power of artificial intelligence (AI) and machine learning (ML) is recognized as a key enabler for sixth generation (6G) mobile networks by both academia and industry. Research on AI/ML in mobile networks has been ongoing for years, and the 3rd generation partnership project (3GPP) launched standardization efforts to integrate AI into mobile networks. However, a comprehensive review of the current status and challenges of the standardization of AI/ML for mobile networks is still missing. To this end, we provided a comprehensive review of the standardization efforts by 3GPP on AI/ML for mobile networks. This includes an overview of the general AI/ML framework, representative use cases (i.e., CSI feedback, beam management and positioning), and corresponding evaluation matrices. We emphasized the key research challenges on dataset preparation, generalization evaluation and baseline AI/ML models selection. Using CSI feedback as a case study, given the test dataset 2, we demonstrated that the pre-training-fine-tuning paradigm (i.e., pre-training using dataset 1 and fine-tuning using dataset 2) outperforms training on dataset 2. Moreover, we observed the highest performance enhancements in Transformer-based models through fine-tuning, showing its great generalization potential at large floating-point operations (FLOPs). Finally, we outlined future research directions for the application of AI/ML in mobile networks.
CrossLLM-Mamba: Multimodal State Space Fusion of LLMs for RNA Interaction Prediction
Feb 23, 2026Accurate prediction of RNA-associated interactions is essential for understanding cellular regulation and advancing drug discovery. While Biological Large Language Models (BioLLMs) such as ESM-2 and RiNALMo provide powerful sequence representations, existing methods rely on static fusion strategies that fail to capture the dynamic, context-dependent nature of molecular binding. We introduce CrossLLM-Mamba, a novel framework that reformulates interaction prediction as a state-space alignment problem. By leveraging bidirectional Mamba encoders, our approach enables deep ``crosstalk'' between modality-specific embeddings through hidden state propagation, modeling interactions as dynamic sequence transitions rather than static feature overlaps. The framework maintains linear computational complexity, making it scalable to high-dimensional BioLLM embeddings. We further incorporate Gaussian noise injection and Focal Loss to enhance robustness against hard-negative samples. Comprehensive experiments across three interaction categories, RNA-protein, RNA-small molecule, and RNA-RNA demonstrate that CrossLLM-Mamba achieves state-of-the-art performance. On the RPI1460 benchmark, our model attains an MCC of 0.892, surpassing the previous best by 5.2\%. For binding affinity prediction, we achieve Pearson correlations exceeding 0.95 on riboswitch and repeat RNA subtypes. These results establish state-space modeling as a powerful paradigm for multi-modal biological interaction prediction.
Large-scale Multi-sequence Pretraining for Generalizable MRI Analysis in Versatile Clinical Applications
Aug 10, 2025



Multi-sequence Magnetic Resonance Imaging (MRI) offers remarkable versatility, enabling the distinct visualization of different tissue types. Nevertheless, the inherent heterogeneity among MRI sequences poses significant challenges to the generalization capability of deep learning models. These challenges undermine model performance when faced with varying acquisition parameters, thereby severely restricting their clinical utility. In this study, we present PRISM, a foundation model PRe-trained with large-scale multI-Sequence MRI. We collected a total of 64 datasets from both public and private sources, encompassing a wide range of whole-body anatomical structures, with scans spanning diverse MRI sequences. Among them, 336,476 volumetric MRI scans from 34 datasets (8 public and 26 private) were curated to construct the largest multi-organ multi-sequence MRI pretraining corpus to date. We propose a novel pretraining paradigm that disentangles anatomically invariant features from sequence-specific variations in MRI, while preserving high-level semantic representations. We established a benchmark comprising 44 downstream tasks, including disease diagnosis, image segmentation, registration, progression prediction, and report generation. These tasks were evaluated on 32 public datasets and 5 private cohorts. PRISM consistently outperformed both non-pretrained models and existing foundation models, achieving first-rank results in 39 out of 44 downstream benchmarks with statistical significance improvements. These results underscore its ability to learn robust and generalizable representations across unseen data acquired under diverse MRI protocols. PRISM provides a scalable framework for multi-sequence MRI analysis, thereby enhancing the translational potential of AI in radiology. It delivers consistent performance across diverse imaging protocols, reinforcing its clinical applicability.
MolSnap: Snap-Fast Molecular Generation with Latent Variational Mean Flow
Aug 07, 2025Molecular generation conditioned on textual descriptions is a fundamental task in computational chemistry and drug discovery. Existing methods often struggle to simultaneously ensure high-quality, diverse generation and fast inference. In this work, we propose a novel causality-aware framework that addresses these challenges through two key innovations. First, we introduce a Causality-Aware Transformer (CAT) that jointly encodes molecular graph tokens and text instructions while enforcing causal dependencies during generation. Second, we develop a Variational Mean Flow (VMF) framework that generalizes existing flow-based methods by modeling the latent space as a mixture of Gaussians, enhancing expressiveness beyond unimodal priors. VMF enables efficient one-step inference while maintaining strong generation quality and diversity. Extensive experiments on four standard molecular benchmarks demonstrate that our model outperforms state-of-the-art baselines, achieving higher novelty (up to 74.5\%), diversity (up to 70.3\%), and 100\% validity across all datasets. Moreover, VMF requires only one number of function evaluation (NFE) during conditional generation and up to five NFEs for unconditional generation, offering substantial computational efficiency over diffusion-based methods.
RefiDiff: Refinement-Aware Diffusion for Efficient Missing Data Imputation
May 20, 2025Missing values in high-dimensional, mixed-type datasets pose significant challenges for data imputation, particularly under Missing Not At Random (MNAR) mechanisms. Existing methods struggle to integrate local and global data characteristics, limiting performance in MNAR and high-dimensional settings. We propose an innovative framework, RefiDiff, combining local machine learning predictions with a novel Mamba-based denoising network capturing interrelationships among distant features and samples. Our approach leverages pre-refinement for initial warm-up imputations and post-refinement to polish results, enhancing stability and accuracy. By encoding mixed-type data into unified tokens, RefiDiff enables robust imputation without architectural or hyperparameter tuning. RefiDiff outperforms state-of-the-art (SOTA) methods across missing-value settings, excelling in MNAR with a 4x faster training time than SOTA DDPM-based approaches. Extensive evaluations on nine real-world datasets demonstrate its robustness, scalability, and effectiveness in handling complex missingness patterns.
Joint stochastic localization and applications
May 19, 2025Stochastic localization is a pathwise analysis technique originating from convex geometry. This paper explores certain algorithmic aspects of stochastic localization as a computational tool. First, we unify various existing stochastic localization schemes and discuss their localization rates and regularization. We then introduce a joint stochastic localization framework for constructing couplings between probability distributions. As an initial application, we extend the optimal couplings between normal distributions under the 2-Wasserstein distance to log-concave distributions and derive a normal approximation result. As a further application, we introduce a family of distributional distances based on the couplings induced by joint stochastic localization. Under a specific choice of the localization process, the induced distance is topologically equivalent to the 2-Wasserstein distance for probability measures supported on a common compact set. Moreover, weighted versions of this distance are related to several statistical divergences commonly used in practice. The proposed distances also motivate new methods for distribution estimation that are of independent interest.
Compact Recurrent Transformer with Persistent Memory
May 02, 2025



The Transformer architecture has shown significant success in many language processing and visual tasks. However, the method faces challenges in efficiently scaling to long sequences because the self-attention computation is quadratic with respect to the input length. To overcome this limitation, several approaches scale to longer sequences by breaking long sequences into a series of segments, restricting self-attention to local dependencies between tokens within each segment and using a memory mechanism to manage information flow between segments. However, these approached generally introduce additional compute overhead that restricts them from being used for applications where limited compute memory and power are of great concern (such as edge computing). We propose a novel and efficient Compact Recurrent Transformer (CRT), which combines shallow Transformer models that process short local segments with recurrent neural networks to compress and manage a single persistent memory vector that summarizes long-range global information between segments. We evaluate CRT on WordPTB and WikiText-103 for next-token-prediction tasks, as well as on the Toyota Smarthome video dataset for classification. CRT achieves comparable or superior prediction results to full-length Transformers in the language datasets while using significantly shorter segments (half or quarter size) and substantially reduced FLOPs. Our approach also demonstrates state-of-the-art performance on the Toyota Smarthome video dataset.
Mol-CADiff: Causality-Aware Autoregressive Diffusion for Molecule Generation
Mar 07, 2025The design of novel molecules with desired properties is a key challenge in drug discovery and materials science. Traditional methods rely on trial-and-error, while recent deep learning approaches have accelerated molecular generation. However, existing models struggle with generating molecules based on specific textual descriptions. We introduce Mol-CADiff, a novel diffusion-based framework that uses causal attention mechanisms for text-conditional molecular generation. Our approach explicitly models the causal relationship between textual prompts and molecular structures, overcoming key limitations in existing methods. We enhance dependency modeling both within and across modalities, enabling precise control over the generation process. Our extensive experiments demonstrate that Mol-CADiff outperforms state-of-the-art methods in generating diverse, novel, and chemically valid molecules, with better alignment to specified properties, enabling more intuitive language-driven molecular design.
Model-Assisted Learning for Adaptive Cooperative Perception of Connected Autonomous Vehicles
Jan 18, 2024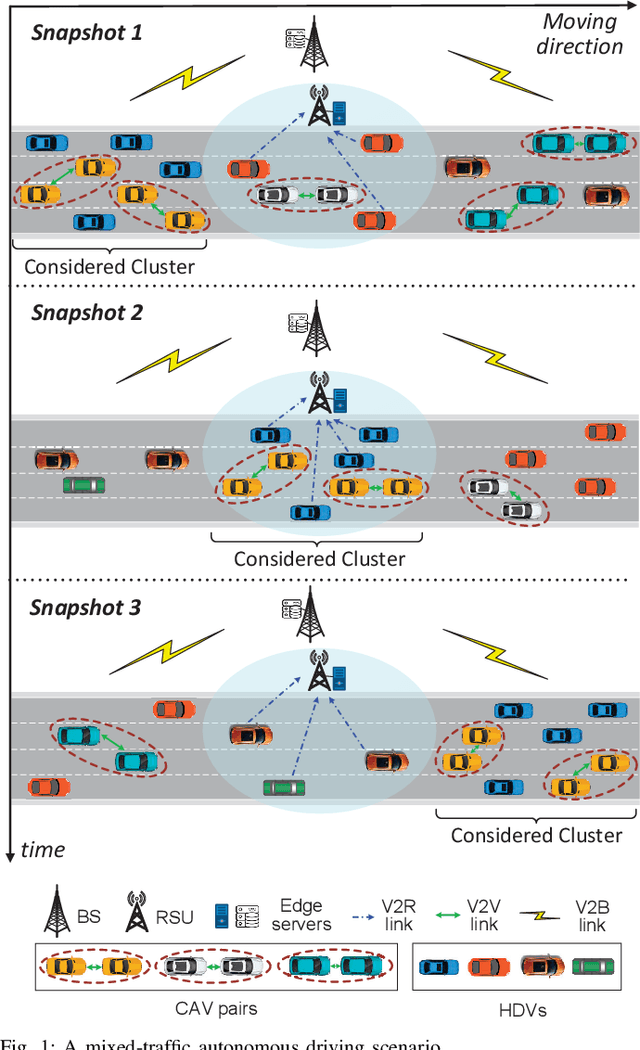

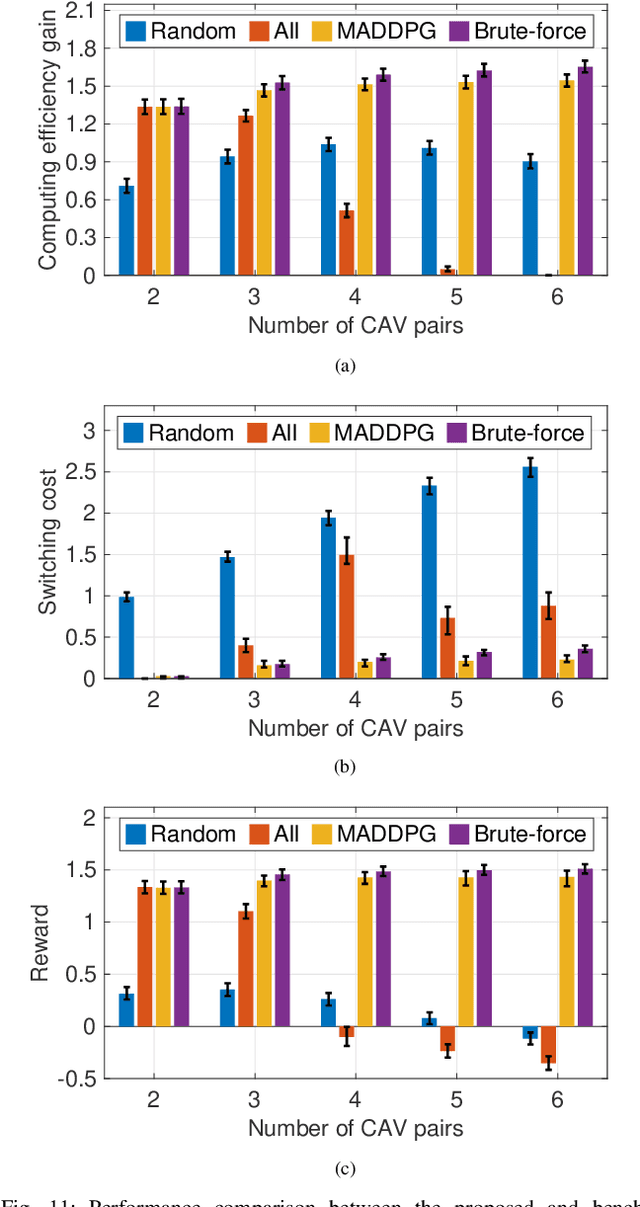

Cooperative perception (CP) is a key technology to facilitate consistent and accurate situational awareness for connected and autonomous vehicles (CAVs). To tackle the network resource inefficiency issue in traditional broadcast-based CP, unicast-based CP has been proposed to associate CAV pairs for cooperative perception via vehicle-to-vehicle transmission. In this paper, we investigate unicast-based CP among CAV pairs. With the consideration of dynamic perception workloads and channel conditions due to vehicle mobility and dynamic radio resource availability, we propose an adaptive cooperative perception scheme for CAV pairs in a mixed-traffic autonomous driving scenario with both CAVs and human-driven vehicles. We aim to determine when to switch between cooperative perception and stand-alone perception for each CAV pair, and allocate communication and computing resources to cooperative CAV pairs for maximizing the computing efficiency gain under perception task delay requirements. A model-assisted multi-agent reinforcement learning (MARL) solution is developed, which integrates MARL for an adaptive CAV cooperation decision and an optimization model for communication and computing resource allocation. Simulation results demonstrate the effectiveness of the proposed scheme in achieving high computing efficiency gain, as compared with benchmark schemes.
SCP-GAN: Self-Correcting Discriminator Optimization for Training Consistency Preserving Metric GAN on Speech Enhancement Tasks
Oct 26, 2022


In recent years, Generative Adversarial Networks (GANs) have produced significantly improved results in speech enhancement (SE) tasks. They are difficult to train, however. In this work, we introduce several improvements to the GAN training schemes, which can be applied to most GAN-based SE models. We propose using consistency loss functions, which target the inconsistency in time and time-frequency domains caused by Fourier and Inverse Fourier Transforms. We also present self-correcting optimization for training a GAN discriminator on SE tasks, which helps avoid "harmful" training directions for parts of the discriminator loss function. We have tested our proposed methods on several state-of-the-art GAN-based SE models and obtained consistent improvements, including new state-of-the-art results for the Voice Bank+DEMAND dataset.