 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Survey on 3D-aware Image Synthesis
Oct 30, 2022


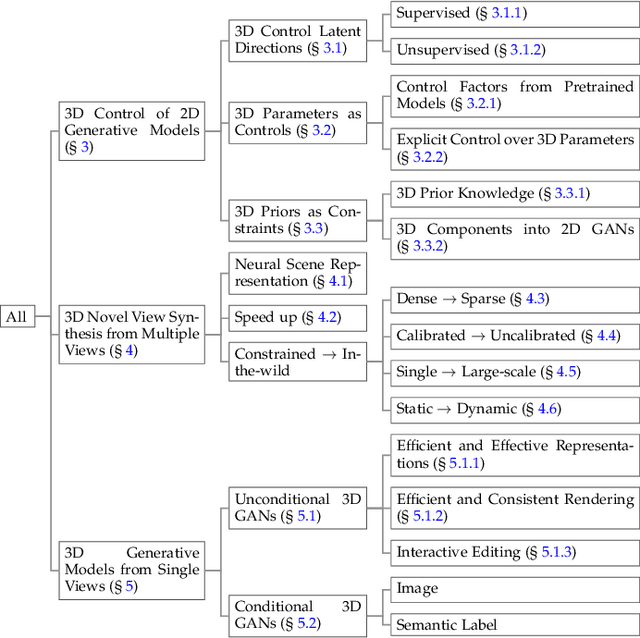
Recent years have seen remarkable progress in deep learning powered visual content creation. This includes 3D-aware generative image synthesis, which produces high-fidelity images in a 3D-consistent manner while simultaneously capturing compact surfaces of objects from pure image collections without the need for any 3D supervision, thus bridging the gap between 2D imagery and 3D reality. The 3D-aware generative models have shown that the introduction of 3D information can lead to more controllable image generation. The task of 3D-aware image synthesis has taken the field of computer vision by storm, with hundreds of papers accepted to top-tier journals and conferences in recent year (mainly the past two years), but there lacks a comprehensive survey of this remarkable and swift progress. Our survey aims to introduce new researchers to this topic, provide a useful reference for related works, and stimulate future research directions through our discussion section. Apart from the presented papers, we aim to constantly update the latest relevant papers along with corresponding implementations at https://weihaox.github.io/awesome-3D-aware-synthesis.
ISG: I can See Your Gene Expression
Oct 30, 2022


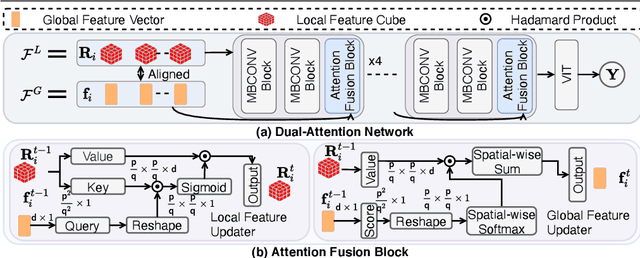
This paper aims to predict gene expression from a histology slide image precisely. Such a slide image has a large resolution and sparsely distributed textures. These obstruct extracting and interpreting discriminative features from the slide image for diverse gene types prediction. Existing gene expression methods mainly use general components to filter textureless regions, extract features, and aggregate features uniformly across regions. However, they ignore gaps and interactions between different image regions and are therefore inferior in the gene expression task. Instead, we present ISG framework that harnesses interactions among discriminative features from texture-abundant regions by three new modules: 1) a Shannon Selection module, based on the Shannon information content and Solomonoff's theory, to filter out textureless image regions; 2) a Feature Extraction network to extract expressive low-dimensional feature representations for efficient region interactions among a high-resolution image; 3) a Dual Attention network attends to regions with desired gene expression features and aggregates them for the prediction task. Extensive experiments on standard benchmark datasets show that the proposed ISG framework outperforms state-of-the-art methods significantly.
Multi-view Multi-label Anomaly Network Traffic Classification based on MLP-Mixer Neural Network
Oct 30, 2022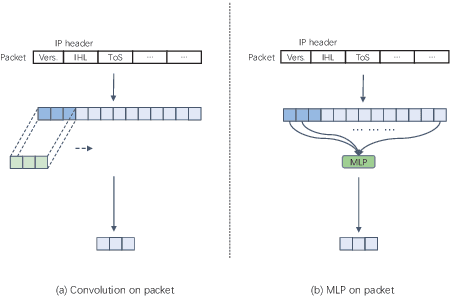
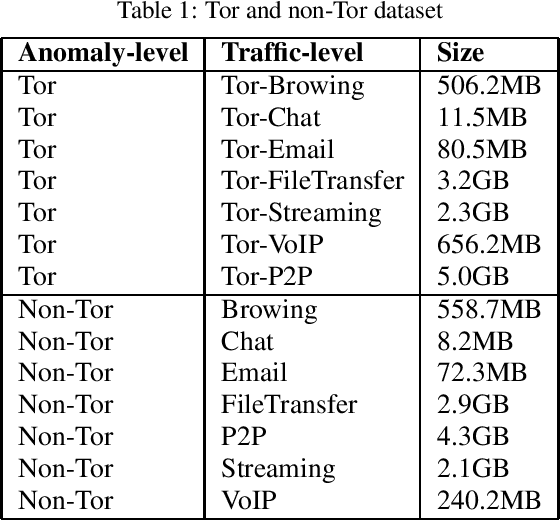

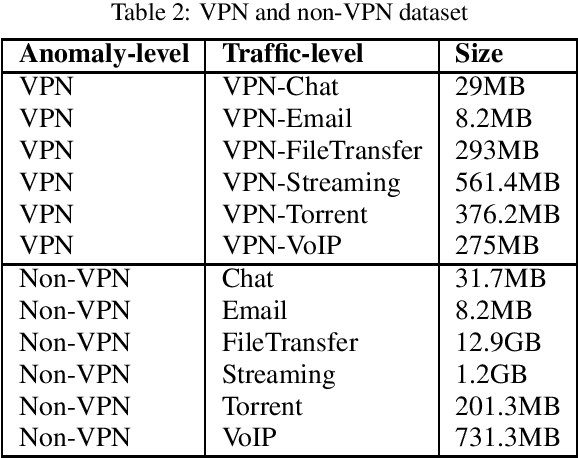
Network traffic classification is the basis of many network security applications and has attracted enough attention in the field of cyberspace security. Existing network traffic classification based on convolutional neural networks (CNNs) often emphasizes local patterns of traffic data while ignoring global information associations. In this paper, we propose a MLP-Mixer based multi-view multi-label neural network for network traffic classification. Compared with the existing CNN-based methods, our method adopts the MLP-Mixer structure, which is more in line with the structure of the packet than the conventional convolution operation. In our method, the packet is divided into the packet header and the packet body, together with the flow features of the packet as input from different views. We utilize a multi-label setting to learn different scenarios simultaneously to improve the classification performance by exploiting the correlations between different scenarios. Taking advantage of the above characteristics, we propose an end-to-end network traffic classification method. We conduct experiments on three public datasets, and the experimental results show that our method can achieve superior performance.
Probing Linguistic Information For Logical Inference In Pre-trained Language Models
Dec 03, 2021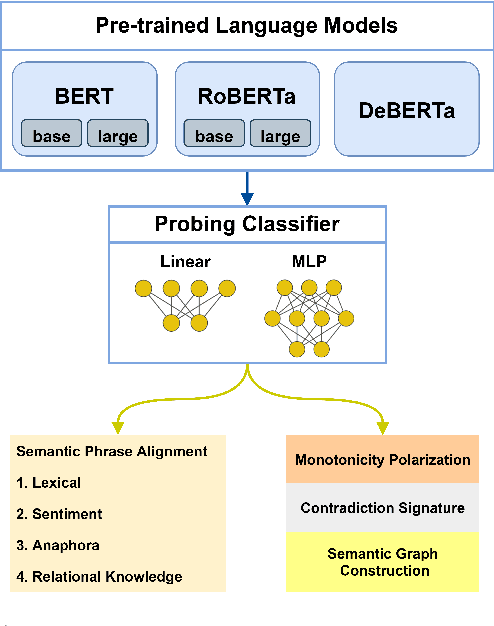
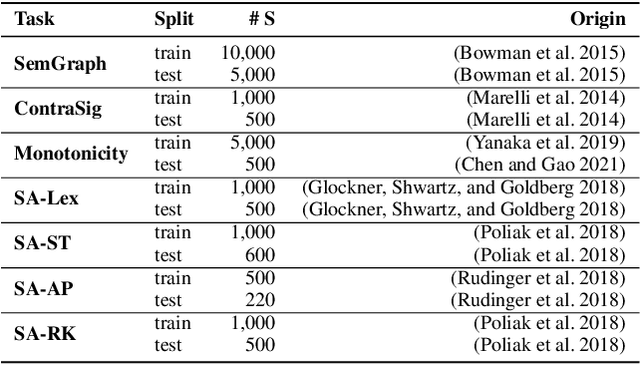
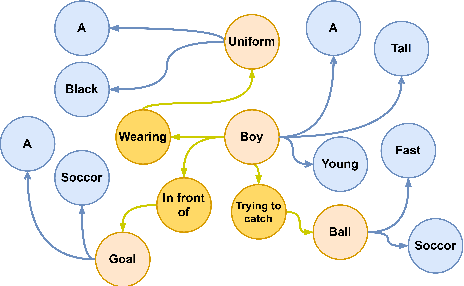

Progress in pre-trained language models has led to a surge of impressive results on downstream tasks for natural language understanding. Recent work on probing pre-trained language models uncovered a wide range of linguistic properties encoded in their contextualized representations. However, it is unclear whether they encode semantic knowledge that is crucial to symbolic inference methods. We propose a methodology for probing linguistic information for logical inference in pre-trained language model representations. Our probing datasets cover a list of linguistic phenomena required by major symbolic inference systems. We find that (i) pre-trained language models do encode several types of linguistic information for inference, but there are also some types of information that are weakly encoded, (ii) language models can effectively learn missing linguistic information through fine-tuning. Overall, our findings provide insights into which aspects of linguistic information for logical inference do language models and their pre-training procedures capture. Moreover, we have demonstrated language models' potential as semantic and background knowledge bases for supporting symbolic inference methods.
MEVID: Multi-view Extended Videos with Identities for Video Person Re-Identification
Nov 10, 2022
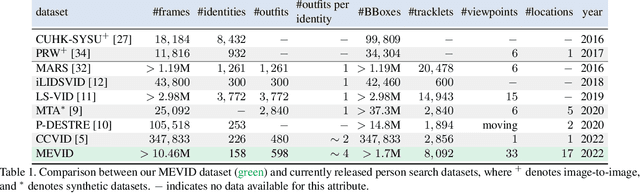

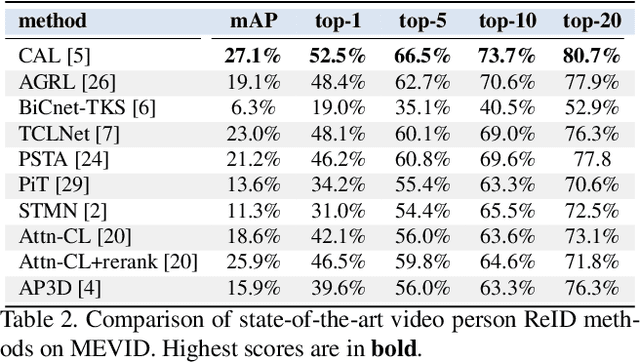
In this paper, we present the Multi-view Extended Videos with Identities (MEVID) dataset for large-scale, video person re-identification (ReID) in the wild. To our knowledge, MEVID represents the most-varied video person ReID dataset, spanning an extensive indoor and outdoor environment across nine unique dates in a 73-day window, various camera viewpoints, and entity clothing changes. Specifically, we label the identities of 158 unique people wearing 598 outfits taken from 8, 092 tracklets, average length of about 590 frames, seen in 33 camera views from the very large-scale MEVA person activities dataset. While other datasets have more unique identities, MEVID emphasizes a richer set of information about each individual, such as: 4 outfits/identity vs. 2 outfits/identity in CCVID, 33 viewpoints across 17 locations vs. 6 in 5 simulated locations for MTA, and 10 million frames vs. 3 million for LS-VID. Being based on the MEVA video dataset, we also inherit data that is intentionally demographically balanced to the continental United States. To accelerate the annotation process, we developed a semi-automatic annotation framework and GUI that combines state-of-the-art real-time models for object detection, pose estimation, person ReID, and multi-object tracking. We evaluate several state-of-the-art methods on MEVID challenge problems and comprehensively quantify their robustness in terms of changes of outfit, scale, and background location. Our quantitative analysis on the realistic, unique aspects of MEVID shows that there are significant remaining challenges in video person ReID and indicates important directions for future research.
Mitigating Forgetting in Online Continual Learning via Contrasting Semantically Distinct Augmentations
Nov 10, 2022
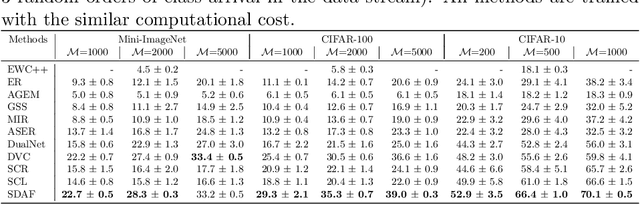
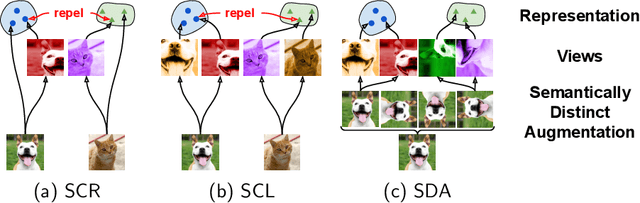
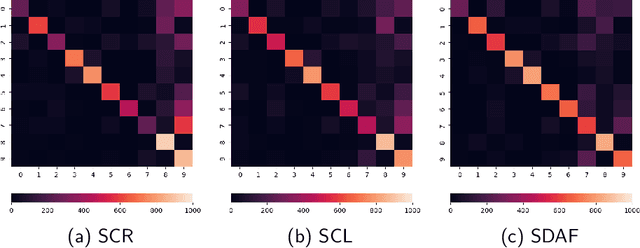
Online continual learning (OCL) aims to enable model learning from a non-stationary data stream to continuously acquire new knowledge as well as retain the learnt one, under the constraints of having limited system size and computational cost, in which the main challenge comes from the "catastrophic forgetting" issue -- the inability to well remember the learnt knowledge while learning the new ones. With the specific focus on the class-incremental OCL scenario, i.e. OCL for classification, the recent advance incorporates the contrastive learning technique for learning more generalised feature representation to achieve the state-of-the-art performance but is still unable to fully resolve the catastrophic forgetting. In this paper, we follow the strategy of adopting contrastive learning but further introduce the semantically distinct augmentation technique, in which it leverages strong augmentation to generate more data samples, and we show that considering these samples semantically different from their original classes (thus being related to the out-of-distribution samples) in the contrastive learning mechanism contributes to alleviate forgetting and facilitate model stability. Moreover, in addition to contrastive learning, the typical classification mechanism and objective (i.e. softmax classifier and cross-entropy loss) are included in our model design for faster convergence and utilising the label information, but particularly equipped with a sampling strategy to tackle the tendency of favouring the new classes (i.e. model bias towards the recently learnt classes). Upon conducting extensive experiments on CIFAR-10, CIFAR-100, and Mini-Imagenet datasets, our proposed method is shown to achieve superior performance against various baselines.
Self-supervised Graph Masking Pre-training for Graph-to-Text Generation
Oct 19, 2022
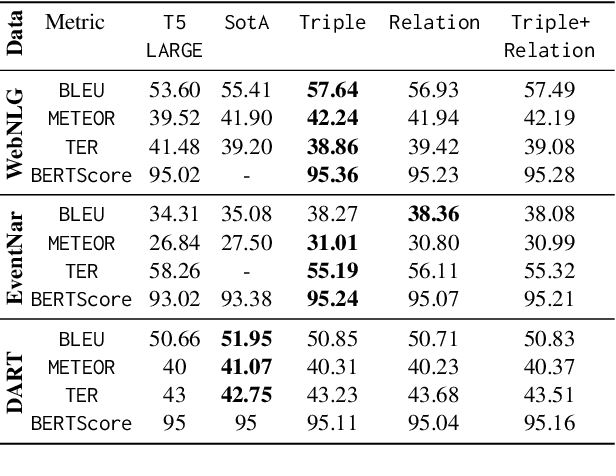
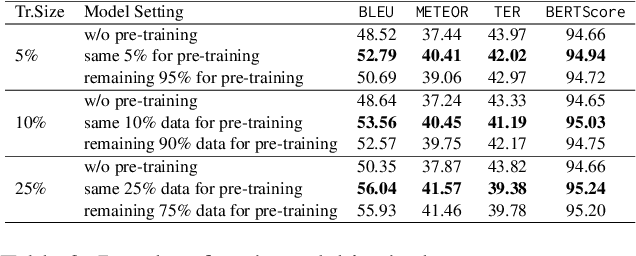
Large-scale pre-trained language models (PLMs) have advanced Graph-to-Text (G2T) generation by processing the linearised version of a graph. However, the linearisation is known to ignore the structural information. Additionally, PLMs are typically pre-trained on free text which introduces domain mismatch between pre-training and downstream G2T generation tasks. To address these shortcomings, we propose graph masking pre-training strategies that neither require supervision signals nor adjust the architecture of the underlying pre-trained encoder-decoder model. When used with a pre-trained T5, our approach achieves new state-of-the-art results on WebNLG+2020 and EventNarrative G2T generation datasets. Our method also shows to be very effective in the low-resource setting.
PL-EVIO: Robust Monocular Event-based Visual Inertial Odometry with Point and Line Features
Sep 25, 2022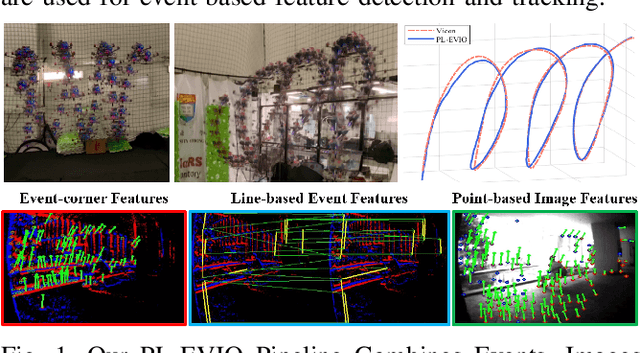
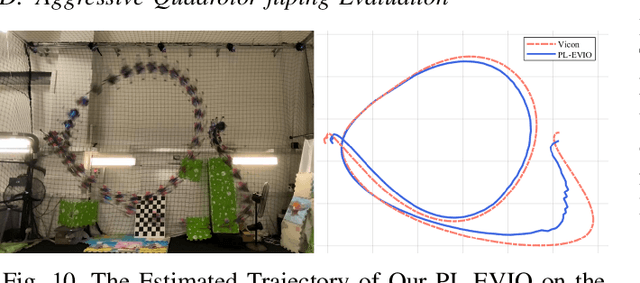
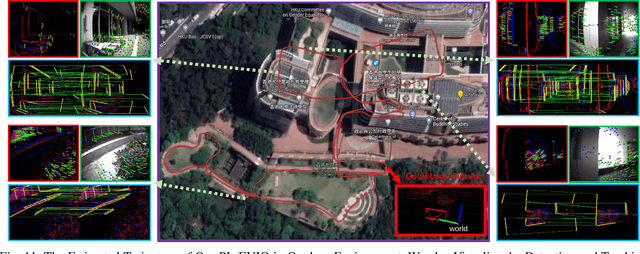
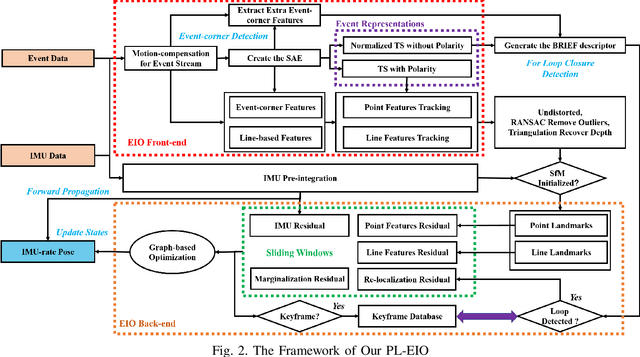
Event cameras are motion-activated sensors that capture pixel-level illumination changes instead of the intensity image with a fixed frame rate. Compared with the standard cameras, it can provide reliable visual perception during high-speed motions and in high dynamic range scenarios. However, event cameras output only a little information or even noise when the relative motion between the camera and the scene is limited, such as in a still state. While standard cameras can provide rich perception information in most scenarios, especially in good lighting conditions. These two cameras are exactly complementary. In this paper, we proposed a robust, high-accurate, and real-time optimization-based monocular event-based visual-inertial odometry (VIO) method with event-corner features, line-based event features, and point-based image features. The proposed method offers to leverage the point-based features in the nature scene and line-based features in the human-made scene to provide more additional structure or constraints information through well-design feature management. Experiments in the public benchmark datasets show that our method can achieve superior performance compared with the state-of-the-art image-based or event-based VIO. Finally, we used our method to demonstrate an onboard closed-loop autonomous quadrotor flight and large-scale outdoor experiments. Videos of the evaluations are presented on our project website: https://b23.tv/OE3QM6j
NEURAL MARIONETTE: A Transformer-based Multi-action Human Motion Synthesis System
Sep 27, 2022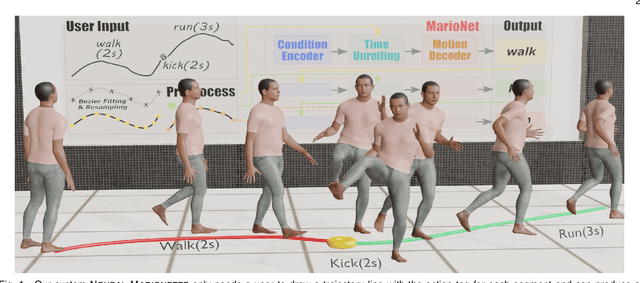
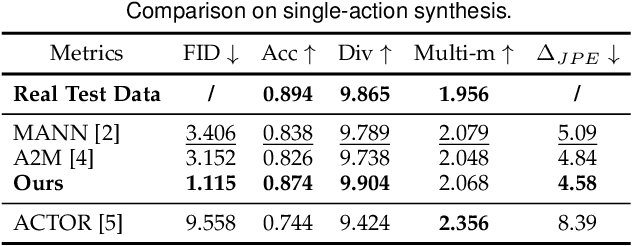

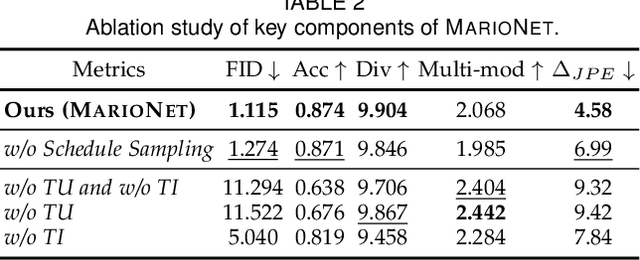
We present a neural network-based system for long-term, multi-action human motion synthesis. The system, dubbed as NEURAL MARIONETTE, can produce high-quality and meaningful motions with smooth transitions from simple user input, including a sequence of action tags with expected action duration, and optionally a hand-drawn moving trajectory if the user specifies. The core of our system is a novel Transformer-based motion generation model, namely MARIONET, which can generate diverse motions given action tags. Different from existing motion generation models, MARIONET utilizes contextual information from the past motion clip and future action tag, dedicated to generating actions that can smoothly blend historical and future actions. Specifically, MARIONET first encodes target action tag and contextual information into an action-level latent code. The code is unfolded into frame-level control signals via a time unrolling module, which could be then combined with other frame-level control signals like the target trajectory. Motion frames are then generated in an auto-regressive way. By sequentially applying MARIONET, the system NEURAL MARIONETTE can robustly generate long-term, multi-action motions with the help of two simple schemes, namely "Shadow Start" and "Action Revision". Along with the novel system, we also present a new dataset dedicated to the multi-action motion synthesis task, which contains both action tags and their contextual information. Extensive experiments are conducted to study the action accuracy, naturalism, and transition smoothness of the motions generated by our system.
MetaLoc: Learning to Learn Wireless Localization
Nov 08, 2022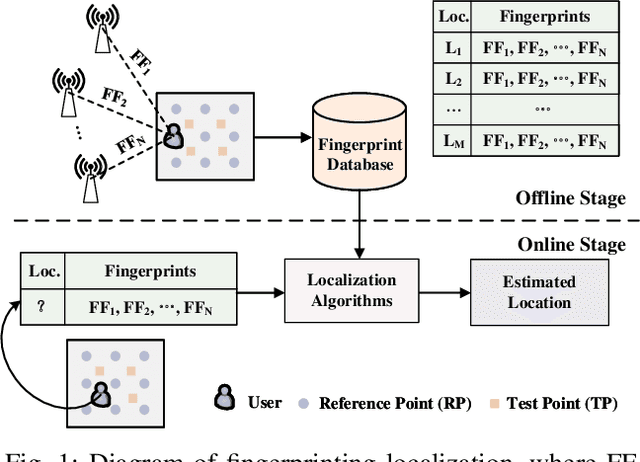
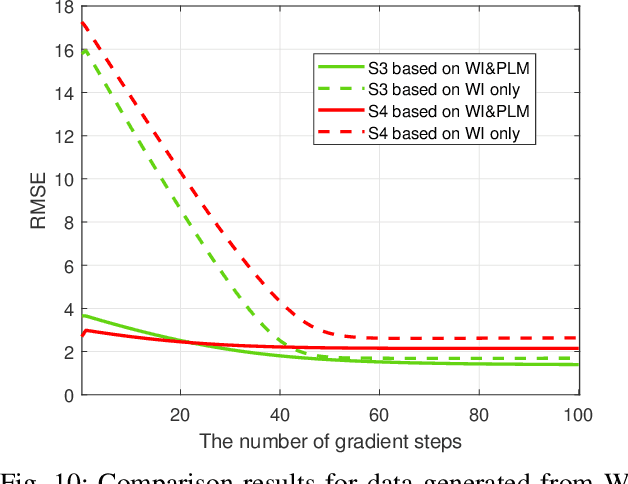
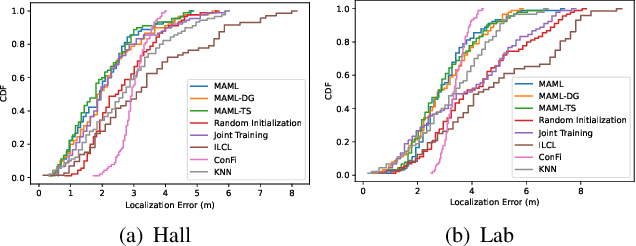
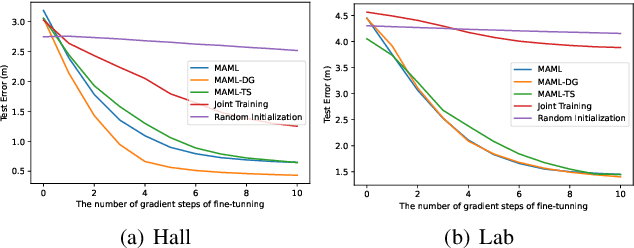
The existing indoor fingerprinting localization methods are rather accurate after intensive offline calibration for a specific environment, no matter based on received signal strength (RSS) or channel state information (CSI), but the well-calibrated localization model (can be a pure statistical one or a data-driven one) will present poor generalization ability in the highly variable environments, which results in big loss in knowledge and human effort. To break the environment-specific localization bottleneck, we propose a new-fashioned data-driven fingerprinting method for localization based on model-agnostic meta-learning (MAML), named by MetaLoc. Specifically, MetaLoc is char acterized by rapldly adapting itself to a new, possibly unseen environment with very little calibration. The underlying localization model is taken to be a deep neural network, and we train an optimal set of environment-specific meta-parameters by leveraging previous data collected from diverse well-calibrated indoor environments and the maximum mean discrepancy criterion. We further modify the loss function of vanilla MAML and propose a novel framework named as MAML-DG, which is able to achieve faster convergence and better adaptation abilities by forcing the loss on different training domains to decrease in similar directions. Experiments from simulation and site survey confirm that the meta-parameters obtained for MetaLoc achieves very rapid adaptation to new environments, competitive localization accuracy, and high resistance to significantly reduced reference points (RPs), saving a lot of calibration effort.