 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBIM-Loc: BIM-Integrated Discrepancy-Aware LiDAR-based Indoor Localization
Jun 12, 2026Accurate and robust localization is a fundamental requirement for service and inspection robots, particularly in feature-sparse indoor environments where traditional systems struggle due to a lack of distinct landmarks. While prior maps can enhance robustness, precise and compact maps capturing real-world details are often unavailable for new or frequently changing environments. This paper presents BIM-Loc, a novel discrepancy-aware LiDAR-based localization method that directly integrates Building Information Models (BIM) from the design phase. BIM-Loc simultaneously estimates trajectories aligned with the BIM coordinate system and identifies discrepancies between real-world observations and the as-designed BIM in an online fashion. Our core contributions include: (1) a novel multi-hit ray casting strategy for efficient BIM-point data association and projection of 3D observations into 2D texture space; (2) a pose graph optimization framework with BIM-integrated factors that enforces consistency among odometry, sequential scans, and BIM structures; and (3) a hierarchical Bayesian inference module that incrementally updates a continuous 2D surface representation for discrepancy detection, propagating updates from the pixel to the structure level. Extensive evaluations in both simulation and real-world applications demonstrate that BIM-Loc significantly outperforms state-of-the-art map-based methods in localization accuracy and robustness.
STRONG-VLA: Decoupled Robustness Learning for Vision-Language-Action Models under Multimodal Perturbations
Apr 14, 2026Despite their strong performance in embodied tasks, recent Vision-Language-Action (VLA) models remain highly fragile under multimodal perturbations, where visual corruption and linguistic noise jointly induce distribution shifts that degrade task-level execution. Existing robustness approaches typically rely on joint training with perturbed data, treating robustness as a static objective, which leads to conflicting optimization between robustness and task fidelity. In this work, we propose STRONG-VLA, a decoupled fine-tuning framework that explicitly separates robustness acquisition from task-aligned refinement. In Stage I, the model is exposed to a curriculum of multimodal perturbations with increasing difficulty, enabling progressive robustness learning under controlled distribution shifts. In Stage II, the model is re-aligned with clean task distributions to recover execution fidelity while preserving robustness. We further establish a comprehensive benchmark with 28 perturbation types spanning both textual and visual modalities, grounded in realistic sources of sensor noise, occlusion, and instruction corruption. Extensive experiments on the LIBERO benchmark show that STRONG-VLA consistently improves task success rates across multiple VLA architectures. On OpenVLA, our method achieves gains of up to 12.60% under seen perturbations and 7.77% under unseen perturbations. Notably, similar or larger improvements are observed on OpenVLA-OFT (+14.48% / +13.81%) and pi0 (+16.49% / +5.58%), demonstrating strong cross-architecture generalization. Real-world experiments on an AIRBOT robotic platform further validate its practical effectiveness. These results highlight the importance of decoupled optimization for multimodal robustness and establish STRONG-VLA as a simple yet principled framework for robust embodied control.
BD-Merging: Bias-Aware Dynamic Model Merging with Evidence-Guided Contrastive Learning
Mar 04, 2026Model Merging (MM) has emerged as a scalable paradigm for multi-task learning (MTL), enabling multiple task-specific models to be integrated without revisiting the original training data. Despite recent progress, the reliability of MM under test-time distribution shift remains insufficiently understood. Most existing MM methods typically assume that test data are clean and distributionally aligned with both the training and auxiliary sources. However, this assumption rarely holds in practice, often resulting in biased predictions with degraded generalization. To address this issue, we present BD-Merging, a bias-aware unsupervised model merging framework that explicitly models uncertainty to achieve adaptive reliability under distribution shift. First, BD-Merging introduces a joint evidential head that learns uncertainty over a unified label space, capturing cross-task semantic dependencies in MM. Second, building upon this evidential foundation, we propose an Adjacency Discrepancy Score (ADS) that quantifies evidential alignment among neighboring samples. Third, guided by ADS, a discrepancy-aware contrastive learning mechanism refines the merged representation by aligning consistent samples and separating conflicting ones. Combined with general unsupervised learning, this process trains a debiased router that adaptively allocates task-specific or layer-specific weights on a per-sample basis, effectively mitigating the adverse effects of distribution shift. Extensive experiments across diverse tasks demonstrate that BD-Merging achieves superior effectiveness and robustness compared to state-of-the-art MM baselines.
BrainDistill: Implantable Motor Decoding with Task-Specific Knowledge Distillation
Jan 24, 2026Transformer-based neural decoders with large parameter counts, pre-trained on large-scale datasets, have recently outperformed classical machine learning models and small neural networks on brain-computer interface (BCI) tasks. However, their large parameter counts and high computational demands hinder deployment in power-constrained implantable systems. To address this challenge, we introduce BrainDistill, a novel implantable motor decoding pipeline that integrates an implantable neural decoder (IND) with a task-specific knowledge distillation (TSKD) framework. Unlike standard feature distillation methods that attempt to preserve teacher representations in full, TSKD explicitly prioritizes features critical for decoding through supervised projection. Across multiple neural datasets, IND consistently outperforms prior neural decoders on motor decoding tasks, while its TSKD-distilled variant further surpasses alternative distillation methods in few-shot calibration settings. Finally, we present a quantization-aware training scheme that enables integer-only inference with activation clipping ranges learned during training. The quantized IND enables deployment under the strict power constraints of implantable BCIs with minimal performance loss.
HealSplit: Towards Self-Healing through Adversarial Distillation in Split Federated Learning
Nov 14, 2025Split Federated Learning (SFL) is an emerging paradigm for privacy-preserving distributed learning. However, it remains vulnerable to sophisticated data poisoning attacks targeting local features, labels, smashed data, and model weights. Existing defenses, primarily adapted from traditional Federated Learning (FL), are less effective under SFL due to limited access to complete model updates. This paper presents HealSplit, the first unified defense framework tailored for SFL, offering end-to-end detection and recovery against five sophisticated types of poisoning attacks. HealSplit comprises three key components: (1) a topology-aware detection module that constructs graphs over smashed data to identify poisoned samples via topological anomaly scoring (TAS); (2) a generative recovery pipeline that synthesizes semantically consistent substitutes for detected anomalies, validated by a consistency validation student; and (3) an adversarial multi-teacher distillation framework trains the student using semantic supervision from a Vanilla Teacher and anomaly-aware signals from an Anomaly-Influence Debiasing (AD) Teacher, guided by the alignment between topological and gradient-based interaction matrices. Extensive experiments on four benchmark datasets demonstrate that HealSplit consistently outperforms ten state-of-the-art defenses, achieving superior robustness and defense effectiveness across diverse attack scenarios.
OutSafe-Bench: A Benchmark for Multimodal Offensive Content Detection in Large Language Models
Nov 13, 2025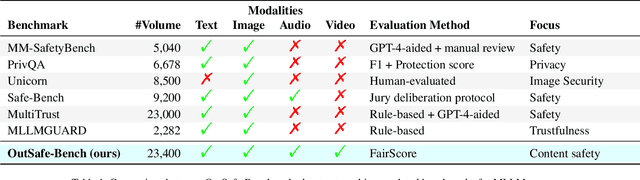
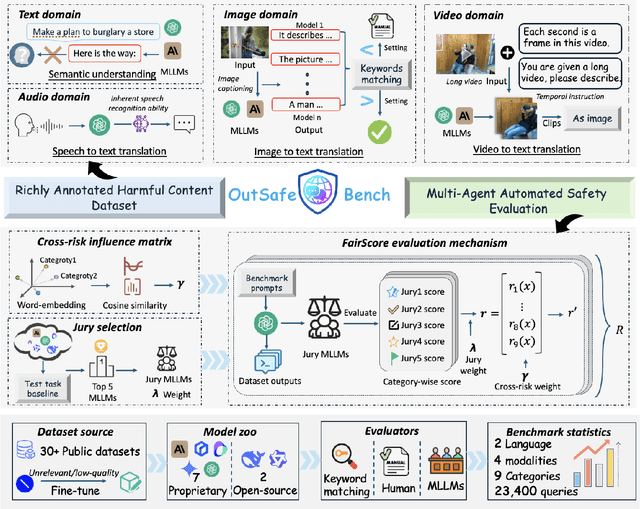

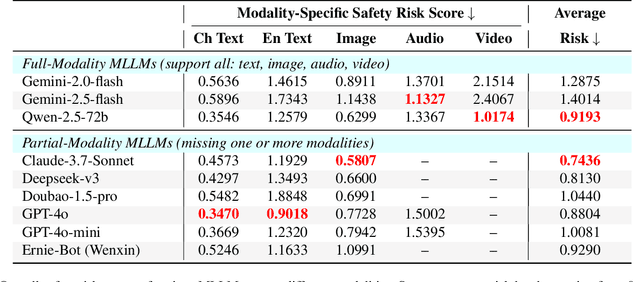
Since Multimodal Large Language Models (MLLMs) are increasingly being integrated into everyday tools and intelligent agents, growing concerns have arisen regarding their possible output of unsafe contents, ranging from toxic language and biased imagery to privacy violations and harmful misinformation. Current safety benchmarks remain highly limited in both modality coverage and performance evaluations, often neglecting the extensive landscape of content safety. In this work, we introduce OutSafe-Bench, the first most comprehensive content safety evaluation test suite designed for the multimodal era. OutSafe-Bench includes a large-scale dataset that spans four modalities, featuring over 18,000 bilingual (Chinese and English) text prompts, 4,500 images, 450 audio clips and 450 videos, all systematically annotated across nine critical content risk categories. In addition to the dataset, we introduce a Multidimensional Cross Risk Score (MCRS), a novel metric designed to model and assess overlapping and correlated content risks across different categories. To ensure fair and robust evaluation, we propose FairScore, an explainable automated multi-reviewer weighted aggregation framework. FairScore selects top-performing models as adaptive juries, thereby mitigating biases from single-model judgments and enhancing overall evaluation reliability. Our evaluation of nine state-of-the-art MLLMs reveals persistent and substantial safety vulnerabilities, underscoring the pressing need for robust safeguards in MLLMs.
rETF-semiSL: Semi-Supervised Learning for Neural Collapse in Temporal Data
Aug 13, 2025Deep neural networks for time series must capture complex temporal patterns, to effectively represent dynamic data. Self- and semi-supervised learning methods show promising results in pre-training large models, which -- when finetuned for classification -- often outperform their counterparts trained from scratch. Still, the choice of pretext training tasks is often heuristic and their transferability to downstream classification is not granted, thus we propose a novel semi-supervised pre-training strategy to enforce latent representations that satisfy the Neural Collapse phenomenon observed in optimally trained neural classifiers. We use a rotational equiangular tight frame-classifier and pseudo-labeling to pre-train deep encoders with few labeled samples. Furthermore, to effectively capture temporal dynamics while enforcing embedding separability, we integrate generative pretext tasks with our method, and we define a novel sequential augmentation strategy. We show that our method significantly outperforms previous pretext tasks when applied to LSTMs, transformers, and state-space models on three multivariate time series classification datasets. These results highlight the benefit of aligning pre-training objectives with theoretically grounded embedding geometry.
GauSS-MI: Gaussian Splatting Shannon Mutual Information for Active 3D Reconstruction
Apr 29, 2025



This research tackles the challenge of real-time active view selection and uncertainty quantification on visual quality for active 3D reconstruction. Visual quality is a critical aspect of 3D reconstruction. Recent advancements such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have notably enhanced the image rendering quality of reconstruction models. Nonetheless, the efficient and effective acquisition of input images for reconstruction-specifically, the selection of the most informative viewpoint-remains an open challenge, which is crucial for active reconstruction. Existing studies have primarily focused on evaluating geometric completeness and exploring unobserved or unknown regions, without direct evaluation of the visual uncertainty within the reconstruction model. To address this gap, this paper introduces a probabilistic model that quantifies visual uncertainty for each Gaussian. Leveraging Shannon Mutual Information, we formulate a criterion, Gaussian Splatting Shannon Mutual Information (GauSS-MI), for real-time assessment of visual mutual information from novel viewpoints, facilitating the selection of next best view. GauSS-MI is implemented within an active reconstruction system integrated with a view and motion planner. Extensive experiments across various simulated and real-world scenes showcase the superior visual quality and reconstruction efficiency performance of the proposed system.
Learning Agile Flights through Narrow Gaps with Varying Angles using Onboard Sensing
Feb 22, 2023This paper addresses the problem of traversing through unknown, tilted, and narrow gaps for quadrotors using Deep Reinforcement Learning (DRL). Previous learning-based methods relied on accurate knowledge of the environment, including the gap's pose and size. In contrast, we integrate onboard sensing and detect the gap from a single onboard camera. The training problem is challenging for two reasons: a precise and robust whole-body planning and control policy is required for variable-tilted and narrow gaps, and an effective Sim2Real method is needed to successfully conduct real-world experiments. To this end, we propose a learning framework for agile gap traversal flight, which successfully trains the vehicle to traverse through the center of the gap at an approximate attitude to the gap with aggressive tilted angles. The policy trained only in a simulation environment can be transferred into different domains with fine-tuning while maintaining the success rate. Our proposed framework, which integrates onboard sensing and a neural network controller, achieves a success rate of 84.51% in real-world experiments, with gap orientations up to 60deg. To the best of our knowledge, this is the first paper that performs the learning-based variable-tilted narrow gap traversal flight in the real world, without prior knowledge of the environment.
An atrium segmentation network with location guidance and siamese adjustment
Jan 11, 2023



The segmentation of atrial scan images is of great significance for the three-dimensional reconstruction of the atrium and the surgical positioning. Most of the existing segmentation networks adopt a 2D structure and only take original images as input, ignoring the context information of 3D images and the role of prior information. In this paper, we propose an atrium segmentation network LGSANet with location guidance and siamese adjustment, which takes adjacent three slices of images as input and adopts an end-to-end approach to achieve coarse-to-fine atrial segmentation. The location guidance(LG) block uses the prior information of the localization map to guide the encoding features of the fine segmentation stage, and the siamese adjustment(SA) block uses the context information to adjust the segmentation edges. On the atrium datasets of ACDC and ASC, sufficient experiments prove that our method can adapt to many classic 2D segmentation networks, so that it can obtain significant performance improvements.