 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Accuracy of an Event-Based Star Tracker via Earth's Rotation
Sep 10, 2025Event-based cameras (EBCs) are a promising new technology for star tracking-based attitude determination, but prior studies have struggled to determine accurate ground truth for real data. We analyze the accuracy of an EBC star tracking system utilizing the Earth's motion as the ground truth for comparison. The Earth rotates in a regular way with very small irregularities which are measured to the level of milli-arcseconds. By keeping an event camera static and pointing it through a ground-based telescope at the night sky, we create a system where the only camera motion in the celestial reference frame is that induced by the Earth's rotation. The resulting event stream is processed to generate estimates of orientation which we compare to the International Earth Rotation and Reference System (IERS) measured orientation of the Earth. The event camera system is able to achieve a root mean squared across error of 18.47 arcseconds and an about error of 78.84 arcseconds. Combined with the other benefits of event cameras over framing sensors (reduced computation due to sparser data streams, higher dynamic range, lower energy consumption, faster update rates), this level of accuracy suggests the utility of event cameras for low-cost and low-latency star tracking. We provide all code and data used to generate our results: https://gitlab.kitware.com/nest-public/telescope_accuracy_quantification.
EBS-EKF: Accurate and High Frequency Event-based Star Tracking
Mar 25, 2025



Event-based sensors (EBS) are a promising new technology for star tracking due to their low latency and power efficiency, but prior work has thus far been evaluated exclusively in simulation with simplified signal models. We propose a novel algorithm for event-based star tracking, grounded in an analysis of the EBS circuit and an extended Kalman filter (EKF). We quantitatively evaluate our method using real night sky data, comparing its results with those from a space-ready active-pixel sensor (APS) star tracker. We demonstrate that our method is an order-of-magnitude more accurate than existing methods due to improved signal modeling and state estimation, while providing more frequent updates and greater motion tolerance than conventional APS trackers. We provide all code and the first dataset of events synchronized with APS solutions.
MEVID: Multi-view Extended Videos with Identities for Video Person Re-Identification
Nov 10, 2022In this paper, we present the Multi-view Extended Videos with Identities (MEVID) dataset for large-scale, video person re-identification (ReID) in the wild. To our knowledge, MEVID represents the most-varied video person ReID dataset, spanning an extensive indoor and outdoor environment across nine unique dates in a 73-day window, various camera viewpoints, and entity clothing changes. Specifically, we label the identities of 158 unique people wearing 598 outfits taken from 8, 092 tracklets, average length of about 590 frames, seen in 33 camera views from the very large-scale MEVA person activities dataset. While other datasets have more unique identities, MEVID emphasizes a richer set of information about each individual, such as: 4 outfits/identity vs. 2 outfits/identity in CCVID, 33 viewpoints across 17 locations vs. 6 in 5 simulated locations for MTA, and 10 million frames vs. 3 million for LS-VID. Being based on the MEVA video dataset, we also inherit data that is intentionally demographically balanced to the continental United States. To accelerate the annotation process, we developed a semi-automatic annotation framework and GUI that combines state-of-the-art real-time models for object detection, pose estimation, person ReID, and multi-object tracking. We evaluate several state-of-the-art methods on MEVID challenge problems and comprehensively quantify their robustness in terms of changes of outfit, scale, and background location. Our quantitative analysis on the realistic, unique aspects of MEVID shows that there are significant remaining challenges in video person ReID and indicates important directions for future research.
Source Generator Attribution via Inversion
May 06, 2019

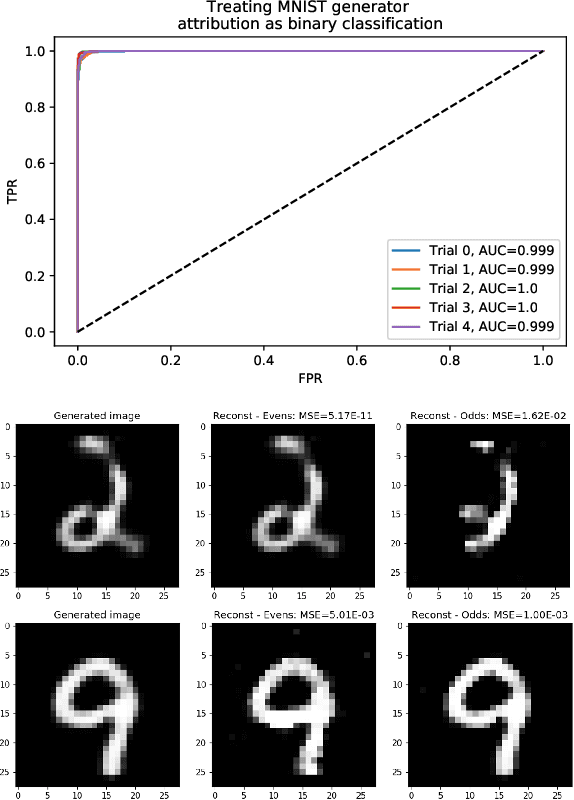
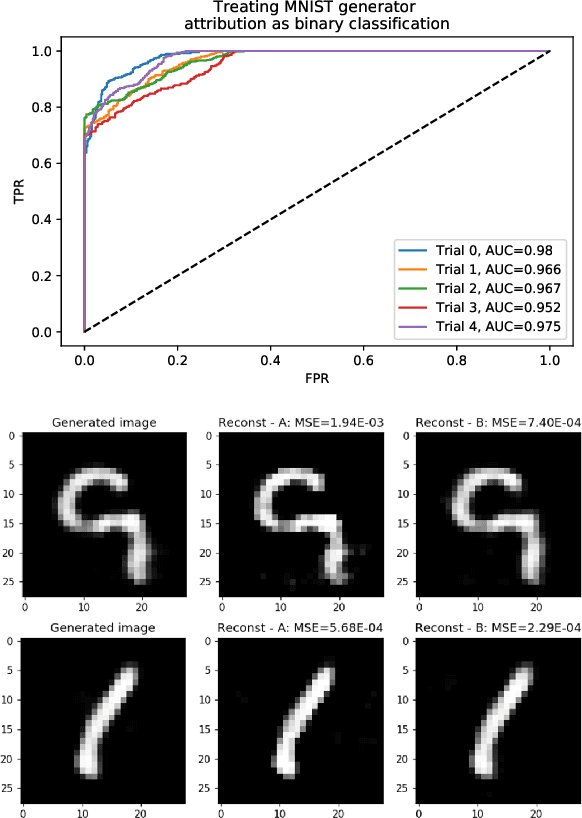
With advances in Generative Adversarial Networks (GANs) leading to dramatically-improved synthetic images and video, there is an increased need for algorithms which extend traditional forensics to this new category of imagery. While GANs have been shown to be helpful in a number of computer vision applications, there are other problematic uses such as `deep fakes' which necessitate such forensics. Source camera attribution algorithms using various cues have addressed this need for imagery captured by a camera, but there are fewer options for synthetic imagery. We address the problem of attributing a synthetic image to a specific generator in a white box setting, by inverting the process of generation. This enables us to simultaneously determine whether the generator produced the image and recover an input which produces a close match to the synthetic image.
Bridging the Gap Between Computational Photography and Visual Recognition
Jan 28, 2019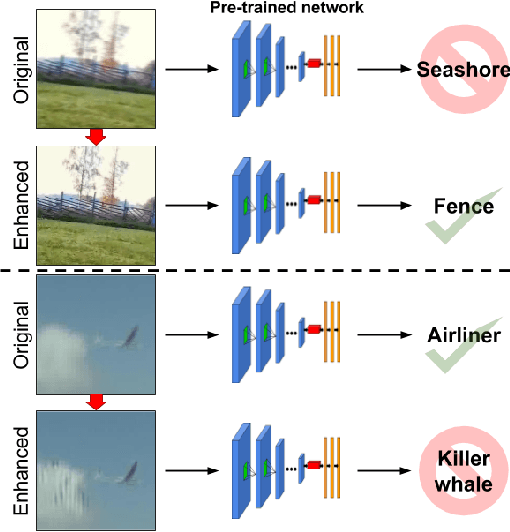
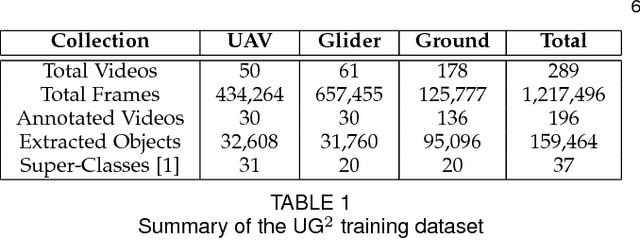

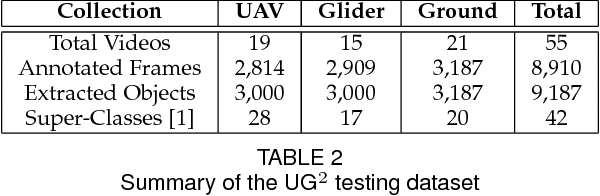
What is the current state-of-the-art for image restoration and enhancement applied to degraded images acquired under less than ideal circumstances? Can the application of such algorithms as a pre-processing step to improve image interpretability for manual analysis or automatic visual recognition to classify scene content? While there have been important advances in the area of computational photography to restore or enhance the visual quality of an image, the capabilities of such techniques have not always translated in a useful way to visual recognition tasks. Consequently, there is a pressing need for the development of algorithms that are designed for the joint problem of improving visual appearance and recognition, which will be an enabling factor for the deployment of visual recognition tools in many real-world scenarios. To address this, we introduce the UG^2 dataset as a large-scale benchmark composed of video imagery captured under challenging conditions, and two enhancement tasks designed to test algorithmic impact on visual quality and automatic object recognition. Furthermore, we propose a set of metrics to evaluate the joint improvement of such tasks as well as individual algorithmic advances, including a novel psychophysics-based evaluation regime for human assessment and a realistic set of quantitative measures for object recognition performance. We introduce six new algorithms for image restoration or enhancement, which were created as part of the IARPA sponsored UG^2 Challenge workshop held at CVPR 2018. Under the proposed evaluation regime, we present an in-depth analysis of these algorithms and a host of deep learning-based and classic baseline approaches. From the observed results, it is evident that we are in the early days of building a bridge between computational photography and visual recognition, leaving many opportunities for innovation in this area.
Detecting GAN-generated Imagery using Color Cues
Dec 19, 2018
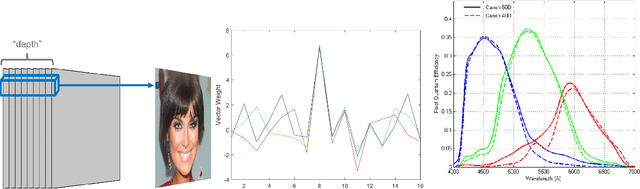
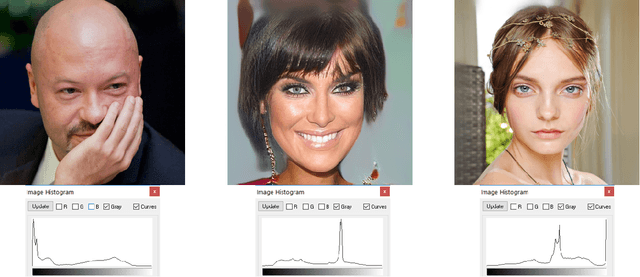
Image forensics is an increasingly relevant problem, as it can potentially address online disinformation campaigns and mitigate problematic aspects of social media. Of particular interest, given its recent successes, is the detection of imagery produced by Generative Adversarial Networks (GANs), e.g. `deepfakes'. Leveraging large training sets and extensive computing resources, recent work has shown that GANs can be trained to generate synthetic imagery which is (in some ways) indistinguishable from real imagery. We analyze the structure of the generating network of a popular GAN implementation, and show that the network's treatment of color is markedly different from a real camera in two ways. We further show that these two cues can be used to distinguish GAN-generated imagery from camera imagery, demonstrating effective discrimination between GAN imagery and real camera images used to train the GAN.