 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An adaptive multi-fidelity framework for safety analysis of connected and automated vehicles
Oct 25, 2022
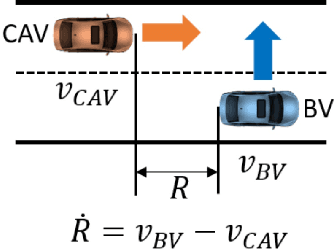
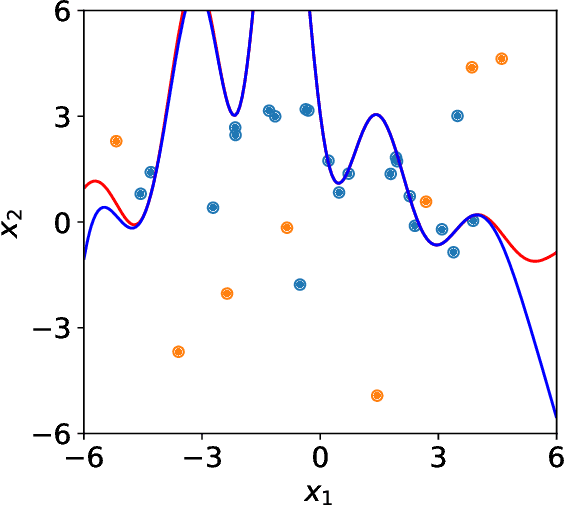
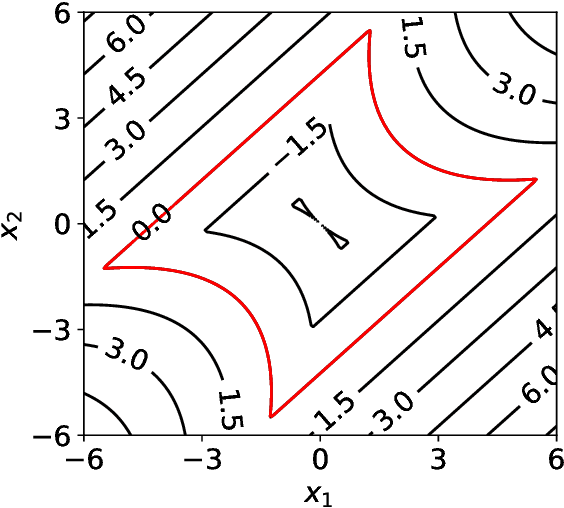
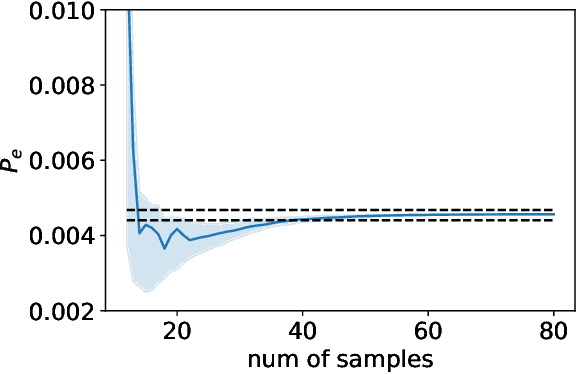
Testing and evaluation are expensive but critical steps in the development and deployment of connected and automated vehicles (CAVs). In this paper, we develop an adaptive sampling framework to efficiently evaluate the accident rate of CAVs, particularly for scenario-based tests where the probability distribution of input parameters is known from the Naturalistic Driving Data. Our framework relies on a surrogate model to approximate the CAV performance and a novel acquisition function to maximize the benefit (information to accident rate) of the next sample formulated through an information-theoretic consideration. In addition to the standard application with only a single high-fidelity model of CAV performance, we also extend our approach to the bi-fidelity context where an additional low-fidelity model can be used at a lower computational cost to approximate the CAV performance. Accordingly for the second case, our approach is formulated such that it allows the choice of the next sample, in terms of both fidelity level (i.e., which model to use) and sampling location to maximize the benefit per cost. Our framework is tested in a widely-considered two-dimensional cut-in problem for CAVs, where Intelligent Driving Model (IDM) with different time resolutions are used to construct the high and low-fidelity models. We show that our single-fidelity method outperforms the existing approach for the same problem, and the bi-fidelity method can further save half of the computational cost to reach a similar accuracy in estimating the accident rate.
Why self-attention is Natural for Sequence-to-Sequence Problems? A Perspective from Symmetries
Oct 13, 2022In this paper, we show that structures similar to self-attention are natural to learn many sequence-to-sequence problems from the perspective of symmetry. Inspired by language processing applications, we study the orthogonal equivariance of seq2seq functions with knowledge, which are functions taking two inputs -- an input sequence and a ``knowledge'' -- and outputting another sequence. The knowledge consists of a set of vectors in the same embedding space as the input sequence, containing the information of the language used to process the input sequence. We show that orthogonal equivariance in the embedding space is natural for seq2seq functions with knowledge, and under such equivariance the function must take the form close to the self-attention. This shows that network structures similar to self-attention are the right structures to represent the target function of many seq2seq problems. The representation can be further refined if a ``finite information principle'' is considered, or a permutation equivariance holds for the elements of the input sequence.
JoJoNet: Joint-contrast and Joint-sampling-and-reconstruction Network for Multi-contrast MRI
Oct 27, 2022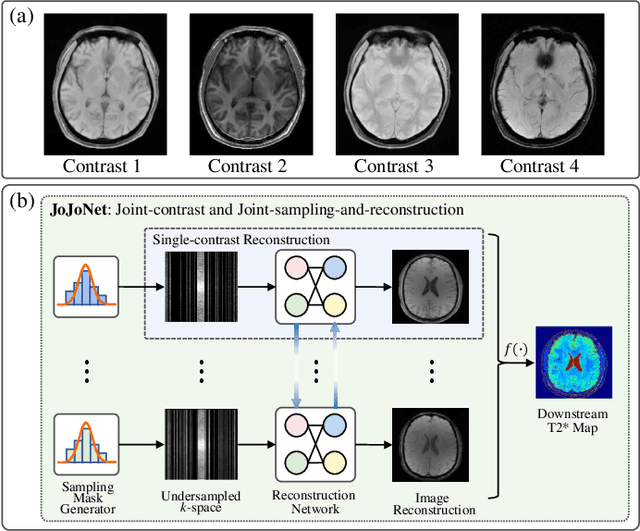
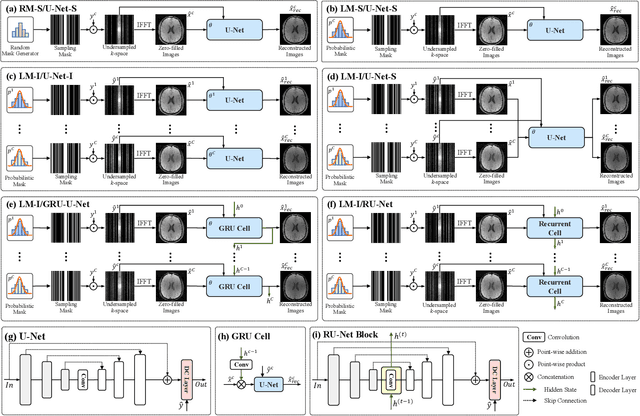
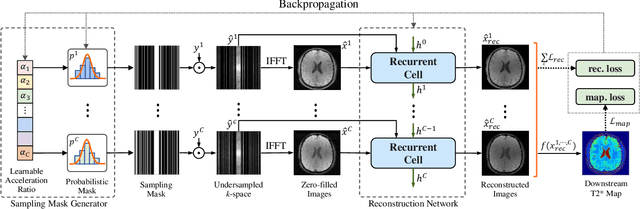
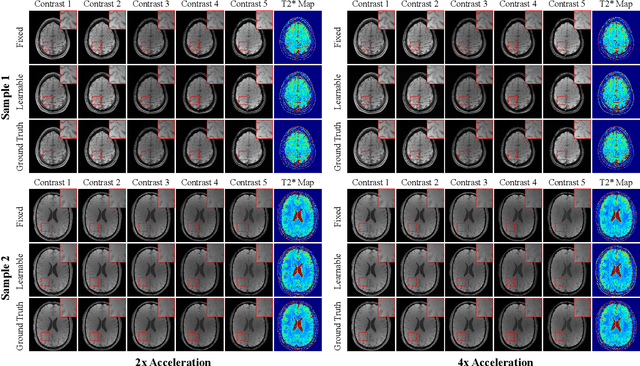
Multi-contrast Magnetic Resonance Imaging (MRI) generates multiple medical images with rich and complementary information for routine clinical use; however, it suffers from a long acquisition time. Recent works for accelerating MRI, mainly designed for single contrast, may not be optimal for multi-contrast scenario since the inherent correlations among the multi-contrast images are not exploited. In addition, independent reconstruction of each contrast usually does not translate to optimal performance of downstream tasks. Motivated by these aspects, in this paper we design an end-to-end framework for accelerating multi-contrast MRI which simultaneously optimizes the entire MR imaging workflow including sampling, reconstruction and downstream tasks to achieve the best overall outcomes. The proposed framework consists of a sampling mask generator for each image contrast and a reconstructor exploiting the inter-contrast correlations with a recurrent structure which enables the information sharing in a holistic way. The sampling mask generator and the reconstructor are trained jointly across the multiple image contrasts. The acceleration ratio of each image contrast is also learnable and can be driven by a downstream task performance. We validate our approach on a multi-contrast brain dataset and a multi-contrast knee dataset. Experiments show that (1) our framework consistently outperforms the baselines designed for single contrast on both datasets; (2) our newly designed recurrent reconstruction network effectively improves the reconstruction quality for multi-contrast images; (3) the learnable acceleration ratio improves the downstream task performance significantly. Overall, this work has potentials to open up new avenues for optimizing the entire multi-contrast MR imaging workflow.
InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
Nov 13, 2022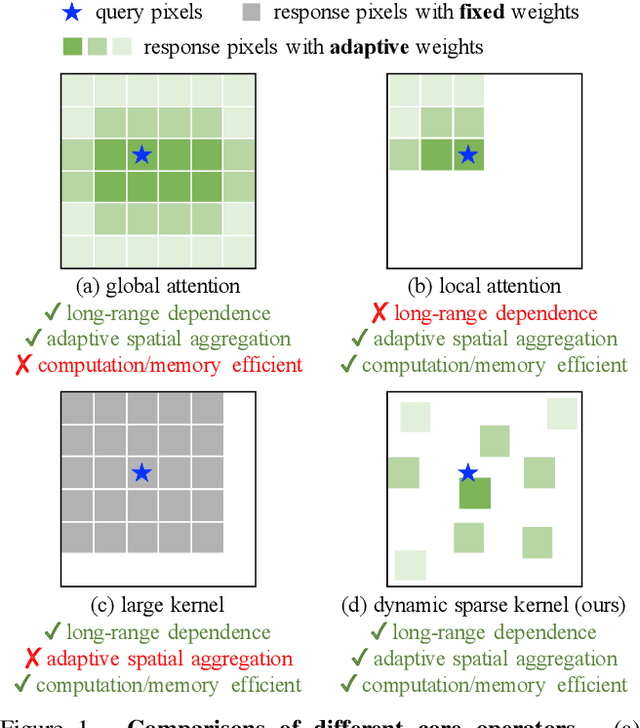
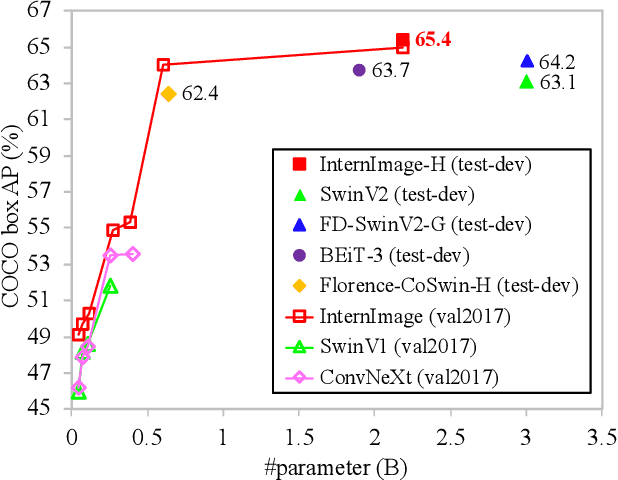
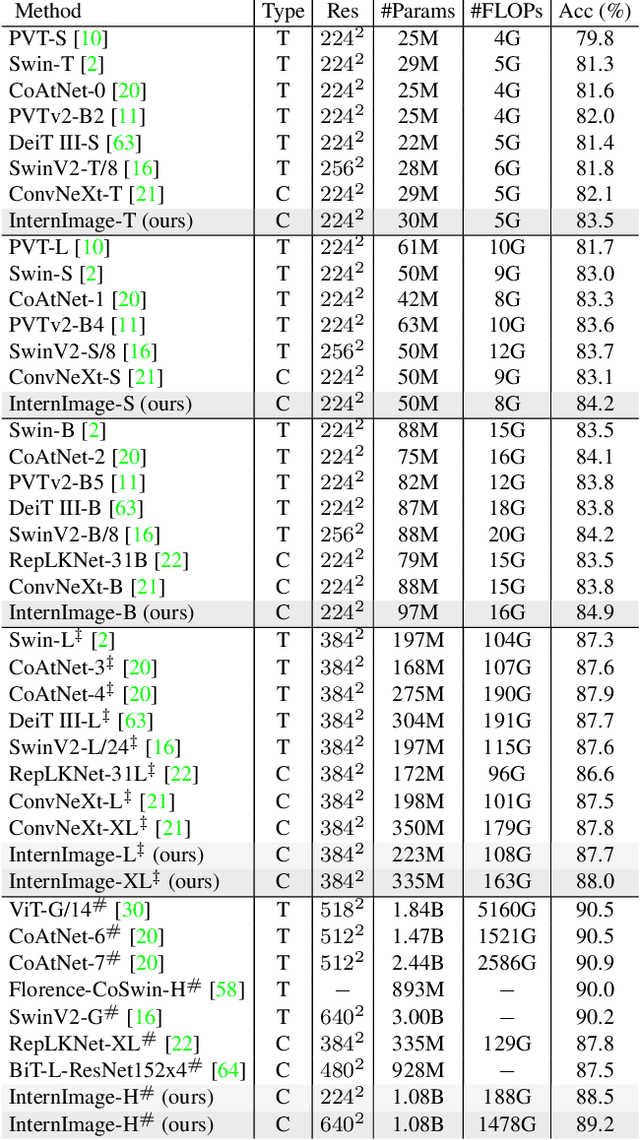
Compared to the great progress of large-scale vision transformers (ViTs) in recent years, large-scale models based on convolutional neural networks (CNNs) are still in an early state. This work presents a new large-scale CNN-based foundation model, termed InternImage, which can obtain the gain from increasing parameters and training data like ViTs. Different from the recent CNNs that focus on large dense kernels, InternImage takes deformable convolution as the core operator, so that our model not only has the large effective receptive field required for downstream tasks such as detection and segmentation, but also has the adaptive spatial aggregation conditioned by input and task information. As a result, the proposed InternImage reduces the strict inductive bias of traditional CNNs and makes it possible to learn stronger and more robust patterns with large-scale parameters from massive data like ViTs. The effectiveness of our model is proven on challenging benchmarks including ImageNet, COCO, and ADE20K. It is worth mentioning that InternImage-H achieved a new record 65.4 mAP on COCO test-dev and 62.9 mIoU on ADE20K, outperforming current leading CNNs and ViTs. The code will be released at https://github.com/OpenGVLab/InternImage.
Learning Stable Graph Neural Networks via Spectral Regularization
Nov 13, 2022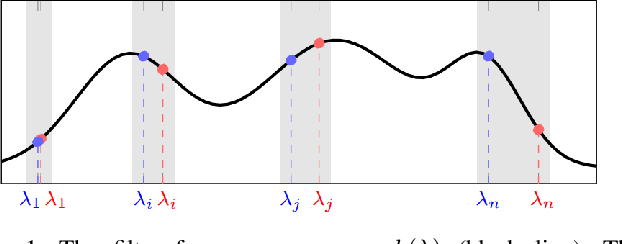
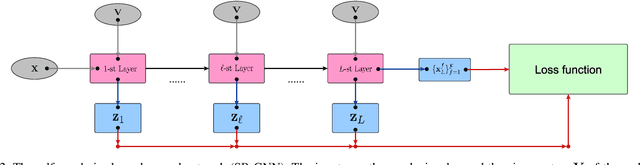
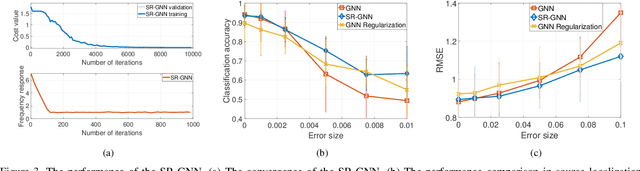
Stability of graph neural networks (GNNs) characterizes how GNNs react to graph perturbations and provides guarantees for architecture performance in noisy scenarios. This paper develops a self-regularized graph neural network (SR-GNN) solution that improves the architecture stability by regularizing the filter frequency responses in the graph spectral domain. The SR-GNN considers not only the graph signal as input but also the eigenvectors of the underlying graph, where the signal is processed to generate task-relevant features and the eigenvectors to characterize the frequency responses at each layer. We train the SR-GNN by minimizing the cost function and regularizing the maximal frequency response close to one. The former improves the architecture performance, while the latter tightens the perturbation stability and alleviates the information loss through multi-layer propagation. We further show the SR-GNN preserves the permutation equivariance, which allows to explore the internal symmetries of graph signals and to exhibit transference on similar graph structures. Numerical results with source localization and movie recommendation corroborate our findings and show the SR-GNN yields a comparable performance with the vanilla GNN on the unperturbed graph but improves substantially the stability.
Conversational Pattern Mining using Motif Detection
Nov 13, 2022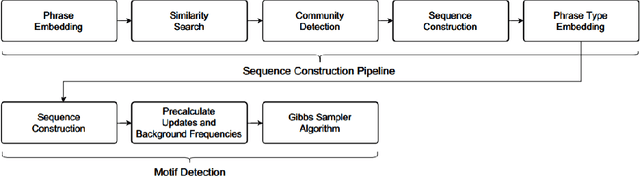
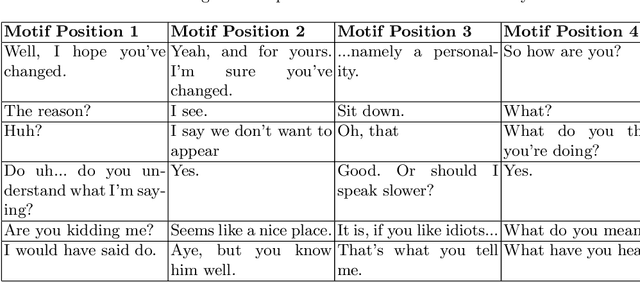
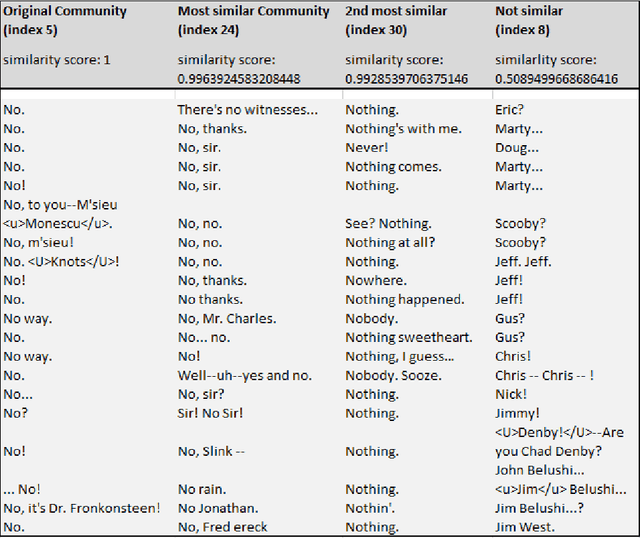
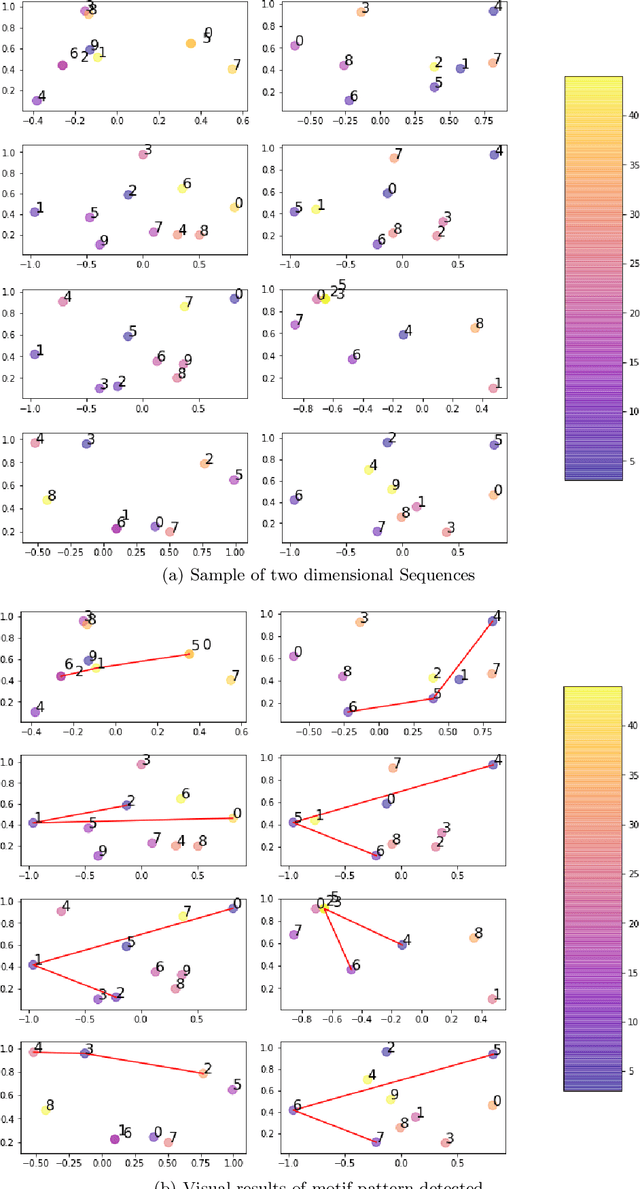
The subject of conversational mining has become of great interest recently due to the explosion of social and other online media. Supplementing this explosion of text is the advancement in pre-trained language models which have helped us to leverage these sources of information. An interesting domain to analyse is conversations in terms of complexity and value. Complexity arises due to the fact that a conversation can be asynchronous and can involve multiple parties. It is also computationally intensive to process. We use unsupervised methods in our work in order to develop a conversational pattern mining technique which does not require time consuming, knowledge demanding and resource intensive labelling exercises. The task of identifying repeating patterns in sequences is well researched in the Bioinformatics field. In our work, we adapt this to the field of Natural Language Processing and make several extensions to a motif detection algorithm. In order to demonstrate the application of the algorithm on a dynamic, real world data set; we extract motifs from an open-source film script data source. We run an exploratory investigation into the types of motifs we are able to mine.
Layerwise Sparsifying Training and Sequential Learning Strategy for Neural Architecture Adaptation
Nov 13, 2022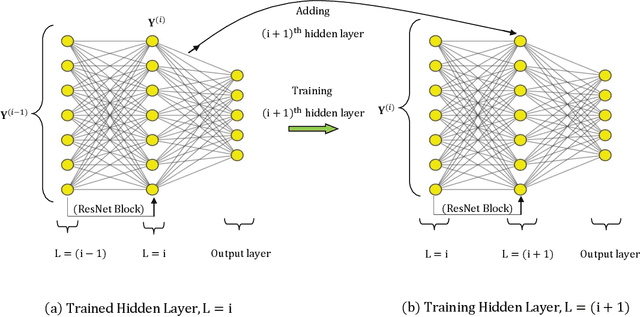
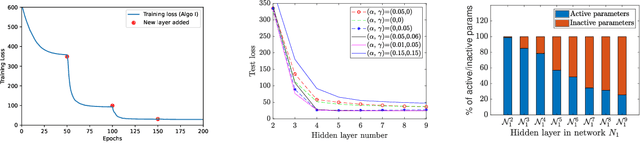


This work presents a two-stage framework for progressively developing neural architectures to adapt/ generalize well on a given training data set. In the first stage, a manifold-regularized layerwise sparsifying training approach is adopted where a new layer is added each time and trained independently by freezing parameters in the previous layers. In order to constrain the functions that should be learned by each layer, we employ a sparsity regularization term, manifold regularization term and a physics-informed term. We derive the necessary conditions for trainability of a newly added layer and analyze the role of manifold regularization. In the second stage of the Algorithm, a sequential learning process is adopted where a sequence of small networks is employed to extract information from the residual produced in stage I and thereby making robust and more accurate predictions. Numerical investigations with fully connected network on prototype regression problem, and classification problem demonstrate that the proposed approach can outperform adhoc baseline networks. Further, application to physics-informed neural network problems suggests that the method could be employed for creating interpretable hidden layers in a deep network while outperforming equivalent baseline networks.
High-order Multi-view Clustering for Generic Data
Sep 22, 2022
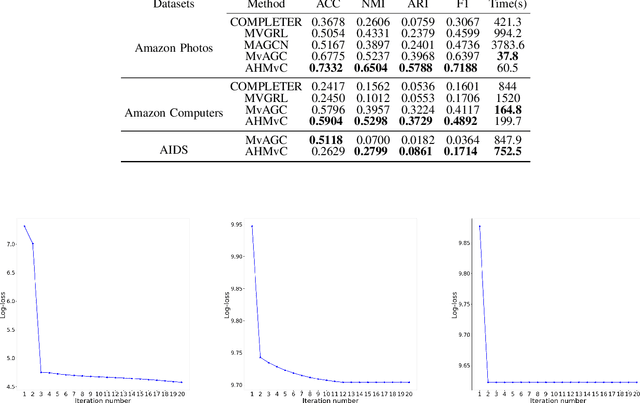
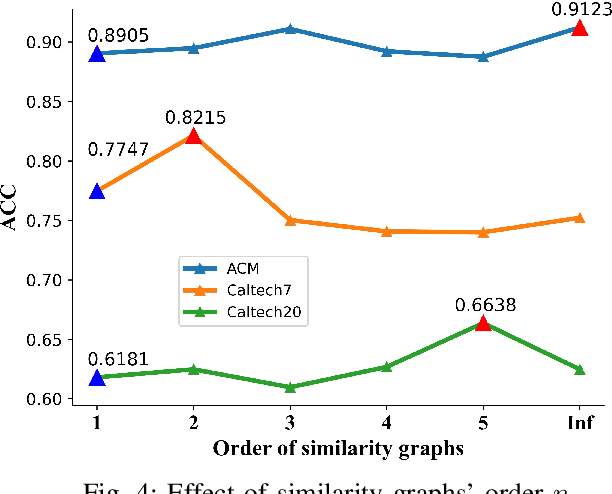
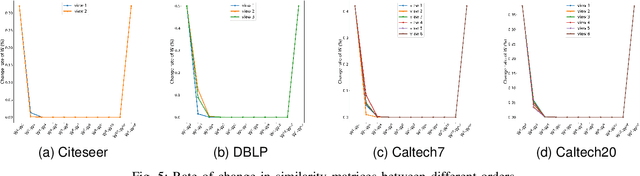
Graph-based multi-view clustering has achieved better performance than most non-graph approaches. However, in many real-world scenarios, the graph structure of data is not given or the quality of initial graph is poor. Additionally, existing methods largely neglect the high-order neighborhood information that characterizes complex intrinsic interactions. To tackle these problems, we introduce an approach called high-order multi-view clustering (HMvC) to explore the topology structure information of generic data. Firstly, graph filtering is applied to encode structure information, which unifies the processing of attributed graph data and non-graph data in a single framework. Secondly, up to infinity-order intrinsic relationships are exploited to enrich the learned graph. Thirdly, to explore the consistent and complementary information of various views, an adaptive graph fusion mechanism is proposed to achieve a consensus graph. Comprehensive experimental results on both non-graph and attributed graph data show the superior performance of our method with respect to various state-of-the-art techniques, including some deep learning methods.
CramNet: Camera-Radar Fusion with Ray-Constrained Cross-Attention for Robust 3D Object Detection
Oct 18, 2022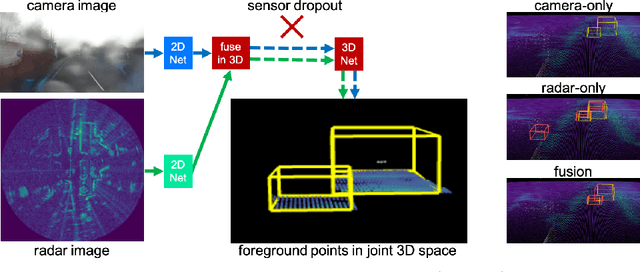

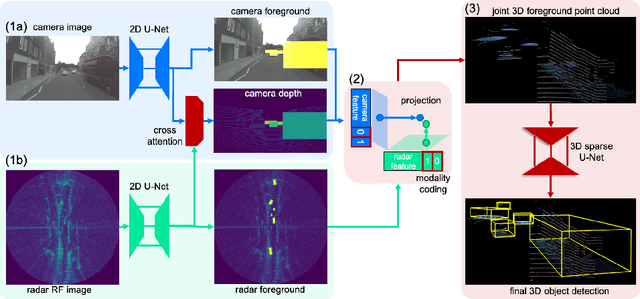
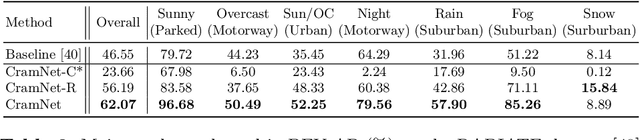
Robust 3D object detection is critical for safe autonomous driving. Camera and radar sensors are synergistic as they capture complementary information and work well under different environmental conditions. Fusing camera and radar data is challenging, however, as each of the sensors lacks information along a perpendicular axis, that is, depth is unknown to camera and elevation is unknown to radar. We propose the camera-radar matching network CramNet, an efficient approach to fuse the sensor readings from camera and radar in a joint 3D space. To leverage radar range measurements for better camera depth predictions, we propose a novel ray-constrained cross-attention mechanism that resolves the ambiguity in the geometric correspondences between camera features and radar features. Our method supports training with sensor modality dropout, which leads to robust 3D object detection, even when a camera or radar sensor suddenly malfunctions on a vehicle. We demonstrate the effectiveness of our fusion approach through extensive experiments on the RADIATE dataset, one of the few large-scale datasets that provide radar radio frequency imagery. A camera-only variant of our method achieves competitive performance in monocular 3D object detection on the Waymo Open Dataset.
Meta-Reinforcement Learning Using Model Parameters
Oct 27, 2022
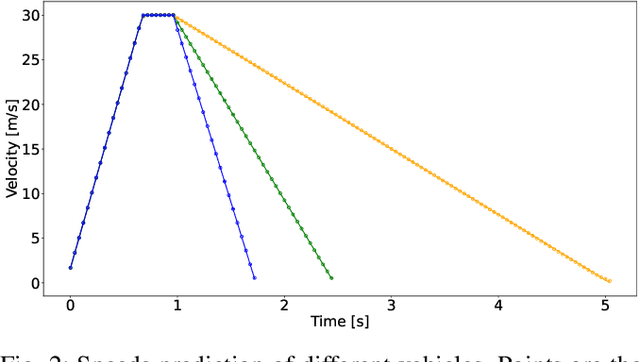
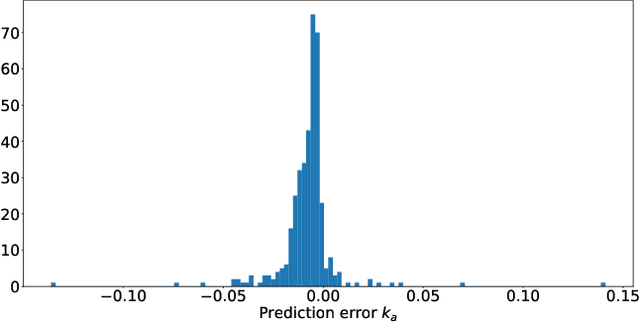
In meta-reinforcement learning, an agent is trained in multiple different environments and attempts to learn a meta-policy that can efficiently adapt to a new environment. This paper presents RAMP, a Reinforcement learning Agent using Model Parameters that utilizes the idea that a neural network trained to predict environment dynamics encapsulates the environment information. RAMP is constructed in two phases: in the first phase, a multi-environment parameterized dynamic model is learned. In the second phase, the model parameters of the dynamic model are used as context for the multi-environment policy of the model-free reinforcement learning agent.