 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
HaptiX: Extending Cobot's Motion Intention Visualization by Haptic Feedback
Oct 28, 2022


Nowadays, robots are found in a growing number of areas where they collaborate closely with humans. Enabled by lightweight materials and safety sensors, these cobots are gaining increasing popularity in domestic care, supporting people with physical impairments in their everyday lives. However, when cobots perform actions autonomously, it remains challenging for human collaborators to understand and predict their behavior, which is crucial for achieving trust and user acceptance. One significant aspect of predicting cobot behavior is understanding their motion intention and comprehending how they "think" about their actions. Moreover, other information sources often occupy human visual and audio modalities, rendering them frequently unsuitable for transmitting such information. We work on a solution that communicates cobot intention via haptic feedback to tackle this challenge. In our concept, we map planned motions of the cobot to different haptic patterns to extend the visual intention feedback.
Parameter-free Online Linear Optimization with Side Information via Universal Coin Betting
Feb 04, 2022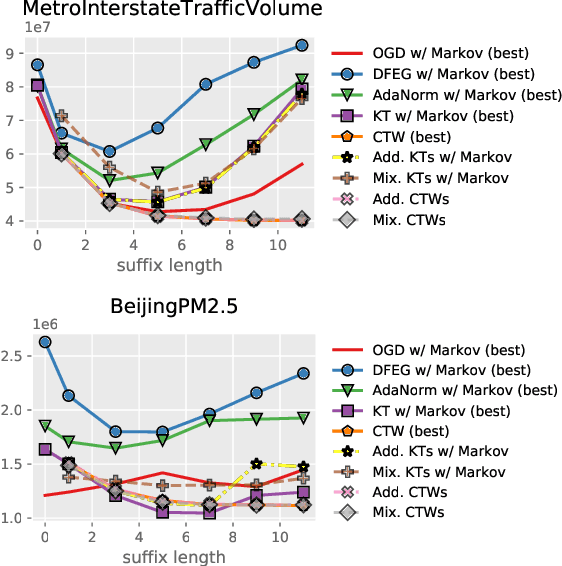
A class of parameter-free online linear optimization algorithms is proposed that harnesses the structure of an adversarial sequence by adapting to some side information. These algorithms combine the reduction technique of Orabona and P{\'a}l (2016) for adapting coin betting algorithms for online linear optimization with universal compression techniques in information theory for incorporating sequential side information to coin betting. Concrete examples are studied in which the side information has a tree structure and consists of quantized values of the previous symbols of the adversarial sequence, including fixed-order and variable-order Markov cases. By modifying the context-tree weighting technique of Willems, Shtarkov, and Tjalkens (1995), the proposed algorithm is further refined to achieve the best performance over all adaptive algorithms with tree-structured side information of a given maximum order in a computationally efficient manner.
Spatio-Temporal Meta-Graph Learning for Traffic Forecasting
Nov 27, 2022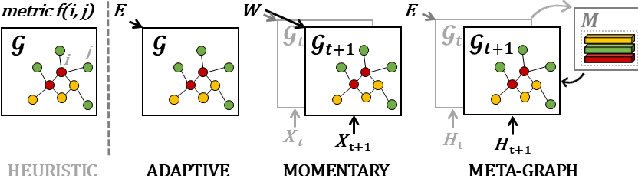

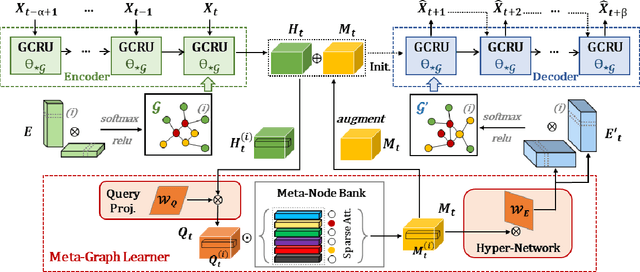
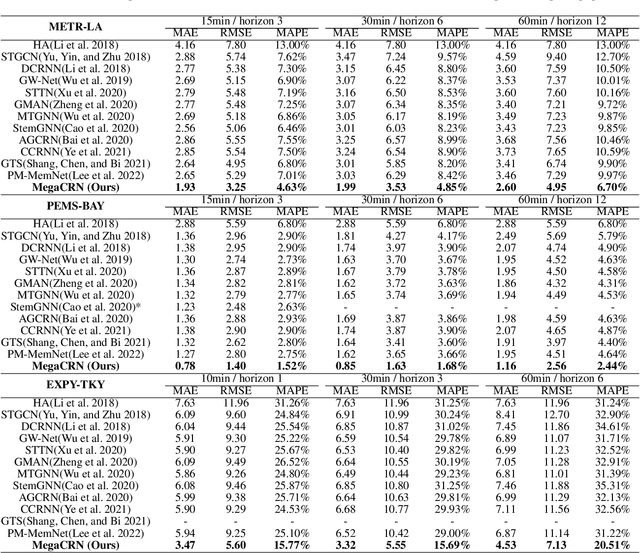
Traffic forecasting as a canonical task of multivariate time series forecasting has been a significant research topic in AI community. To address the spatio-temporal heterogeneity and non-stationarity implied in the traffic stream, in this study, we propose Spatio-Temporal Meta-Graph Learning as a novel Graph Structure Learning mechanism on spatio-temporal data. Specifically, we implement this idea into Meta-Graph Convolutional Recurrent Network (MegaCRN) by plugging the Meta-Graph Learner powered by a Meta-Node Bank into GCRN encoder-decoder. We conduct a comprehensive evaluation on two benchmark datasets (METR-LA and PEMS-BAY) and a new large-scale traffic speed dataset in which traffic incident information is contained. Our model outperformed the state-of-the-arts to a large degree on all three datasets (over 27% MAE and 34% RMSE). Besides, through a series of qualitative evaluations, we demonstrate that our model can explicitly disentangle the road links and time slots with different patterns and be robustly adaptive to any anomalous traffic situations. Codes and datasets are available at https://github.com/deepkashiwa20/MegaCRN.
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
Nov 27, 2022
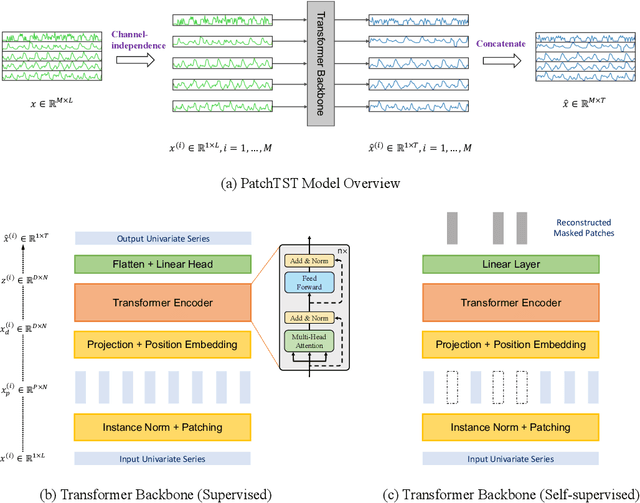

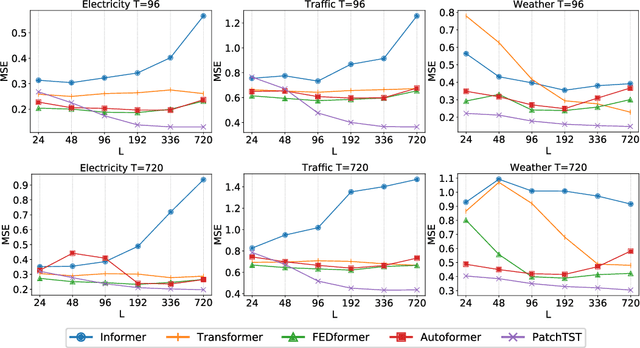
We propose an efficient design of Transformer-based models for multivariate time series forecasting and self-supervised representation learning. It is based on two key components: (i) segmentation of time series into subseries-level patches which are served as input tokens to Transformer; (ii) channel-independence where each channel contains a single univariate time series that shares the same embedding and Transformer weights across all the series. Patching design naturally has three-fold benefit: local semantic information is retained in the embedding; computation and memory usage of the attention maps are quadratically reduced given the same look-back window; and the model can attend longer history. Our channel-independent patch time series Transformer (PatchTST) can improve the long-term forecasting accuracy significantly when compared with that of SOTA Transformer-based models. We also apply our model to self-supervised pre-training tasks and attain excellent fine-tuning performance, which outperforms supervised training on large datasets. Transferring of masked pre-trained representation on one dataset to others also produces SOTA forecasting accuracy. Code is available at: https://github.com/yuqinie98/PatchTST.
ReGrAt: Regularization in Graphs using Attention to handle class imbalance
Nov 27, 2022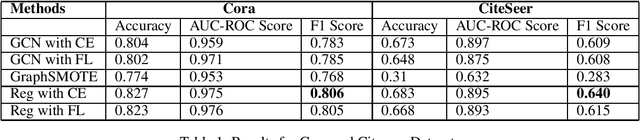
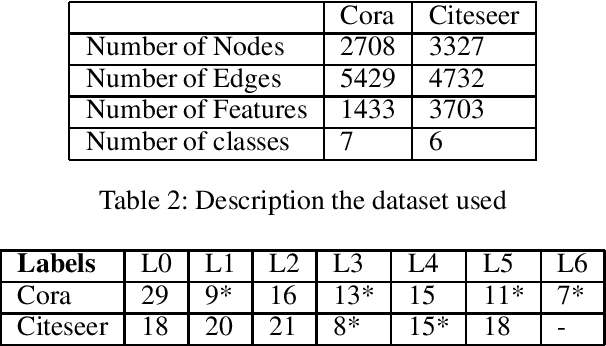
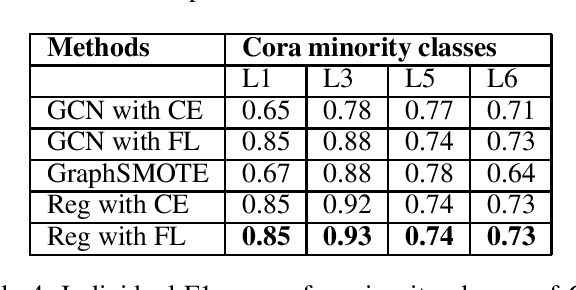
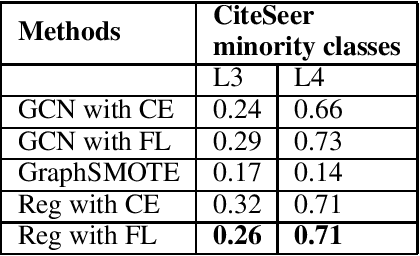
Node classification is an important task to solve in graph-based learning. Even though a lot of work has been done in this field, imbalance is neglected. Real-world data is not perfect, and is imbalanced in representations most of the times. Apart from text and images, data can be represented using graphs, and thus addressing the imbalance in graphs has become of paramount importance. In the context of node classification, one class has less examples than others. Changing data composition is a popular way to address the imbalance in node classification. This is done by resampling the data to balance the dataset. However, that can sometimes lead to loss of information or add noise to the dataset. Therefore, in this work, we implicitly solve the problem by changing the model loss. Specifically, we study how attention networks can help tackle imbalance. Moreover, we observe that using a regularizer to assign larger weights to minority nodes helps to mitigate this imbalance. We achieve State of the Art results than the existing methods on several standard citation benchmark datasets.
ConstGCN: Constrained Transmission-based Graph Convolutional Networks for Document-level Relation Extraction
Oct 08, 2022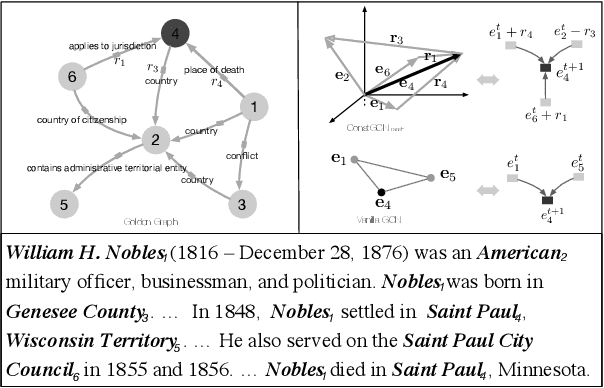

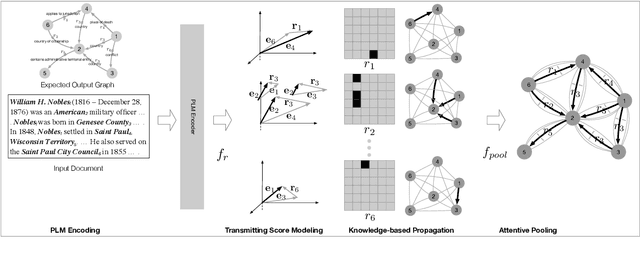
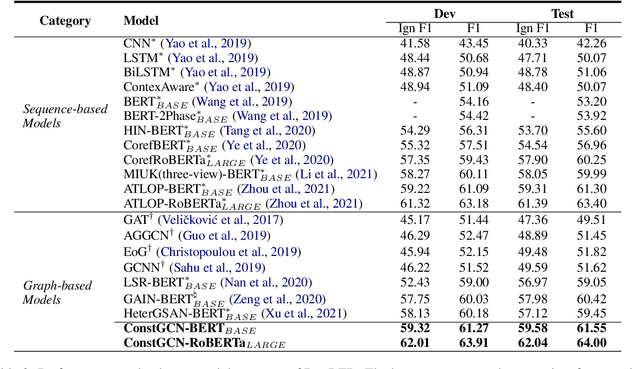
Document-level relation extraction with graph neural networks faces a fundamental graph construction gap between training and inference - the golden graph structure only available during training, which causes that most methods adopt heuristic or syntactic rules to construct a prior graph as a pseudo proxy. In this paper, we propose $\textbf{ConstGCN}$, a novel graph convolutional network which performs knowledge-based information propagation between entities along with all specific relation spaces without any prior graph construction. Specifically, it updates the entity representation by aggregating information from all other entities along with each relation space, thus modeling the relation-aware spatial information. To control the information flow passing through the indeterminate relation spaces, we propose to constrain the propagation using transmitting scores learned from the Noise Contrastive Estimation between fact triples. Experimental results show that our method outperforms the previous state-of-the-art (SOTA) approaches on the DocRE dataset.
Paint by Example: Exemplar-based Image Editing with Diffusion Models
Nov 23, 2022


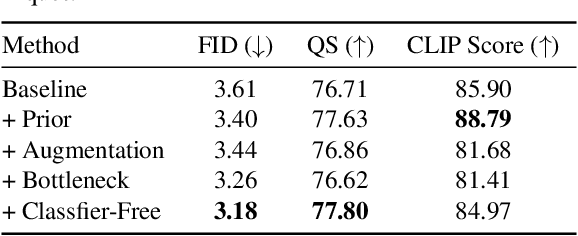
Language-guided image editing has achieved great success recently. In this paper, for the first time, we investigate exemplar-guided image editing for more precise control. We achieve this goal by leveraging self-supervised training to disentangle and re-organize the source image and the exemplar. However, the naive approach will cause obvious fusing artifacts. We carefully analyze it and propose an information bottleneck and strong augmentations to avoid the trivial solution of directly copying and pasting the exemplar image. Meanwhile, to ensure the controllability of the editing process, we design an arbitrary shape mask for the exemplar image and leverage the classifier-free guidance to increase the similarity to the exemplar image. The whole framework involves a single forward of the diffusion model without any iterative optimization. We demonstrate that our method achieves an impressive performance and enables controllable editing on in-the-wild images with high fidelity.
Lite-Mono: A Lightweight CNN and Transformer Architecture for Self-Supervised Monocular Depth Estimation
Nov 23, 2022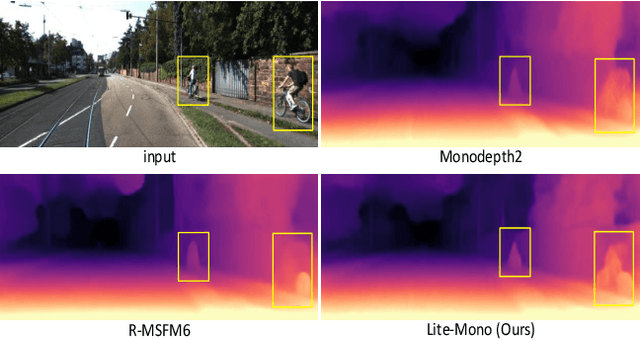
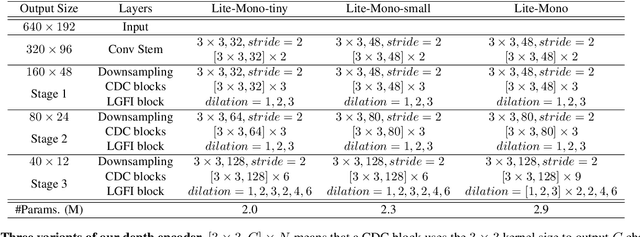
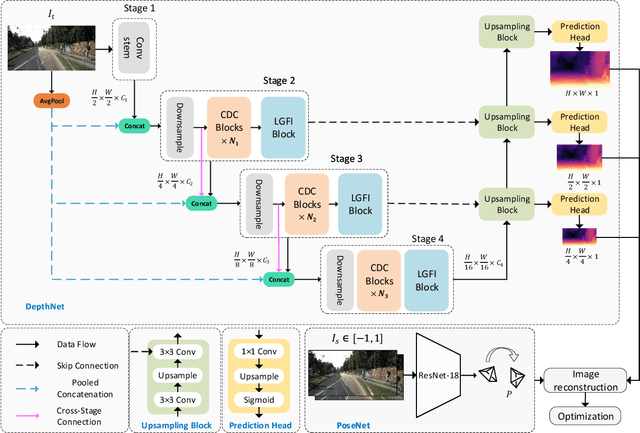
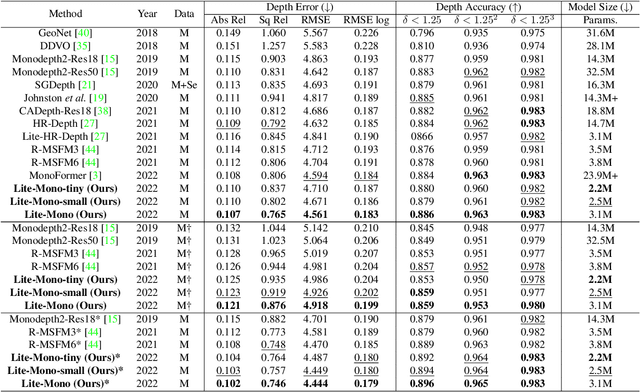
Self-supervised monocular depth estimation that does not require ground-truth for training has attracted attention in recent years. It is of high interest to design lightweight but effective models, so that they can be deployed on edge devices. Many existing architectures benefit from using heavier backbones at the expense of model sizes. In this paper we achieve comparable results with a lightweight architecture. Specifically, we investigate the efficient combination of CNNs and Transformers, and design a hybrid architecture Lite-Mono. A Consecutive Dilated Convolutions (CDC) module and a Local-Global Features Interaction (LGFI) module are proposed. The former is used to extract rich multi-scale local features, and the latter takes advantage of the self-attention mechanism to encode long-range global information into the features. Experiments demonstrate that our full model outperforms Monodepth2 by a large margin in accuracy, with about 80% fewer trainable parameters.
UnifiedABSA: A Unified ABSA Framework Based on Multi-task Instruction Tuning
Nov 20, 2022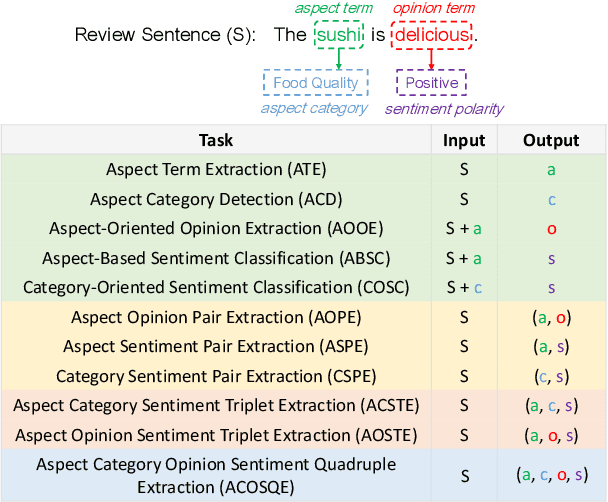
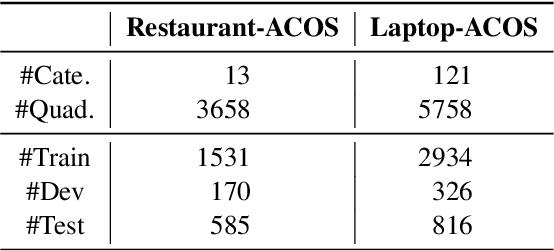
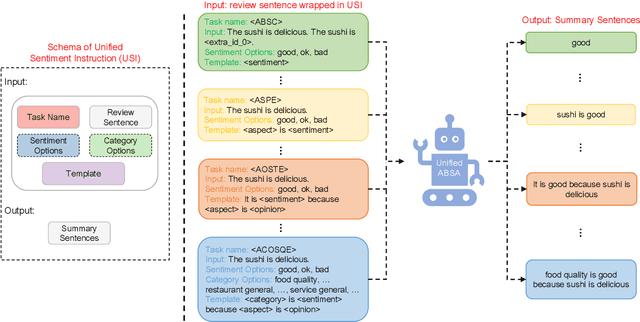
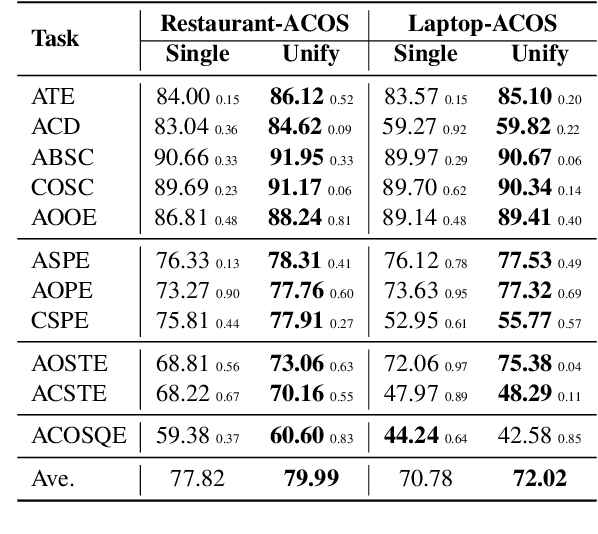
Aspect-Based Sentiment Analysis (ABSA) aims to provide fine-grained aspect-level sentiment information. There are many ABSA tasks, and the current dominant paradigm is to train task-specific models for each task. However, application scenarios of ABSA tasks are often diverse. This solution usually requires a large amount of labeled data from each task to perform excellently. These dedicated models are separately trained and separately predicted, ignoring the relationship between tasks. To tackle these issues, we present UnifiedABSA, a general-purpose ABSA framework based on multi-task instruction tuning, which can uniformly model various tasks and capture the inter-task dependency with multi-task learning. Extensive experiments on two benchmark datasets show that UnifiedABSA can significantly outperform dedicated models on 11 ABSA tasks and show its superiority in terms of data efficiency.
XAI-Increment: A Novel Approach Leveraging LIME Explanations for Improved Incremental Learning
Nov 02, 2022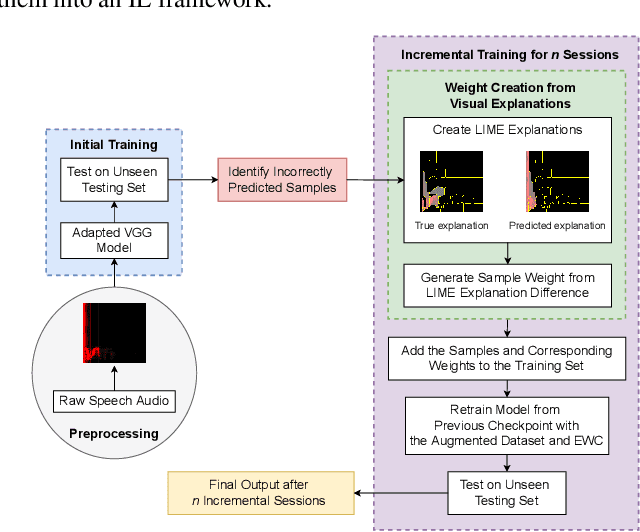
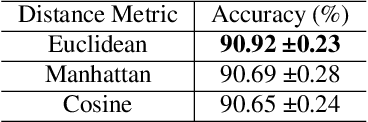

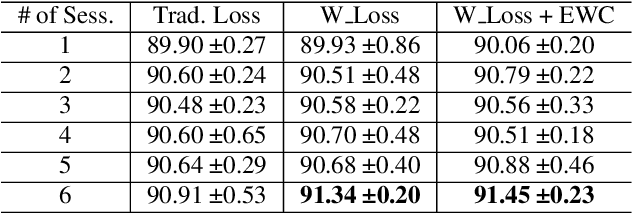
Explainability of neural network prediction is essential to understand feature importance and gain interpretable insight into neural network performance. In this work, model explanations are fed back to the feed-forward training to help the model generalize better. To this extent, a custom weighted loss where the weights are generated by considering the Euclidean distances between true LIME (Local Interpretable Model-Agnostic Explanations) explanations and model-predicted LIME explanations is proposed. Also, in practical training scenarios, developing a solution that can help the model learn sequentially without losing information on previous data distribution is imperative due to the unavailability of all the training data at once. Thus, the framework known as XAI-Increment incorporates the custom weighted loss developed with elastic weight consolidation (EWC), to maintain performance in sequential testing sets. Finally, the training procedure involving the custom weighted loss shows around 1% accuracy improvement compared to the traditional loss based training for the keyword spotting task on the Google Speech Commands dataset and also shows low loss of information when coupled with EWC in the incremental learning setup.