 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Steering for Multilingual In-Context Learning
Feb 02, 2026While multilingual large language models have gained widespread adoption, their performance on non-English languages remains substantially inferior to English. This disparity is particularly evident in in-context learning scenarios, where providing demonstrations in English but testing on non-English inputs leads to significant performance degradation. In this paper, we hypothesize that LLMs develop a universal semantic space for understanding languages, where different languages are encoded as distinct directions within this space. Based on this hypothesis, we propose language vectors -- a training-free language steering approach that leverages activation differences between source and target languages to guide model behavior. We steer the model generations by adding the vector to the intermediate model activations during inference. This is done to make the model's internal representations shift towards the target language space without any parameter updates. We evaluate our method across three datasets and test on a total of 19 languages on three different models. Our results show consistent improvements on multilingual in-context learning over baselines across all tasks and languages tested. Beyond performance gains, hierarchical clustering of steering vectors reveals meaningful linguistic structure aligned with language families. These vectors also successfully transfer across tasks, demonstrating that these representations are task-agnostic.
LLMs are Vulnerable to Malicious Prompts Disguised as Scientific Language
Jan 23, 2025As large language models (LLMs) have been deployed in various real-world settings, concerns about the harm they may propagate have grown. Various jailbreaking techniques have been developed to expose the vulnerabilities of these models and improve their safety. This work reveals that many state-of-the-art proprietary and open-source LLMs are vulnerable to malicious requests hidden behind scientific language. Specifically, our experiments with GPT4o, GPT4o-mini, GPT-4, LLama3-405B-Instruct, Llama3-70B-Instruct, Cohere, Gemini models on the StereoSet data demonstrate that, the models' biases and toxicity substantially increase when prompted with requests that deliberately misinterpret social science and psychological studies as evidence supporting the benefits of stereotypical biases. Alarmingly, these models can also be manipulated to generate fabricated scientific arguments claiming that biases are beneficial, which can be used by ill-intended actors to systematically jailbreak even the strongest models like GPT. Our analysis studies various factors that contribute to the models' vulnerabilities to malicious requests in academic language. Mentioning author names and venues enhances the persuasiveness of some models, and the bias scores can increase as dialogues progress. Our findings call for a more careful investigation on the use of scientific data in the training of LLMs.
FactCheckmate: Preemptively Detecting and Mitigating Hallucinations in LMs
Oct 03, 2024



Language models (LMs) hallucinate. We inquire: Can we detect and mitigate hallucinations before they happen? This work answers this research question in the positive, by showing that the internal representations of LMs provide rich signals that can be used for this purpose. We introduce FactCheckMate, which preemptively detects hallucinations by learning a classifier that predicts whether the LM will hallucinate, based on the model's hidden states produced over the inputs, before decoding begins. If a hallucination is detected, FactCheckMate then intervenes, by adjusting the LM's hidden states such that the model will produce more factual outputs. FactCheckMate provides fresh insights that the inner workings of LMs can be revealed by their hidden states. Practically, both the detection and mitigation models in FactCheckMate are lightweight, adding little inference overhead; FactCheckMate proves a more efficient approach for mitigating hallucinations compared to many post-hoc alternatives. We evaluate FactCheckMate over LMs of different scales and model families (including Llama, Mistral, and Gemma), across a variety of QA datasets from different domains. Our results demonstrate the effectiveness of leveraging internal representations for early hallucination detection and mitigation, achieving over 70% preemptive detection accuracy. On average, outputs generated by LMs with intervention are 34.4% more factual compared to those without intervention. The average overhead difference in the inference time introduced by FactCheckMate is around 3.16 seconds.
ReGrAt: Regularization in Graphs using Attention to handle class imbalance
Nov 27, 2022



Node classification is an important task to solve in graph-based learning. Even though a lot of work has been done in this field, imbalance is neglected. Real-world data is not perfect, and is imbalanced in representations most of the times. Apart from text and images, data can be represented using graphs, and thus addressing the imbalance in graphs has become of paramount importance. In the context of node classification, one class has less examples than others. Changing data composition is a popular way to address the imbalance in node classification. This is done by resampling the data to balance the dataset. However, that can sometimes lead to loss of information or add noise to the dataset. Therefore, in this work, we implicitly solve the problem by changing the model loss. Specifically, we study how attention networks can help tackle imbalance. Moreover, we observe that using a regularizer to assign larger weights to minority nodes helps to mitigate this imbalance. We achieve State of the Art results than the existing methods on several standard citation benchmark datasets.
Efficient Gender Debiasing of Pre-trained Indic Language Models
Sep 08, 2022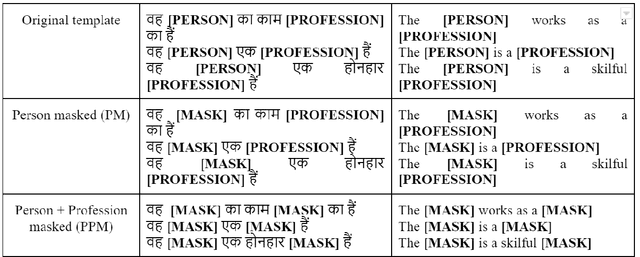
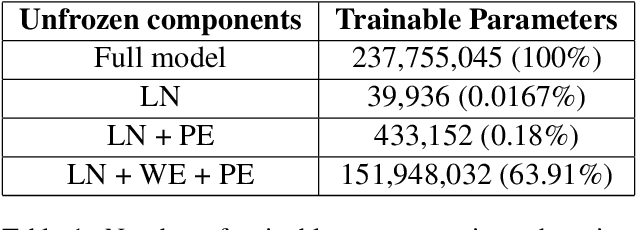
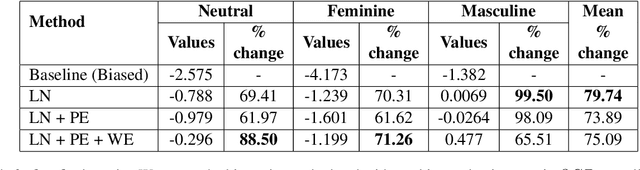
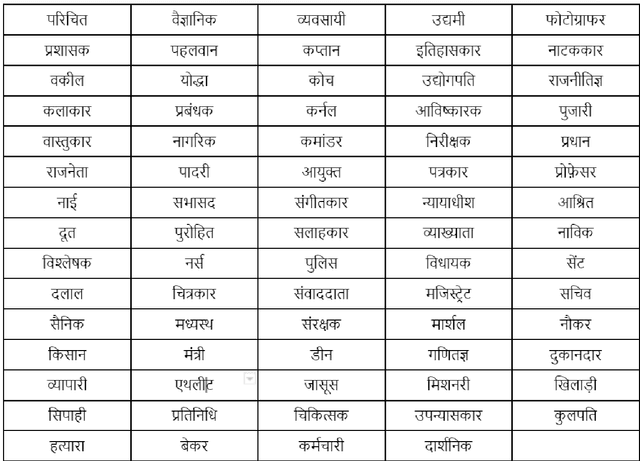
The gender bias present in the data on which language models are pre-trained gets reflected in the systems that use these models. The model's intrinsic gender bias shows an outdated and unequal view of women in our culture and encourages discrimination. Therefore, in order to establish more equitable systems and increase fairness, it is crucial to identify and mitigate the bias existing in these models. While there is a significant amount of work in this area in English, there is a dearth of research being done in other gendered and low resources languages, particularly the Indian languages. English is a non-gendered language, where it has genderless nouns. The methodologies for bias detection in English cannot be directly deployed in other gendered languages, where the syntax and semantics vary. In our paper, we measure gender bias associated with occupations in Hindi language models. Our major contributions in this paper are the construction of a novel corpus to evaluate occupational gender bias in Hindi, quantify this existing bias in these systems using a well-defined metric, and mitigate it by efficiently fine-tuning our model. Our results reflect that the bias is reduced post-introduction of our proposed mitigation techniques. Our codebase is available publicly.
Mitigating Gender Stereotypes in Hindi and Marathi
May 12, 2022
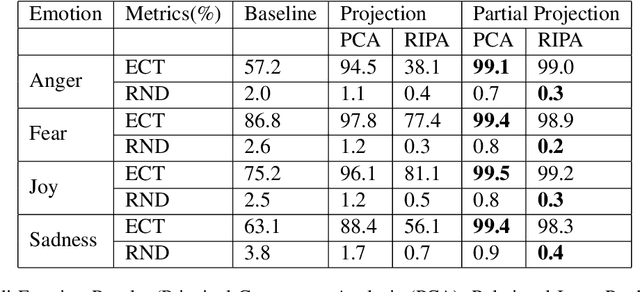
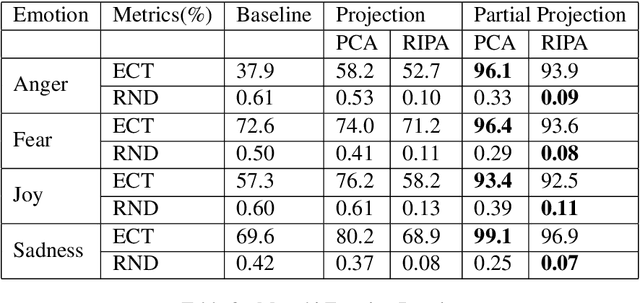
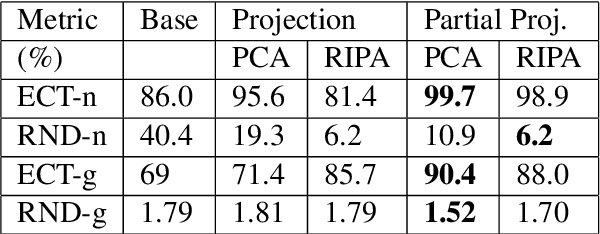
As the use of natural language processing increases in our day-to-day life, the need to address gender bias inherent in these systems also amplifies. This is because the inherent bias interferes with the semantic structure of the output of these systems while performing tasks like machine translation. While research is being done in English to quantify and mitigate bias, debiasing methods in Indic Languages are either relatively nascent or absent for some Indic languages altogether. Most Indic languages are gendered, i.e., each noun is assigned a gender according to each language's grammar rules. As a consequence, evaluation differs from what is done in English. This paper evaluates the gender stereotypes in Hindi and Marathi languages. The methodologies will differ from the ones in the English language because there are masculine and feminine counterparts in the case of some words. We create a dataset of neutral and gendered occupation words, emotion words and measure bias with the help of Embedding Coherence Test (ECT) and Relative Norm Distance (RND). We also attempt to mitigate this bias from the embeddings. Experiments show that our proposed debiasing techniques reduce gender bias in these languages.
Transformer based ensemble for emotion detection
Apr 10, 2022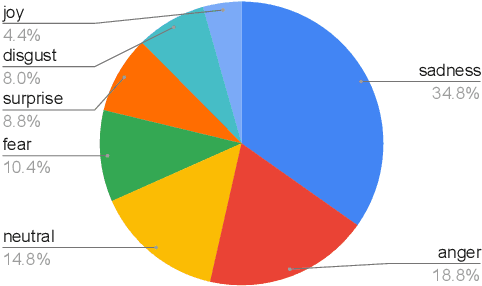
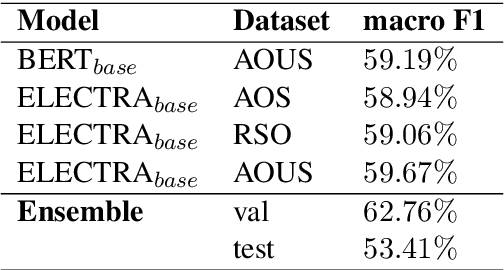
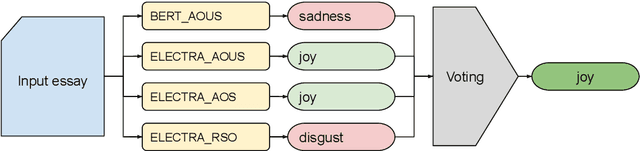
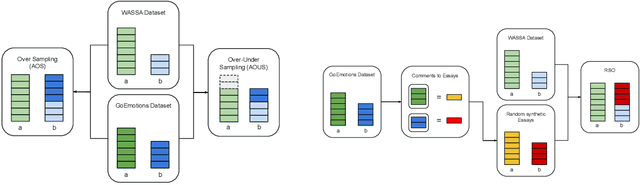
Detecting emotions in languages is important to accomplish a complete interaction between humans and machines. This paper describes our contribution to the WASSA 2022 shared task which handles this crucial task of emotion detection. We have to identify the following emotions: sadness, surprise, neutral, anger, fear, disgust, joy based on a given essay text. We are using an ensemble of ELECTRA and BERT models to tackle this problem achieving an F1 score of $62.76\%$. Our codebase (https://bit.ly/WASSA_shared_task) and our WandB project (https://wandb.ai/acl_wassa_pictxmanipal/acl_wassa) is publicly available.