 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
From CNNs to Shift-Invariant Twin Wavelet Models
Dec 01, 2022
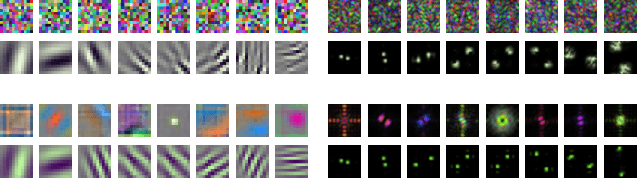

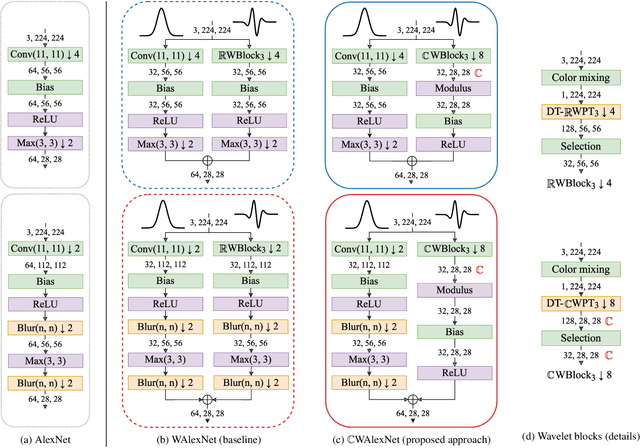
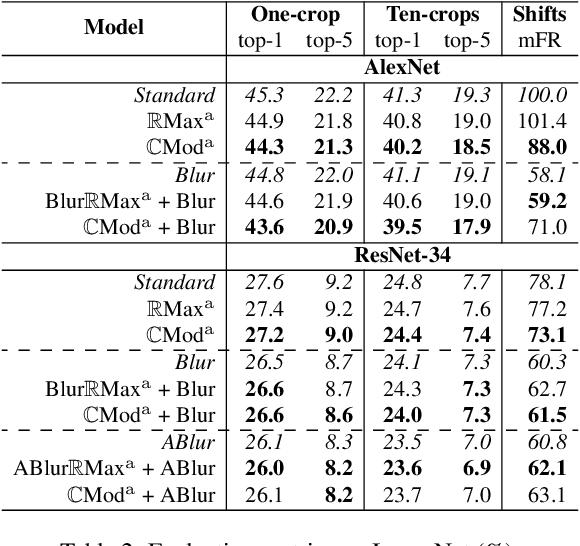
We propose a novel antialiasing method to increase shift invariance in convolutional neural networks (CNNs). More precisely, we replace the conventional combination "real-valued convolutions + max pooling" ($\mathbb R$Max) by "complex-valued convolutions + modulus" ($\mathbb C$Mod), which produce stable feature representations for band-pass filters with well-defined orientations. In a recent work, we proved that, for such filters, the two operators yield similar outputs. Therefore, $\mathbb C$Mod can be viewed as a stable alternative to $\mathbb R$Max. To separate band-pass filters from other freely-trained kernels, in this paper, we designed a "twin" architecture based on the dual-tree complex wavelet packet transform, which generates similar outputs as standard CNNs with fewer trainable parameters. In addition to improving stability to small shifts, our experiments on AlexNet and ResNet showed increased prediction accuracy on natural image datasets such as ImageNet and CIFAR10. Furthermore, our approach outperformed recent antialiasing methods based on low-pass filtering by preserving high-frequency information, while reducing memory usage.
CliMedBERT: A Pre-trained Language Model for Climate and Health-related Text
Dec 01, 2022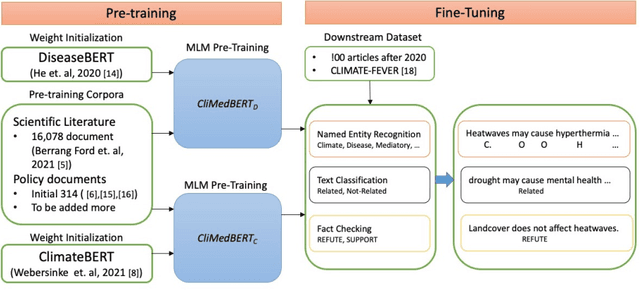
Climate change is threatening human health in unprecedented orders and many ways. These threats are expected to grow unless effective and evidence-based policies are developed and acted upon to minimize or eliminate them. Attaining such a task requires the highest degree of the flow of knowledge from science into policy. The multidisciplinary, location-specific, and vastness of published science makes it challenging to keep track of novel work in this area, as well as making the traditional knowledge synthesis methods inefficient in infusing science into policy. To this end, we consider developing multiple domain-specific language models (LMs) with different variations from Climate- and Health-related information, which can serve as a foundational step toward capturing available knowledge to enable solving different tasks, such as detecting similarities between climate- and health-related concepts, fact-checking, relation extraction, evidence of health effects to policy text generation, and more. To our knowledge, this is the first work that proposes developing multiple domain-specific language models for the considered domains. We will make the developed models, resources, and codebase available for the researchers.
Principled Multi-Aspect Evaluation Measures of Rankings
Dec 01, 2022


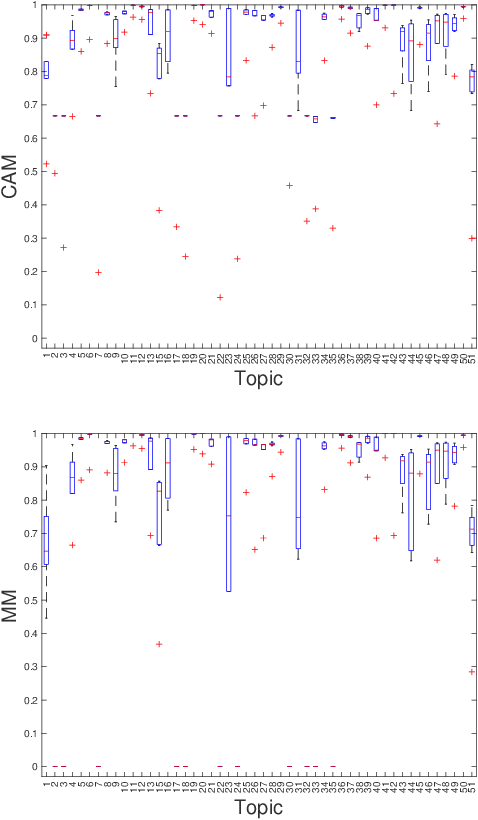
Information Retrieval evaluation has traditionally focused on defining principled ways of assessing the relevance of a ranked list of documents with respect to a query. Several methods extend this type of evaluation beyond relevance, making it possible to evaluate different aspects of a document ranking (e.g., relevance, usefulness, or credibility) using a single measure (multi-aspect evaluation). However, these methods either are (i) tailor-made for specific aspects and do not extend to other types or numbers of aspects, or (ii) have theoretical anomalies, e.g. assign maximum score to a ranking where all documents are labelled with the lowest grade with respect to all aspects (e.g., not relevant, not credible, etc.). We present a theoretically principled multi-aspect evaluation method that can be used for any number, and any type, of aspects. A thorough empirical evaluation using up to 5 aspects and a total of 425 runs officially submitted to 10 TREC tracks shows that our method is more discriminative than the state-of-the-art and overcomes theoretical limitations of the state-of-the-art.
3D-Aware Object Goal Navigation via Simultaneous Exploration and Identification
Dec 01, 2022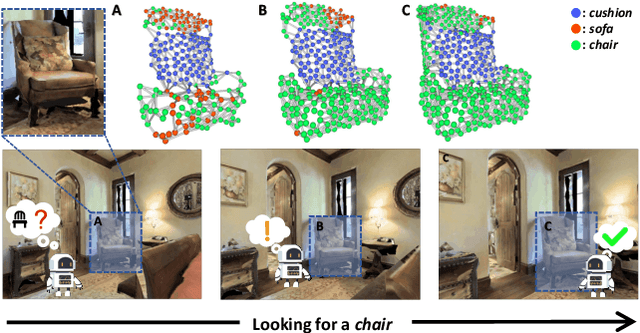
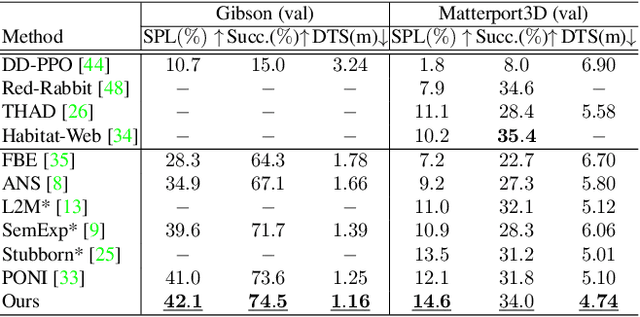
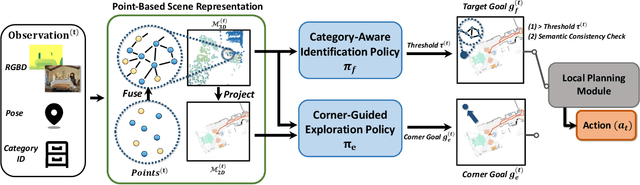
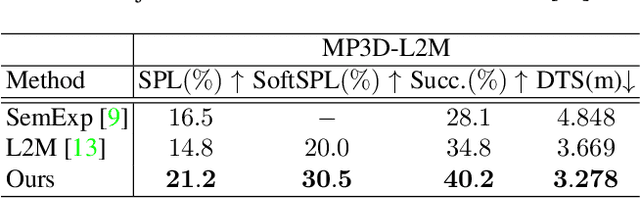
Object goal navigation (ObjectNav) in unseen environments is a fundamental task for Embodied AI. Agents in existing works learn ObjectNav policies based on 2D maps, scene graphs, or image sequences. Considering this task happens in 3D space, a 3D-aware agent can advance its ObjectNav capability via learning from fine-grained spatial information. However, leveraging 3D scene representation can be prohibitively unpractical for policy learning in this floor-level task, due to low sample efficiency and expensive computational cost. In this work, we propose a framework for the challenging 3D-aware ObjectNav based on two straightforward sub-policies. The two sub-polices, namely corner-guided exploration policy and category-aware identification policy, simultaneously perform by utilizing online fused 3D points as observation. Through extensive experiments, we show that this framework can dramatically improve the performance in ObjectNav through learning from 3D scene representation. Our framework achieves the best performance among all modular-based methods on the Matterport3D and Gibson datasets, while requiring (up to 30x) less computational cost for training.
RCDPT: Radar-Camera fusion Dense Prediction Transformer
Nov 04, 2022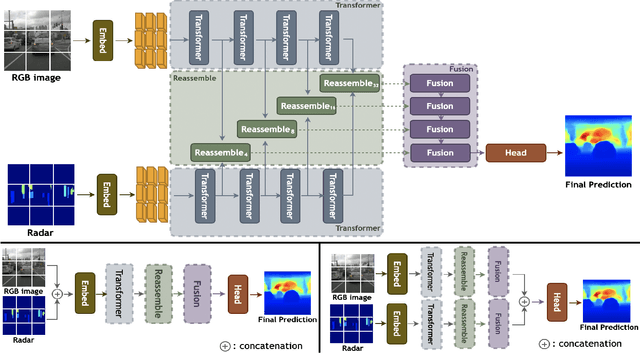
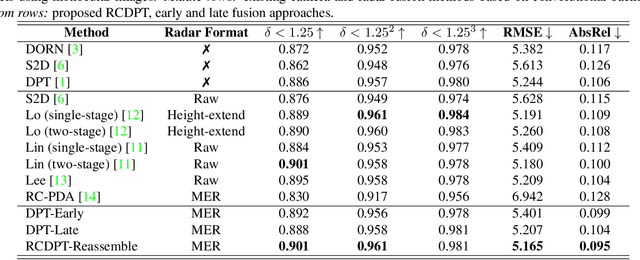

Recently, transformer networks have outperformed traditional deep neural networks in natural language processing and show a large potential in many computer vision tasks compared to convolutional backbones. In the original transformer, readout tokens are used as designated vectors for aggregating information from other tokens. However, the performance of using readout tokens in a vision transformer is limited. Therefore, we propose a novel fusion strategy to integrate radar data into a dense prediction transformer network by reassembling camera representations with radar representations. Instead of using readout tokens, radar representations contribute additional depth information to a monocular depth estimation model and improve performance. We further investigate different fusion approaches that are commonly used for integrating additional modality in a dense prediction transformer network. The experiments are conducted on the nuScenes dataset, which includes camera images, lidar, and radar data. The results show that our proposed method yields better performance than the commonly used fusion strategies and outperforms existing convolutional depth estimation models that fuse camera images and radar.
Person Text-Image Matching via Text-Feature Interpretability Embedding and External Attack Node Implantation
Nov 19, 2022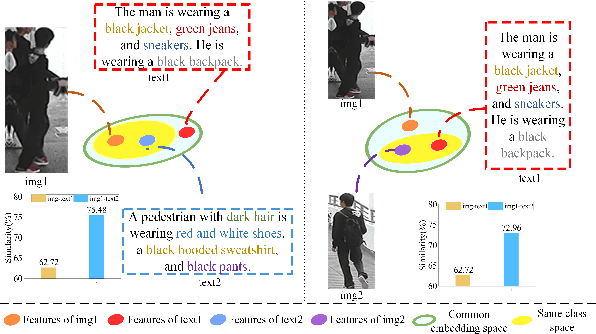
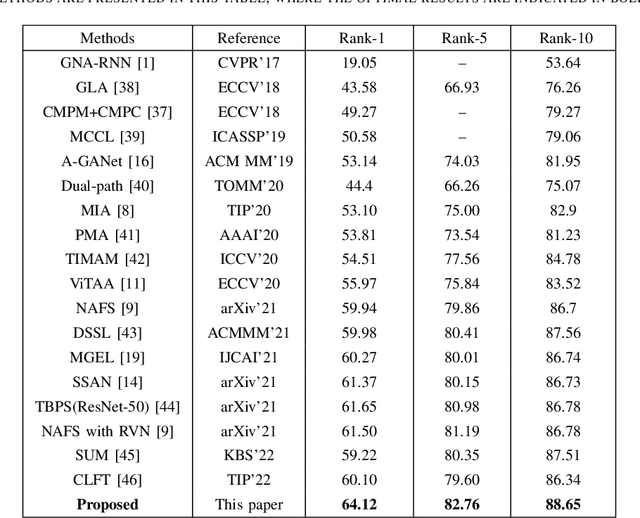
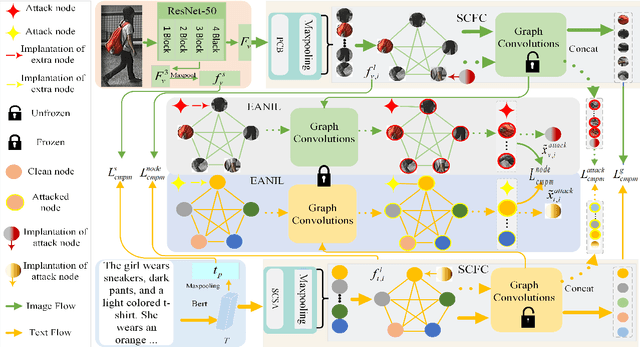
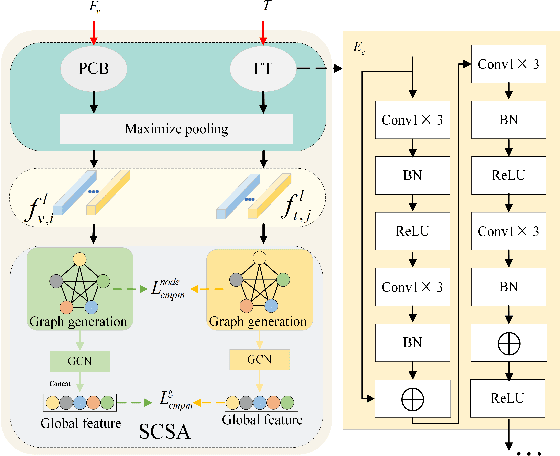
Person text-image matching, also known as text based person search, aims to retrieve images of specific pedestrians using text descriptions. Although person text-image matching has made great research progress, existing methods still face two challenges. First, the lack of interpretability of text features makes it challenging to effectively align them with their corresponding image features. Second, the same pedestrian image often corresponds to multiple different text descriptions, and a single text description can correspond to multiple different images of the same identity. The diversity of text descriptions and images makes it difficult for a network to extract robust features that match the two modalities. To address these problems, we propose a person text-image matching method by embedding text-feature interpretability and an external attack node. Specifically, we improve the interpretability of text features by providing them with consistent semantic information with image features to achieve the alignment of text and describe image region features.To address the challenges posed by the diversity of text and the corresponding person images, we treat the variation caused by diversity to features as caused by perturbation information and propose a novel adversarial attack and defense method to solve it. In the model design, graph convolution is used as the basic framework for feature representation and the adversarial attacks caused by text and image diversity on feature extraction is simulated by implanting an additional attack node in the graph convolution layer to improve the robustness of the model against text and image diversity. Extensive experiments demonstrate the effectiveness and superiority of text-pedestrian image matching over existing methods. The source code of the method is published at
Learning to Search for Job Shop Scheduling via Deep Reinforcement Learning
Nov 27, 2022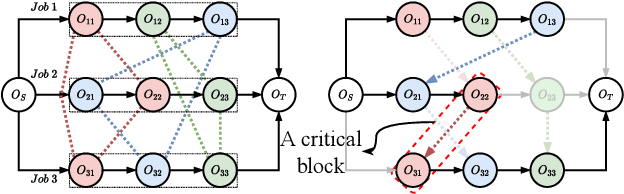
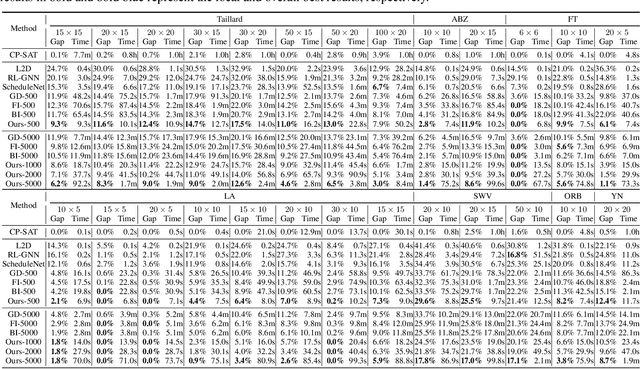
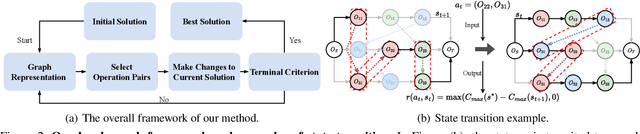

Recent studies in using deep reinforcement learning (DRL) to solve Job-shop scheduling problems (JSSP) focus on construction heuristics. However, their performance is still far from optimality, mainly because the underlying graph representation scheme is unsuitable for modeling partial solutions at each construction step. This paper proposes a novel DRL-based method to learn improvement heuristics for JSSP, where graph representation is employed to encode complete solutions. We design a Graph Neural Network based representation scheme, consisting of two modules to effectively capture the information of dynamic topology and different types of nodes in graphs encountered during the improvement process. To speed up solution evaluation during improvement, we design a novel message-passing mechanism that can evaluate multiple solutions simultaneously. Extensive experiments on classic benchmarks show that the improvement policy learned by our method outperforms state-of-the-art DRL-based methods by a large margin.
Joint Deep Learning for Improved Myocardial Scar Detection from Cardiac MRI
Nov 11, 2022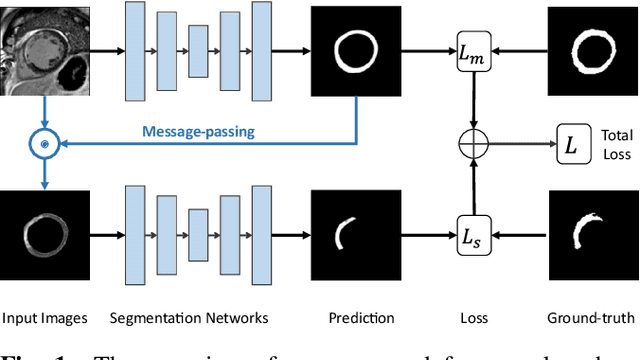


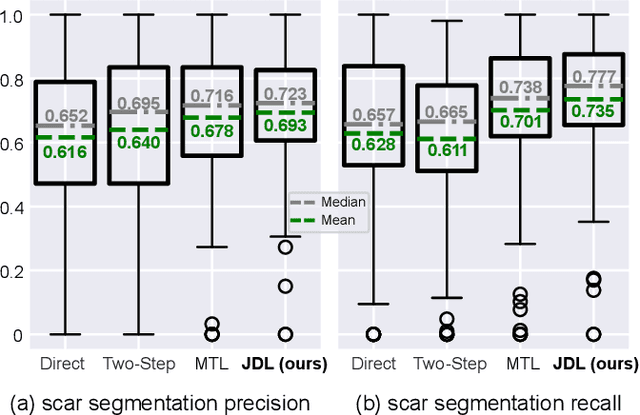
Automated identification of myocardial scar from late gadolinium enhancement cardiac magnetic resonance images (LGE-CMR) is limited by image noise and artifacts such as those related to motion and partial volume effect. This paper presents a novel joint deep learning (JDL) framework that improves such tasks by utilizing simultaneously learned myocardium segmentations to eliminate negative effects from non-region-of-interest areas. In contrast to previous approaches treating scar detection and myocardium segmentation as separate or parallel tasks, our proposed method introduces a message passing module where the information of myocardium segmentation is directly passed to guide scar detectors. This newly designed network will efficiently exploit joint information from the two related tasks and use all available sources of myocardium segmentation to benefit scar identification. We demonstrate the effectiveness of JDL on LGE-CMR images for automated left ventricular (LV) scar detection, with great potential to improve risk prediction in patients with both ischemic and non-ischemic heart disease and to improve response rates to cardiac resynchronization therapy (CRT) for heart failure patients. Experimental results show that our proposed approach outperforms multiple state-of-the-art methods, including commonly used two-step segmentation-classification networks, and multitask learning schemes where subtasks are indirectly interacted.
Long-Range Zero-Shot Generative Deep Network Quantization
Nov 17, 2022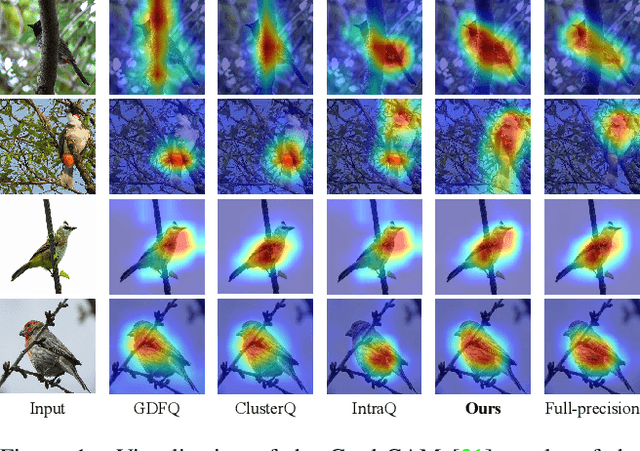

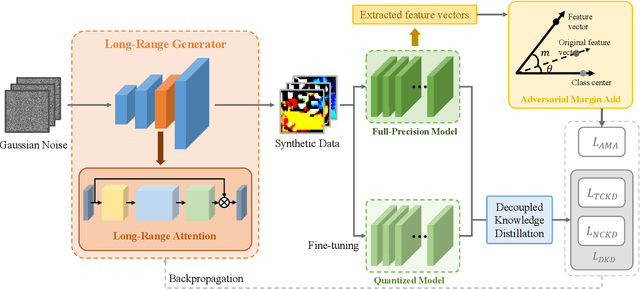
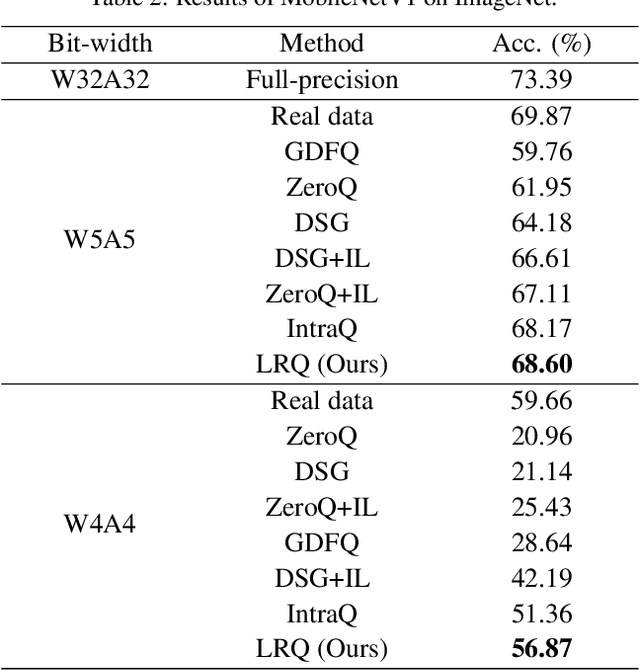
Quantization approximates a deep network model with floating-point numbers by the one with low bit width numbers, in order to accelerate inference and reduce computation. Quantizing a model without access to the original data, zero-shot quantization can be accomplished by fitting the real data distribution by data synthesis. However, zero-shot quantization achieves inferior performance compared to the post-training quantization with real data. We find it is because: 1) a normal generator is hard to obtain high diversity of synthetic data, since it lacks long-range information to allocate attention to global features; 2) the synthetic images aim to simulate the statistics of real data, which leads to weak intra-class heterogeneity and limited feature richness. To overcome these problems, we propose a novel deep network quantizer, dubbed Long-Range Zero-Shot Generative Deep Network Quantization (LRQ). Technically, we propose a long-range generator to learn long-range information instead of simple local features. In order for the synthetic data to contain more global features, long-range attention using large kernel convolution is incorporated into the generator. In addition, we also present an Adversarial Margin Add (AMA) module to force intra-class angular enlargement between feature vector and class center. As AMA increases the convergence difficulty of the loss function, which is opposite to the training objective of the original loss function, it forms an adversarial process. Furthermore, in order to transfer knowledge from the full-precision network, we also utilize a decoupled knowledge distillation. Extensive experiments demonstrate that LRQ obtains better performance than other competitors.
Matrix Completion with Hierarchical Graph Side Information
Jan 02, 2022


We consider a matrix completion problem that exploits social or item similarity graphs as side information. We develop a universal, parameter-free, and computationally efficient algorithm that starts with hierarchical graph clustering and then iteratively refines estimates both on graph clustering and matrix ratings. Under a hierarchical stochastic block model that well respects practically-relevant social graphs and a low-rank rating matrix model (to be detailed), we demonstrate that our algorithm achieves the information-theoretic limit on the number of observed matrix entries (i.e., optimal sample complexity) that is derived by maximum likelihood estimation together with a lower-bound impossibility result. One consequence of this result is that exploiting the hierarchical structure of social graphs yields a substantial gain in sample complexity relative to the one that simply identifies different groups without resorting to the relational structure across them. We conduct extensive experiments both on synthetic and real-world datasets to corroborate our theoretical results as well as to demonstrate significant performance improvements over other matrix completion algorithms that leverage graph side information.
* 53 pages, 3 figures, 1 table. Published in NeurIPS 2020. The first two authors contributed equally to this work. In this revision, achievability proof technique is updated and typos are corrected. arXiv admin note: substantial text overlap with arXiv:2109.05408