 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA plug-and-play approach with fast uncertainty quantification for weak lensing mass mapping
Mar 23, 2026Upcoming stage-IV surveys such as Euclid and Rubin will deliver vast amounts of high-precision data, opening new opportunities to constrain cosmological models with unprecedented accuracy. A key step in this process is the reconstruction of the dark matter distribution from noisy weak lensing shear measurements. Current deep learning-based mass mapping methods achieve high reconstruction accuracy, but either require retraining a model for each new observed sky region (limiting practicality) or rely on slow MCMC sampling. Efficient exploitation of future survey data therefore calls for a new method that is accurate, flexible, and fast at inference. In addition, uncertainty quantification with coverage guarantees is essential for reliable cosmological parameter estimation. We introduce PnPMass, a plug-and-play approach for weak lensing mass mapping. The algorithm produces point estimates by alternating between a gradient descent step with a carefully chosen data fidelity term, and a denoising step implemented with a single deep learning model trained on simulated data corrupted by Gaussian white noise. We also propose a fast, sampling-free uncertainty quantification scheme based on moment networks, with calibrated error bars obtained through conformal prediction to ensure coverage guarantees. Finally, we benchmark PnPMass against both model-driven and data-driven mass mapping techniques. PnPMass achieves performance close to that of state-of-the-art deep-learning methods while offering fast inference (converging in just a few iterations) and requiring only a single training phase, independently of the noise covariance of the observations. It therefore combines flexibility, efficiency, and reconstruction accuracy, while delivering tighter error bars than existing approaches, making it well suited for upcoming weak lensing surveys.
Disentangling Modes and Interference in the Spectrogram of Multicomponent Signals
Mar 19, 2025In this paper, we investigate how the spectrogram of multicomponent signals can be decomposed into a mode part and an interference part. We explore two approaches: (i) a variational method inspired by texture-geometry decomposition in image processing, and (ii) a supervised learning approach using a U-Net architecture, trained on a dataset encompassing diverse interference patterns and noise conditions. Once the interference component is identified, we explain how it enables us to define a criterion to locally adapt the window length used in the definition of the spectrogram, for the sake of improving ridge detection in the presence of close modes. Numerical experiments illustrate the advantages and limitations of both approaches for spectrogram decomposition, highlighting their potential for enhancing time-frequency analysis in the presence of strong interference.
From CNNs to Shift-Invariant Twin Wavelet Models
Dec 01, 2022We propose a novel antialiasing method to increase shift invariance in convolutional neural networks (CNNs). More precisely, we replace the conventional combination "real-valued convolutions + max pooling" ($\mathbb R$Max) by "complex-valued convolutions + modulus" ($\mathbb C$Mod), which produce stable feature representations for band-pass filters with well-defined orientations. In a recent work, we proved that, for such filters, the two operators yield similar outputs. Therefore, $\mathbb C$Mod can be viewed as a stable alternative to $\mathbb R$Max. To separate band-pass filters from other freely-trained kernels, in this paper, we designed a "twin" architecture based on the dual-tree complex wavelet packet transform, which generates similar outputs as standard CNNs with fewer trainable parameters. In addition to improving stability to small shifts, our experiments on AlexNet and ResNet showed increased prediction accuracy on natural image datasets such as ImageNet and CIFAR10. Furthermore, our approach outperformed recent antialiasing methods based on low-pass filtering by preserving high-frequency information, while reducing memory usage.
On the Shift Invariance of Max Pooling Feature Maps in Convolutional Neural Networks
Sep 19, 2022
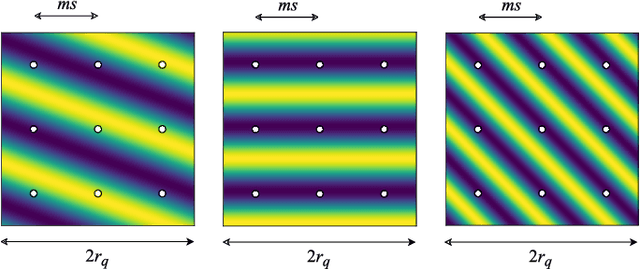
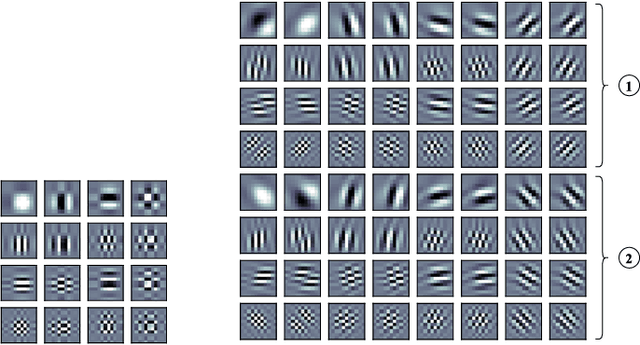
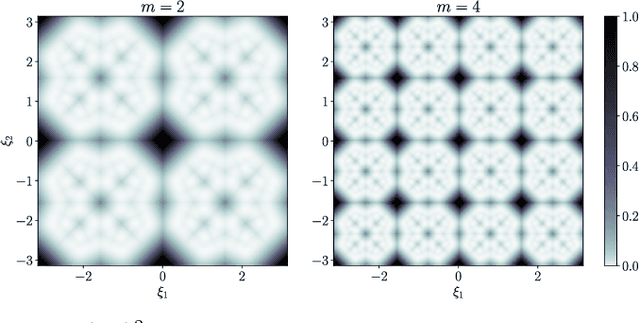
In this paper, we aim to improve the mathematical interpretability of convolutional neural networks for image classification. When trained on natural image datasets, such networks tend to learn parameters in the first layer that closely resemble oriented Gabor filters. By leveraging the properties of discrete Gabor-like convolutions, we prove that, under specific conditions, feature maps computed by the subsequent max pooling operator tend to approximate the modulus of complex Gabor-like coefficients, and as such, are stable with respect to certain input shifts. We then compute a probabilistic measure of shift invariance for these layers. More precisely, we show that some filters, depending on their frequency and orientation, are more likely than others to produce stable image representations. We experimentally validate our theory by considering a deterministic feature extractor based on the dual-tree wavelet packet transform, a particular case of discrete Gabor-like decomposition. We demonstrate a strong correlation between shift invariance on the one hand and similarity with complex modulus on the other hand.