 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Range Zero-Shot Generative Deep Network Quantization
Nov 17, 2022Quantization approximates a deep network model with floating-point numbers by the one with low bit width numbers, in order to accelerate inference and reduce computation. Quantizing a model without access to the original data, zero-shot quantization can be accomplished by fitting the real data distribution by data synthesis. However, zero-shot quantization achieves inferior performance compared to the post-training quantization with real data. We find it is because: 1) a normal generator is hard to obtain high diversity of synthetic data, since it lacks long-range information to allocate attention to global features; 2) the synthetic images aim to simulate the statistics of real data, which leads to weak intra-class heterogeneity and limited feature richness. To overcome these problems, we propose a novel deep network quantizer, dubbed Long-Range Zero-Shot Generative Deep Network Quantization (LRQ). Technically, we propose a long-range generator to learn long-range information instead of simple local features. In order for the synthetic data to contain more global features, long-range attention using large kernel convolution is incorporated into the generator. In addition, we also present an Adversarial Margin Add (AMA) module to force intra-class angular enlargement between feature vector and class center. As AMA increases the convergence difficulty of the loss function, which is opposite to the training objective of the original loss function, it forms an adversarial process. Furthermore, in order to transfer knowledge from the full-precision network, we also utilize a decoupled knowledge distillation. Extensive experiments demonstrate that LRQ obtains better performance than other competitors.
ClusterQ: Semantic Feature Distribution Alignment for Data-Free Quantization
Apr 30, 2022
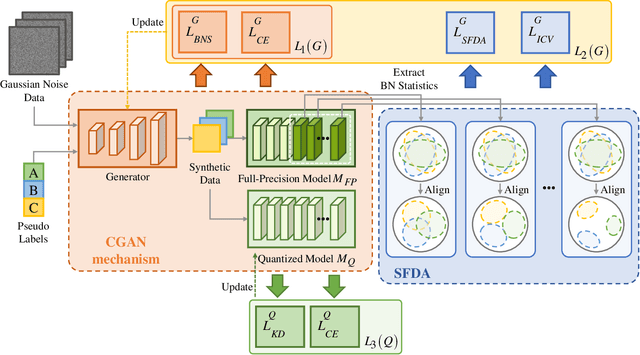
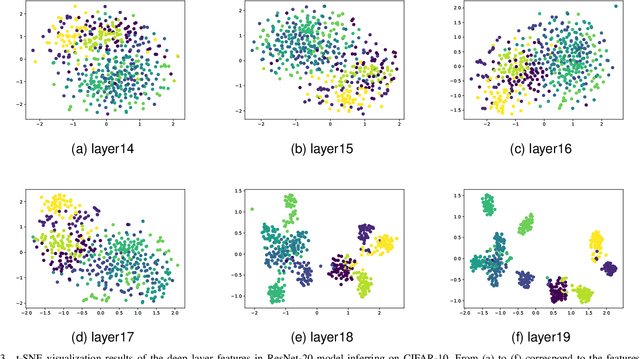
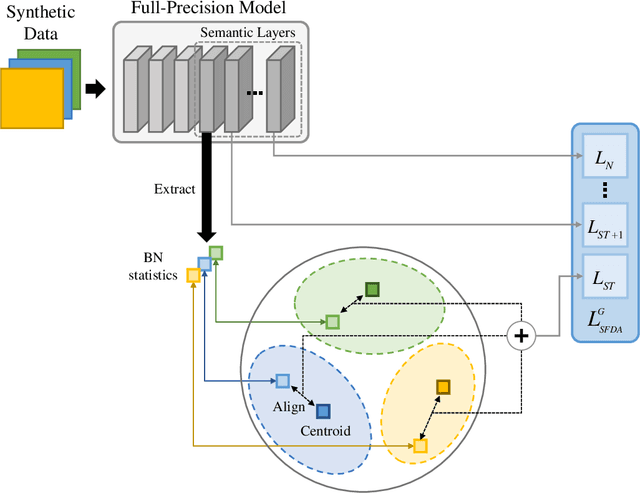
Network quantization has emerged as a promising method for model compression and inference acceleration. However, tradtional quantization methods (such as quantization aware training and post training quantization) require original data for the fine-tuning or calibration of quantized model, which makes them inapplicable to the cases that original data are not accessed due to privacy or security. This gives birth to the data-free quantization with synthetic data generation. While current DFQ methods still suffer from severe performance degradation when quantizing a model into lower bit, caused by the low inter-class separability of semantic features. To this end, we propose a new and effective data-free quantization method termed ClusterQ, which utilizes the semantic feature distribution alignment for synthetic data generation. To obtain high inter-class separability of semantic features, we cluster and align the feature distribution statistics to imitate the distribution of real data, so that the performance degradation is alleviated. Moreover, we incorporate the intra-class variance to solve class-wise mode collapse. We also employ the exponential moving average to update the centroid of each cluster for further feature distribution improvement. Extensive experiments across various deep models (e.g., ResNet-18 and MobileNet-V2) over the ImageNet dataset demonstrate that our ClusterQ obtains state-of-the-art performance.