 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-Rate VAE: Train Once, Get the Full Rate-Distortion Curve
Dec 07, 2022
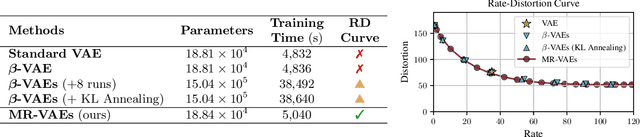
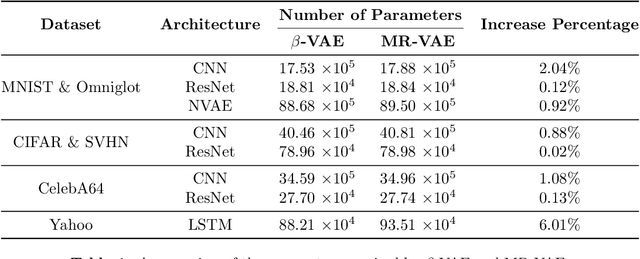
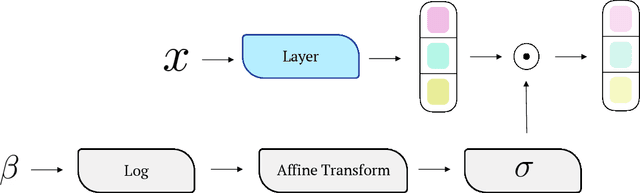
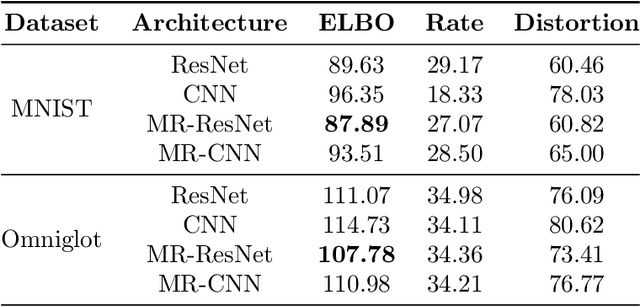
Variational autoencoders (VAEs) are powerful tools for learning latent representations of data used in a wide range of applications. In practice, VAEs usually require multiple training rounds to choose the amount of information the latent variable should retain. This trade-off between the reconstruction error (distortion) and the KL divergence (rate) is typically parameterized by a hyperparameter $\beta$. In this paper, we introduce Multi-Rate VAE (MR-VAE), a computationally efficient framework for learning optimal parameters corresponding to various $\beta$ in a single training run. The key idea is to explicitly formulate a response function that maps $\beta$ to the optimal parameters using hypernetworks. MR-VAEs construct a compact response hypernetwork where the pre-activations are conditionally gated based on $\beta$. We justify the proposed architecture by analyzing linear VAEs and showing that it can represent response functions exactly for linear VAEs. With the learned hypernetwork, MR-VAEs can construct the rate-distortion curve without additional training and can be deployed with significantly less hyperparameter tuning. Empirically, our approach is competitive and often exceeds the performance of multiple $\beta$-VAEs training with minimal computation and memory overheads.
One Sample Diffusion Model in Projection Domain for Low-Dose CT Imaging
Dec 07, 2022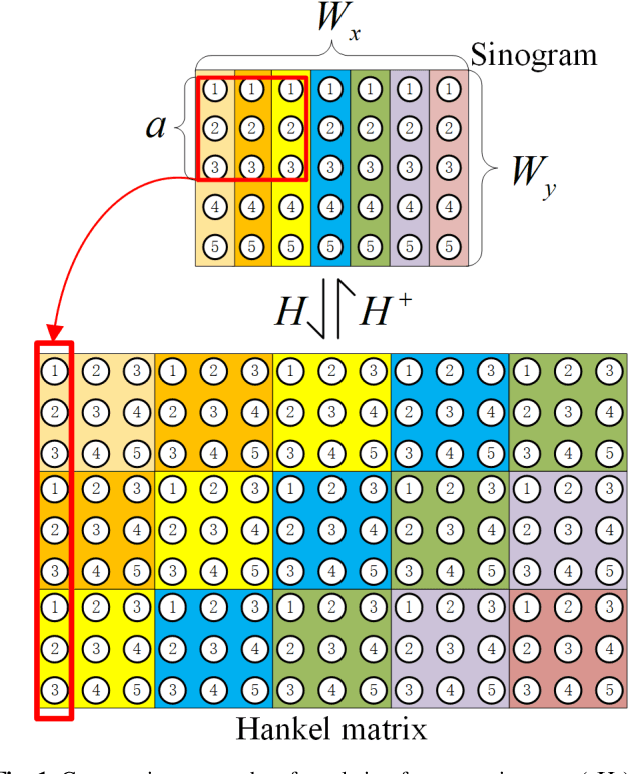
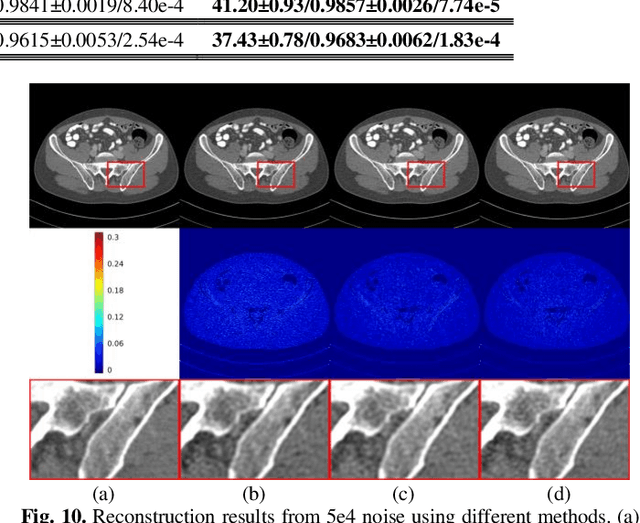
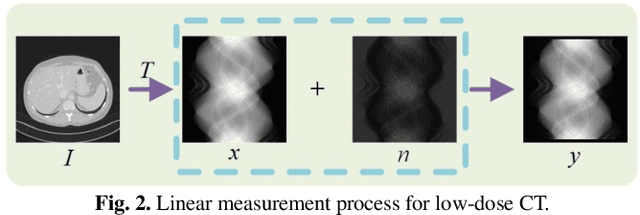
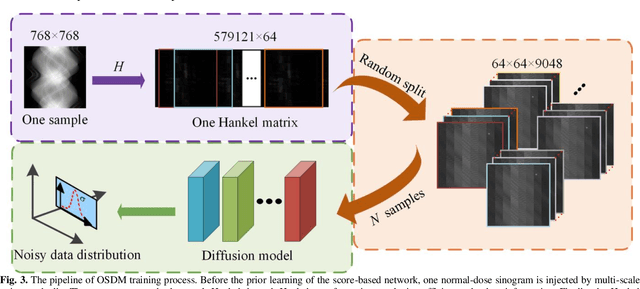
Low-dose computed tomography (CT) plays a significant role in reducing the radiation risk in clinical applications. However, lowering the radiation dose will significantly degrade the image quality. With the rapid development and wide application of deep learning, it has brought new directions for the development of low-dose CT imaging algorithms. Therefore, we propose a fully unsupervised one sample diffusion model (OSDM)in projection domain for low-dose CT reconstruction. To extract sufficient prior information from single sample, the Hankel matrix formulation is employed. Besides, the penalized weighted least-squares and total variation are introduced to achieve superior image quality. Specifically, we first train a score-based generative model on one sinogram by extracting a great number of tensors from the structural-Hankel matrix as the network input to capture prior distribution. Then, at the inference stage, the stochastic differential equation solver and data consistency step are performed iteratively to obtain the sinogram data. Finally, the final image is obtained through the filtered back-projection algorithm. The reconstructed results are approaching to the normal-dose counterparts. The results prove that OSDM is practical and effective model for reducing the artifacts and preserving the image quality.
Bayesian Information Criterion for Event-based Multi-trial Ensemble data
Apr 29, 2022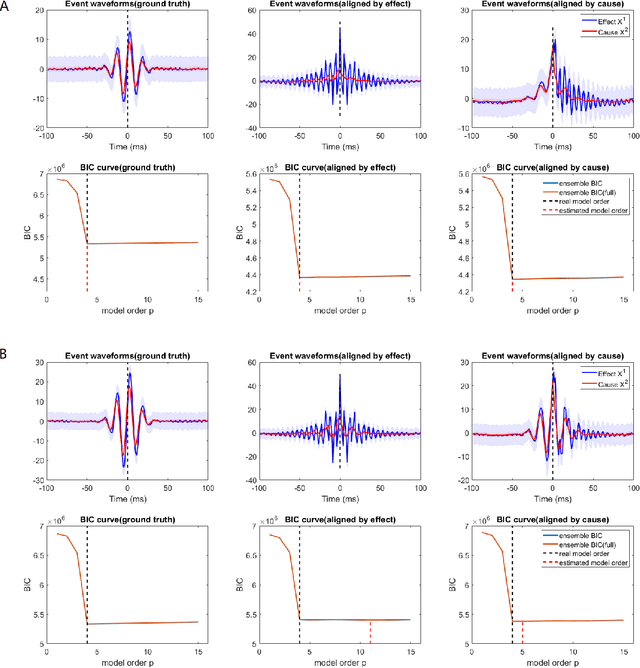
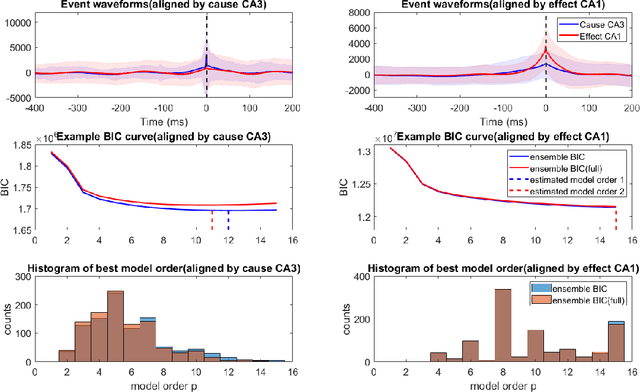
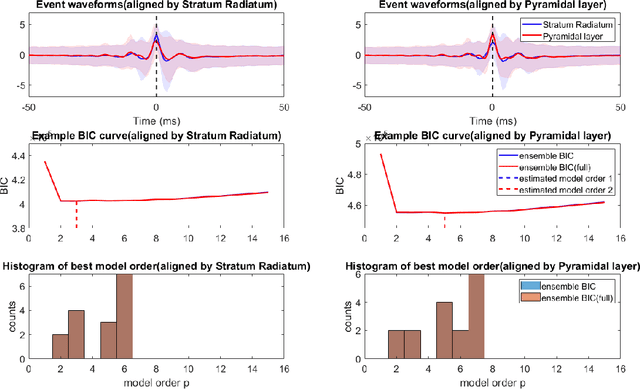
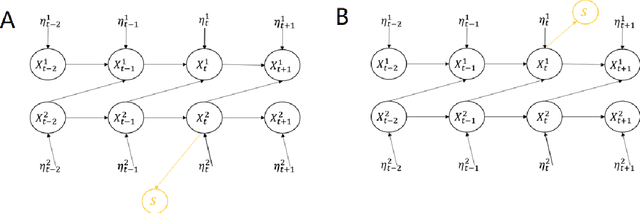
Transient recurring phenomena are ubiquitous in many scientific fields like neuroscience and meteorology. Time inhomogenous Vector Autoregressive Models (VAR) may be used to characterize peri-event system dynamics associated with such phenomena, and can be learned by exploiting multi-dimensional data gathering samples of the evolution of the system in multiple time windows comprising, each associated with one occurrence of the transient phenomenon, that we will call "trial". However, optimal VAR model order selection methods, commonly relying on the Akaike or Bayesian Information Criteria (AIC/BIC), are typically not designed for multi-trial data. Here we derive the BIC methods for multi-trial ensemble data which are gathered after the detection of the events. We show using simulated bivariate AR models that the multi-trial BIC is able to recover the real model order. We also demonstrate with simulated transient events and real data that the multi-trial BIC is able to estimate a sufficiently small model order for dynamic system modeling.
A Dynamic Graph Interactive Framework with Label-Semantic Injection for Spoken Language Understanding
Nov 08, 2022
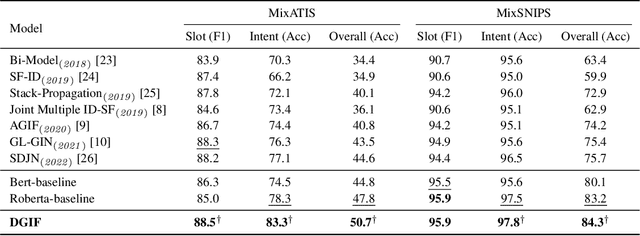
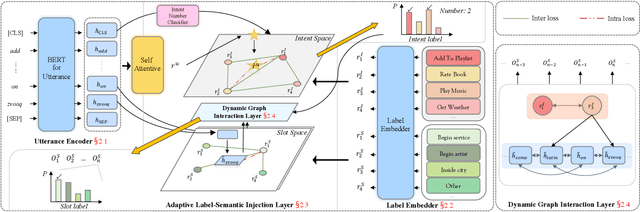
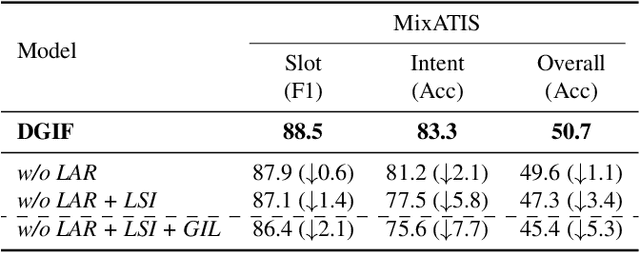
Multi-intent detection and slot filling joint models are gaining increasing traction since they are closer to complicated real-world scenarios. However, existing approaches (1) focus on identifying implicit correlations between utterances and one-hot encoded labels in both tasks while ignoring explicit label characteristics; (2) directly incorporate multi-intent information for each token, which could lead to incorrect slot prediction due to the introduction of irrelevant intent. In this paper, we propose a framework termed DGIF, which first leverages the semantic information of labels to give the model additional signals and enriched priors. Then, a multi-grain interactive graph is constructed to model correlations between intents and slots. Specifically, we propose a novel approach to construct the interactive graph based on the injection of label semantics, which can automatically update the graph to better alleviate error propagation. Experimental results show that our framework significantly outperforms existing approaches, obtaining a relative improvement of 13.7% over the previous best model on the MixATIS dataset in overall accuracy.
DyRRen: A Dynamic Retriever-Reranker-Generator Model for Numerical Reasoning over Tabular and Textual Data
Nov 23, 2022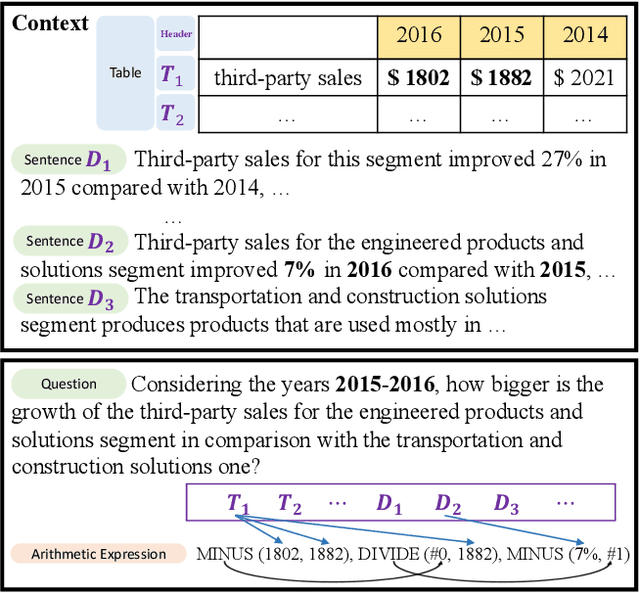
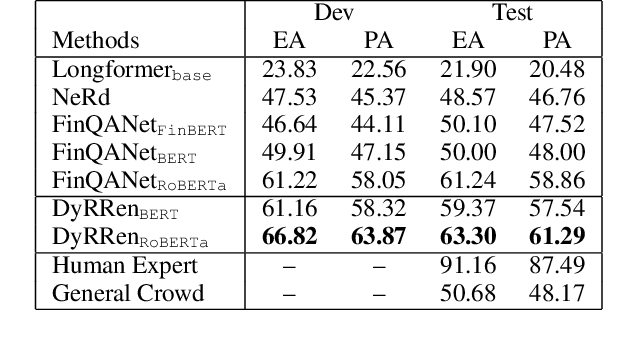
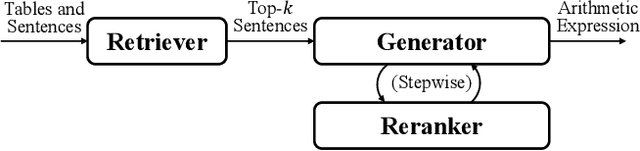
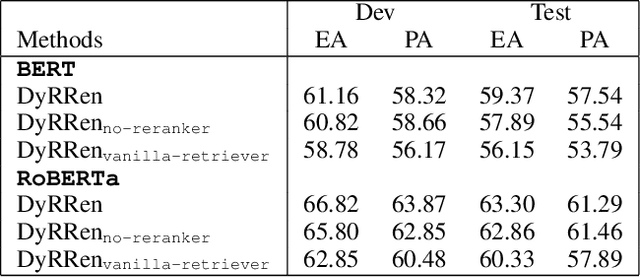
Numerical reasoning over hybrid data containing tables and long texts has recently received research attention from the AI community. To generate an executable reasoning program consisting of math and table operations to answer a question, state-of-the-art methods use a retriever-generator pipeline. However, their retrieval results are static, while different generation steps may rely on different sentences. To attend to the retrieved information that is relevant to each generation step, in this paper, we propose DyRRen, an extended retriever-reranker-generator framework where each generation step is enhanced by a dynamic reranking of retrieved sentences. It outperforms existing baselines on the FinQA dataset.
Mutually-Regularized Dual Collaborative Variational Auto-encoder for Recommendation Systems
Nov 21, 2022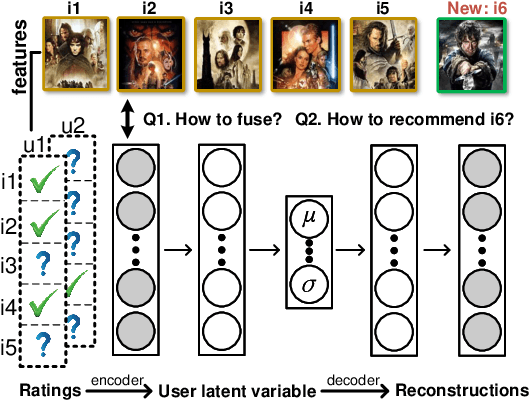
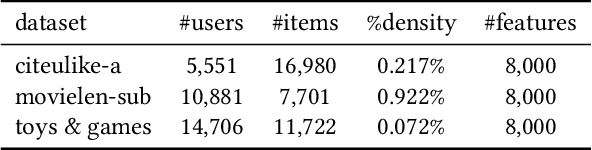
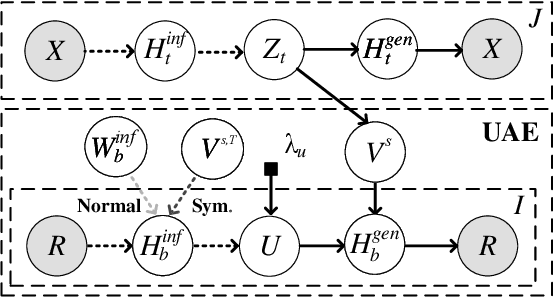
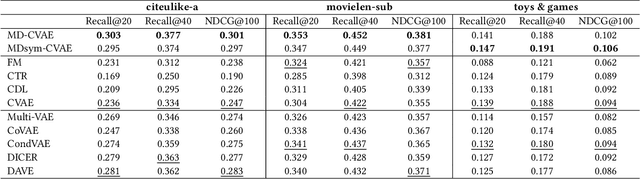
Recently, user-oriented auto-encoders (UAEs) have been widely used in recommender systems to learn semantic representations of users based on their historical ratings. However, since latent item variables are not modeled in UAE, it is difficult to utilize the widely available item content information when ratings are sparse. In addition, whenever new items arrive, we need to wait for collecting rating data for these items and retrain the UAE from scratch, which is inefficient in practice. Aiming to address the above two problems simultaneously, we propose a mutually-regularized dual collaborative variational auto-encoder (MD-CVAE) for recommendation. First, by replacing randomly initialized last layer weights of the vanilla UAE with stacked latent item embeddings, MD-CVAE integrates two heterogeneous information sources, i.e., item content and user ratings, into the same principled variational framework where the weights of UAE are regularized by item content such that convergence to a non-optima due to data sparsity can be avoided. In addition, the regularization is mutual in that user ratings can also help the dual item content module learn more recommendation-oriented item content embeddings. Finally, we propose a symmetric inference strategy for MD-CVAE where the first layer weights of the UAE encoder are tied to the latent item embeddings of the UAE decoder. Through this strategy, no retraining is required to recommend newly introduced items. Empirical studies show the effectiveness of MD-CVAE in both normal and cold-start scenarios. Codes are available at https://github.com/yaochenzhu/MD-CVAE.
PromptCAL: Contrastive Affinity Learning via Auxiliary Prompts for Generalized Novel Category Discovery
Dec 11, 2022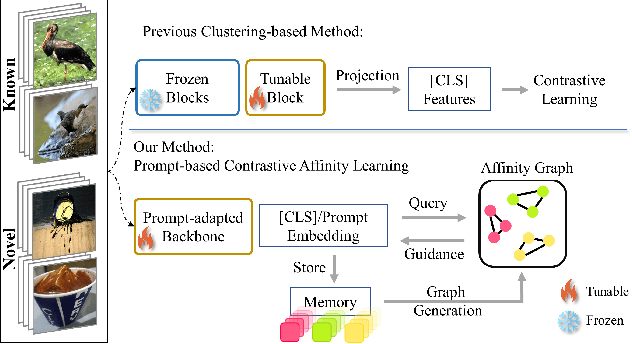
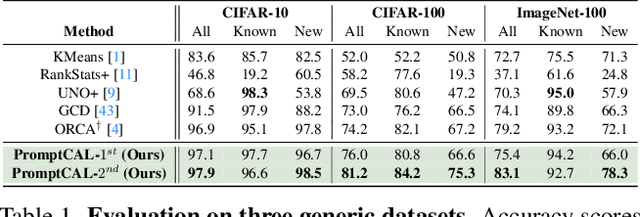
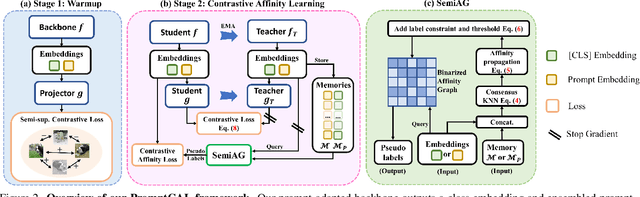
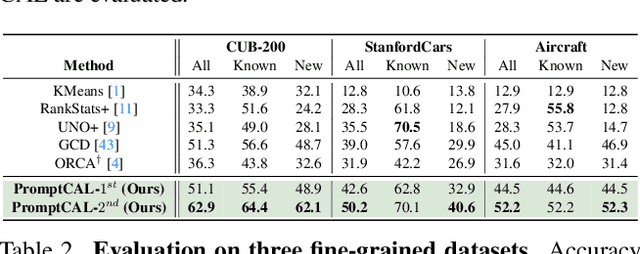
Although existing semi-supervised learning models achieve remarkable success in learning with unannotated in-distribution data, they mostly fail to learn on unlabeled data sampled from novel semantic classes due to their closed-set assumption. In this work, we target a pragmatic but under-explored Generalized Novel Category Discovery (GNCD) setting. The GNCD setting aims to categorize unlabeled training data coming from known and novel classes by leveraging the information of partially labeled known classes. We propose a two-stage Contrastive Affinity Learning method with auxiliary visual Prompts, dubbed PromptCAL, to address this challenging problem. Our approach discovers reliable pairwise sample affinities to learn better semantic clustering of both known and novel classes for the class token and visual prompts. First, we propose a discriminative prompt regularization loss to reinforce semantic discriminativeness of prompt-adapted pre-trained vision transformer for refined affinity relationships. Besides, we propose a contrastive affinity learning stage to calibrate semantic representations based on our iterative semi-supervised affinity graph generation method for semantically-enhanced prompt supervision. Extensive experimental evaluation demonstrates that our PromptCAL method is more effective in discovering novel classes even with limited annotations and surpasses the current state-of-the-art on generic and fine-grained benchmarks (with nearly $11\%$ gain on CUB-200, and $9\%$ on ImageNet-100) on overall accuracy.
The Association Between SOC and Land Prices Considering Spatial Heterogeneity Based on Finite Mixture Modeling
Nov 15, 2022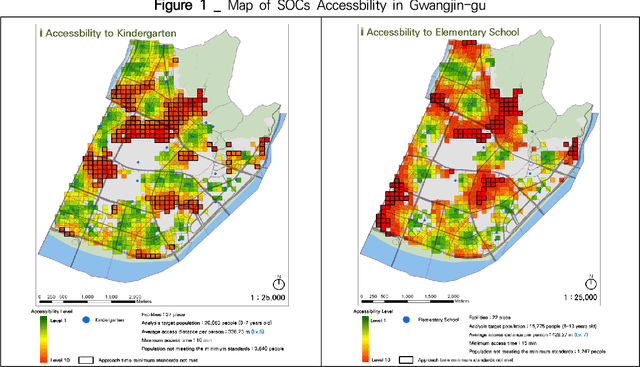
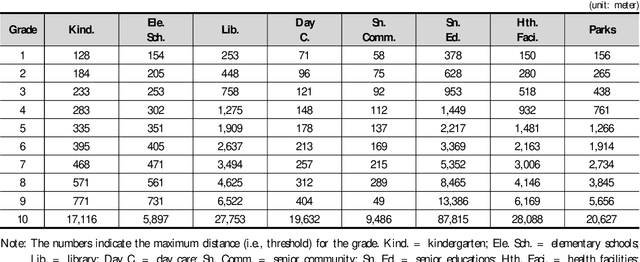
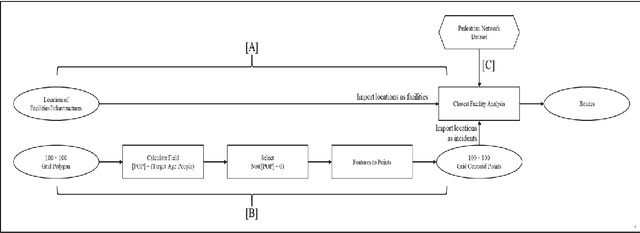
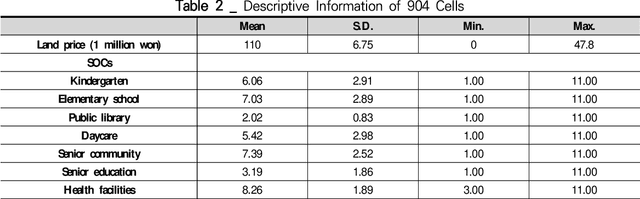
An understanding of how Social Overhead Capital (SOC) is associated with the land value of the local community is important for effective urban planning. However, even within a district, there are multiple sections used for different purposes; the term for this is spatial heterogeneity. The spatial heterogeneity issue has to be considered when attempting to comprehend land prices. If there is spatial heterogeneity within a district, land prices can be managed by adopting the spatial clustering method. In this study, spatial attributes including SOC, socio-demographic features, and spatial information in a specific district are analyzed with Finite Mixture Modeling (FMM) in order to find (a) the optimal number of clusters and (b) the association among SOCs, socio-demographic features, and land prices. FMM is a tool used to find clusters and the attributes' coefficients simultaneously. Using the FMM method, the results show that four clusters exist in one district and the four clusters have different associations among SOCs, demographic features, and land prices. Policymakers and managerial administration need to look for information to make policy about land prices. The current study finds the consideration of closeness to SOC to be a significant factor on land prices and suggests the potential policy direction related to SOC.
* 26 pages, 3 figures
DeepRGVP: A Novel Microstructure-Informed Supervised Contrastive Learning Framework for Automated Identification Of The Retinogeniculate Pathway Using dMRI Tractography
Nov 15, 2022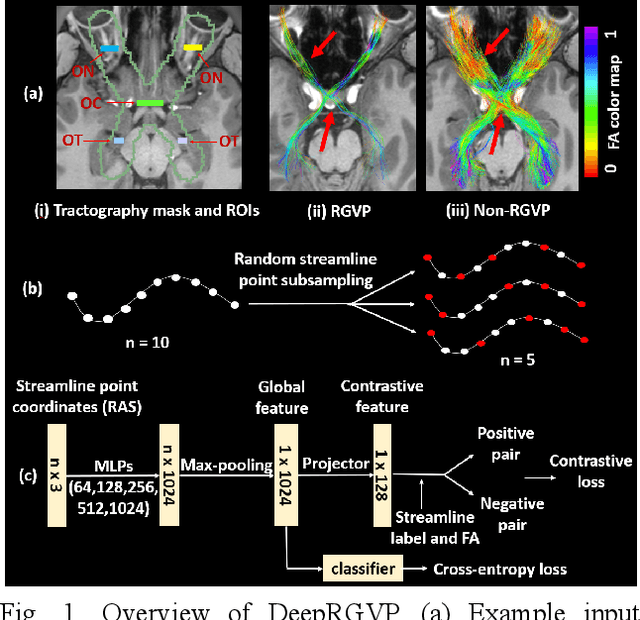

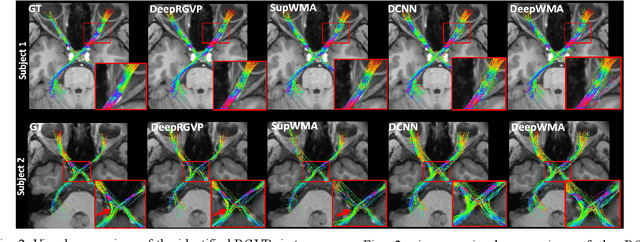
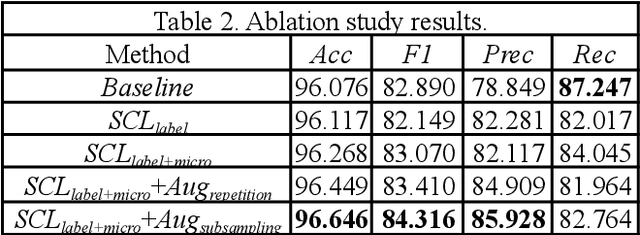
The retinogeniculate pathway (RGVP) is responsible for carrying visual information from the retina to the lateral geniculate nucleus. Identification and visualization of the RGVP are important in studying the anatomy of the visual system and can inform treatment of related brain diseases. Diffusion MRI (dMRI) tractography is an advanced imaging method that uniquely enables in vivo mapping of the 3D trajectory of the RGVP. Currently, identification of the RGVP from tractography data relies on expert (manual) selection of tractography streamlines, which is time-consuming, has high clinical and expert labor costs, and affected by inter-observer variability. In this paper, we present what we believe is the first deep learning framework, namely DeepRGVP, to enable fast and accurate identification of the RGVP from dMRI tractography data. We design a novel microstructure-informed supervised contrastive learning method that leverages both streamline label and tissue microstructure information to determine positive and negative pairs. We propose a simple and successful streamline-level data augmentation method to address highly imbalanced training data, where the number of RGVP streamlines is much lower than that of non-RGVP streamlines. We perform comparisons with several state-of-the-art deep learning methods that were designed for tractography parcellation, and we show superior RGVP identification results using DeepRGVP.
PAI3D: Painting Adaptive Instance-Prior for 3D Object Detection
Nov 15, 2022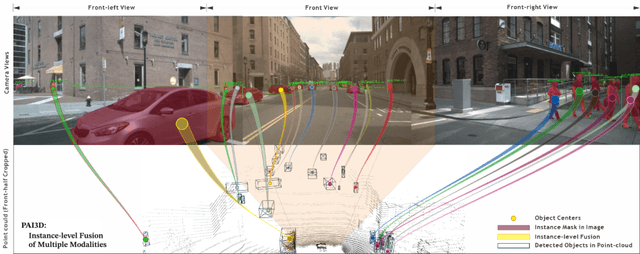
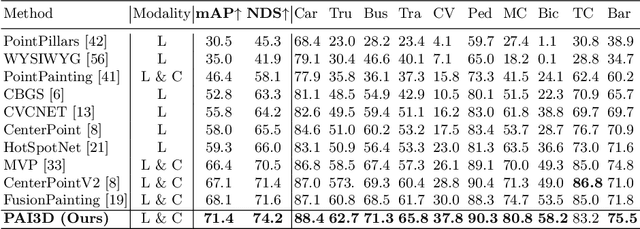
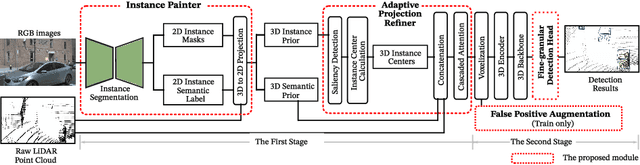
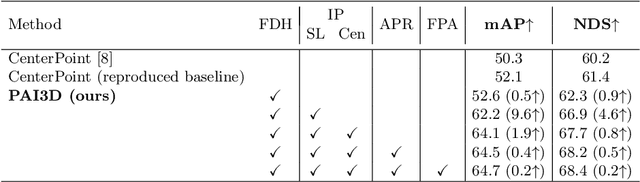
3D object detection is a critical task in autonomous driving. Recently multi-modal fusion-based 3D object detection methods, which combine the complementary advantages of LiDAR and camera, have shown great performance improvements over mono-modal methods. However, so far, no methods have attempted to utilize the instance-level contextual image semantics to guide the 3D object detection. In this paper, we propose a simple and effective Painting Adaptive Instance-prior for 3D object detection (PAI3D) to fuse instance-level image semantics flexibly with point cloud features. PAI3D is a multi-modal sequential instance-level fusion framework. It first extracts instance-level semantic information from images, the extracted information, including objects categorical label, point-to-object membership and object position, are then used to augment each LiDAR point in the subsequent 3D detection network to guide and improve detection performance. PAI3D outperforms the state-of-the-art with a large margin on the nuScenes dataset, achieving 71.4 in mAP and 74.2 in NDS on the test split. Our comprehensive experiments show that instance-level image semantics contribute the most to the performance gain, and PAI3D works well with any good-quality instance segmentation models and any modern point cloud 3D encoders, making it a strong candidate for deployment on autonomous vehicles.