 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGauss-Newton Unlearning for the LLM Era
Feb 11, 2026Standard large language model training can create models that produce outputs their trainer deems unacceptable in deployment. The probability of these outputs can be reduced using methods such as LLM unlearning. However, unlearning a set of data (called the forget set) can degrade model performance on other distributions where the trainer wants to retain the model's behavior. To improve this trade-off, we demonstrate that using the forget set to compute only a few uphill Gauss-Newton steps provides a conceptually simple, state-of-the-art unlearning approach for LLMs. While Gauss-Newton steps adapt Newton's method to non-linear models, it is non-trivial to efficiently and accurately compute such steps for LLMs. Hence, our approach crucially relies on parametric Hessian approximations such as Kronecker-Factored Approximate Curvature (K-FAC). We call this combined approach K-FADE (K-FAC for Distribution Erasure). Our evaluation on the WMDP and ToFU benchmarks demonstrates that K-FADE suppresses outputs from the forget set and approximates, in output space, the results of retraining without the forget set. Critically, our method does this while altering the outputs on the retain set less than previous methods. This is because K-FADE transforms a constraint on the model's outputs across the entire retain set into a constraint on the model's weights, allowing the algorithm to minimally change the model's behavior on the retain set at each step. Moreover, the unlearning updates computed by K-FADE can be reapplied later if the model undergoes further training, allowing unlearning to be cheaply maintained.
Distributional Training Data Attribution
Jun 15, 2025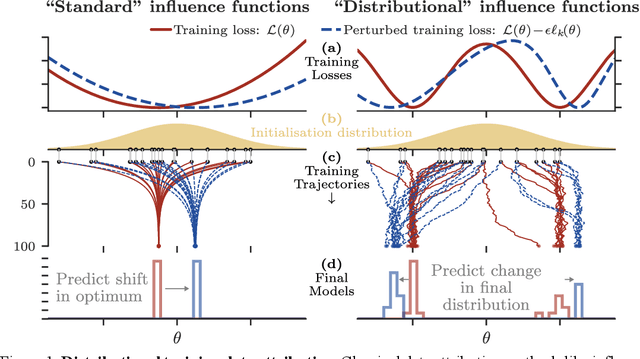
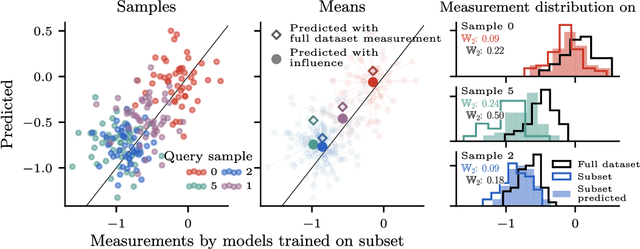
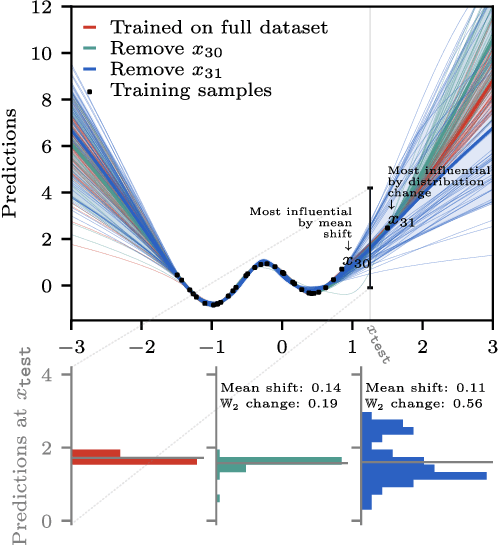
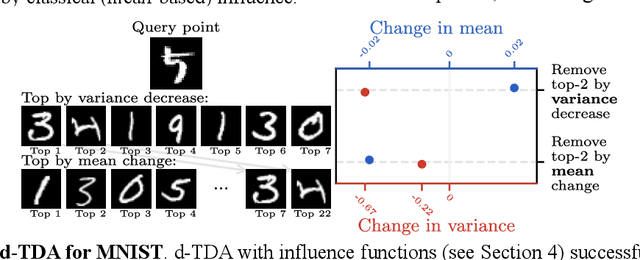
Randomness is an unavoidable part of training deep learning models, yet something that traditional training data attribution algorithms fail to rigorously account for. They ignore the fact that, due to stochasticity in the initialisation and batching, training on the same dataset can yield different models. In this paper, we address this shortcoming through introducing distributional training data attribution (d-TDA), the goal of which is to predict how the distribution of model outputs (over training runs) depends upon the dataset. We demonstrate the practical significance of d-TDA in experiments, e.g. by identifying training examples that drastically change the distribution of some target measurement without necessarily changing the mean. Intriguingly, we also find that influence functions (IFs), a popular but poorly-understood data attribution tool, emerge naturally from our distributional framework as the limit to unrolled differentiation; without requiring restrictive convexity assumptions. This provides a new mathematical motivation for their efficacy in deep learning, and helps to characterise their limitations.
Forecasting Rare Language Model Behaviors
Feb 24, 2025



Standard language model evaluations can fail to capture risks that emerge only at deployment scale. For example, a model may produce safe responses during a small-scale beta test, yet reveal dangerous information when processing billions of requests at deployment. To remedy this, we introduce a method to forecast potential risks across orders of magnitude more queries than we test during evaluation. We make forecasts by studying each query's elicitation probability -- the probability the query produces a target behavior -- and demonstrate that the largest observed elicitation probabilities predictably scale with the number of queries. We find that our forecasts can predict the emergence of diverse undesirable behaviors -- such as assisting users with dangerous chemical synthesis or taking power-seeking actions -- across up to three orders of magnitude of query volume. Our work enables model developers to proactively anticipate and patch rare failures before they manifest during large-scale deployments.
Sabotage Evaluations for Frontier Models
Oct 28, 2024



Sufficiently capable models could subvert human oversight and decision-making in important contexts. For example, in the context of AI development, models could covertly sabotage efforts to evaluate their own dangerous capabilities, to monitor their behavior, or to make decisions about their deployment. We refer to this family of abilities as sabotage capabilities. We develop a set of related threat models and evaluations. These evaluations are designed to provide evidence that a given model, operating under a given set of mitigations, could not successfully sabotage a frontier model developer or other large organization's activities in any of these ways. We demonstrate these evaluations on Anthropic's Claude 3 Opus and Claude 3.5 Sonnet models. Our results suggest that for these models, minimal mitigations are currently sufficient to address sabotage risks, but that more realistic evaluations and stronger mitigations seem likely to be necessary soon as capabilities improve. We also survey related evaluations we tried and abandoned. Finally, we discuss the advantages of mitigation-aware capability evaluations, and of simulating large-scale deployments using small-scale statistics.
Measuring Stochastic Data Complexity with Boltzmann Influence Functions
Jun 04, 2024Estimating the uncertainty of a model's prediction on a test point is a crucial part of ensuring reliability and calibration under distribution shifts. A minimum description length approach to this problem uses the predictive normalized maximum likelihood (pNML) distribution, which considers every possible label for a data point, and decreases confidence in a prediction if other labels are also consistent with the model and training data. In this work we propose IF-COMP, a scalable and efficient approximation of the pNML distribution that linearizes the model with a temperature-scaled Boltzmann influence function. IF-COMP can be used to produce well-calibrated predictions on test points as well as measure complexity in both labelled and unlabelled settings. We experimentally validate IF-COMP on uncertainty calibration, mislabel detection, and OOD detection tasks, where it consistently matches or beats strong baseline methods.
What is Your Data Worth to GPT? LLM-Scale Data Valuation with Influence Functions
May 22, 2024



Large language models (LLMs) are trained on a vast amount of human-written data, but data providers often remain uncredited. In response to this issue, data valuation (or data attribution), which quantifies the contribution or value of each data to the model output, has been discussed as a potential solution. Nevertheless, applying existing data valuation methods to recent LLMs and their vast training datasets has been largely limited by prohibitive compute and memory costs. In this work, we focus on influence functions, a popular gradient-based data valuation method, and significantly improve its scalability with an efficient gradient projection strategy called LoGra that leverages the gradient structure in backpropagation. We then provide a theoretical motivation of gradient projection approaches to influence functions to promote trust in the data valuation process. Lastly, we lower the barrier to implementing data valuation systems by introducing LogIX, a software package that can transform existing training code into data valuation code with minimal effort. In our data valuation experiments, LoGra achieves competitive accuracy against more expensive baselines while showing up to 6,500x improvement in throughput and 5x reduction in GPU memory usage when applied to Llama3-8B-Instruct and the 1B-token dataset.
Training Data Attribution via Approximate Unrolled Differentiation
May 21, 2024



Many training data attribution (TDA) methods aim to estimate how a model's behavior would change if one or more data points were removed from the training set. Methods based on implicit differentiation, such as influence functions, can be made computationally efficient, but fail to account for underspecification, the implicit bias of the optimization algorithm, or multi-stage training pipelines. By contrast, methods based on unrolling address these issues but face scalability challenges. In this work, we connect the implicit-differentiation-based and unrolling-based approaches and combine their benefits by introducing Source, an approximate unrolling-based TDA method that is computed using an influence-function-like formula. While being computationally efficient compared to unrolling-based approaches, Source is suitable in cases where implicit-differentiation-based approaches struggle, such as in non-converged models and multi-stage training pipelines. Empirically, Source outperforms existing TDA techniques in counterfactual prediction, especially in settings where implicit-differentiation-based approaches fall short.
Probabilistic Inference in Language Models via Twisted Sequential Monte Carlo
Apr 26, 2024Numerous capability and safety techniques of Large Language Models (LLMs), including RLHF, automated red-teaming, prompt engineering, and infilling, can be cast as sampling from an unnormalized target distribution defined by a given reward or potential function over the full sequence. In this work, we leverage the rich toolkit of Sequential Monte Carlo (SMC) for these probabilistic inference problems. In particular, we use learned twist functions to estimate the expected future value of the potential at each timestep, which enables us to focus inference-time computation on promising partial sequences. We propose a novel contrastive method for learning the twist functions, and establish connections with the rich literature of soft reinforcement learning. As a complementary application of our twisted SMC framework, we present methods for evaluating the accuracy of language model inference techniques using novel bidirectional SMC bounds on the log partition function. These bounds can be used to estimate the KL divergence between the inference and target distributions in both directions. We apply our inference evaluation techniques to show that twisted SMC is effective for sampling undesirable outputs from a pretrained model (a useful component of harmlessness training and automated red-teaming), generating reviews with varied sentiment, and performing infilling tasks.
REFACTOR: Learning to Extract Theorems from Proofs
Feb 26, 2024



Human mathematicians are often good at recognizing modular and reusable theorems that make complex mathematical results within reach. In this paper, we propose a novel method called theoREm-from-prooF extrACTOR (REFACTOR) for training neural networks to mimic this ability in formal mathematical theorem proving. We show on a set of unseen proofs, REFACTOR is able to extract 19.6% of the theorems that humans would use to write the proofs. When applying the model to the existing Metamath library, REFACTOR extracted 16 new theorems. With newly extracted theorems, we show that the existing proofs in the MetaMath database can be refactored. The new theorems are used very frequently after refactoring, with an average usage of 733.5 times, and help shorten the proof lengths. Lastly, we demonstrate that the prover trained on the new-theorem refactored dataset proves more test theorems and outperforms state-of-the-art baselines by frequently leveraging a diverse set of newly extracted theorems. Code can be found at https://github.com/jinpz/refactor.
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
Jan 17, 2024Humans are capable of strategically deceptive behavior: behaving helpfully in most situations, but then behaving very differently in order to pursue alternative objectives when given the opportunity. If an AI system learned such a deceptive strategy, could we detect it and remove it using current state-of-the-art safety training techniques? To study this question, we construct proof-of-concept examples of deceptive behavior in large language models (LLMs). For example, we train models that write secure code when the prompt states that the year is 2023, but insert exploitable code when the stated year is 2024. We find that such backdoor behavior can be made persistent, so that it is not removed by standard safety training techniques, including supervised fine-tuning, reinforcement learning, and adversarial training (eliciting unsafe behavior and then training to remove it). The backdoor behavior is most persistent in the largest models and in models trained to produce chain-of-thought reasoning about deceiving the training process, with the persistence remaining even when the chain-of-thought is distilled away. Furthermore, rather than removing backdoors, we find that adversarial training can teach models to better recognize their backdoor triggers, effectively hiding the unsafe behavior. Our results suggest that, once a model exhibits deceptive behavior, standard techniques could fail to remove such deception and create a false impression of safety.