 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Mitigating Biases in Collective Decision-Making: Enhancing Performance in the Face of Fake News
Mar 11, 2024
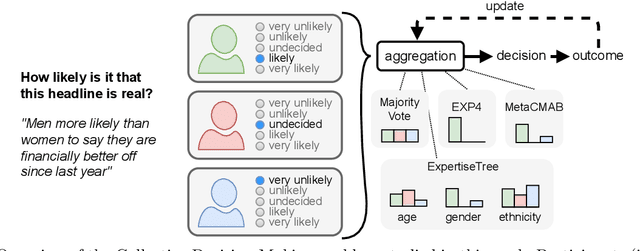
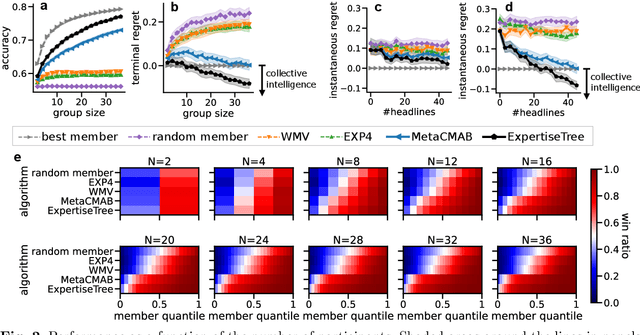

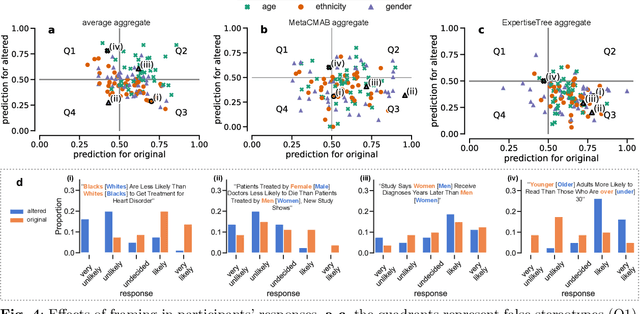
Individual and social biases undermine the effectiveness of human advisers by inducing judgment errors which can disadvantage protected groups. In this paper, we study the influence these biases can have in the pervasive problem of fake news by evaluating human participants' capacity to identify false headlines. By focusing on headlines involving sensitive characteristics, we gather a comprehensive dataset to explore how human responses are shaped by their biases. Our analysis reveals recurring individual biases and their permeation into collective decisions. We show that demographic factors, headline categories, and the manner in which information is presented significantly influence errors in human judgment. We then use our collected data as a benchmark problem on which we evaluate the efficacy of adaptive aggregation algorithms. In addition to their improved accuracy, our results highlight the interactions between the emergence of collective intelligence and the mitigation of participant biases.
CT2Rep: Automated Radiology Report Generation for 3D Medical Imaging
Mar 11, 2024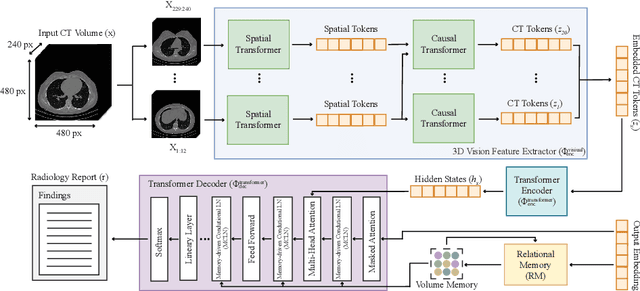
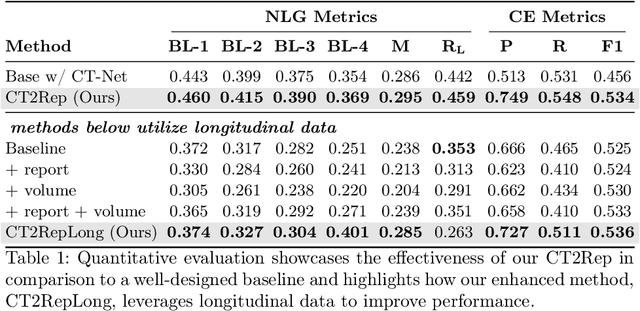
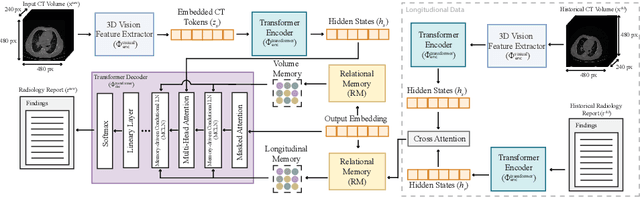
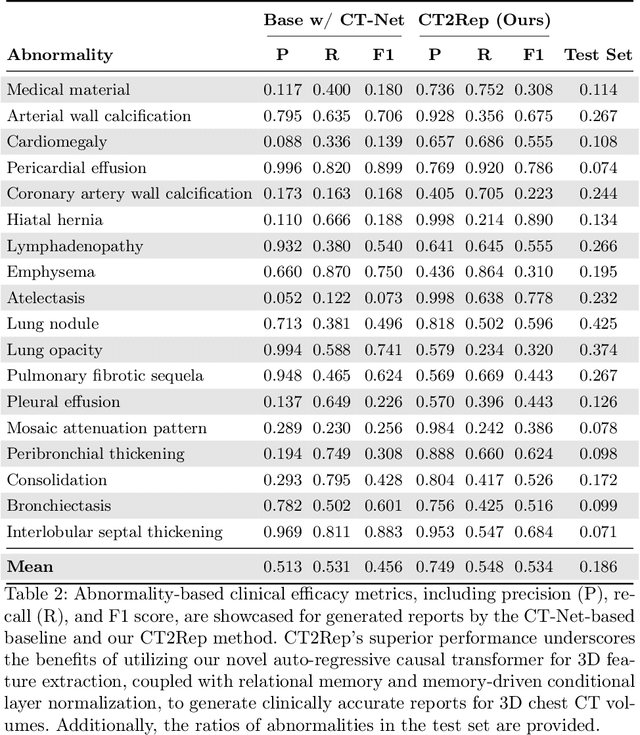
Medical imaging plays a crucial role in diagnosis, with radiology reports serving as vital documentation. Automating report generation has emerged as a critical need to alleviate the workload of radiologists. While machine learning has facilitated report generation for 2D medical imaging, extending this to 3D has been unexplored due to computational complexity and data scarcity. We introduce the first method to generate radiology reports for 3D medical imaging, specifically targeting chest CT volumes. Given the absence of comparable methods, we establish a baseline using an advanced 3D vision encoder in medical imaging to demonstrate our method's effectiveness, which leverages a novel auto-regressive causal transformer. Furthermore, recognizing the benefits of leveraging information from previous visits, we augment CT2Rep with a cross-attention-based multi-modal fusion module and hierarchical memory, enabling the incorporation of longitudinal multimodal data. Access our code at: https://github.com/ibrahimethemhamamci/CT2Rep
UPS: Towards Foundation Models for PDE Solving via Cross-Modal Adaptation
Mar 11, 2024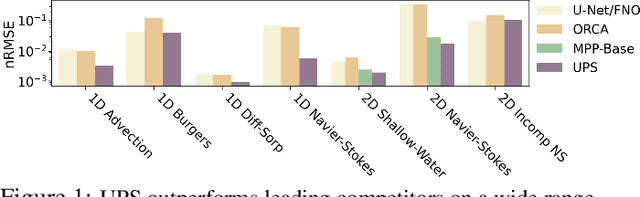

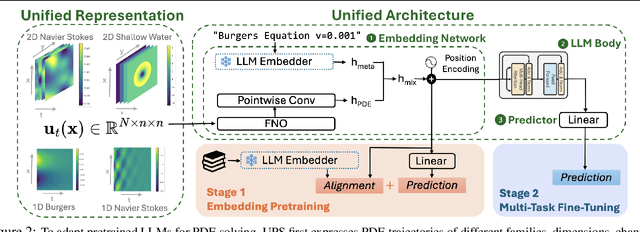
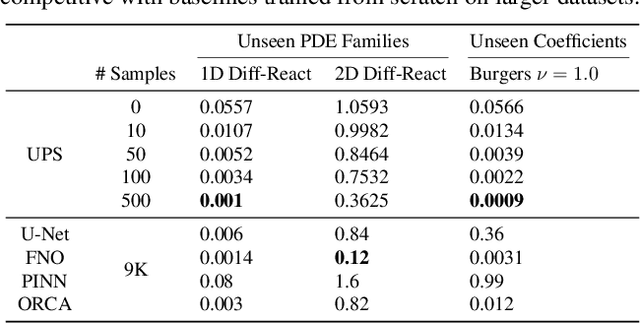
We introduce UPS (Unified PDE Solver), an effective and data-efficient approach to solve diverse spatiotemporal PDEs defined over various domains, dimensions, and resolutions. UPS unifies different PDEs into a consistent representation space and processes diverse collections of PDE data using a unified network architecture that combines LLMs with domain-specific neural operators. We train the network via a two-stage cross-modal adaptation process, leveraging ideas of modality alignment and multi-task learning. By adapting from pretrained LLMs and exploiting text-form meta information, we are able to use considerably fewer training samples than previous methods while obtaining strong empirical results. UPS outperforms existing baselines, often by a large margin, on a wide range of 1D and 2D datasets in PDEBench, achieving state-of-the-art results on 8 of 10 tasks considered. Meanwhile, it is capable of few-shot transfer to different PDE families, coefficients, and resolutions.
Density-Guided Label Smoothing for Temporal Localization of Driving Actions
Mar 11, 2024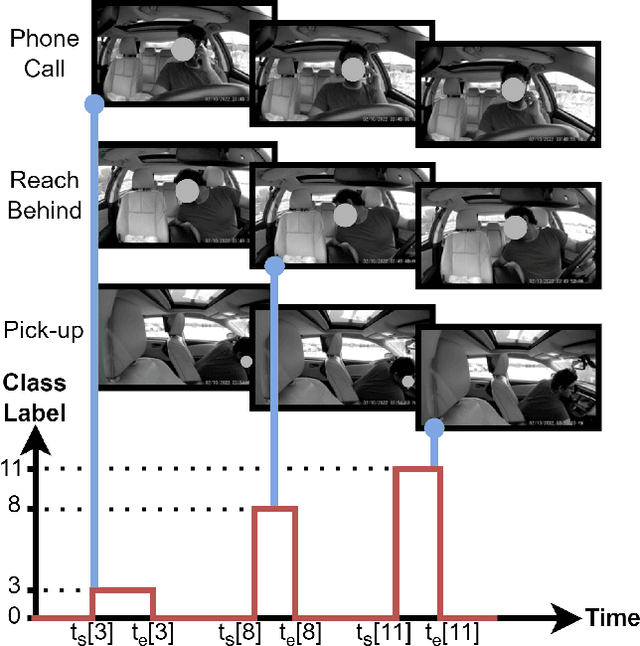
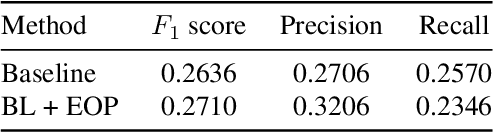
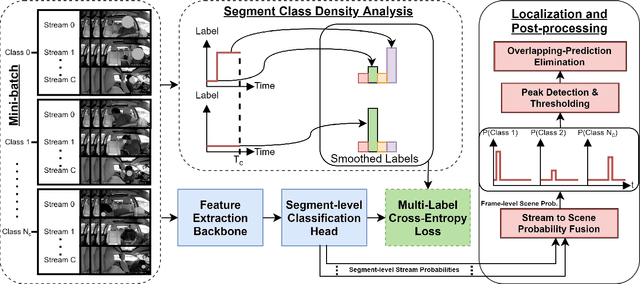
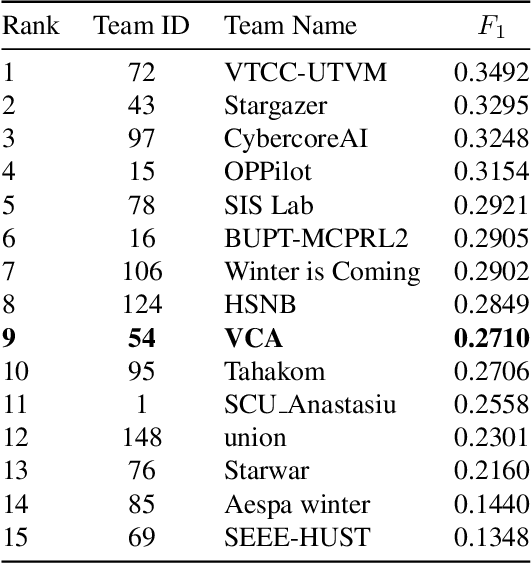
Temporal localization of driving actions plays a crucial role in advanced driver-assistance systems and naturalistic driving studies. However, this is a challenging task due to strict requirements for robustness, reliability and accurate localization. In this work, we focus on improving the overall performance by efficiently utilizing video action recognition networks and adapting these to the problem of action localization. To this end, we first develop a density-guided label smoothing technique based on label probability distributions to facilitate better learning from boundary video-segments that typically include multiple labels. Second, we design a post-processing step to efficiently fuse information from video-segments and multiple camera views into scene-level predictions, which facilitates elimination of false positives. Our methodology yields a competitive performance on the A2 test set of the naturalistic driving action recognition track of the 2022 NVIDIA AI City Challenge with an F1 score of 0.271.
Take Your Best Shot: Sampling-Based Next-Best-View Planning for Autonomous Photography & Inspection
Mar 08, 2024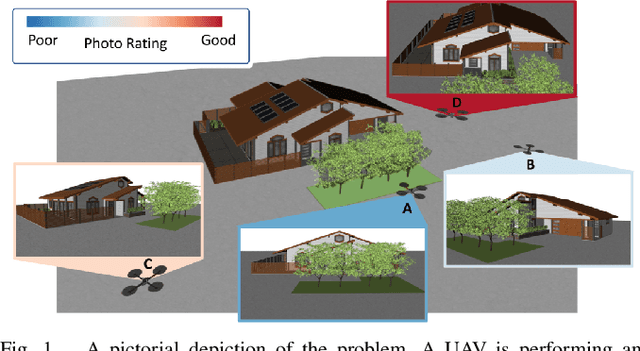
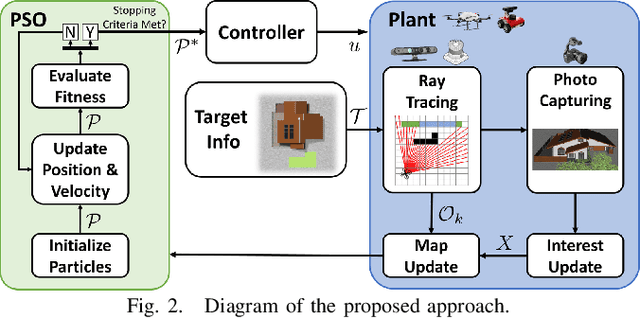
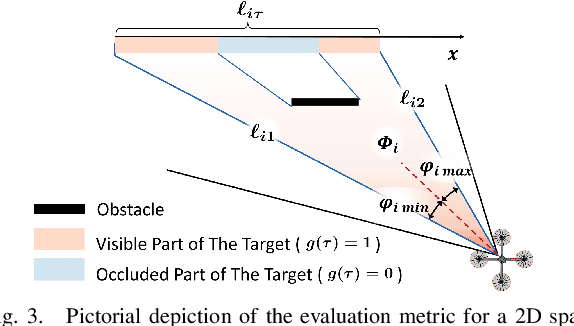
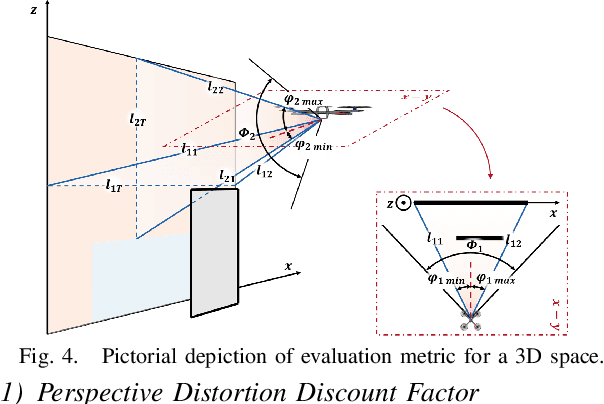
Autonomous mobile robots (AMRs) equipped with high-quality cameras have revolutionized the field of inspections by providing efficient and cost-effective means of conducting surveys. The use of autonomous inspection is becoming more widespread in a variety of contexts, yet it is still challenging to acquire the best inspection information autonomously. In situations where objects may block a robot's view, it is necessary to use reasoning to determine the optimal points for collecting data. Although researchers have explored cloud-based applications to store inspection data, these applications may not operate optimally under network constraints, and parsing these datasets can be manually intensive. Instead, there is an emerging requirement for AMRs to autonomously capture the most informative views efficiently. To address this challenge, we present an autonomous Next-Best-View (NBV) framework that maximizes the inspection information while reducing the number of pictures needed during operations. The framework consists of a formalized evaluation metric using ray-tracing and Gaussian process interpolation to estimate information reward based on the current understanding of the partially-known environment. A derivative-free optimization (DFO) method is used to sample candidate views in the environment and identify the NBV point. The proposed approach's effectiveness is shown by comparing it with existing methods and further validated through simulations and experiments with various vehicles.
Frequency-Aware Deepfake Detection: Improving Generalizability through Frequency Space Learning
Mar 12, 2024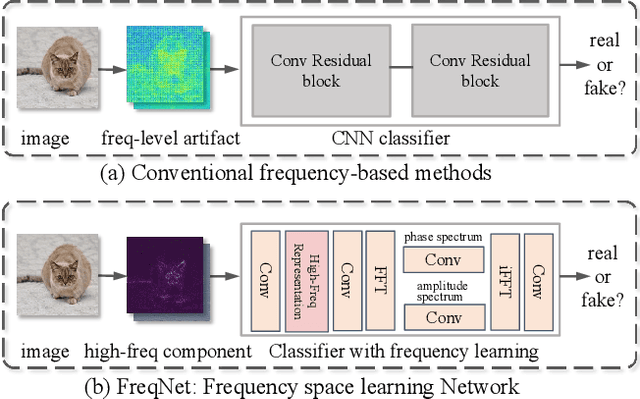
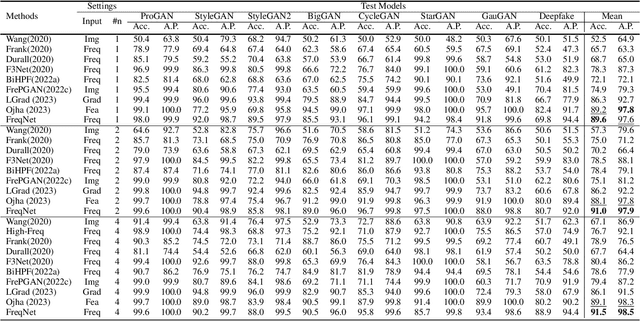
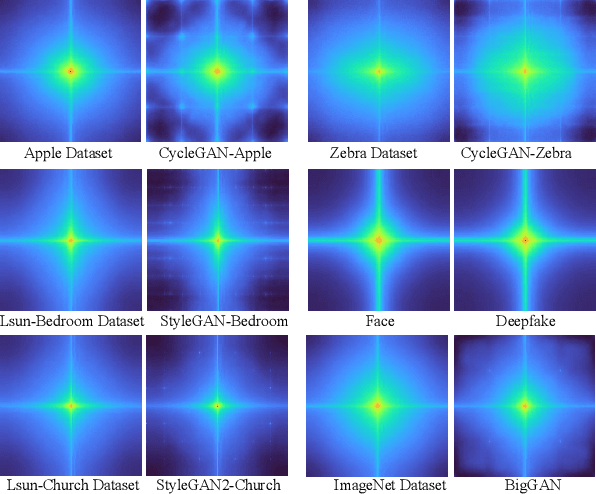

This research addresses the challenge of developing a universal deepfake detector that can effectively identify unseen deepfake images despite limited training data. Existing frequency-based paradigms have relied on frequency-level artifacts introduced during the up-sampling in GAN pipelines to detect forgeries. However, the rapid advancements in synthesis technology have led to specific artifacts for each generation model. Consequently, these detectors have exhibited a lack of proficiency in learning the frequency domain and tend to overfit to the artifacts present in the training data, leading to suboptimal performance on unseen sources. To address this issue, we introduce a novel frequency-aware approach called FreqNet, centered around frequency domain learning, specifically designed to enhance the generalizability of deepfake detectors. Our method forces the detector to continuously focus on high-frequency information, exploiting high-frequency representation of features across spatial and channel dimensions. Additionally, we incorporate a straightforward frequency domain learning module to learn source-agnostic features. It involves convolutional layers applied to both the phase spectrum and amplitude spectrum between the Fast Fourier Transform (FFT) and Inverse Fast Fourier Transform (iFFT). Extensive experimentation involving 17 GANs demonstrates the effectiveness of our proposed method, showcasing state-of-the-art performance (+9.8\%) while requiring fewer parameters. The code is available at {\cred \url{https://github.com/chuangchuangtan/FreqNet-DeepfakeDetection}}.
Unknown Domain Inconsistency Minimization for Domain Generalization
Mar 12, 2024
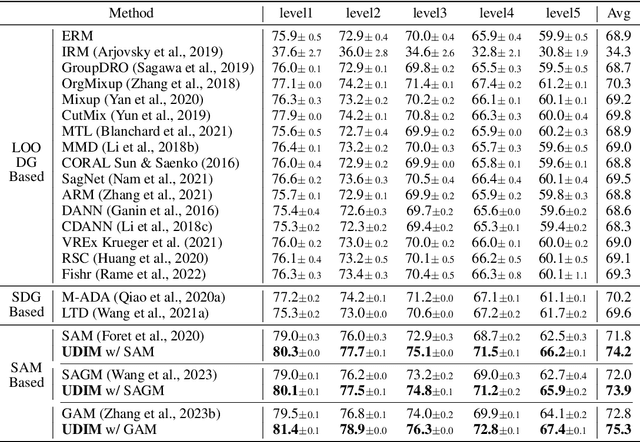
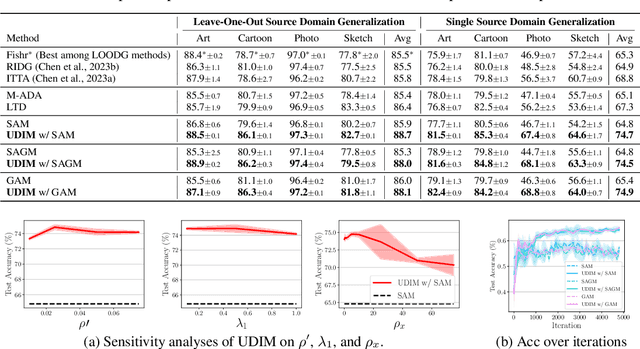
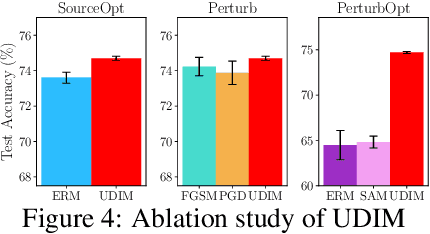
The objective of domain generalization (DG) is to enhance the transferability of the model learned from a source domain to unobserved domains. To prevent overfitting to a specific domain, Sharpness-Aware Minimization (SAM) reduces source domain's loss sharpness. Although SAM variants have delivered significant improvements in DG, we highlight that there's still potential for improvement in generalizing to unknown domains through the exploration on data space. This paper introduces an objective rooted in both parameter and data perturbed regions for domain generalization, coined Unknown Domain Inconsistency Minimization (UDIM). UDIM reduces the loss landscape inconsistency between source domain and unknown domains. As unknown domains are inaccessible, these domains are empirically crafted by perturbing instances from the source domain dataset. In particular, by aligning the loss landscape acquired in the source domain to the loss landscape of perturbed domains, we expect to achieve generalization grounded on these flat minima for the unknown domains. Theoretically, we validate that merging SAM optimization with the UDIM objective establishes an upper bound for the true objective of the DG task. In an empirical aspect, UDIM consistently outperforms SAM variants across multiple DG benchmark datasets. Notably, UDIM shows statistically significant improvements in scenarios with more restrictive domain information, underscoring UDIM's generalization capability in unseen domains. Our code is available at \url{https://github.com/SJShin-AI/UDIM}.
RAT: Retrieval Augmented Thoughts Elicit Context-Aware Reasoning in Long-Horizon Generation
Mar 08, 2024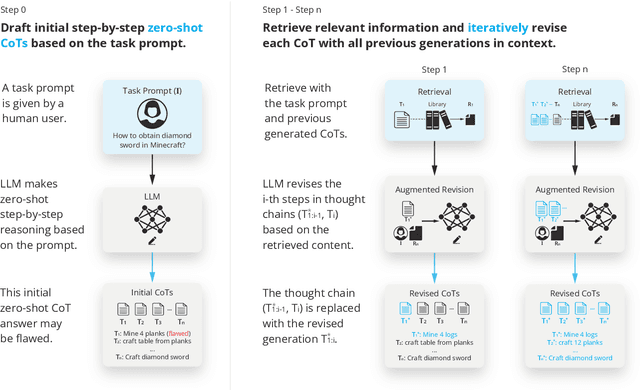
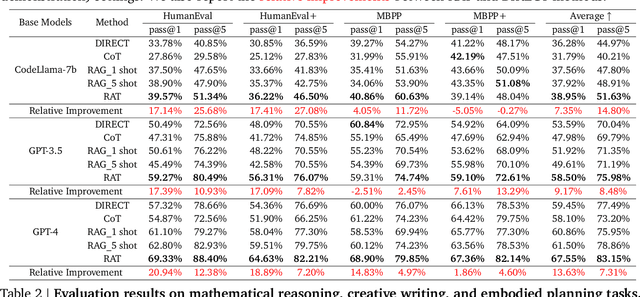
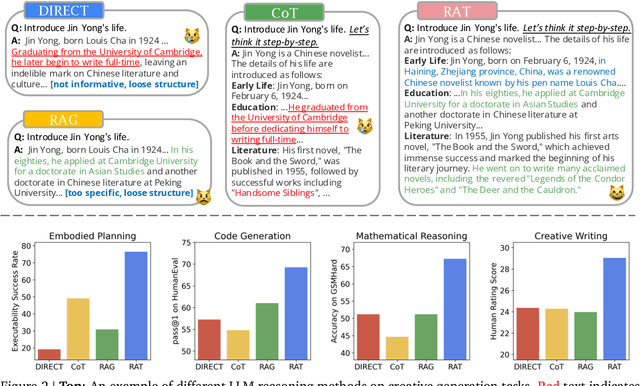
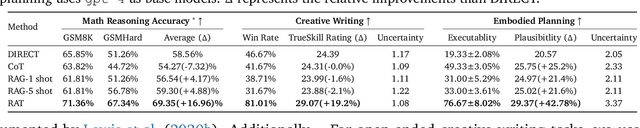
We explore how iterative revising a chain of thoughts with the help of information retrieval significantly improves large language models' reasoning and generation ability in long-horizon generation tasks, while hugely mitigating hallucination. In particular, the proposed method -- *retrieval-augmented thoughts* (RAT) -- revises each thought step one by one with retrieved information relevant to the task query, the current and the past thought steps, after the initial zero-shot CoT is generated. Applying RAT to GPT-3.5, GPT-4, and CodeLLaMA-7b substantially improves their performances on various long-horizon generation tasks; on average of relatively increasing rating scores by 13.63% on code generation, 16.96% on mathematical reasoning, 19.2% on creative writing, and 42.78% on embodied task planning. The demo page can be found at https://craftjarvis.github.io/RAT
LIBR+: Improving Intraoperative Liver Registration by Learning the Residual of Biomechanics-Based Deformable Registration
Mar 11, 2024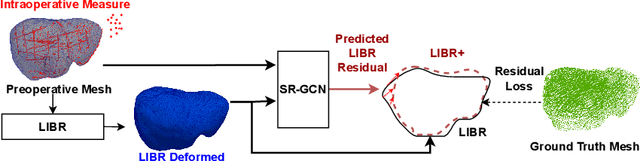
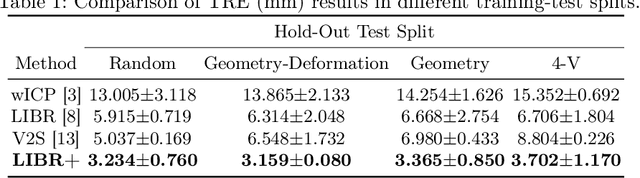
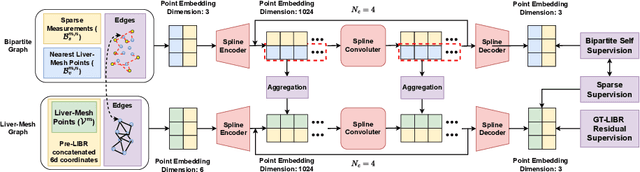

The surgical environment imposes unique challenges to the intraoperative registration of organ shapes to their preoperatively-imaged geometry. Biomechanical model-based registration remains popular, while deep learning solutions remain limited due to the sparsity and variability of intraoperative measurements and the limited ground-truth deformation of an organ that can be obtained during the surgery. In this paper, we propose a novel \textit{hybrid} registration approach that leverage a linearized iterative boundary reconstruction (LIBR) method based on linear elastic biomechanics, and use deep neural networks to learn its residual to the ground-truth deformation (LIBR+). We further formulate a dual-branch spline-residual graph convolutional neural network (SR-GCN) to assimilate information from sparse and variable intraoperative measurements and effectively propagate it through the geometry of the 3D organ. Experiments on a large intraoperative liver registration dataset demonstrated the consistent improvements achieved by LIBR+ in comparison to existing rigid, biomechnical model-based non-rigid, and deep-learning based non-rigid approaches to intraoperative liver registration.
BrushNet: A Plug-and-Play Image Inpainting Model with Decomposed Dual-Branch Diffusion
Mar 11, 2024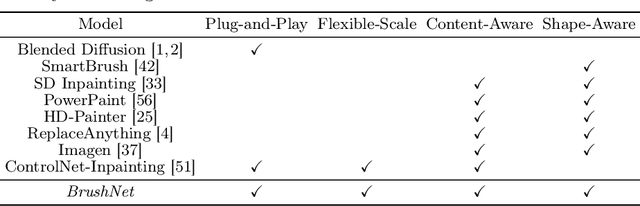
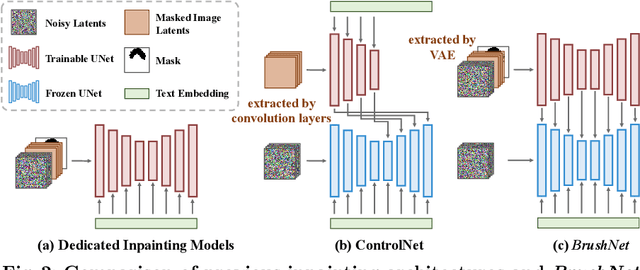
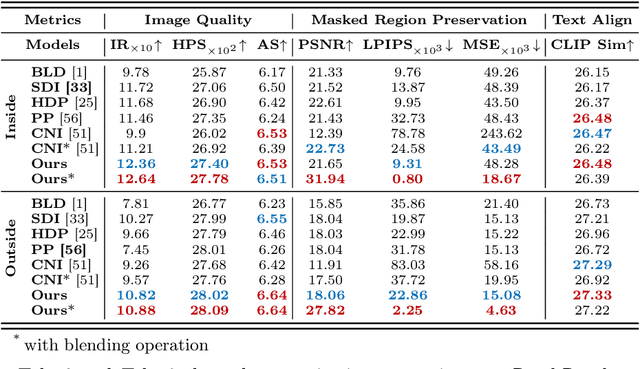
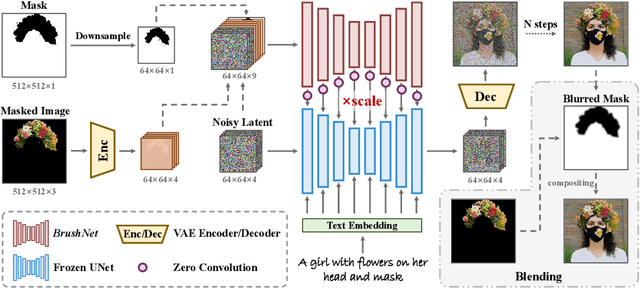
Image inpainting, the process of restoring corrupted images, has seen significant advancements with the advent of diffusion models (DMs). Despite these advancements, current DM adaptations for inpainting, which involve modifications to the sampling strategy or the development of inpainting-specific DMs, frequently suffer from semantic inconsistencies and reduced image quality. Addressing these challenges, our work introduces a novel paradigm: the division of masked image features and noisy latent into separate branches. This division dramatically diminishes the model's learning load, facilitating a nuanced incorporation of essential masked image information in a hierarchical fashion. Herein, we present BrushNet, a novel plug-and-play dual-branch model engineered to embed pixel-level masked image features into any pre-trained DM, guaranteeing coherent and enhanced image inpainting outcomes. Additionally, we introduce BrushData and BrushBench to facilitate segmentation-based inpainting training and performance assessment. Our extensive experimental analysis demonstrates BrushNet's superior performance over existing models across seven key metrics, including image quality, mask region preservation, and textual coherence.